이전 강의 보기 -  Lecture 8 | Deep Learning Software
Lecture 8 | Deep Learning Software
Lecture 8 | Deep Learning Software
 Note Taking
Note Taking
Lecture 8 요약
•
CPU VS GPU
◦
CPU 는 코어 수가 적은 대신에 clock 이 높음
◦
GPU 는 clock 이 낮은 대신에 코어 수가 많음
◦
GPU 는 병렬처리에 이점을 가짐
▪
Matrix multiplication
▪
Convolution operation
•
Deep Learning Framework
◦
크고 복잡한 computational graph 를 설계하기 쉬움
◦
Computational graph 내 weight 요소들의 gradient 를 계산하기 쉬움
◦
GPU 에서 효율적으로 학습할 수 있음
◦
TensorFlow
▪
레퍼런스가 많음
▪
Static model 로 학습 모델을 코드로부터 분리하기 쉬움
◦
PyTorch
▪
Model, Variable, Module 의 3체계로 이루어짐
▪
Dynamic model 로 학습 도중에 모델을 구성하여 conditional 한 flow 를 python code 기반으로 구성할 수 있음
LeNet-5
•
Conv - Pool - Conv - Pool - FC - FC 의 구조
•
Digit recognition 에 좋은 성능을 보였음
AlexNet
•
현재 많은 CNN 의 근간이 되는 네트워크
•
ILSVRC 2012 winner 로 ILSVRC 사상 첫 CNN-based network 가 1등을 차지하는 경우였음
•
Conv - Max Pool - Norm -
Conv - Max Pool - Norm -
Conv - Conv - Conv -
Max Pool -
FC - FC - FC
•
간단한 parameter 계산 예시
◦
Input 은 의 이미지
◦
First Layer (Conv-1) 에 filter with stride 가 96 개가 존재
◦
Output dimension 은 ?
▪
▪
•
2012 년 당시 GPU 의 메모리가 작았기 때문에 activation vector 를 depth 를 기준으로 반으로 나누어 각기 다른 GPU 에서 병렬적으로 학습을 진행하는 방법을 채택
•
Conv-1, Conv-2, Conv-4, Conv-5 는 단일 GPU 만으로도 진행이 가능한 연산
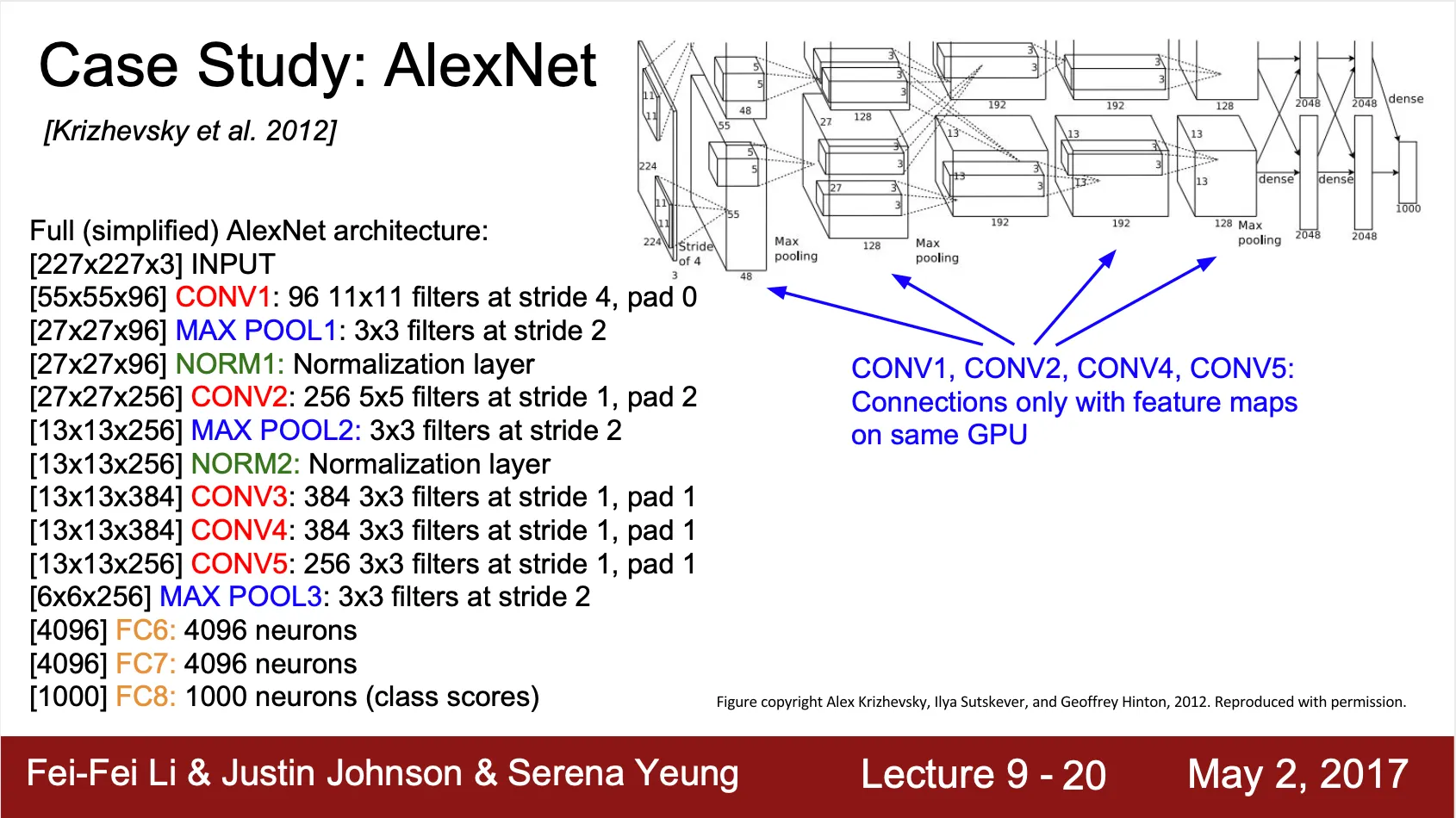
•
Conv-3 ,FC-6, FC-7, FC-8 같은 경우에는 이전 layer 의 모든 데이터를 쓰기 때문에 GPU 간의 통신이 필요한 형태
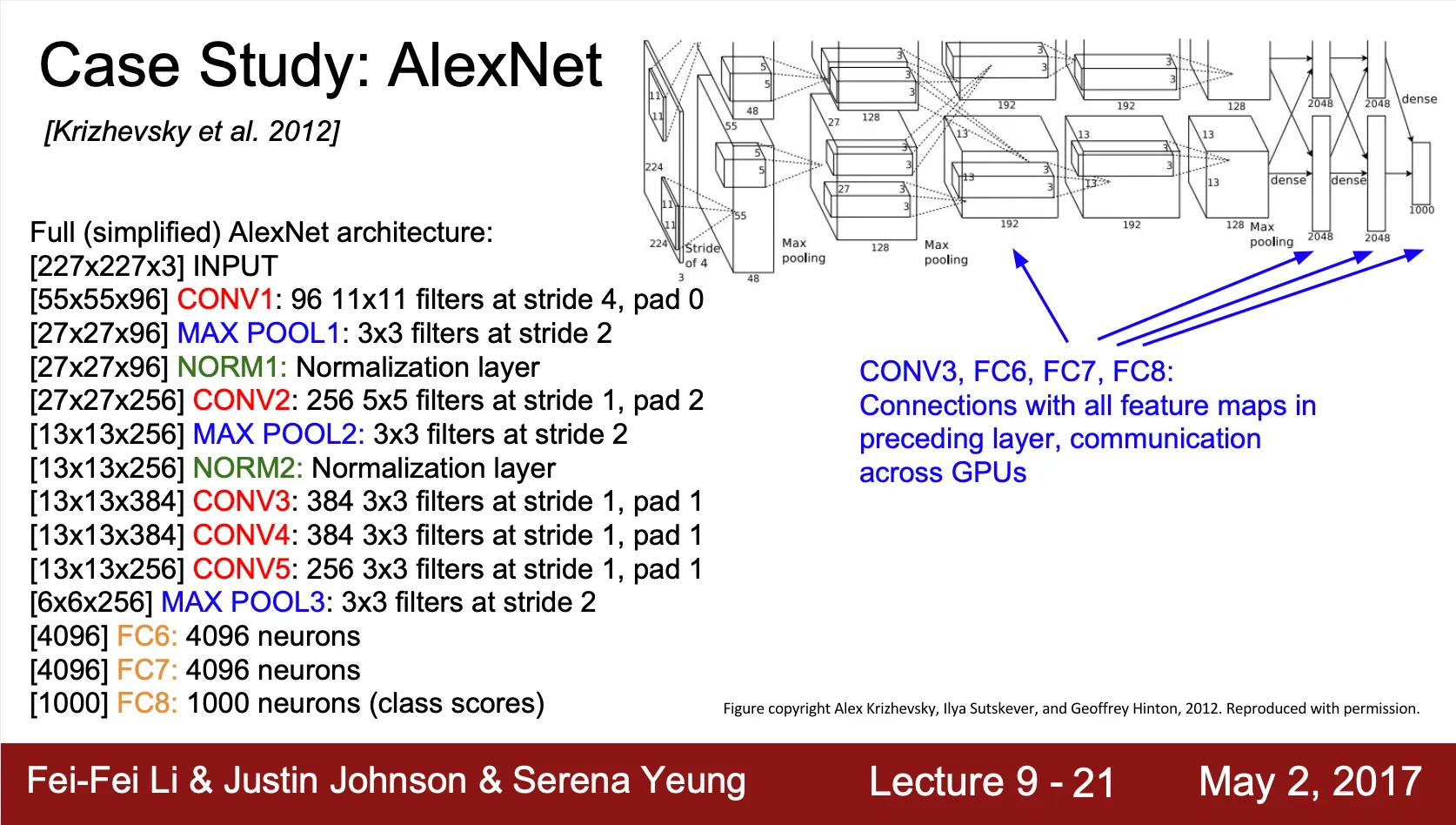
Details
VGGNet
•
ILSVRC 2014 에서 아쉽게 GoogLeNet 을 이기지 못하고 2등을 차지한 네트워크
•
ILSVRC 2013 까지와는 다르게 ILSVRC 2014 의 상위 네트워크는 깊이가 깊어짐
◦
ILSVRC 2012 winner - 8 layers
◦
ILSVRC 2013 winner - 8 layers
◦
ILSVRC 2014 winner - 19 layers
◦
ILSVRC 2014 second place - 22 layers
•
큰 receptive field filter 를 적게 쓰는 것보다 작은 receptive field filter 를 많이 쓰는 것이 좋다는 것이 논문이 시사하는 점
◦
Conv with stride 이 3 개 연달아 있는 것은 Conv with stride 이 1개 있는 것과 최종 receptive field 가 같음
◦
마지막 activation vector 의 한 pixel 이 첫 input 의 어느 범위만큼의 계산 결과인지를 보면 서로 영역으로 같음을 알 수 있음
◦
Receptive field 는 같지만 두 방법은 parameter 수는 다름
◦
Input vector, output vector 모두의 depth 를 라고 가정하면, Conv with stride 이 3 개 연달아 있는 것은 으로 이지만 Conv with stide 이 1개 있는 것은 으로 임
•
때문에, VGGNet 은 , Conv with stride 이 3 개 연달아 있는 구조의 반복임

•
Parameter 의 대부분이 끝 쪽의 FC layer 에 몰려 있는 것을 볼 수 있음
Detail
GoogLeNet
•
ILSVRC 2014 winner 네트워크
•
FC layer 를 가지지 않아 parameter 를 대폭 줄임
•
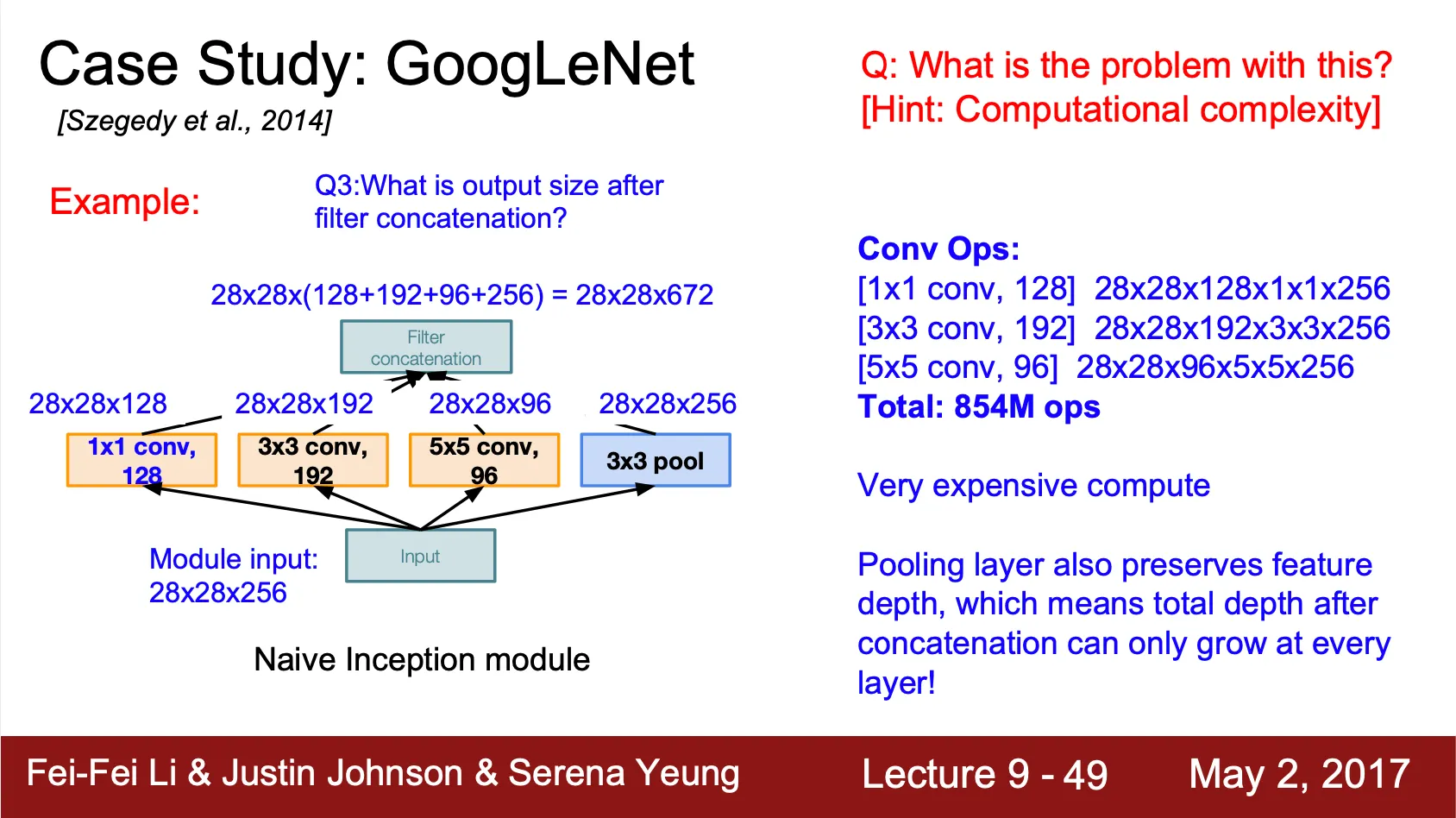
Inception Module
◦
Localize 된 네트워크 구조인 Inception Module 을 제안하고, 그 구조를 켜켜이 쌓아 네트워크를 구성
◦
Conv, Conv, Conv, Max Pool 을 병렬적으로 나열하여 그 output vector 를 depthwise concatnate 하는 구조
◦
Computation 측면에서 GoogLeNet 은 local 하게 dense 한 네트워크 연산을 진행하게 되는 반면 크게 보았을 때는 한 Layer 안에 존재하는 parameter 에 비해서 병렬화가 되어 있기 때문에 네트워크 자체는 sparse 하다고 볼 수 있음
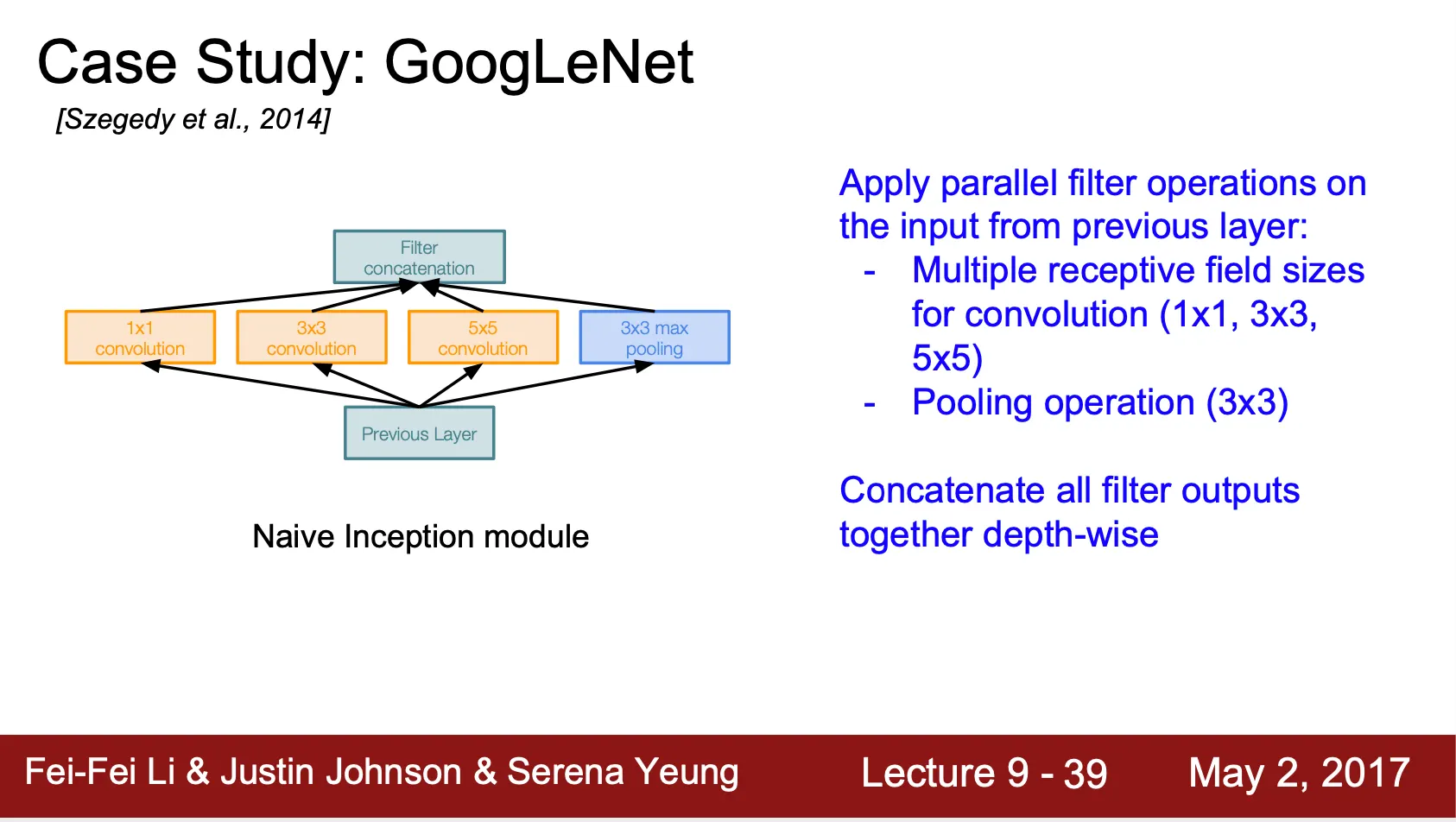
•
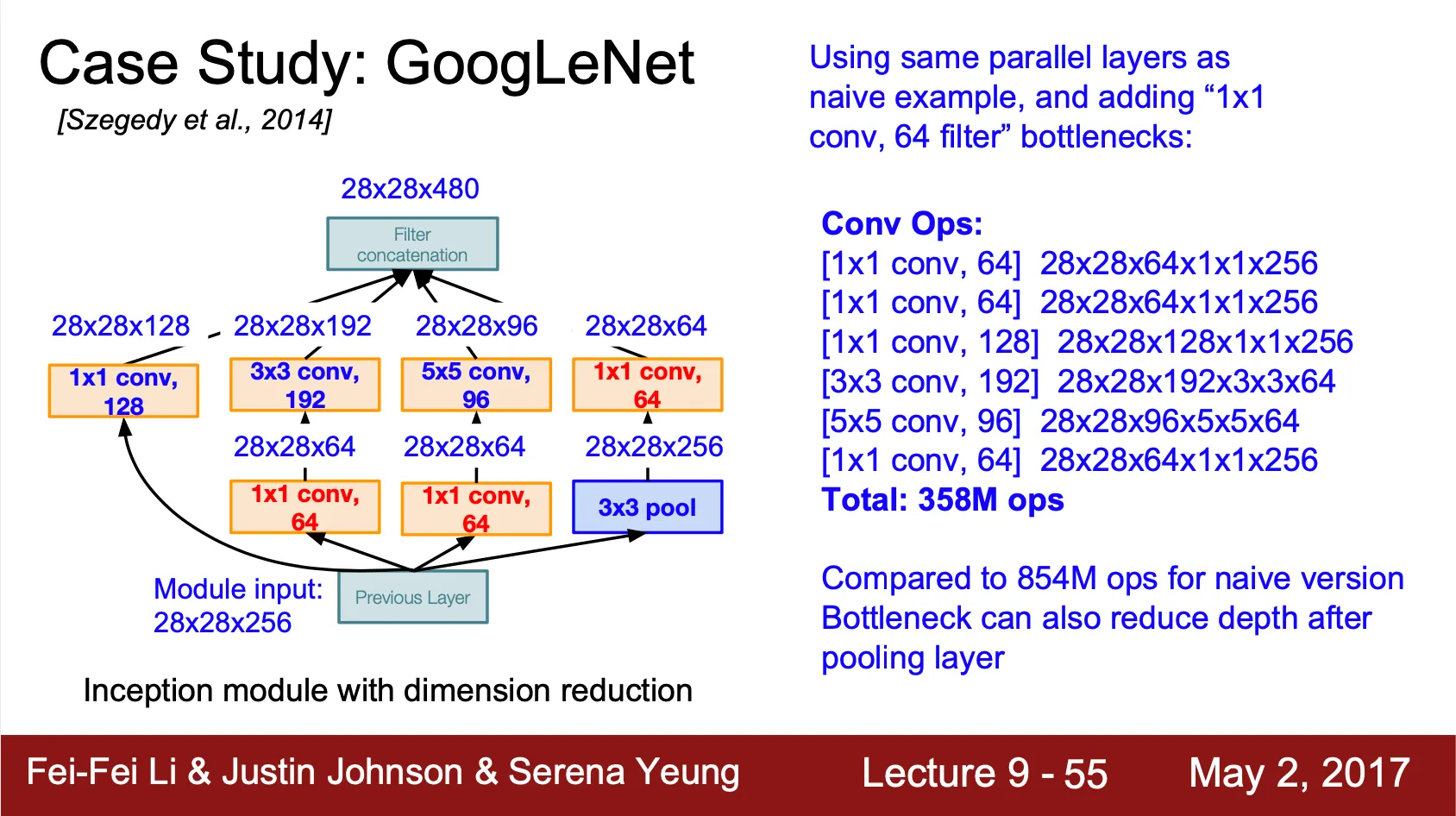
Bottleneck Layer
◦
Inception Module 은 연산 수가 생각보다 많은 것이 단점
◦
병렬로 나열된 convolution 연산을 하기 전에 bottleneck layer 로 Conv 를 주어 기존에 존재하던 convolution 연산을 하기에 앞서 vector 의 depth 를 줄임
◦
강의의 예시 depth 로는 854M 에서 358M 으로 총 연산 수를 줄임
•
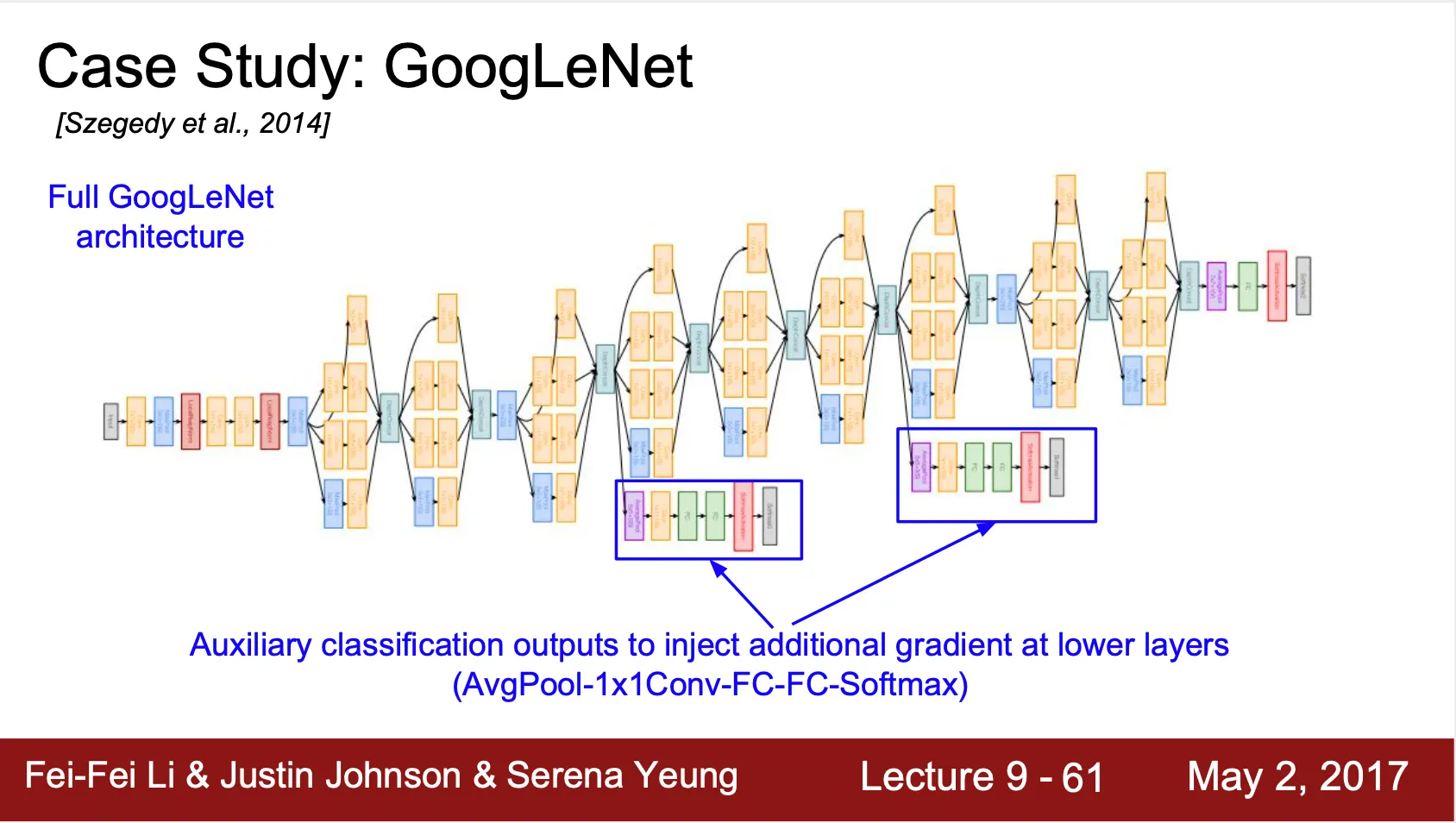
Auxiliary Classifier
◦
GoogLeNet 은 생각보다 깊은 네트워크이기 때문에 어김없이 gradient vanishing 문제가 나타남
◦
이에 대한 해결책으로 output 에서 가까운 곳들에 추가적으로 classifier 를 설치하여 input 과 가까운 곳의 학습된 weight 들의 update 에 기여할 수 있도록 함
◦
Back Propagation 시 auxiliary classifier 는 gradient 의 0.3 배 만큼의 가중치를 가지게 됨
◦
Inference time 엔 제외
ResNet
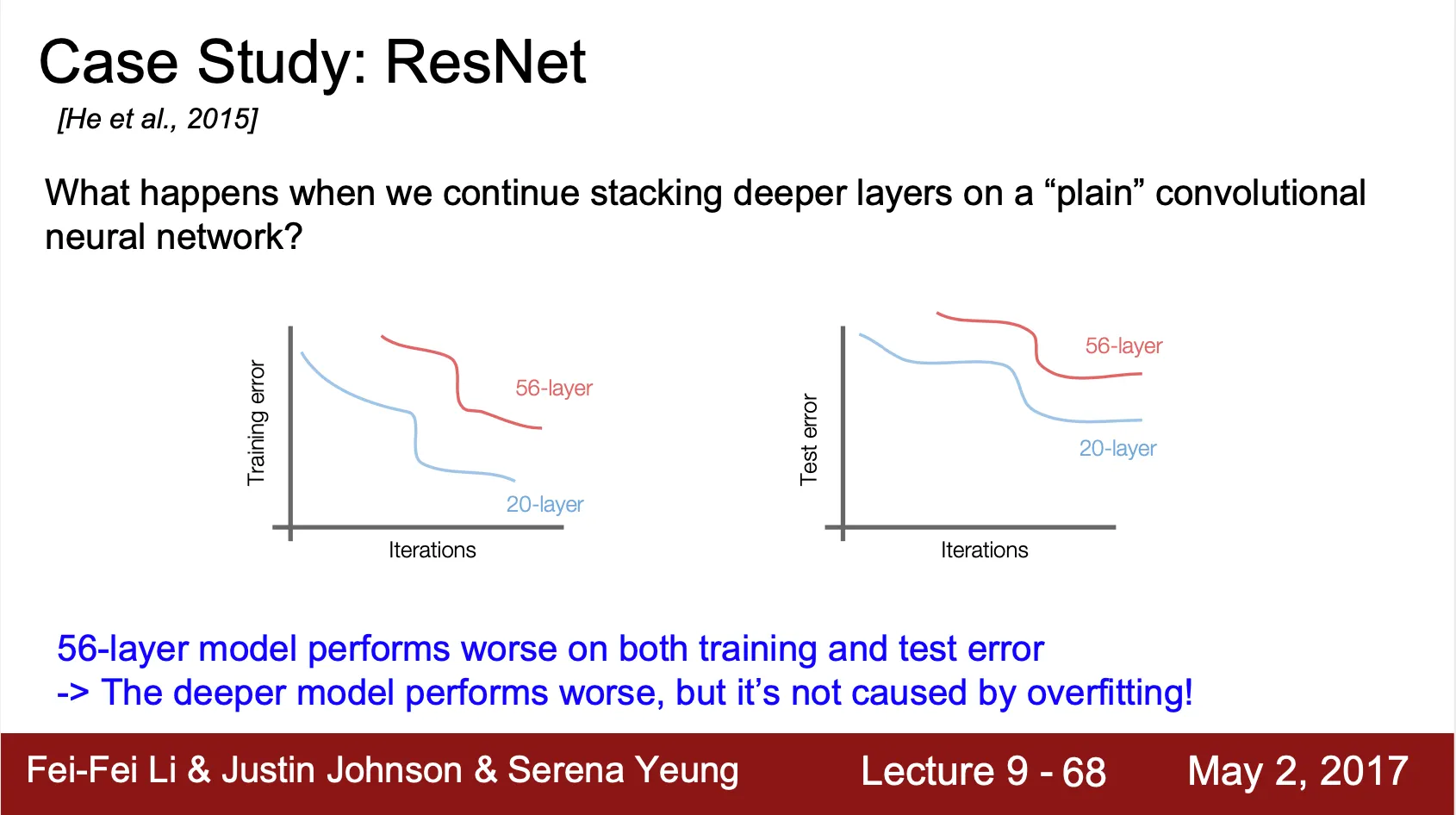
•
네트워크의 구조가 깊어지면서 생기는 나타나는 학습 효과 저하는 overfitting 에 의한 효과가 아님
◦
아래의 그림처럼, training time 에도 deep network 가 오히려 error 가 높은 것을 볼 수 있음
•
깊은 네트워크에서 발생하는 학습 효과 저해를 optimization problem 으로 보았고, 정확히는 gradient vanishing 문제로 봄
•
깊은 네트워크에서도 얕은 네트워크에서처럼 gradient 를 잘 전달해줄 수 있도록 identity mapping 을 layer 에 추가
◦
Residual Block 구조
◦
Back Propagation 시에 일정하게 전달되는 최소한의 upstream gradient 를 보장해줄 수 있음
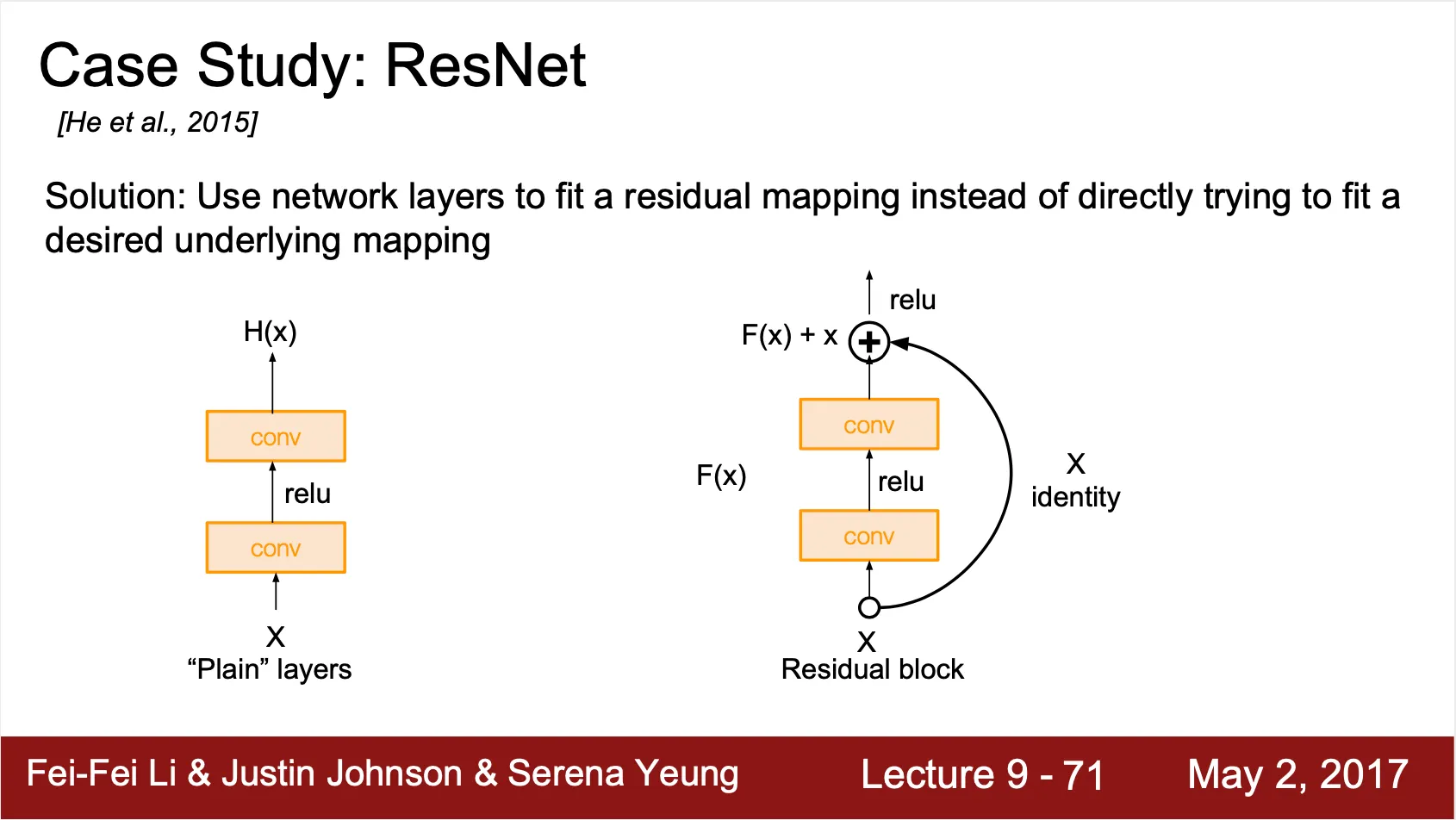
•
전체적인 구조는 Residual Block 을 켜켜이 쌓은 형태
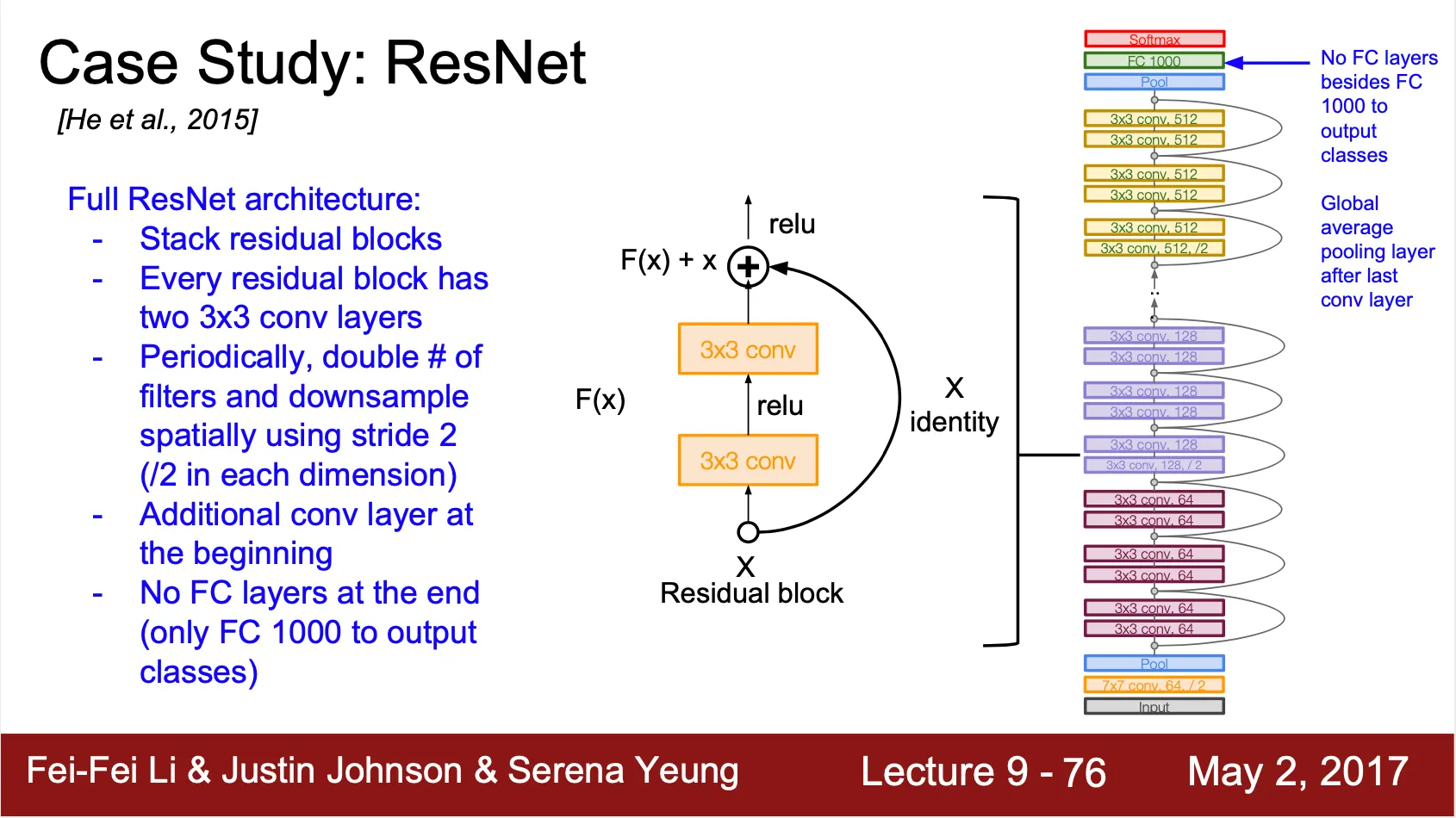
•
35, 50 ,101, 152 layer 구조의 ResNet 이 존재
•
ResNet-50+ 같은 경우에는 연산의 수를 줄이기 위해서 GoogLeNet 에서 썼던 것과 같은 bottleneck layer 를 사용
◦
Depth 를 줄여 연산하고 다시 늘리는 형태
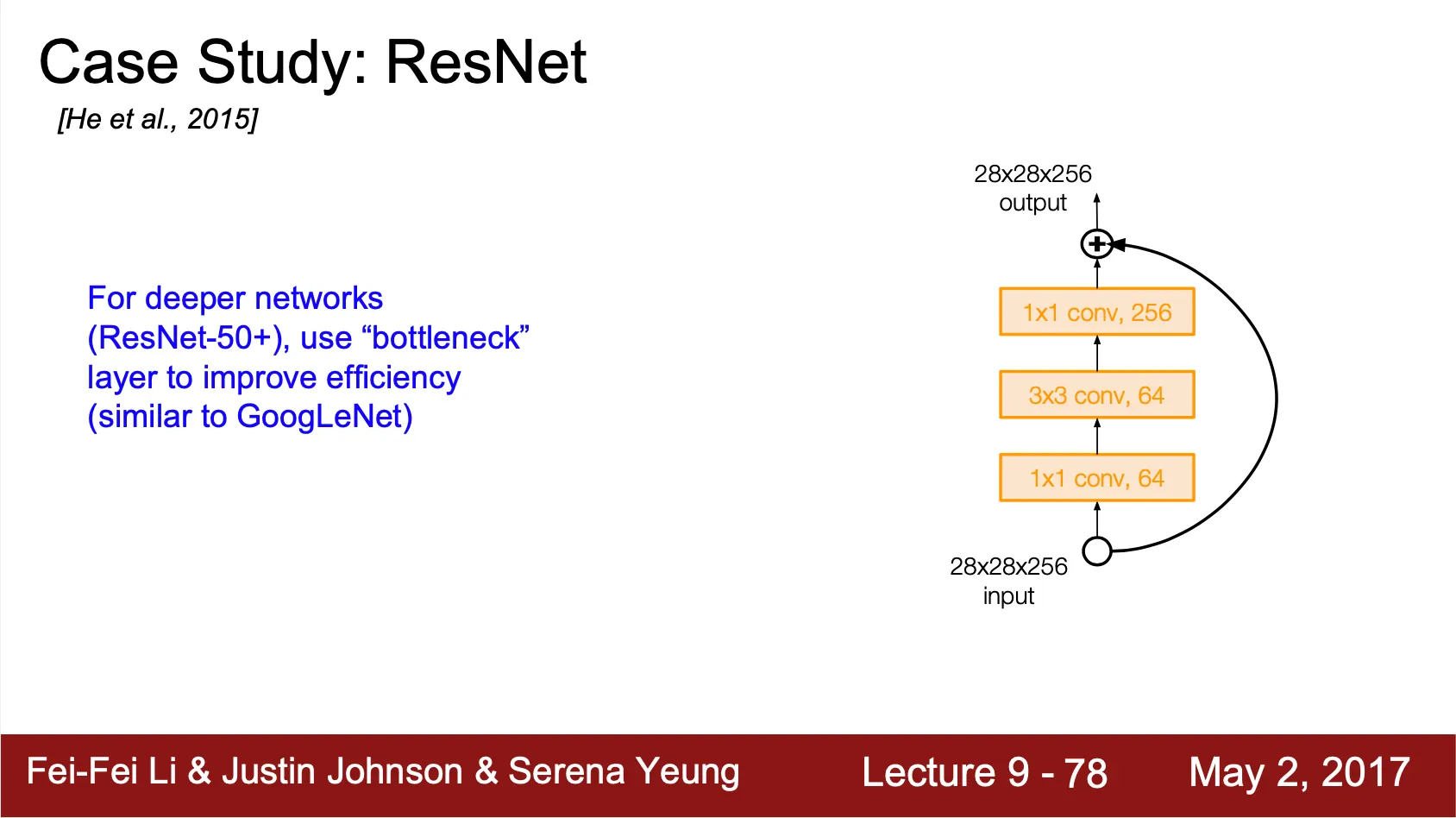
Detail
Deep Neural Network Model 비교
•
좌측은 단순 top-1 accuracy 비교
•
우측은 메모리 사용량, 연산수 등을 포함한 자료
◦
원 크기는 메모리 사용량
◦
x 축은 연산 수
◦
y 축은 top-1 accuracy
•
VGGNet 은 필요 메모리가 크고 연산수가 많지만 그만큼 accuracy 가 좋은 편임
•
GoogLeNet 은 메모리 사용량이 굉장히 적음
•
AlexNet 은 낮은 accuracy 를 가지고 필요 메모리도 큼
•
ResNet 은 메모리와 연산 수 측면에서 중간정도 지표를 가지는데 accuracy 가 굉장히 좋음
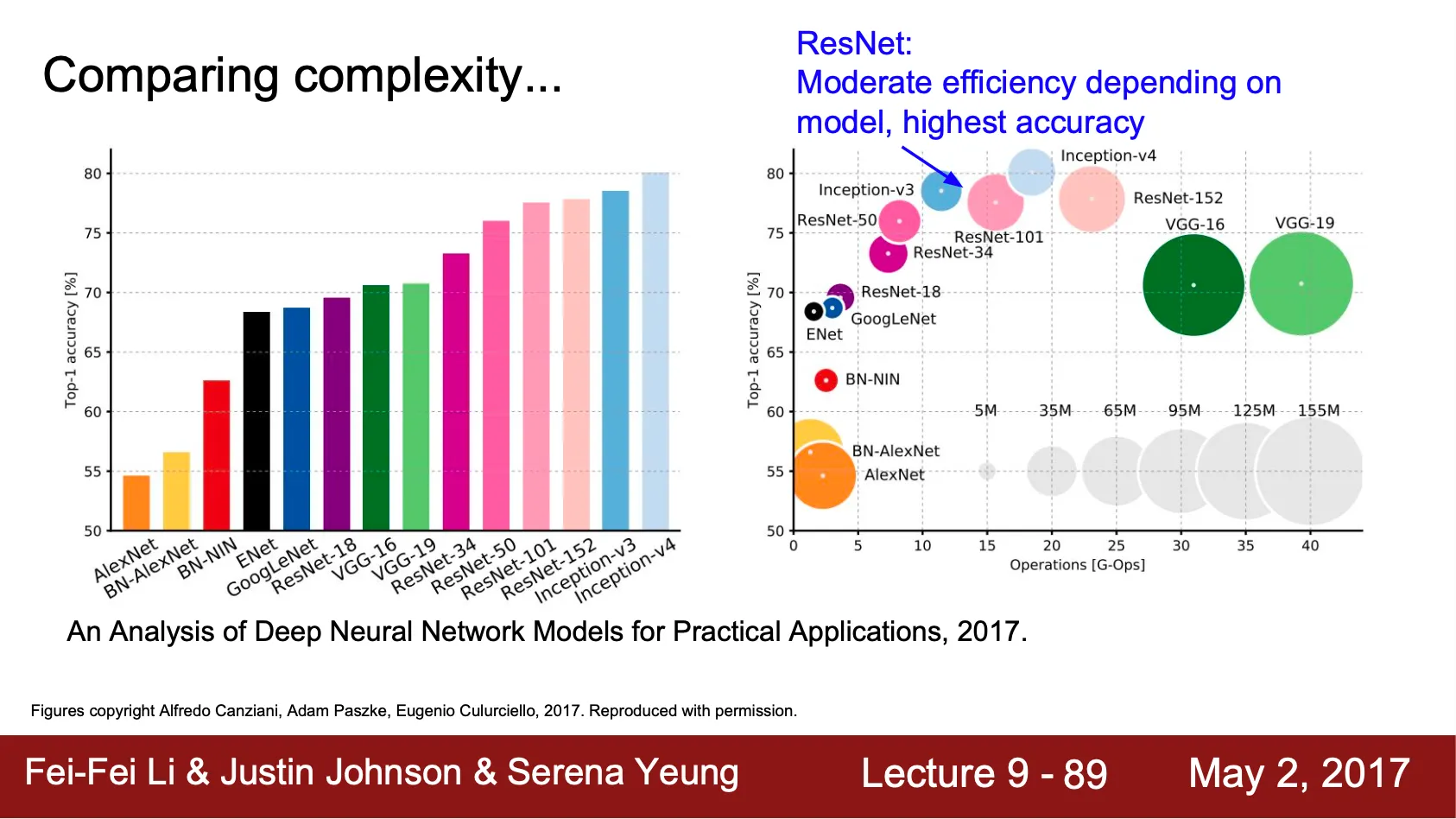
•
VGGNet 은 forward pass 에 걸리는 시간이 김 (deep network)
•
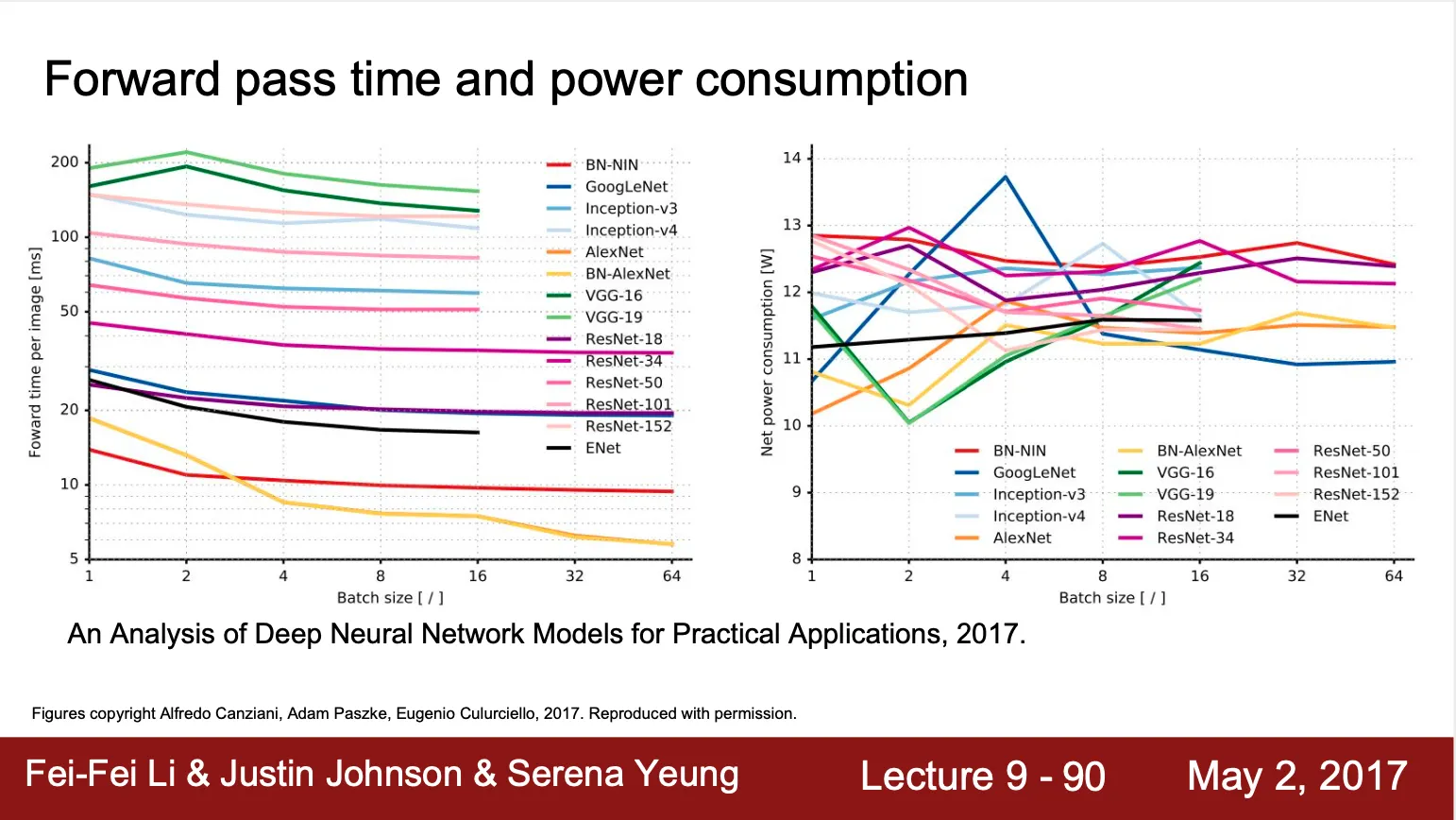
Other Architectures
•
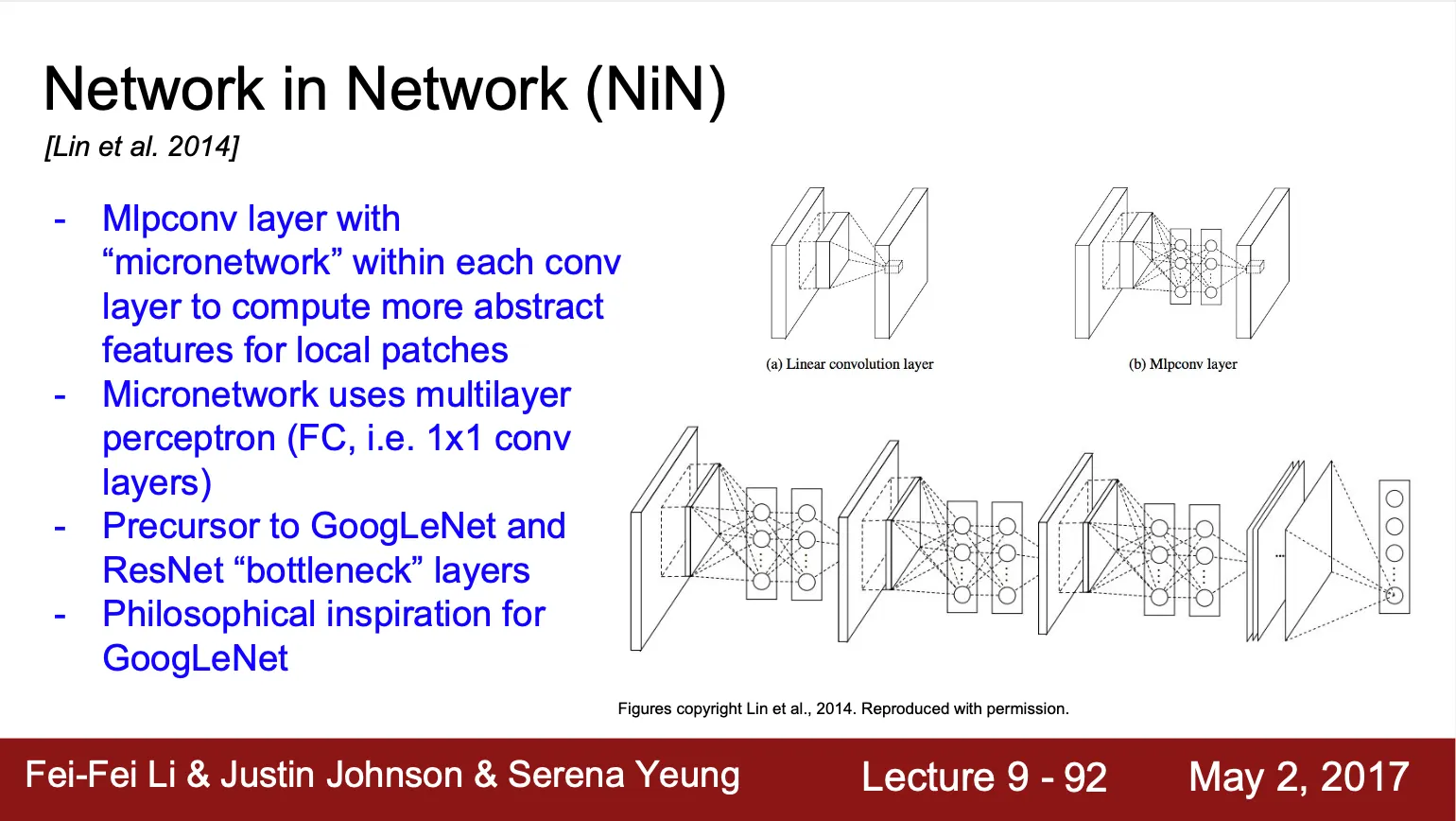
Network in Network
◦
Convolution 연산에서 dot product 이후 생긴 각 값들을 MLP 을 통과시켜 최종적인 value 를 뽑아내는 구조 (Convolution network 내에 MLP micronetwork 가 존재)
◦
GoogLeNet 과 ResNet 에서 보여진 bottleneck layer 의 선구자
◦
GoogLeNet 의 Inception Module 설계에 영감이 된 구조
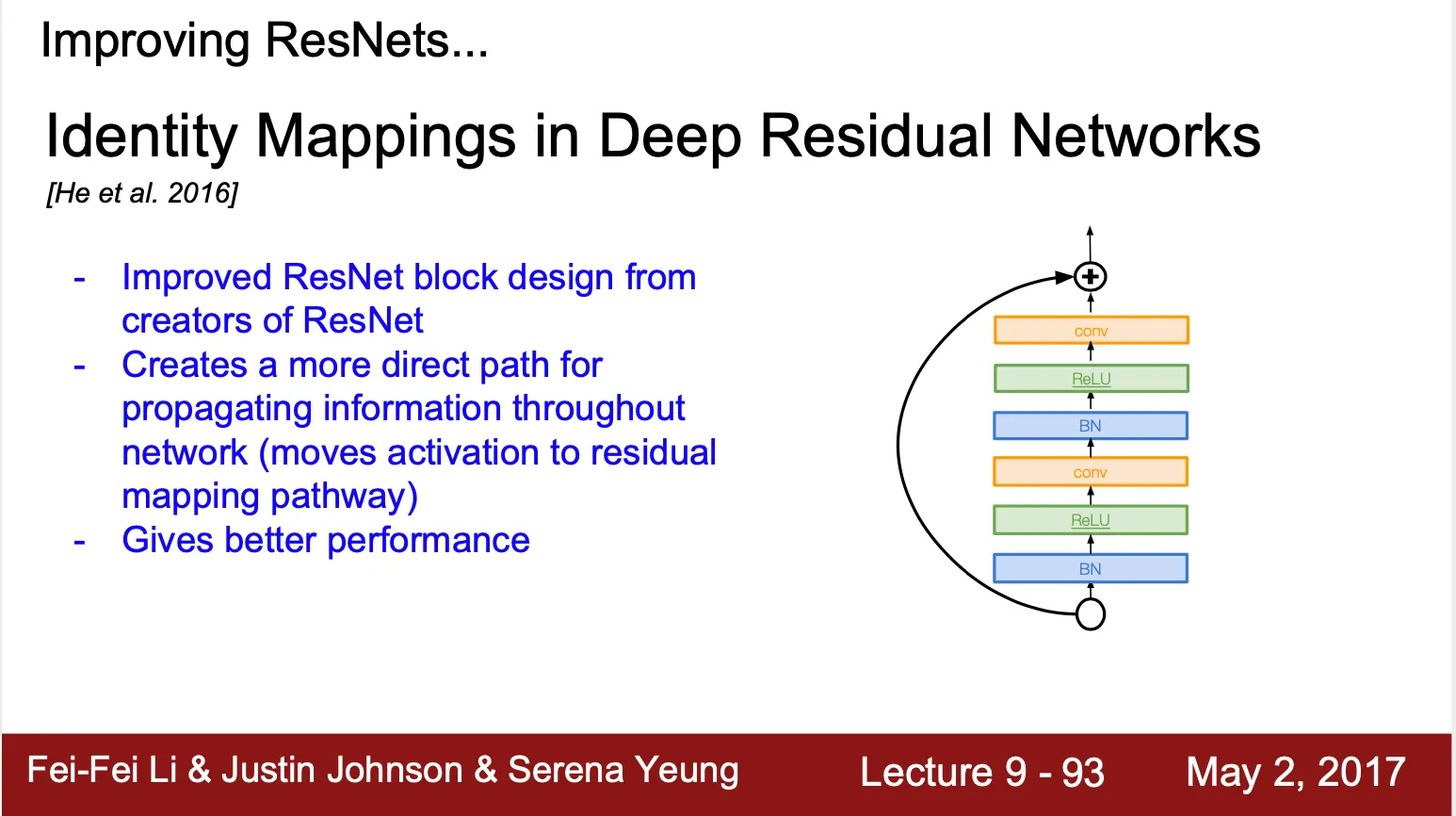
•
Identity Mappings in Deep Residual Network
◦
ResNet 개발팀이 만들어낸 또 다른 residual network
◦
기존 Residual Block 보다 큰 구조(Batch Norm - ReLU - Conv - Batch Norm - ReLU - Conv) 를 residual mapping pathway 로 연결
•
Wide Residual Networks
◦
기존 Residual Block 의 filter 개수를 늘린 구조
◦
50-layer 의 wide ResNet 이 152-layer 기존 ResNet 을 performance 에서 좋음
◦
네트워크의 depth 를 늘리는 것보다 병렬처리가 가능한 width 를 늘리는 것이 computationally efficient 함
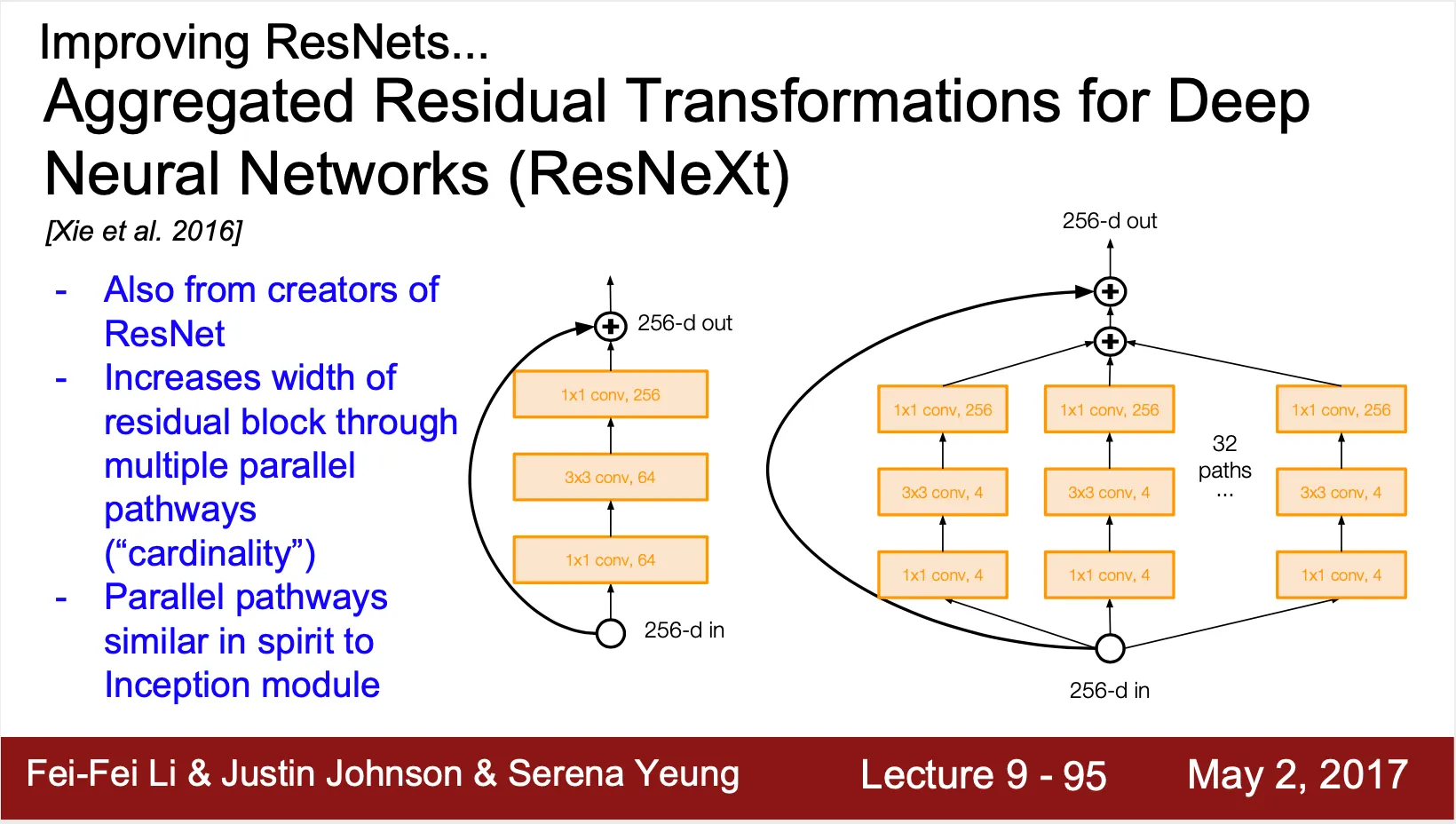
•
Aggregated Residual Transformations Neural Networks (ResNeXt)
◦
ResNet 개발팀이 만들어낸 또 다른 residual network
◦
기존 Residual Block 의 pathway 개수 (cardinality) 를 늘림 (Inception Module 에 영향을 받은 구조)
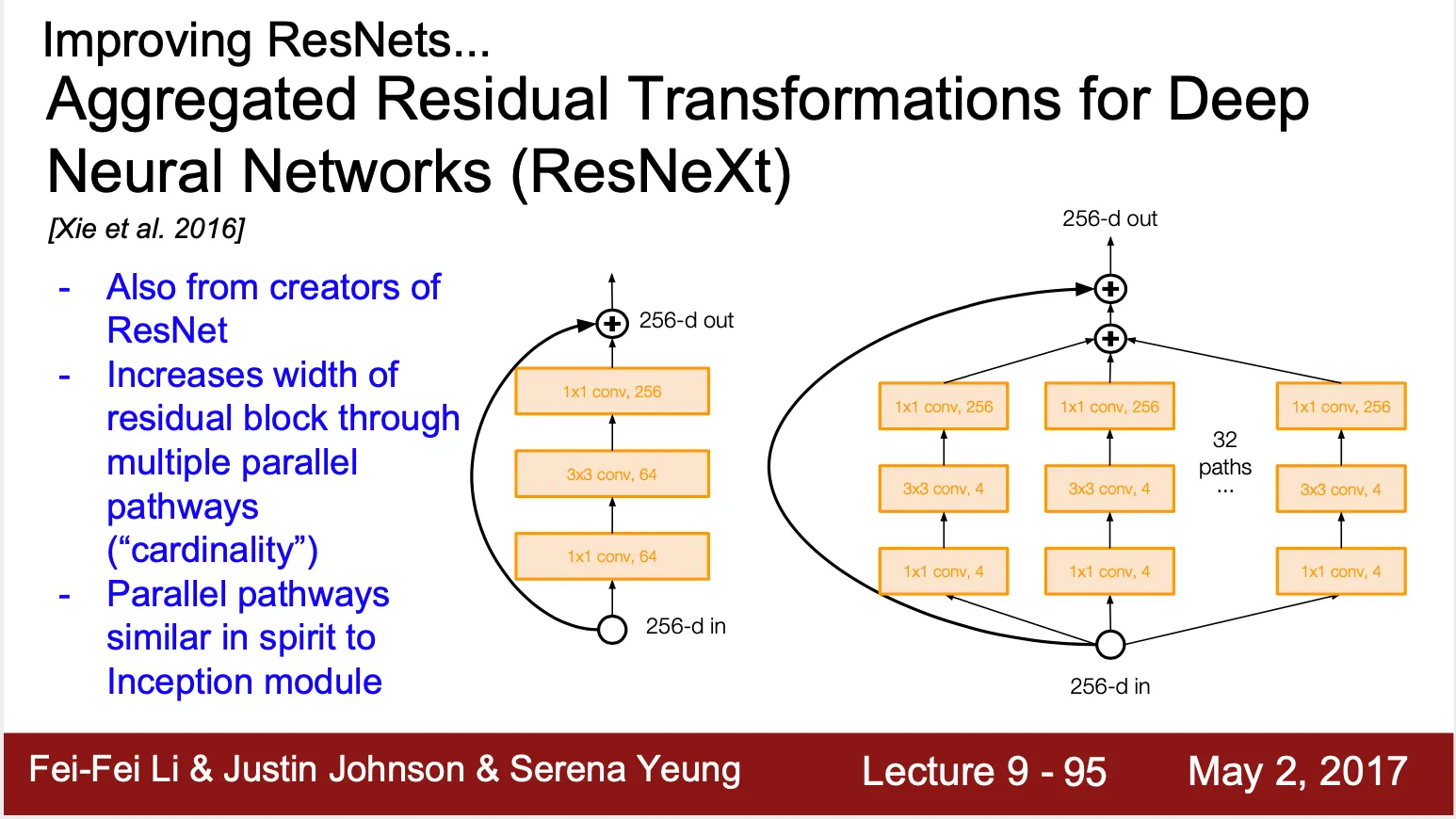
•
Deep Networks with Stochastic Depth
◦
Gradient vanishing 문제를 해결하기 위해 고안된 네트워크
◦
각 layer subset 사이에 ResNet 처럼 identity function 을 연결하고, training time 에 랜덤하게 layer subset 자체를 dropout 하는 형태
◦
Inference time 에는 dropout 없이 전체 네트워크 사용

•
FractalNet: Ultra-Deep Neural Networks without Residuals
◦
Shallow path 와 deep path 가 공존하여, shallow path 로부터 어느정도 gradient 의 전달을 보장받고, deep path 로부터 모델의 깊이를 증가시키는 효과를 얻음
◦
Training time 에 일부 sub-path 를 dropout 함
◦
Inference time 에는 전체 네트워크를 사용
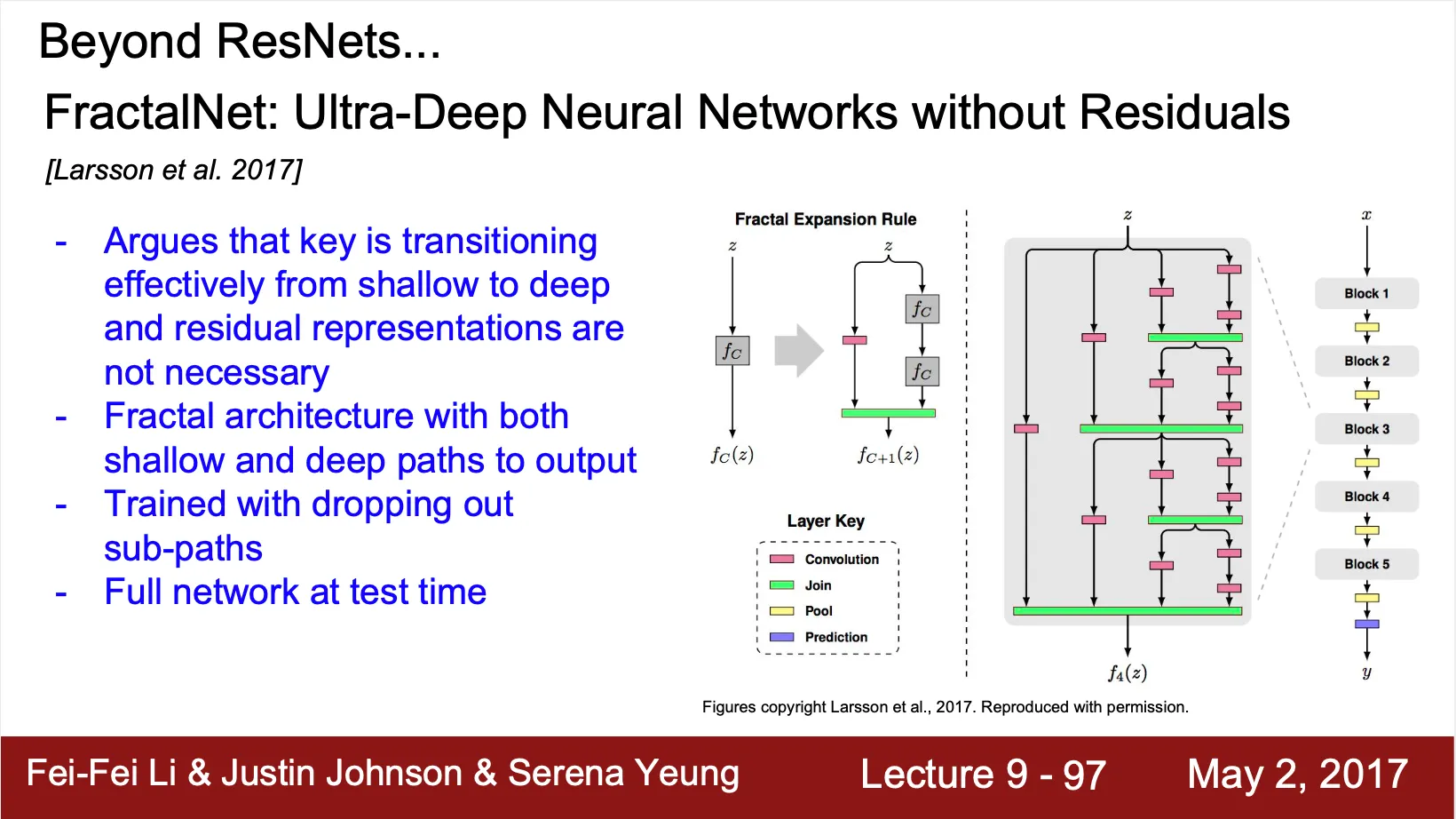
•
Densly Connected Convolutional Networks (denseNet)
◦
각 Conv 가 낮은 단계의 Conv 로 자신의 output vector 를 전달
◦
각 Conv 는 받은 output vector 들을 concatenate 하여 다음 Conv 에 전달
◦
Dense connection 으로 gradient vanishing 을 완화하고 feature propagation 을 용이하게 함
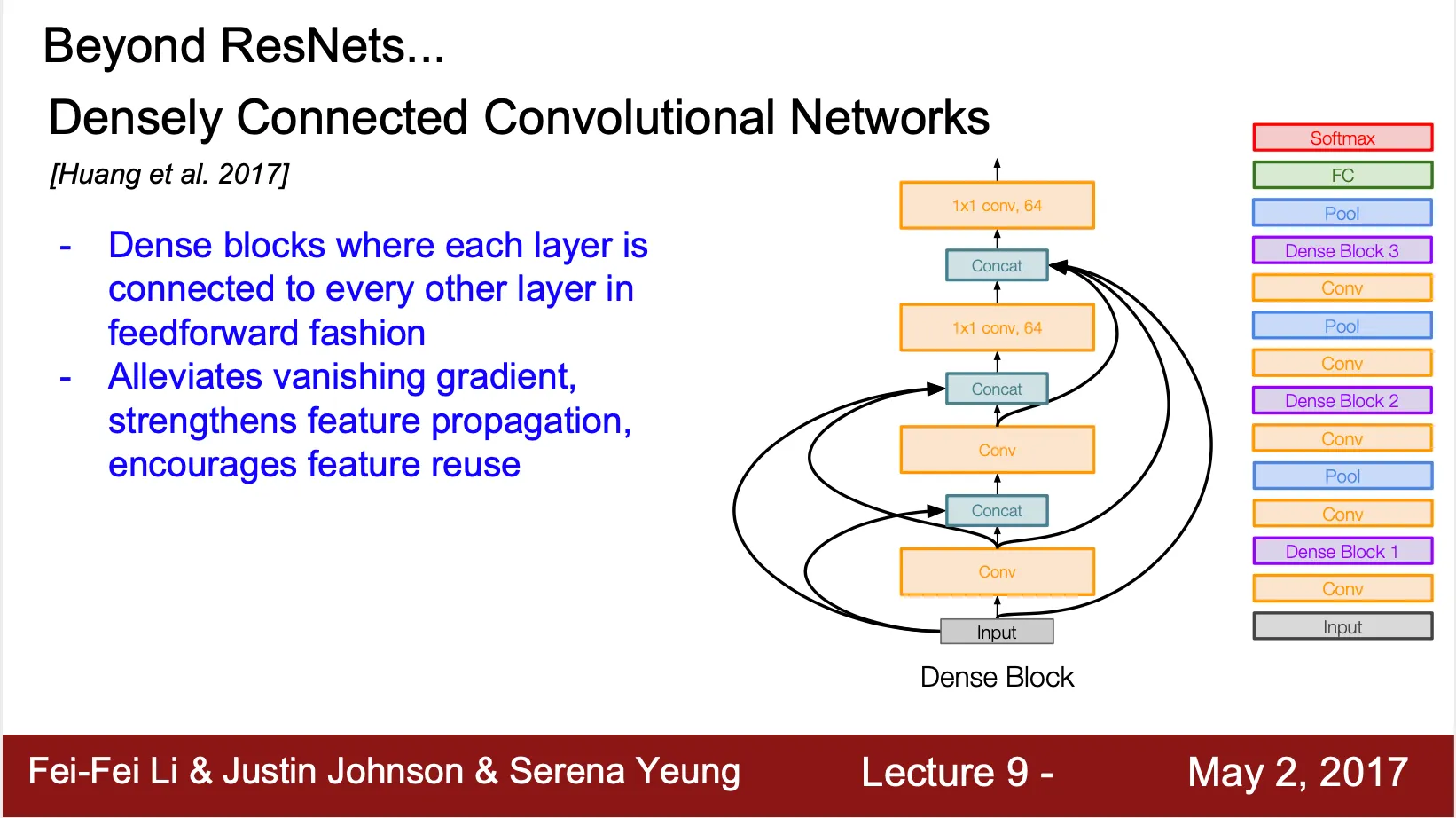
•
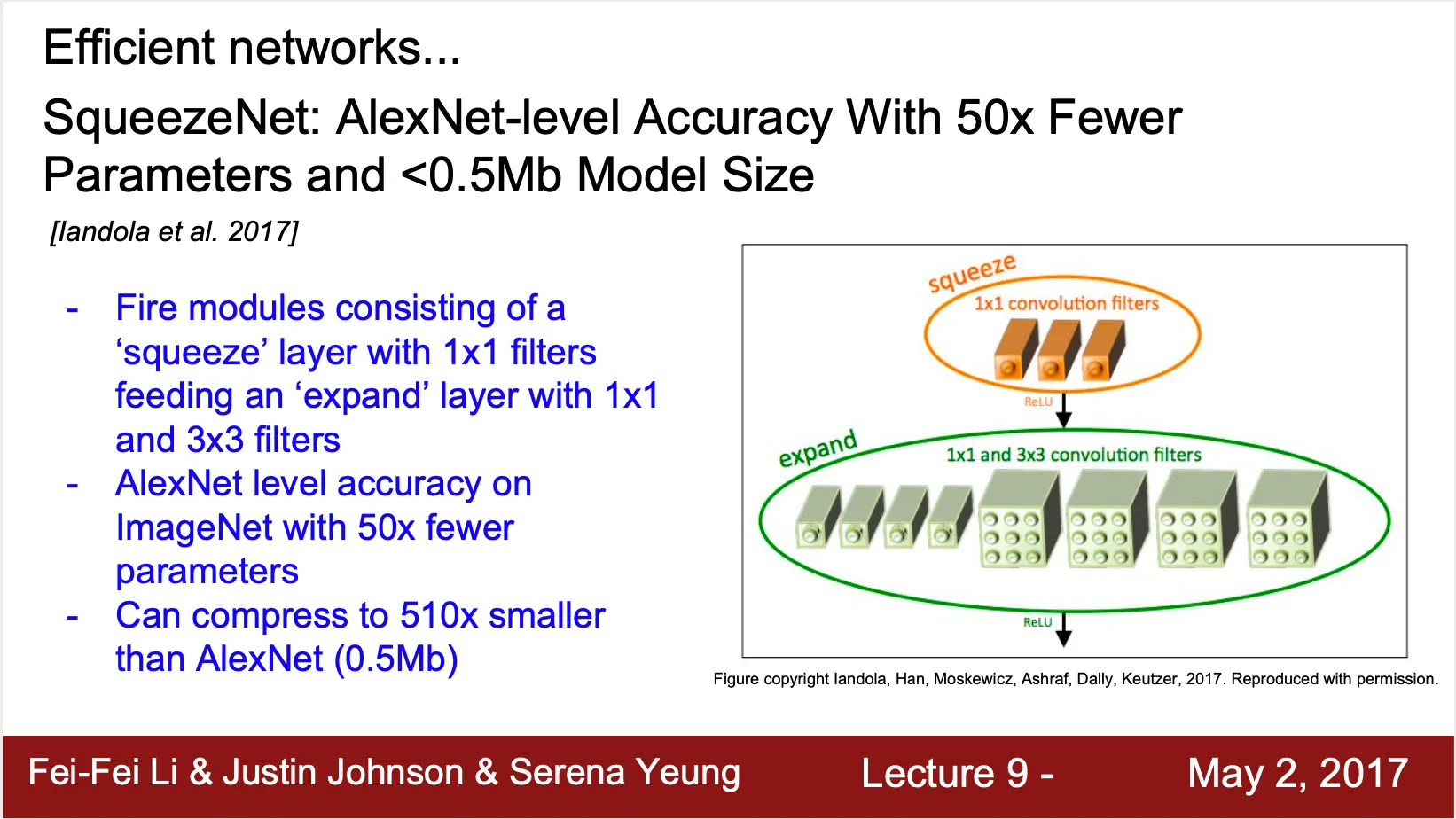
SqueezeNet
◦
Squeeze step 과 expand step 이 나누어져 있음
◦
Squeeze step 에서는 Conv 로만, expand step 에서는 Conv, Conv 모두로 이루어져 있음
◦
AlexNet 과 비슷한 수준의 accuacy 를 가지지만 50 배 적은 parameter 를 가짐
◦
모델 사이즈도 0.5 Mb 정도로 AlexNet 보다 510 배 작음