


 Note Taking
Note Taking
Lecture 7 요약
•
Optimization Algorithms
◦
SGD - 전체 데이터셋에 대한 loss 계산 후 update (mini-batch 등의 변종 존재)
◦
SGD + Momentum - 관성 요소 도입하여 saddle point, local optima 수렴의 문제 해결
◦
Nesterov Momentum - 미래의 방향성을 현재에 어느정도 반영해 유연하고 부드러운 변화 도입
◦
AdaGrad - wieghtwise gradient scale 조정
◦
RMSProp - AdaGrad 가 시간에 따라 gradient 가 매우 작아지는 현상 해결
◦
Adam - Momentum + RMSProp
•
Learning rate schedule
◦
Step decay
◦
Exponential decay
◦
decay
•
Model Ensemble
◦
여러 training model 의 결과를 average 하여 inference time 의 accuracy 를 극대화 하는 방법론
◦
각 training model 이 집중하는 특성이 다르기 때문에 specifity 를 줄이고 generality 가 높은 결과를 낼 가능성을 높임 (averaging)
◦
Training step 도중에 snapshot 을 찍는 방법론도 존재
•
Regularization
◦
L1, L2 Regularization
◦
Dropout - activation 을 0 으로 변경하여 neuron 을 제거하는 효과 (random regularization)
◦
Inverted Dropout - Dropout 사용 시 inference 쪽에 있었던 probability 곱 연산을 train time 으로 가져와서 inference time 의 효율 극대화
◦
Data Augmentation - 이미지 전처리로 train data 의 수 늘림
◦
DropConnect - Dropout 과는 달리 weight 를 0 으로 만들어 연결관계만을 끊음
◦
Fractional Max Pooling - Max pooling region 에 randomness 부여
◦
Stochastic Depth - Random 하게 layer block 을 끊고 이전의 layer block 의 결과가 이어짐
•
Transfer Learning
◦
Pre-trained 모델을 이용해 모델의 뒷 부분만 변경하여 재학습하는 방법론
◦
적은 데이터로도 좋은 성능을 낼 수 있음
CPU VS GPU
•
CPU 는 clock 이 높은 대신에 코어 수가 적음
◦
순차적 작업에 적합함
•
GPU 는 코어 수가 많은 대신에 clock 이 낮음
◦
병렬처리 작업에 적합함
◦
Matrix Multiplication 같은 경우, 각 dot product 연산이 병렬적으로 연산 가능
◦
때문에 deep Learning 에서 GPU 가 통상적으로 CPU 보다 6~70 배 빠르고, 같은 GPU 더라도 highly optimized 된 computational primitives 의 사용 여하에 따라 3배 정도 차이가 남
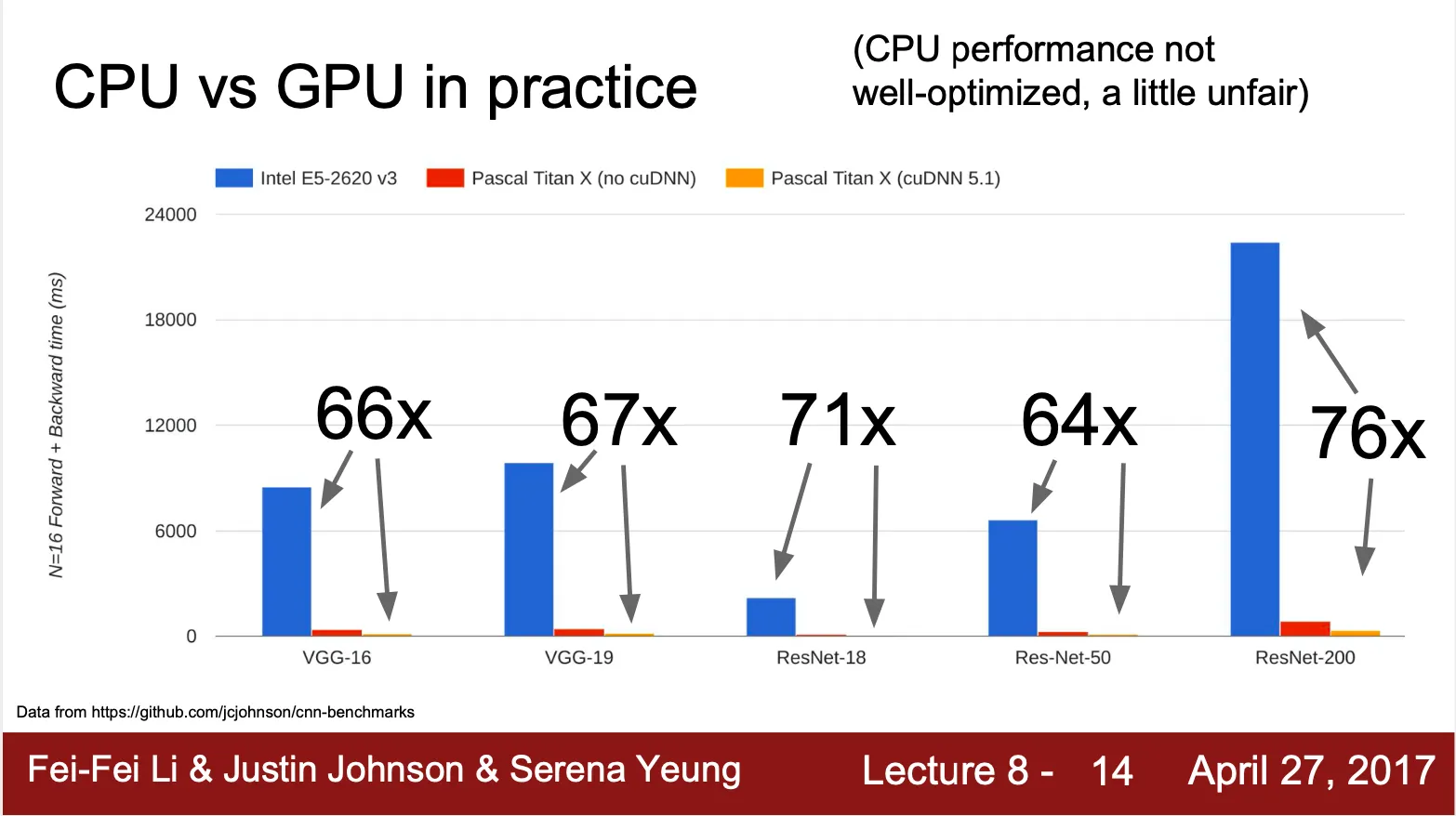
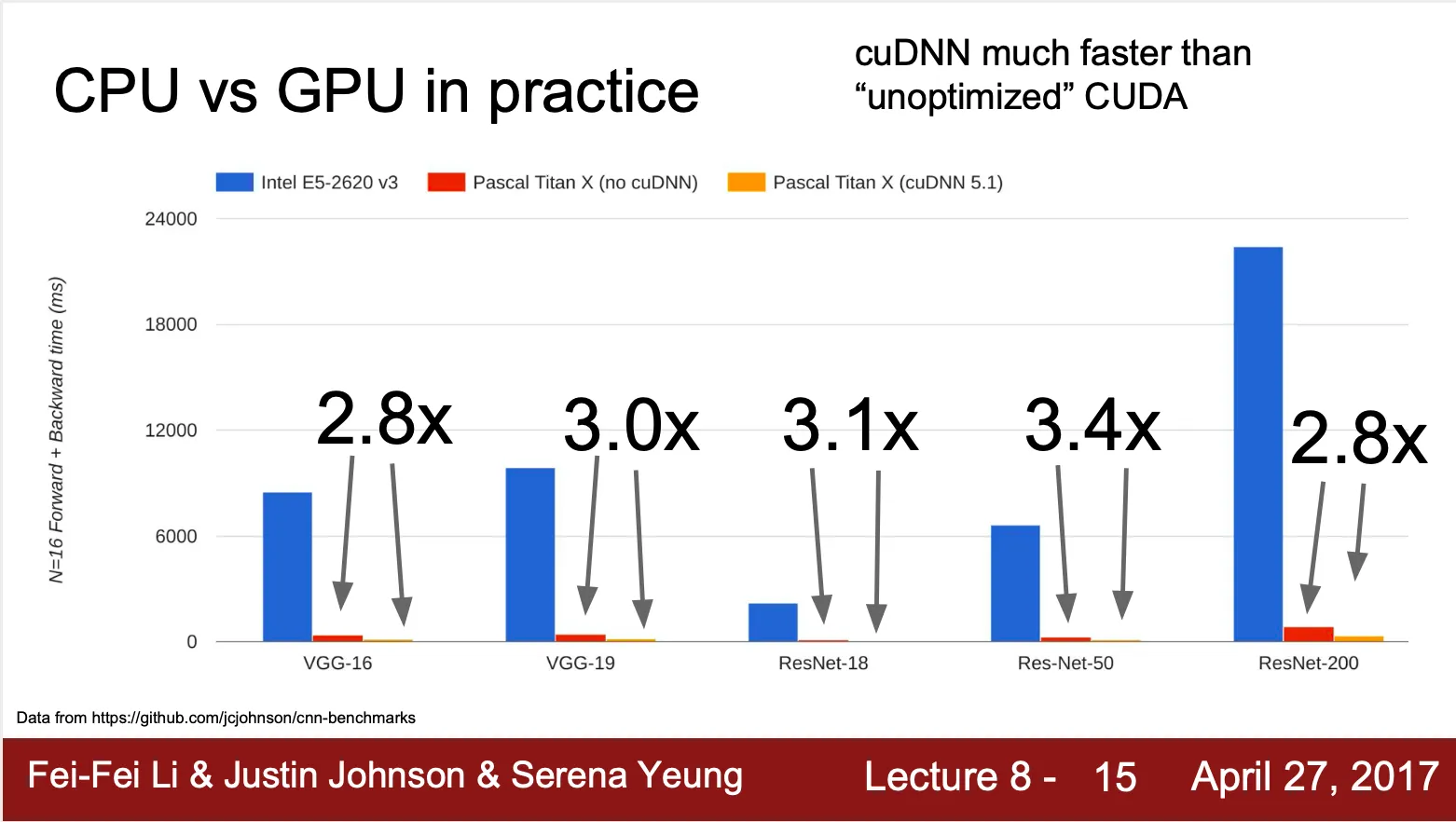
•
보통 학습은 GPU 에서 진행하는 반면, training data 는 SSD/HDD 에 저장되어 있기 때문에 GPU 와 CPU 간의 통신이 필요
◦
잘못하면 data 를 GPU 에 가져오는 것만으로도 bottleneck 이 생길 수 있음
◦
RAM 에 모든 데이터를 가져다 넣거나,
◦
HDD 보다는 SSD 를 사용하고,
◦
GPU 로 data 를 전달할 때 multithread CPU 를 사용하는 등의 방법이 필요할 수 있음
Deep Learning Frameworks
•
First generation deep leraning framework 는 아카데미에서 만들어지는 경우가 많은 반면 Second generation deep leraning framework 는 기업에서 만들어진 경우가 많음
◦
UC Berkely 에서 만든 Caffe 는 이후에 Facebook 에서 Caffe2 를 만듬
◦
NYU 에서 만든 Torch 는 이후에 Facebook 에서 PyTorch 를 만듬
◦
Montreal University 에서 만든 Theano 는 이후 Google 에서 TensorFlow 를 만듬
•
Deep learning framework 의 장점 ?
◦
크고 복잡하여 그릴수조차 없는 computational graph 를 쉽게 설계할 수 있음
◦
Computational graph 내부의 gradient 를 쉽게 계산할 수 있음
◦
GPU 에서 효과적으로 학습할 수 있도록 highly optimize 되어 있음 (cuDNN, cuBLAS 등)
•
Numpy 구현의 단점 ?
◦
CPU only
▪
TensorFlow → with tf.device('/gpu:0')
▪
PyTorch → .cuda()
◦
직접 하나하나 gradient 를 계산해야 함
▪
TensorFlow → tf.gradients()
▪
PyTorch → loss.backward()
TensorFlow
•
Computational graph 를 정의하는 부분과 graph 를 지속적으로 지나는 부분으로 나누어져 있음

•
graph 를 지속적으로 지날 때 numpy array 로부터 weight 를 복사하여 TensorFlow placeholder 에 집어넣고 다시 output 을 꺼내 numpy array 로 변환하는 과정 존재
•
이 과정에서 GPU, CPU 간의 통신이 필요한 점을 개선하기 위해 weight 를 TensorFlow 내부의 변수로 선언하게 됨

•
변화한 w 가 TensorFlow 내부 변수로 존재해야 하므로 assign 을 추가로 사용
◦
하지만, TensorFlow 는 불필요한 계산을 하지 않기 때문에 new_w1, new_w2 를 계산하는 것을 명시적으로 진행해야 함
◦
이를 output 으로 내게 되면, w_1, w_2 를 update 할 수는 있지만, 이러면 큰 tensor 인 CPU, GPU 간 통신에 w_1, w_2 를 copy 하는 작업이 또 다시 일어나게 되서 비효율적임
◦
이를 핸들링하기 위해 dummy node 를 만들고 dependency 로 w_1, w_2 를 두어 output 은 내지 않은 채 update 는 반영하는 trick 을 사용

•
predefined loss, optimizer, initializer 사용 가능
•
High level wrappers 사용 가능
◦
tf.layers
◦
tf.contrib.learn
•
Pretrained model 사용 가능
•
Tensorboard
◦
Loss, weight 등을 logging 하는 툴
•
Theano 는 TensorFlow 와 굉장히 유사
PyTorch
•
Tensor, Variable, Module 의 3체계로 이루어져 있음
◦
Tensor 는 TensorFlow 의 numpy array 에 해당
◦
Variable 은 TensorFlow 의 Tensor, Variable, Placeholder 에 해당
◦
Module 은 TensorFlow 의 high level wrapper 에 해당
•
Tensor 선언, forward pass, backward pass, gradient step 으로 나누어져 있음
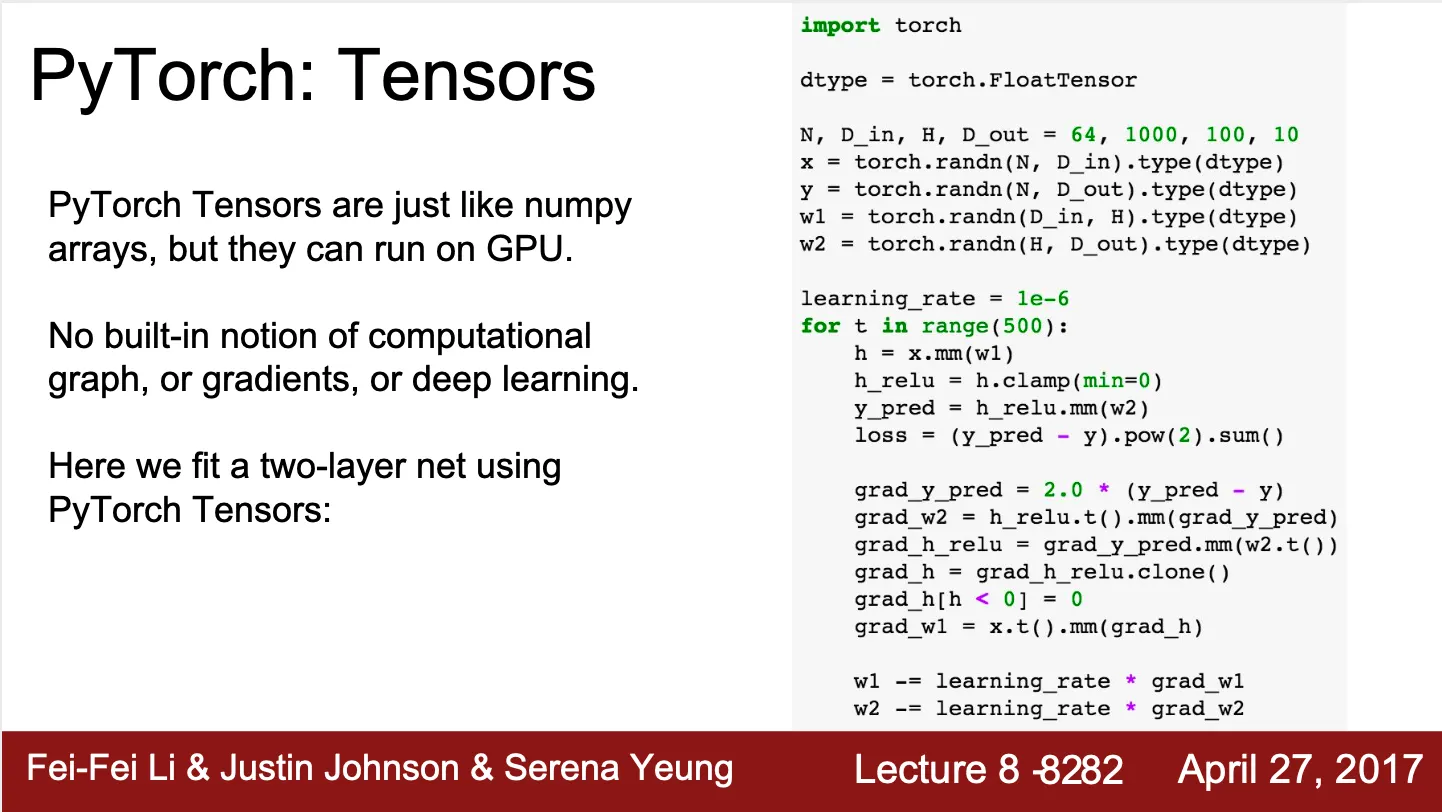
•
Autograd 지원
◦
loss.backward() 연산을 통해서 기존의 gradient 손수 계산을 대신할 수 있음
◦
해당 loss 연산을 완료하기까지의 forward pass 를 이용해 back propagation 을 진행하고 각 weight 의 grad attribute 에 계산한 gradient 값을 적재
◦
Custom autograd 를 선언하여 사용할 수 있음

•
Higher-level wrapper 인 nn 사용 가능
◦
모델을 쉽고 빠르게 구현할 수 있음
◦
nn Module 을 사용하여 custom 모델을 구현할 수 있음

•
Pre-defined optimizer 사용 가능

•
Mini-batch 구현에 용이한 DataLoader 사용 가능 (multithread)
•
Pre-trained model 사용 가능
•
Visdom
◦
TensorFlow 의 Tensorboard 같은 logging 툴
TensorFlow VS PyTorch
•
TensorFlow 는 static graph, PyTorch 는 dynamic graph
◦
TensorFlow 의 경우는 모델을 정의하면 재사용성이 좋고, 그 모델 그대로 구현 코드와 떼어낼 수 있는 장점이 있음
◦
PyTorch 는 동적으로 모델이 정의되기 때문에 conditional case 를 python code 로 구현할 수 있어 용이함 (특히, recurrent loop, recursive network 와 같은 경우)
Caffe
•
HDF5 나 LMDB 의 형태로 data 변환이 필요
•
Computational graph 정의에 코드가 아니라 prototxt 파일이 필요
◦
이를 만들기 위한 python 파일을 만들기도 하는데... ㅜㅜ
•
Solver prototxt 파일에 learning rate 나 optimization algorithm 등을 정의
•
Caffe binary 를 command 로 실행하여 train
•
Model zoo 사용 가능 (AlexNet 등)