




 Note Taking
Note Taking
Lecture 9 요약
•
AlexNet
◦
ILSVRC 2012 winner
◦
9 layers Conv network
◦
많은 computer vision 연구에 사용되는 CNN 의 근간이 됨
•
VGGNet
◦
ILSVRC 2014 second place
◦
16, 19 layers → 처음에는 11 layer 였는데 점점 늘려갔음
◦
Batch Norm 이 나오기 전 연구라서 깊은 네트워크를 학습하는데 어려움이 있었을 것
◦
filter 를 여러 개 쓰는 형태의 구조 (작은 Conv filter 여러 개가 큰 Conv filter 1 개보다 나음)
•
GoogLeNet
◦
ILSVRC 2014 winner
◦
22 layers
◦
Batch Norm 이 나오기 전 연구라서 깊은 네트워크를 학습하는데 어려움이 있었을 것
◦
Inception Module 을 사용하여 locally dense, globally sparse computation 을 진행
◦
Auxiliary classifier 를 사용하여 gradient 가 lower level 에도 전달될 수 있도록 함
•
ResNet
◦
ILSVRC 2015 winner
◦
Residual Block
▪
Shortcut connection 이 존재
▪
Shortcut connection 을 통한 identity mapping 연산 추가
▪
weight 가 모두 0 이면 연산은 identity
•
layer 가 필요 없는 경우를 상대적으로 쉽게 학습할 수 있음
•
L2 regularization 을 사용할 경우 일반적인 네트워크는 zero 방향으로의 과도한 이동이 weight 자체의 의미를 없애는 반면, ResNet 은 그 layer 가 필요 없음을 의미함
▪
Upstream gradient 를 안정적으로 downstream 으로 전달할 수 있음
•
DenseNet & FractalNet
◦
추가적인 shortcut connection 이 존재하여 ResNet 과 같이 안정적으로 gradient 를 전달할 수 있음
•
CNN Architectures
◦
VGGNet, AlexNet 은 parameter 수가 굉장히 많음
▪
이는 FC 의 지분이 큼
▪
ex) AlexNet 의 전체 62M 중 FC-6 에서 38M 을 가짐
◦
GoogLeNet, ResNet 은 FC 를 많이 제거하여 parameter 수를 줄임
RNN
•
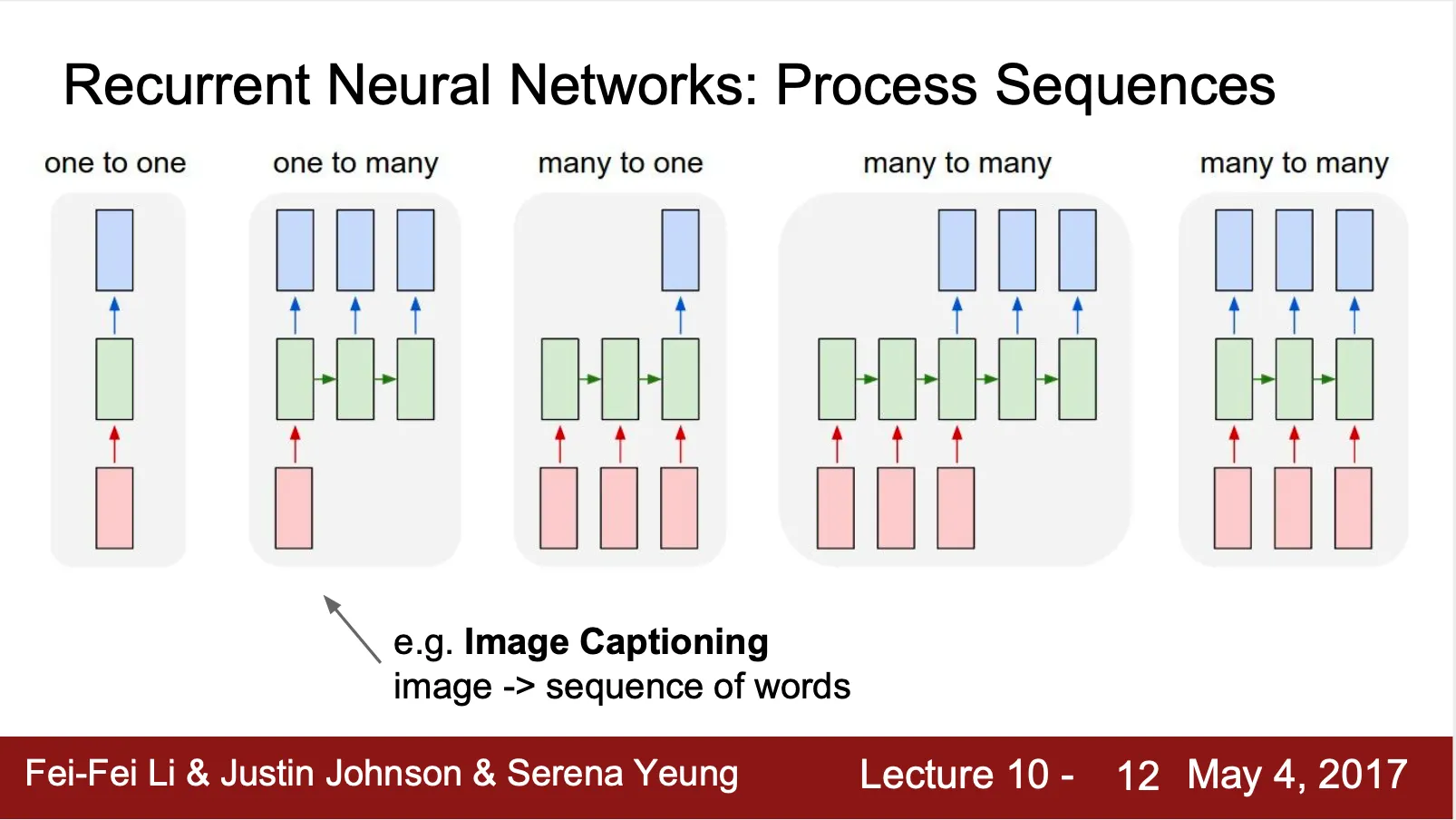
Vanilla Neural Networks 는 One To One Network (하나의 input 으로 하나의 결과)
•
모델이 가지는 프로세싱하는 데이터 타입의 유동성을 증가시키기 위해 다양한 네트워크가 등장
◦
One To Many
▪
Image Captioning (Image 를 잘 묘사하는 캡션 달기)
◦
Many To One
▪
Sentiment Classification (Word sequence 로 sentiment 분류)
◦
Many To Many
▪
Machine Translation (기계 번역)
▪
Video classification of frame level
◦
Non-Sequence data 로도 sequential processing 이 가능
▪
Image glimpse 를 sequence 하게 살펴보면서 최종 digit recognize
•
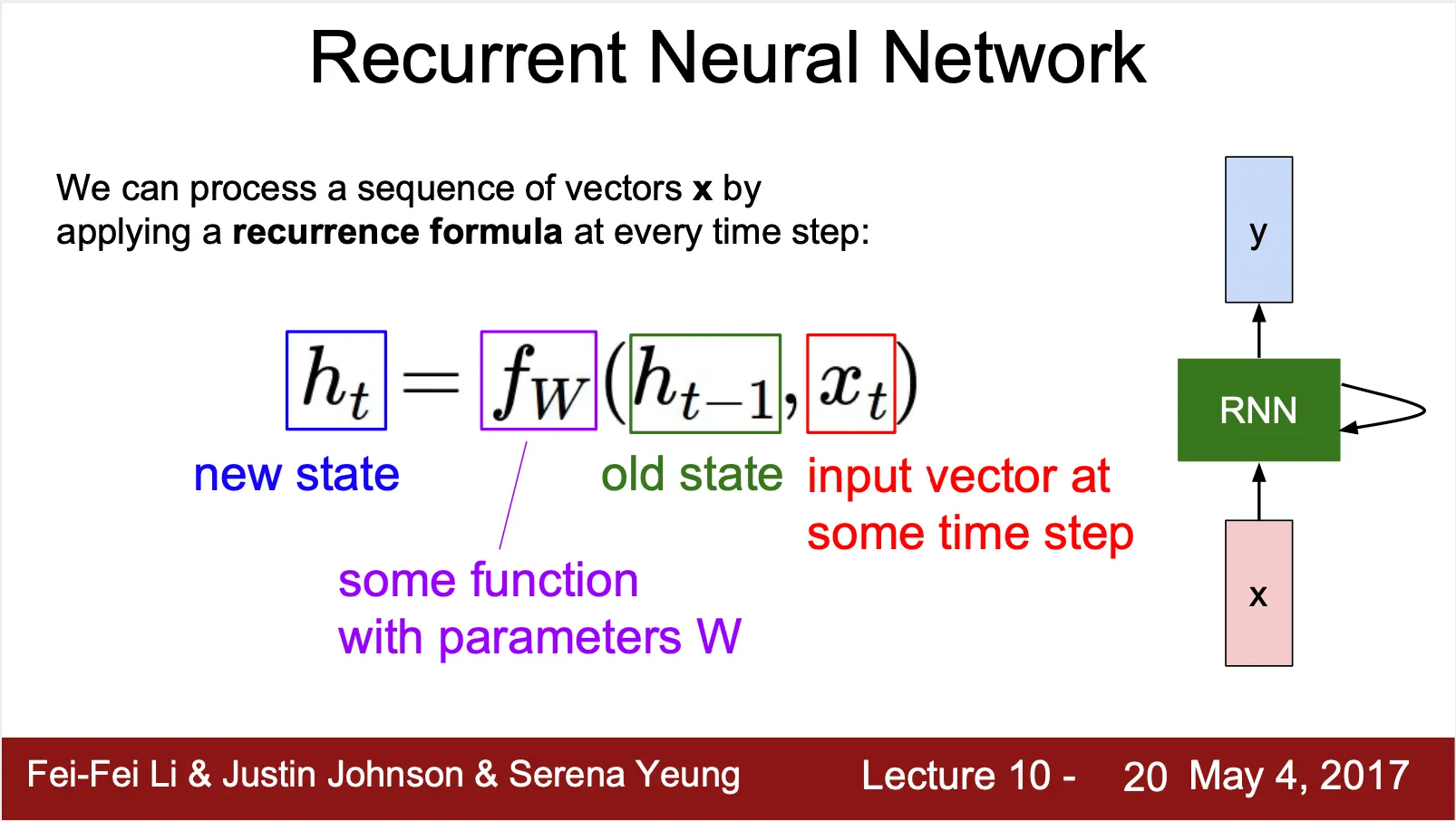
RNN ?
◦
Input 과 이전의 hidden state 를 받아 새로운 hidden state 와 output 을 내는 형태의 sequential network
•
Recurrence Formula ?
◦
▪
(score prediction)
◦
새로운 hidden state 는 이전 hidden state 와 input 과의 연산을 통해서 계산
◦
같은 step(한 번의 weight update 단위) 에서는 모든 recurrent cell 이 같은 weight 를 사용
•
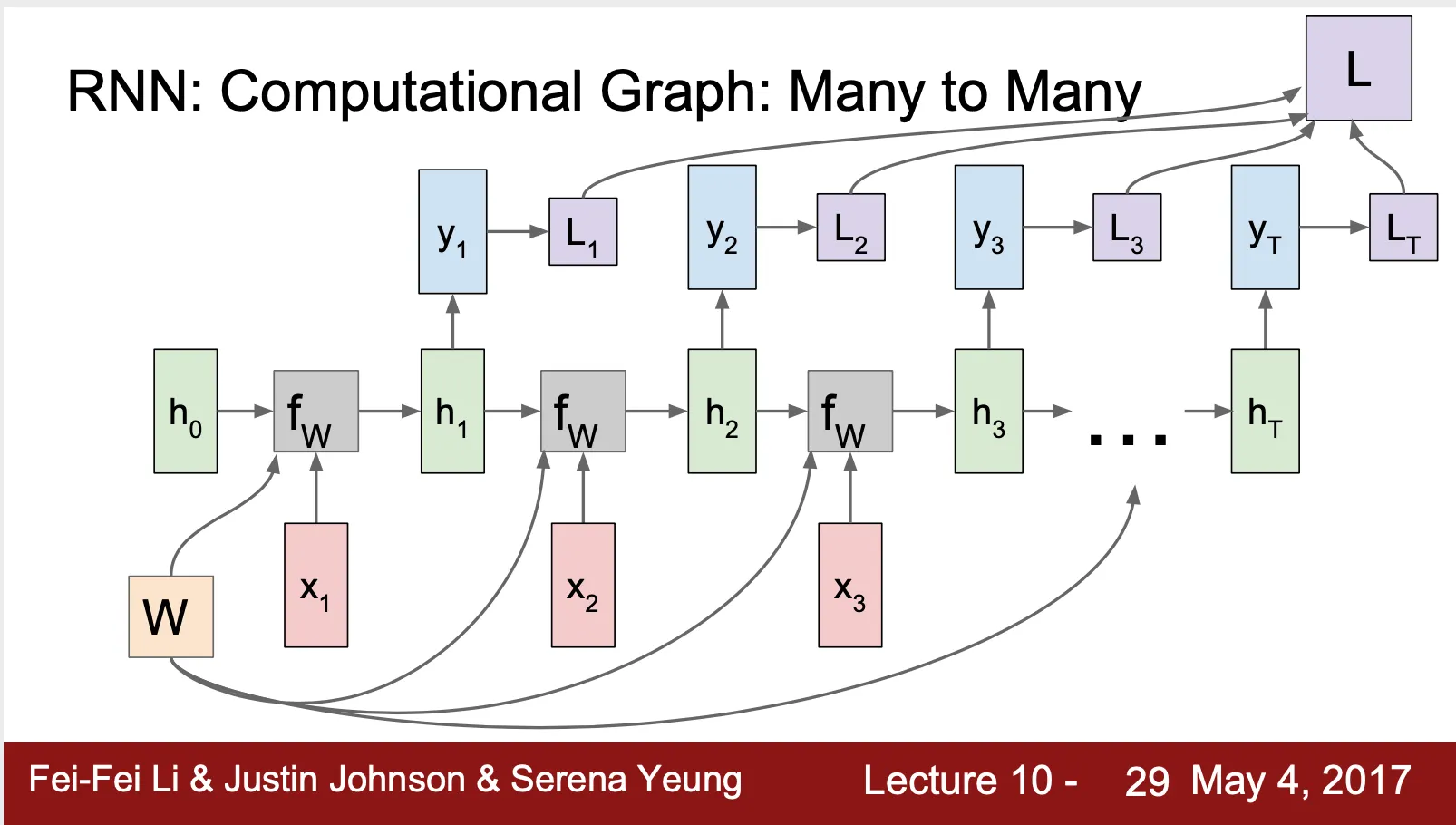
RNN: Computational Graph (Many To Many)
◦
RNN 의 표기는 recurrent connection 으로 간단하게 표현되었지만 실제 네트워크의 구조는 반복되는 recurrent cell 로 이루어져 있음
◦
RNN 의 back propagation 은 각 time step 에서의 L 에 대한 W 의 gradient 들의 합
▪
▪
▪
•
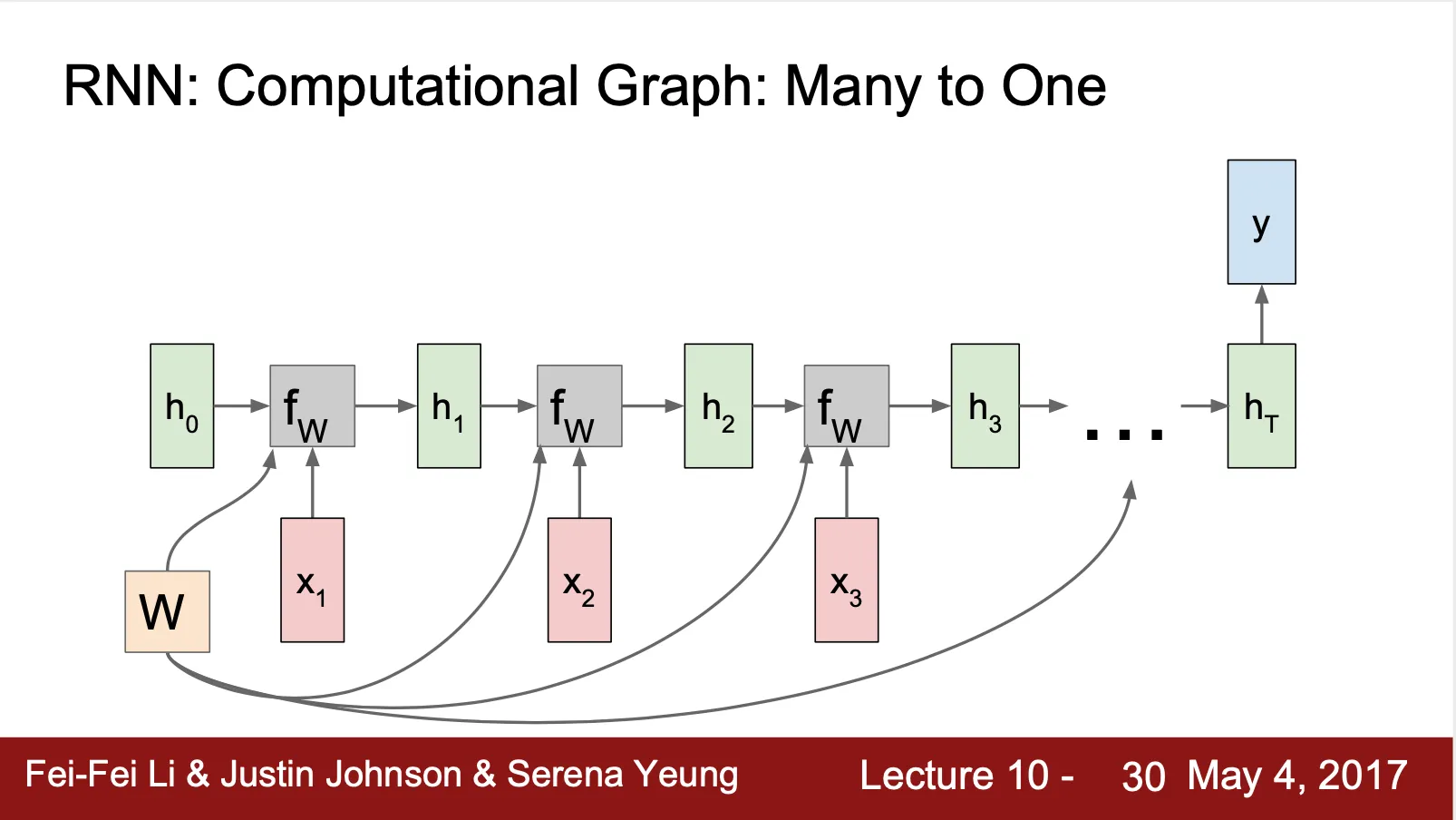
RNN: Computational Graph (Many To One)
◦
Final Hidden State 만으로 결과 산출
•
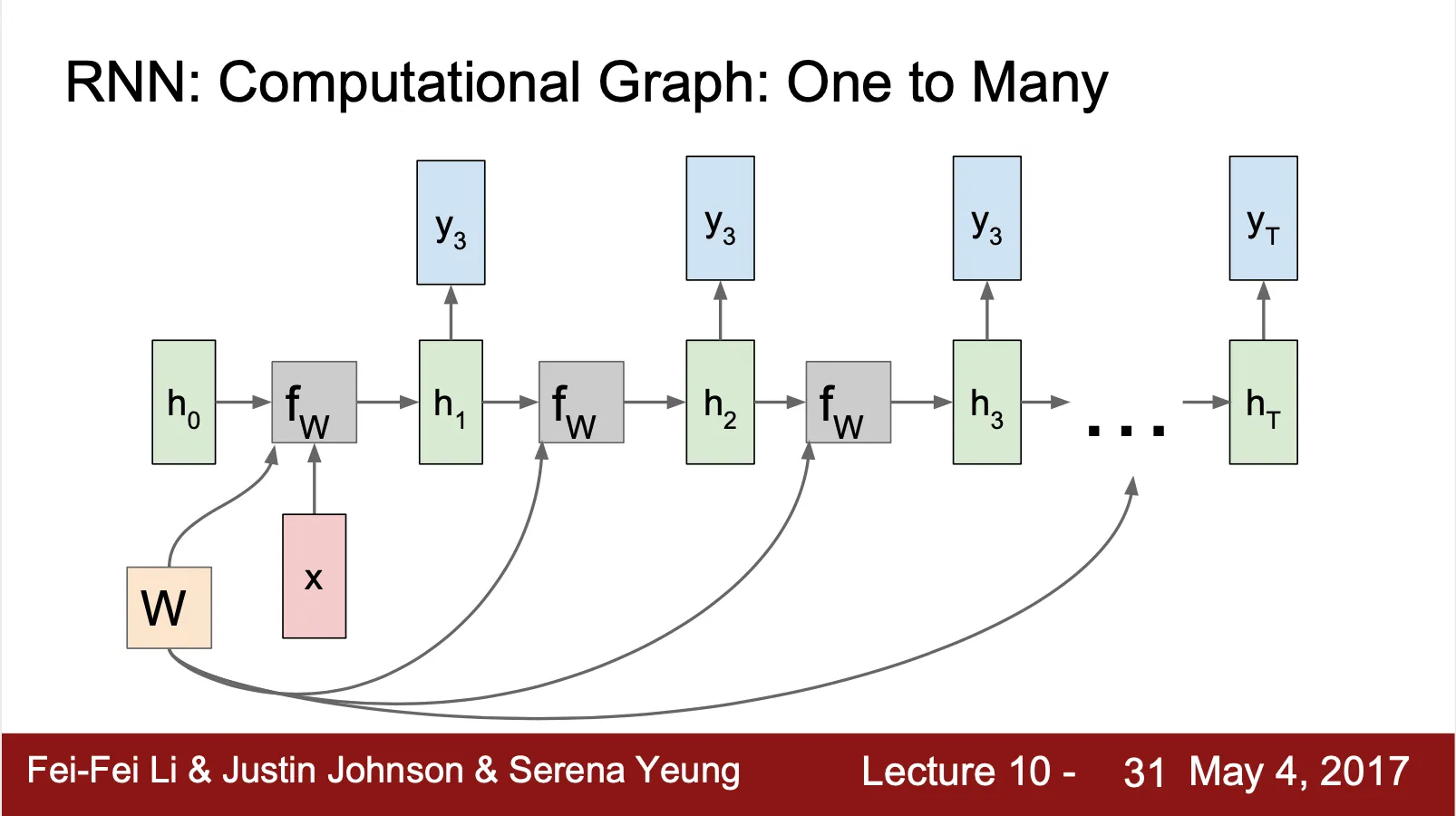
RNN: Computational Graph (One To Many)
◦
Initial cell 에만 input 사용
•
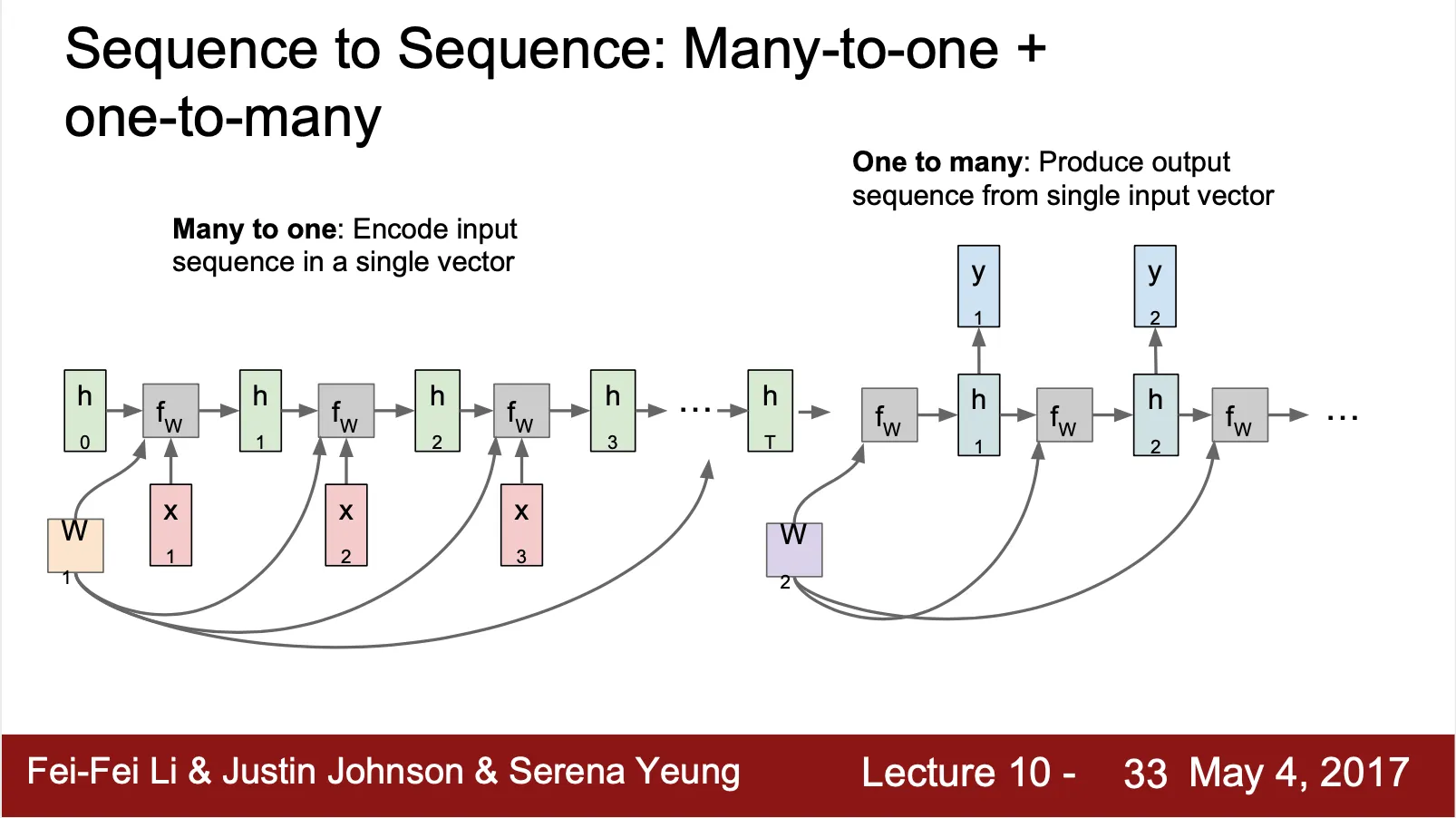
RNN: Computational Graph (Many To One + One To Many)
◦
Many To One (Encoder) + One To Many (Decoder)
◦
Input sequence 에 대한 feature 를 가지고 있는 vector 를 산출하는 encoder
◦
Feature vector 를 사용해서 output sequence 를 만들어 내는 decoder
◦
Many To Many 와의 차별점은 sequence data 의 전체적인 feature 를 capture 하여 output sequence 산출에 반영할 수 있다는 점
◦
Encoder 와 Decoder 의 weight 는 다름
•
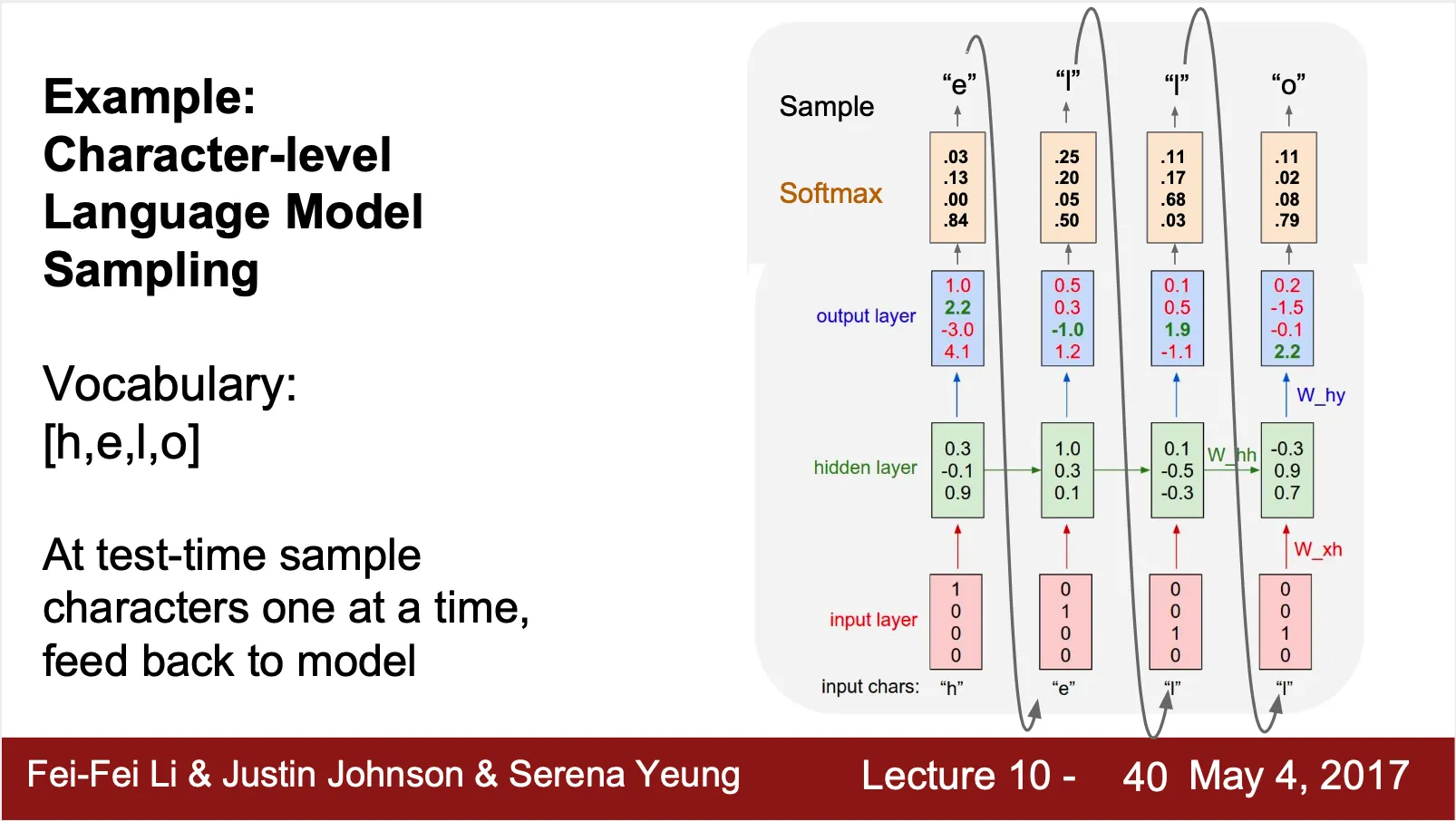
Example - Character-Level Language Model
◦
One-Hot Encoding 된 input vector
◦
Sofrmax 결과를 사용해 sampling 한 결과를 다음 recurrent cell 의 input 으로 사용
▪
Sampling 을 사용하면 Argmax 를 사용하는 것에 비해 다른 여러 종류의 그럴듯한 output 을 내는 장점이 있음
▪
Input 으로 사용할 때는 One-Hot Encoding 을 하여 입력
•
Softmax 결과를 그대로 사용하면 모델이 training 하기 굉장히 어려움 (특히 학습 데이터가 굉장히 많은 경우 - 사전의 단어)
•
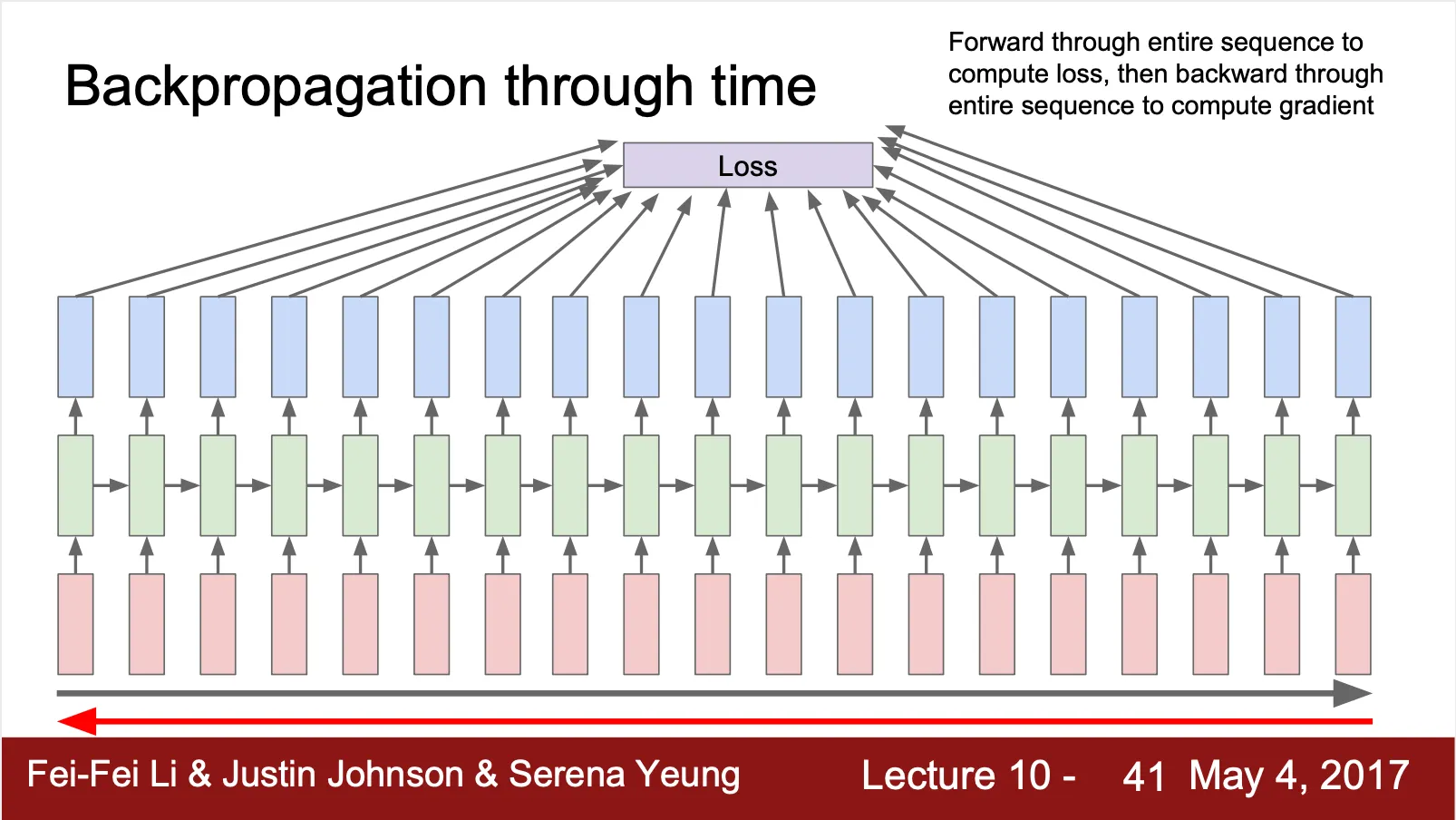
Back Propagation Trough Time (BPTT)
◦
각 recurrent cell 이 산출하는 결과들의 loss 합으로 Loss 를 구해 bacpropagation 하여 weight 를 update 하는 방법
◦
Sequence 가 굉장히 긴 경우, 매우 오래 걸리는 단점이 있음 (sequence 를 forward propagate 해가며 loss 를 구하고 이를 다시 back propagation 하여 update 해야 하기 때문)
•
Truncated Back Propagation Through Time
◦
같은 sequence 에 속하는 데이터라도, batch size 에 해당하는 결과만을 loss 를 구해 update 를 하는 방법
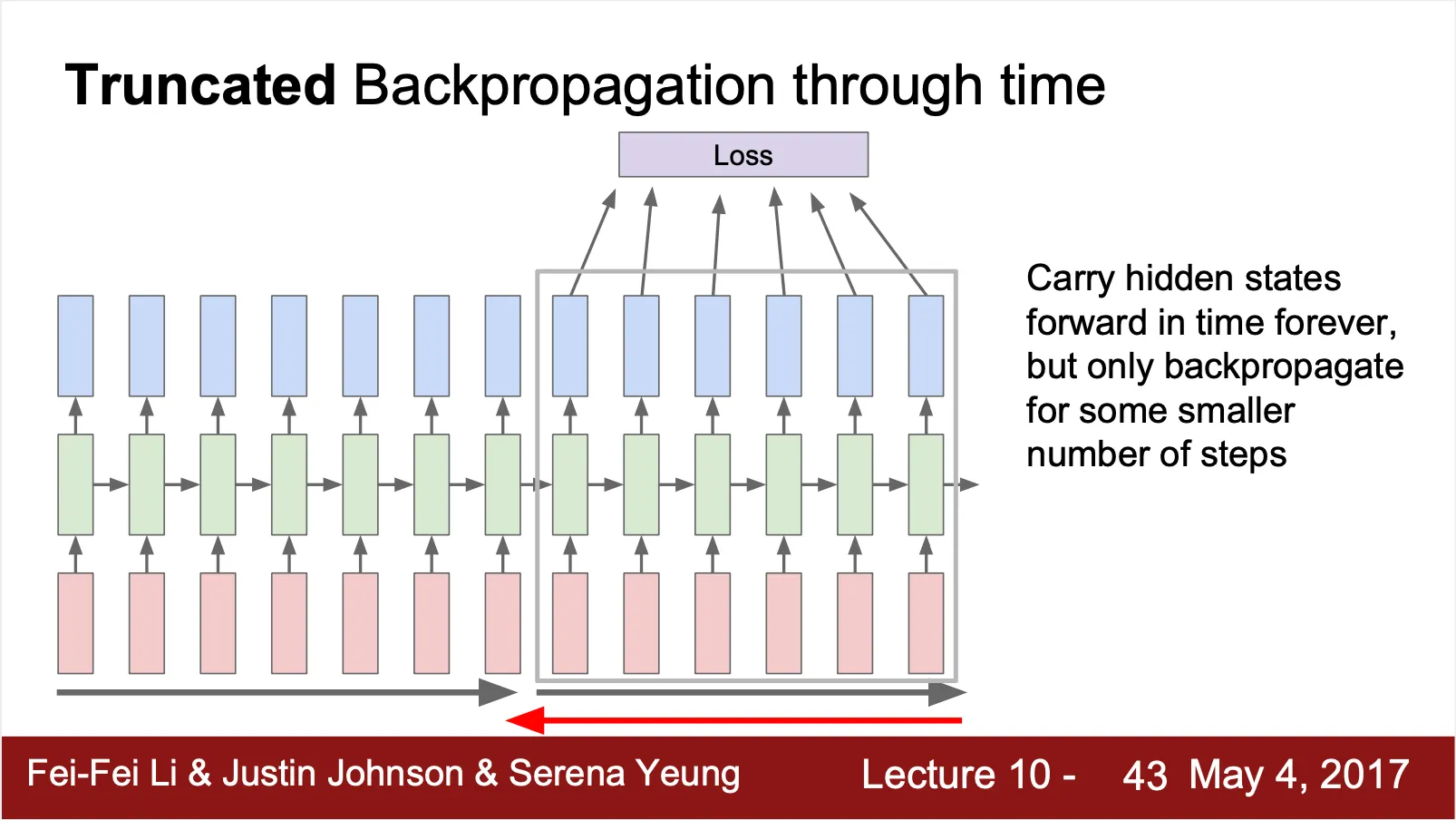
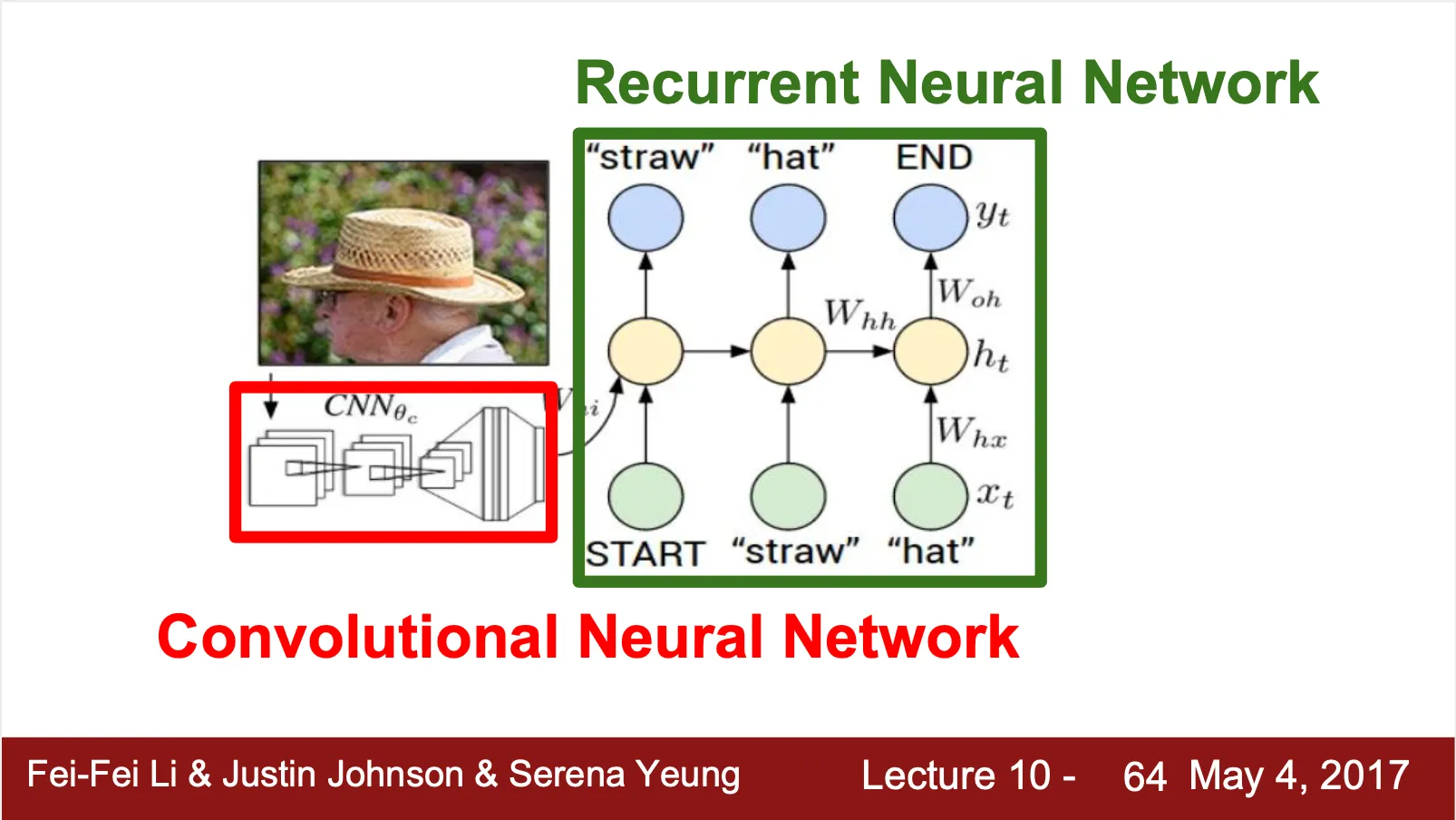
Image Captioning
•
CNN + RNN 의 네트워크 구조
◦
CNN 이 image 에 대한 feature vector 를 산출하고, RNN 이 그 feature vector 를 사용해 caption words 를 sequential 하게 생성
•
Inference time 에서 일어나는 일 ?
◦
CNN 에서 feature vector 를 산출해준 이후, 이 feature vector 를 표현하는 matrix 를 각각의 RNN cell 모두에서 사용
◦
◦
END token 이 나오면 sequence 를 멈춤
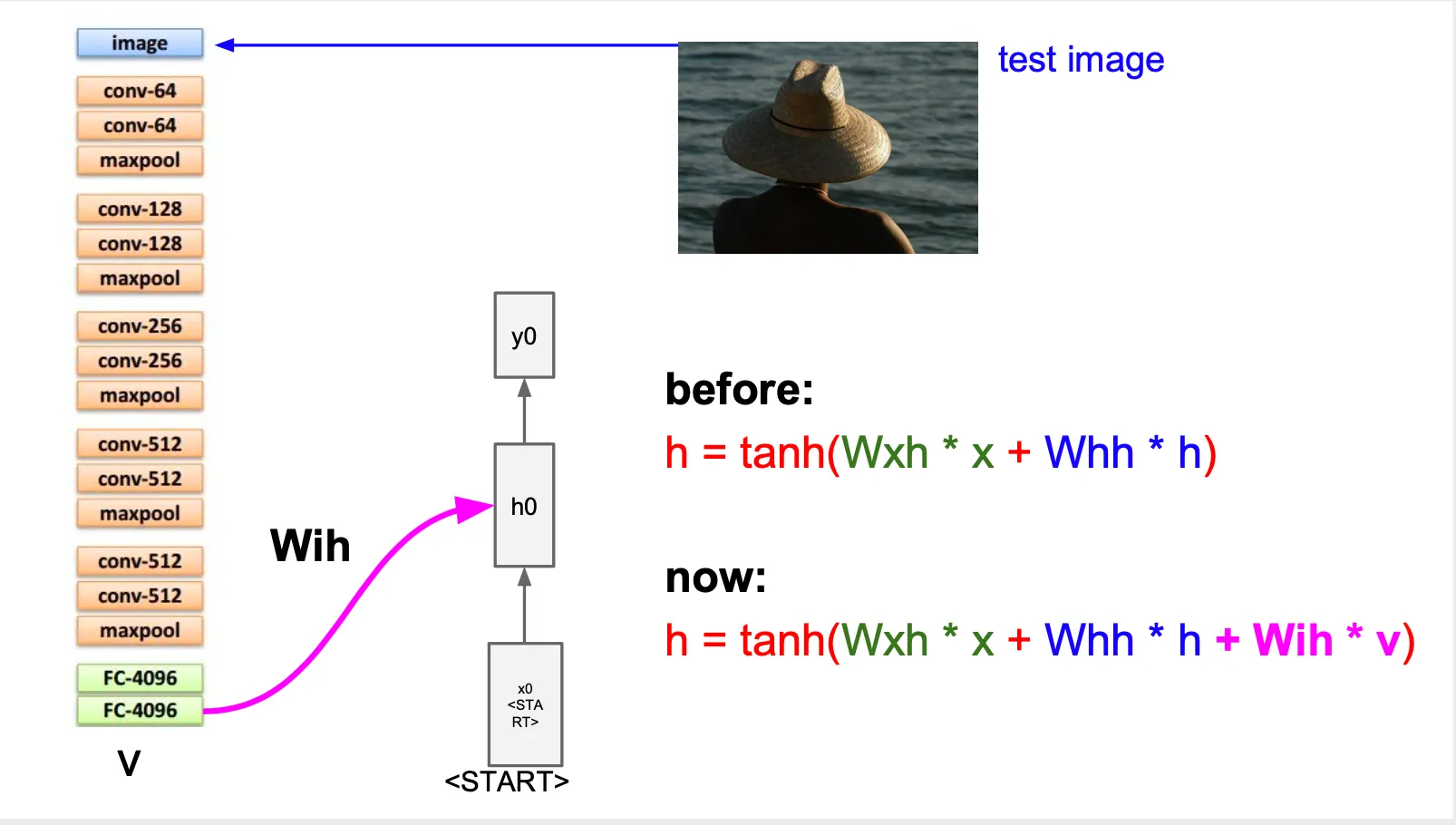
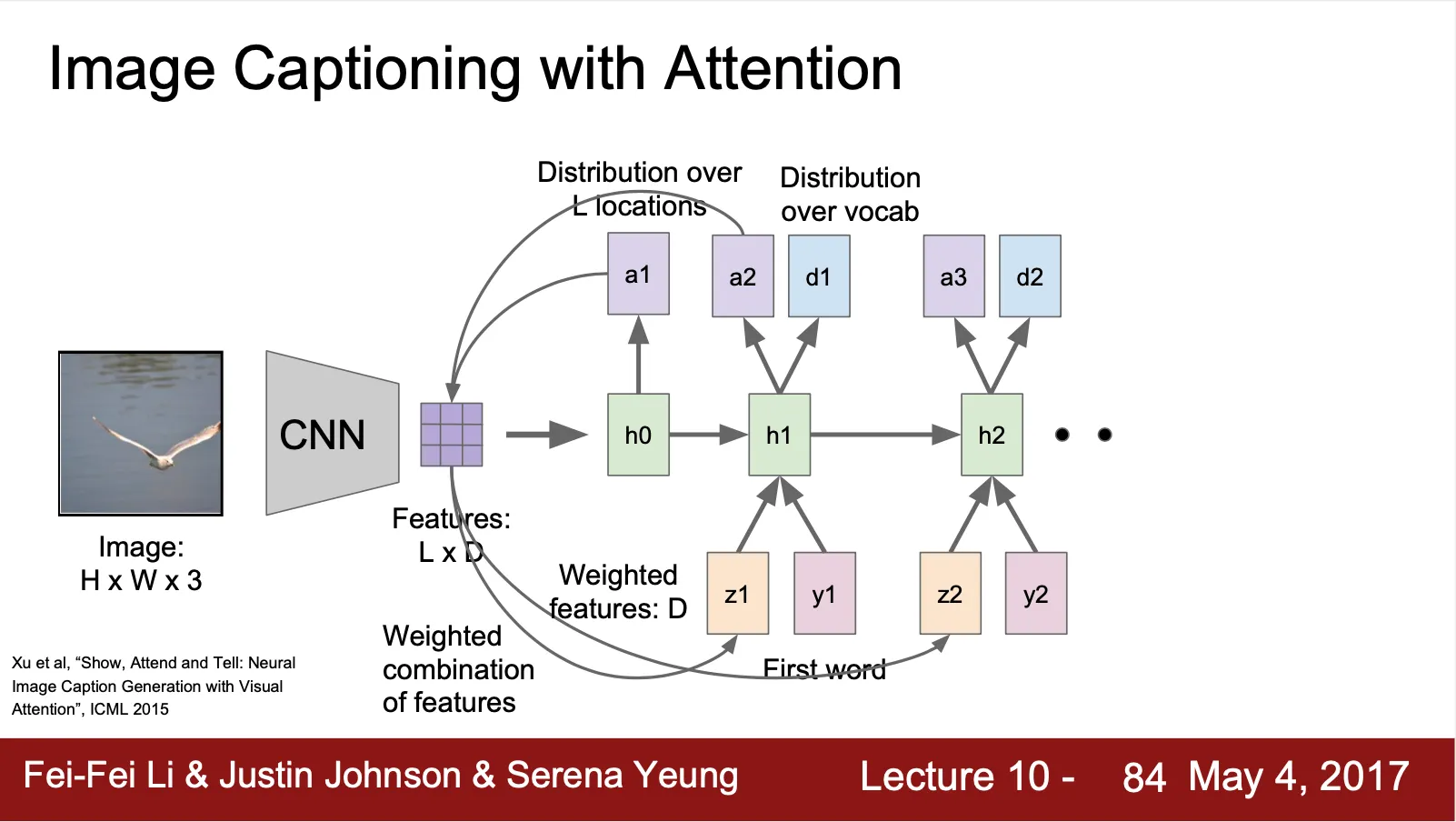
Image Captioning with Attention
•
CNN 이 single vector 를 산출하는 것이 아니라 grid vector 를 산출
(ex. 이미지 location 당 하나의 vector)
•
각 time step 마다 vocabulary 를 sampling 하여 산출하는 것 이외에도 이미지 내에서 살펴볼 영역에 distribution 또한 산출
•
산출한 distribution 과 특정 summary vector 의 sum of product 로 새로운 input vector 를 생성하여 sampling 한 vocabulary 와 함께 다음 sequence 로 넘겨줌
Various Computer Vision tasks using RNN
•
Visual Question Answering
◦
문제와 그 답변의 객관식 문항에서 가장 알맞는 답변을 선택해주는 기능
•
Visual Question Answering: RNNs with Attention
◦
질문의 sequence 와 image 를 각각 RNN 과 CNN 으로 받아 산출된 vector 를 combine 하여 최종적으로 answer 의 distribution 을 산출
LSTM
•
Vanilla RNN Gradient Flow 의 문제점
◦
가 지속적으로 matrix multiplication 되는 형태로 loss 가 계산되기 때문에 Back Propagation 시 가 지속적으로 곱해짐 (같은 값이 지속적으로 곱해지는 효과이기 때문에 Gradient Exploding/Vanishing 이 발생할 가능성이 높음)
◦
Largest singular value > 1 → Gradient Explode
▪
Gradient Clipping 기법을 사용해 어느정도 해결 가능
(Gradient Norm 이 threshold 보다 커질 경우 각 gradient 를 threshold/gradient norm 만큼으로 나누어주는 방법)
◦
Largest singular value < 1 → Gradient Vanishing
•
Gradient Vanishing 을 해결하는 구조를 고안한 것이 RNN
◦
두 개의 state 인 를 가짐
▪
는 cell state
▪
는 hidden state
◦
이전의 hidden state 와 현재의 input, 그리고 weight 를 이용하여 4 개의 gate, 를 만들어냄
▪
는 input gate 로 얼마나 input 의 요소를 cell state 에 반영할지를 결정하는 요소
▪
는 forget gate 로 얼마나 이전 cell state 의 값을 현재 cell state 에 반영할지를 결정하는 요소
▪
는 output gate 로 얼마나 현재 cell state 의 값을 output hidden state 에 반영할지를 결정하는 요소
▪
는 gate gate(?) 로 input vector 를 대변하는 요소
◦
현재의 cell state 는 gate 와 이전의 cell state, hidden state, 그리고 현재의 input 으로 연산
▪
◦
현재의 output hidden state 는 gate 와 cell state 로 연산
▪
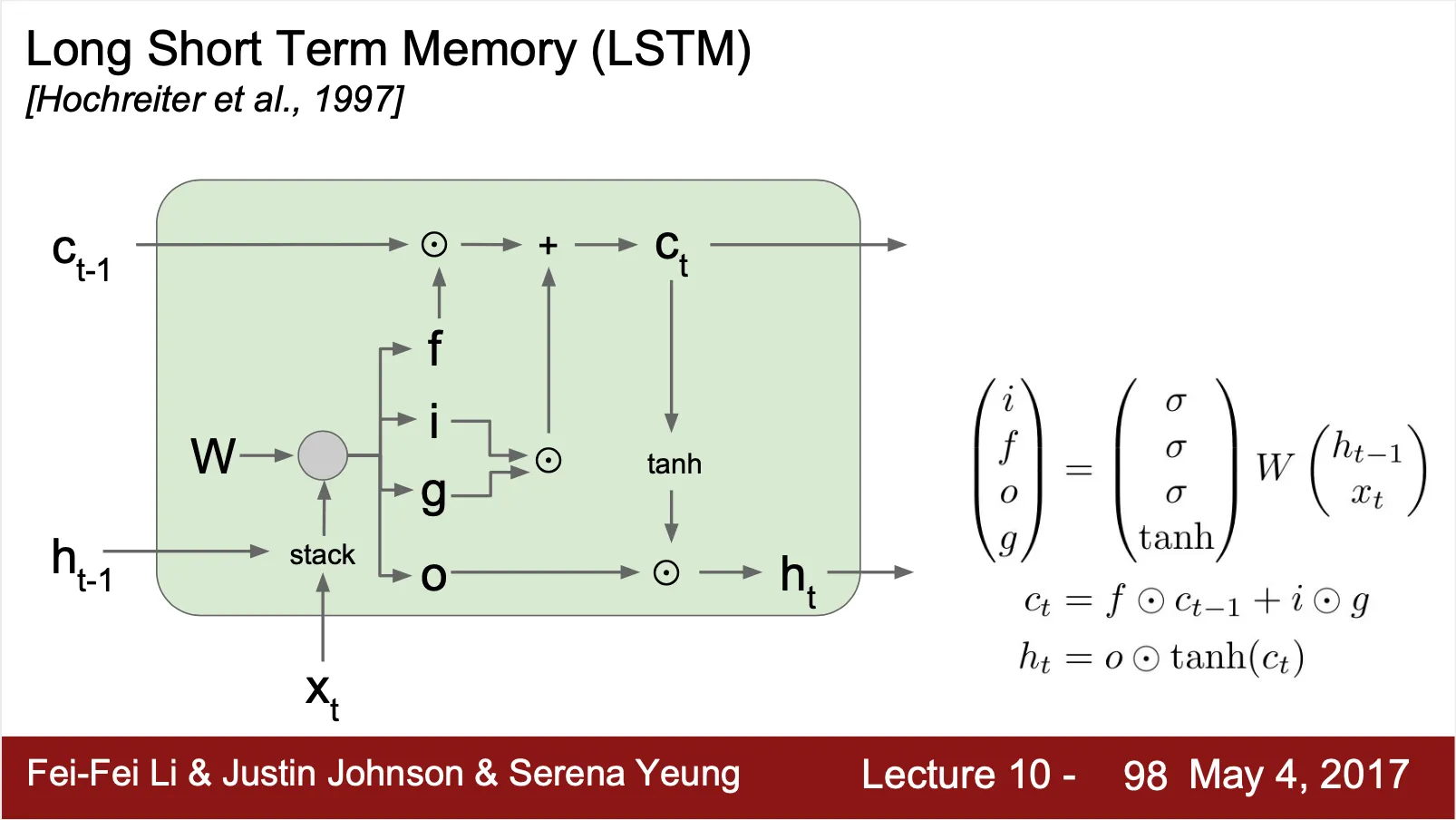
•
Forget gate 가 elementwise multiplication 이고 이것이 현재의 cell state 에 합 연산으로 연결되어 있기 때문에 cell state 경로를 따라서 uninterrupted gradient flow 가 형성됨 (ResNet 과 유사)
•
Vanilla RNN 에서는 무조건 tanh 를 타야만 이전 cell 로 들어갈 수 있지만, LSTM 에서는 그렇지 않음
•
GRU (Gated Recureent Unit) 는 LSTM 과 유사한 구조를 가지고 있음