




 Note Taking
Note Taking
Lecture 10 요약
•
RNN
◦
Input 과 이전 단계의 Hidden State 를 사용해 이번 단계의 Hidden State 를 연산
◦
◦
◦
일반적인 형태는 One Input One Output 이나, One To Many, Many To Many 도 가능
◦
Back Propagation Through Time (BPTT)
▪
각각의 Output Loss 를 모두 더해 하나의 Total Loss 로 정의하여 back propagation
▪
loss 로부터 특정 weight 로 갈 수 있는 path 가 다수인데, gradient 가 더해지는 형태로 계산
▪
Sequence 가 길 수록 느림
•
LSTM
◦
RNN 이 가진 Long Term Dependency Problem 을 해결한 형태의 네트워크
▪
RNN 의 각 timestamp 마다 W를 재활용하는데, W 가 지속적으로 곱해지는 효과
▪
W의 Largest Singular Value 에 따라 gradient exploding, gradient vanishing 발생
▪
이전 단계로 이동하려면 Tanh 를 타야만 하는 기존의 RNN 과는 다르게 Cell State path 가 생겨남
Semantic Segmentation
•
이미지 각 픽셀의 class 를 도출해내는 task (classification for each pixel of image)
•
instance 를 구별해내지는 않음
◦
두 마리의 소가 붙어 있는 경우 소의 경계면을 알아낼 수는 없음
•
FIrst Approach - Sliding Window
◦
Image crop 을 잘라내서 각 cropped image 의 중앙 pixel 의 class 에 대한 classification 진행
◦
매우 비쌈
▪
각 pixel 의 class 를 명시해야 함
▪
cropped image 를 사용한 convolution 연산에 중복이 많음 (낭비되는 연산)
•
Second Approach - Fully Convolutional
◦
Full Convolutional Layer (No FC layer) → Activation Map 의 size 가 줄어들지 않음
◦
: classification class 수
◦
: output tensor size
◦
Cross Entropy Loss on every pixel
◦
매우 비쌈
▪
Conv Filter 의 개수가 64, 128, 256 되면서 굉장히 연산 수 및 메모리 다량 사용
•
Third Approach - Fully Convolutional + Downsampling & Upsampling
◦
깊은 네트워크를 낮은 spatial dimension 영역에서 구현할 수 있기 때문에 효율적임
◦
Downsampling
▪
Strided Convolution
▪
Pooling
◦
Upsampling
▪
Unpooling
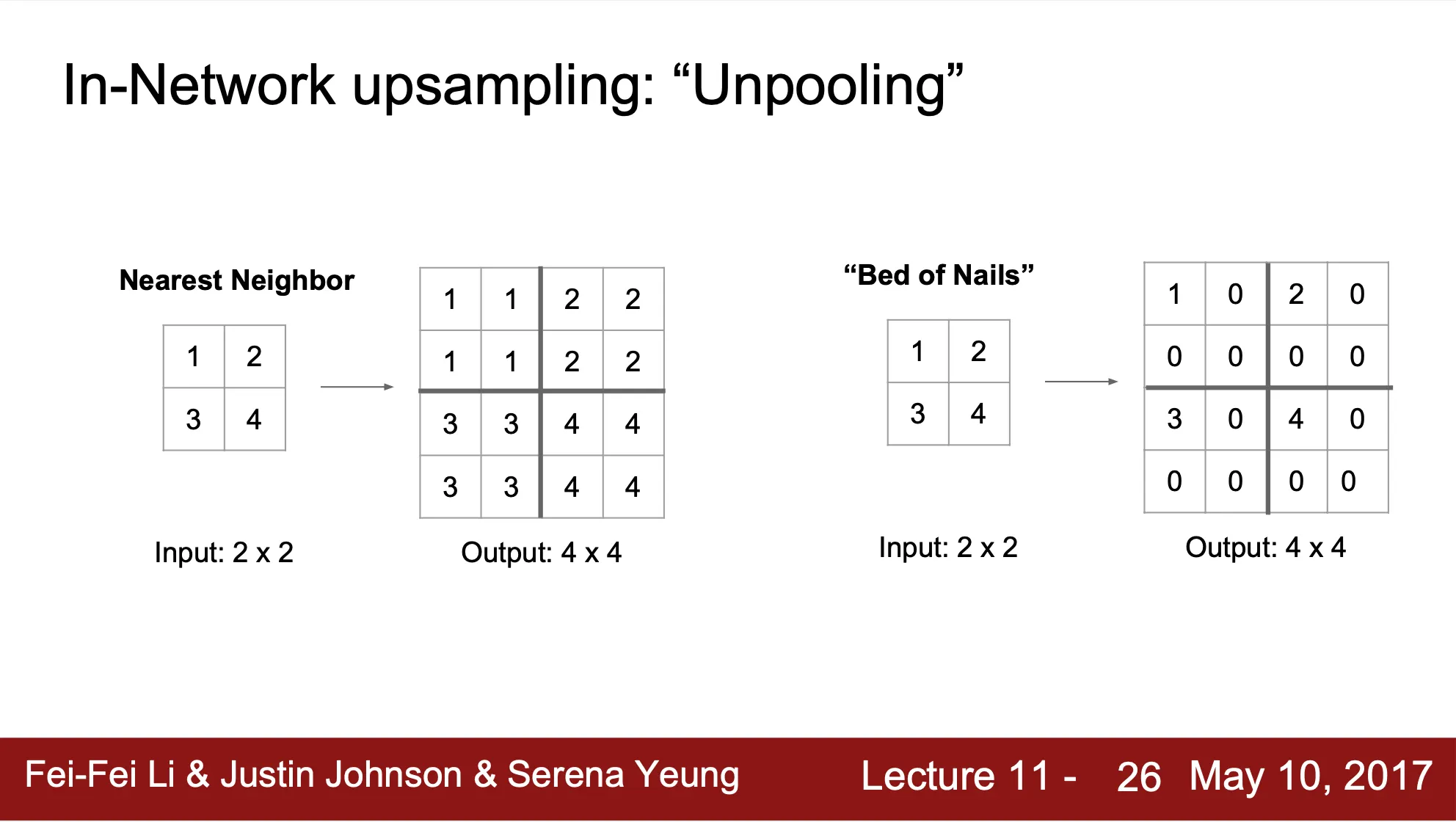
•
Nearest Neighbor Unpooling
주변 영역을 자신과 같게 확장
•
Bed of Nails Unpooling
좌상단을 본인으로 유지 후 나머지 0 으로 채워 넣음
•
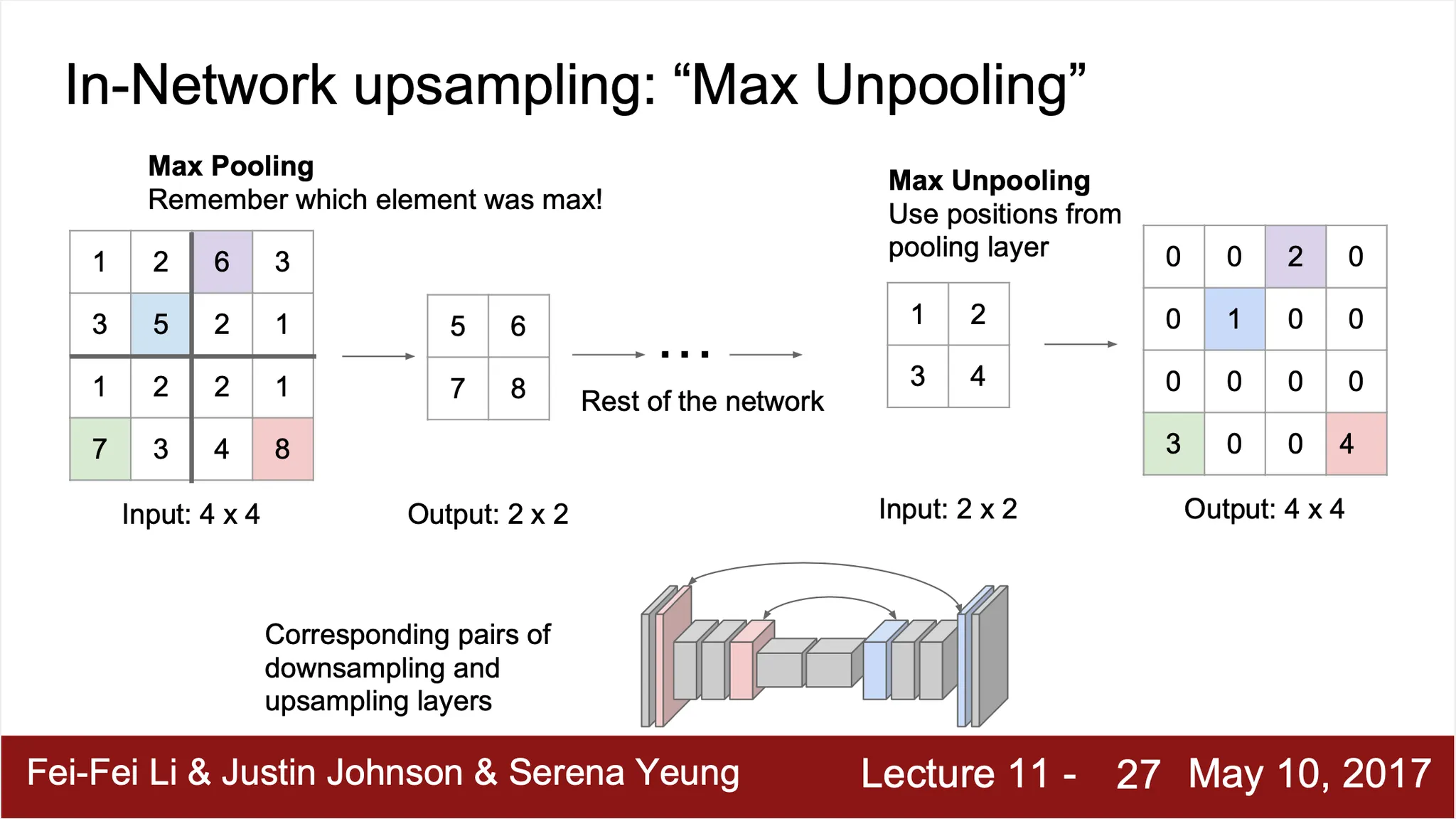
Max Unpooling
Pooling 단계에서 선택되었던 지점으로 본인을 위치하고, 나머지 0 으로 채워넣음
▪
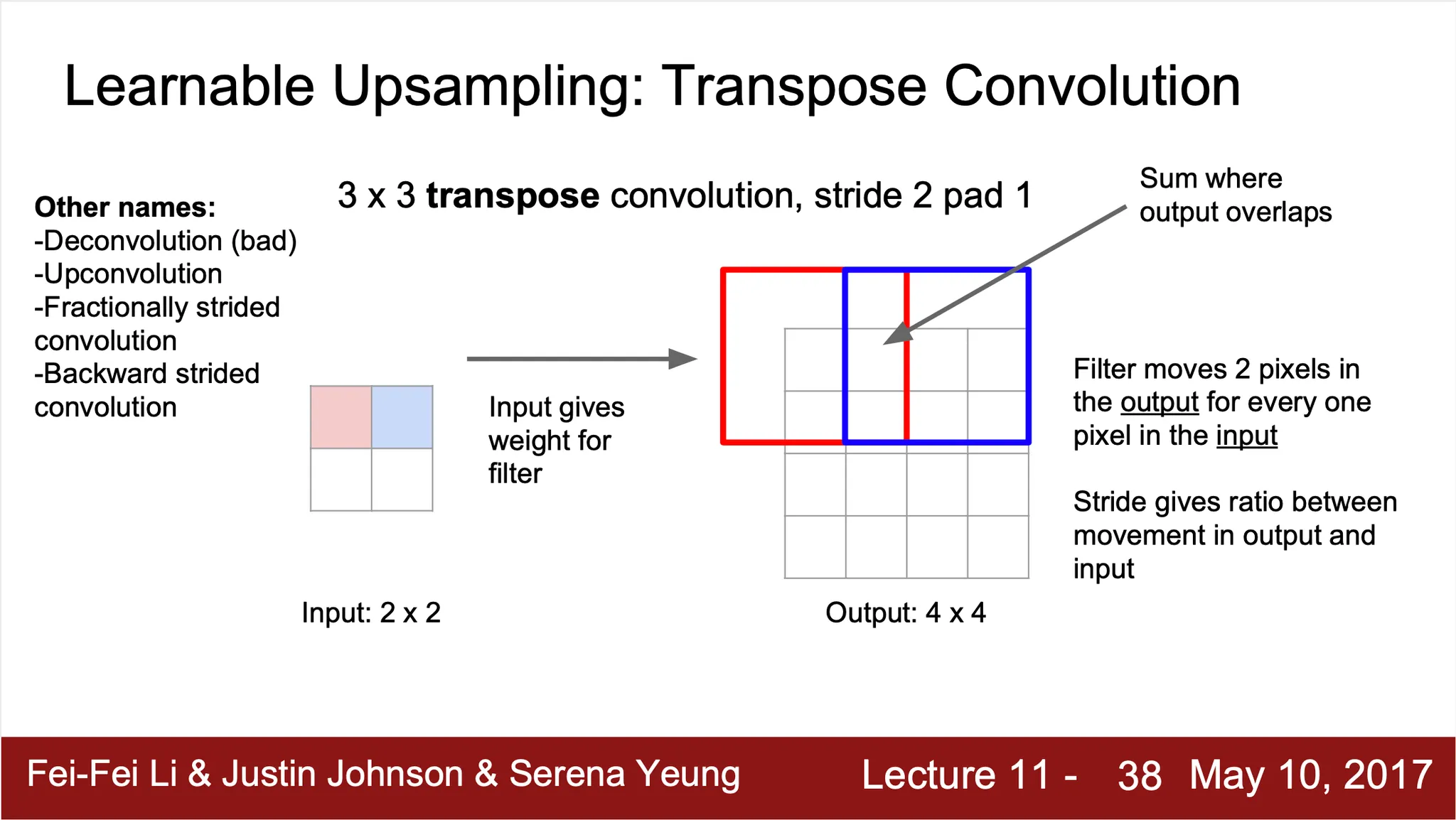
Transpose Convolution
•
Dimension 을 확장할 수 있는 learnable layer (Strided Convolution 의 reverse 버전)
•
kernel 전체에 해당 input 한 pixel 을 곱해서 kernel 이 포함하는 영역을 채워넣음
Classification + Localization
•
이미지의 category 뿐만이 아니라, 그 category 의 물체가 이미지 속에서 어디 있는지도 찾는 task
•
이미지 속에서 하나의 object 가 located 되어 있다고 가정하고 진행
•
Multitask Problem
◦
Image 를 summarizing 하는 vector 로부터 2 개의 다른 fully connected layer 가 존재

◦
하나의 fully connected layer 는 class 를
◦
다른 fully connected layer 는 bounding box coordinate 를 산출
◦
두 loss 를 조절하는 weighting parameter 를 설정해야 함
▪
이 친구가 굉장히 특이한 것이, 다른 hyperparameter 와 다르게 이 친구의 변경이 loss 자체를 바꾸기 떄문에, 조절해가며 loss 를 관찰하는 것으로 부터 좋고 나쁨을 판단하기 어려움
◦
같이 학습하는 이유는 big network 의 fine tuning 효과를 얻기 위함
•
Coordinate 산출이라는 점에서 Human Pose Estimation 문제와 비슷하게 볼 수 있음
Object Detection
•
다수의 object 에 대한 classification + localization task
•
First Approach - Sliding Window
◦
Image crop 에 대한 background class 를 포함한 classification (Conv Network)
◦
Crop 선정을 할 기준이 없음...
Brute force 로 Sliding Window 를, 가능한 다양한 크기의 bounding box region 에 대해서 진행하기에는 computationally intractable
•
Selective Search (Region Proposal)
◦
Crop 선정을 할 기준
◦
전통적인 Signal Processing / Image Processing 테크닉
◦
Object 가 존재할만한 bounding box 를 찾아줌
•
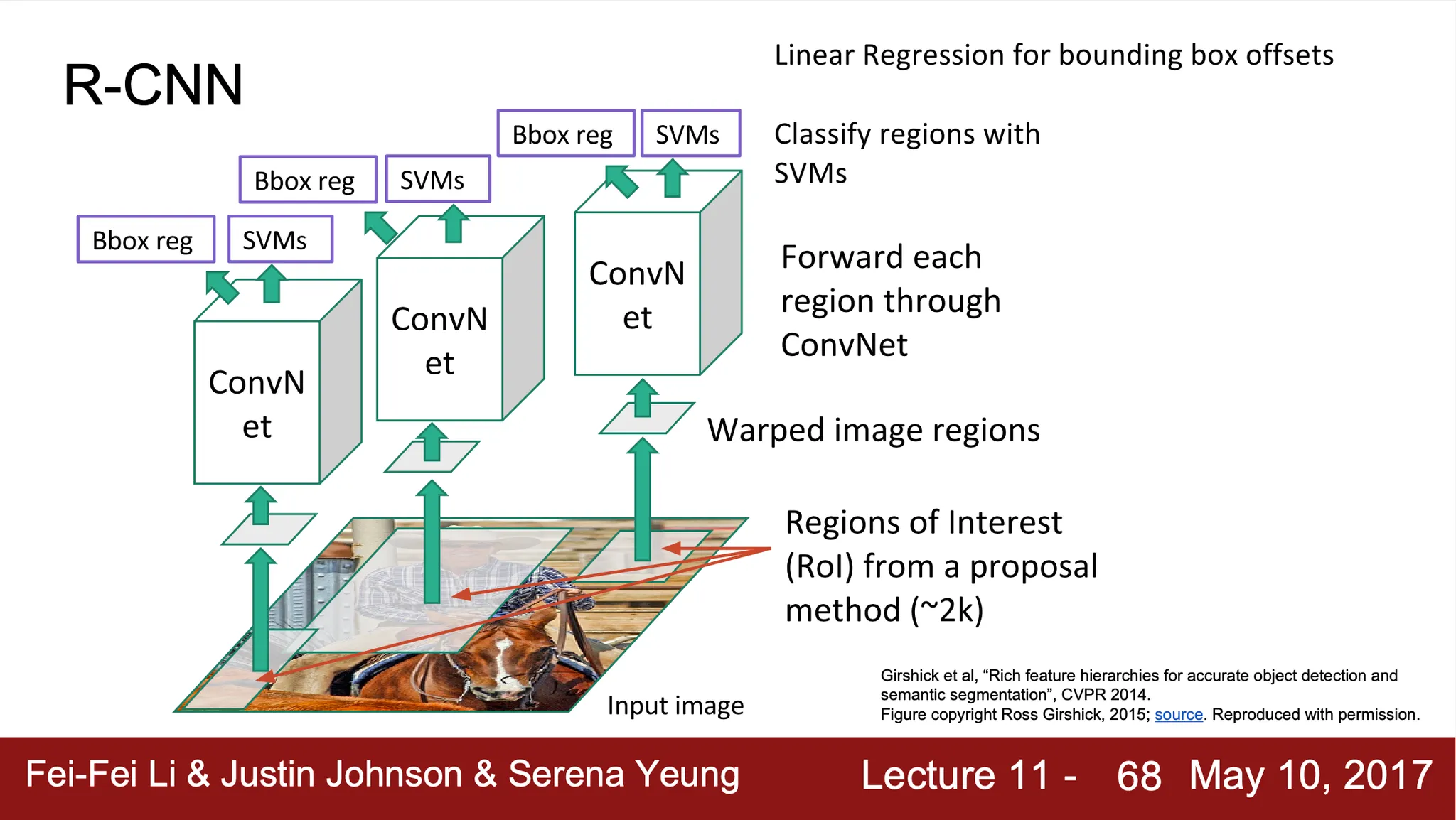
R-CNN
◦
Selective Search 로 Region Proposal 을 뽑아줌 (~2000 regions)
◦
Image region 을 같은 ConvNet 로 학습시키기 위해서 동일한 크기로 warp
◦
Warp 한 이미지를 ConvNet 으로 통과시킨 후 SVM loss 로 학습
◦
여전히 computationally expensive
◦
Regional Proposal 이 고정되어 있음
◦
Inference time 도 느림
1000 개 가량의 regional propsoal 에 대한 forward propagation 을 진행해야 하기 때문
•
Fast R-CNN
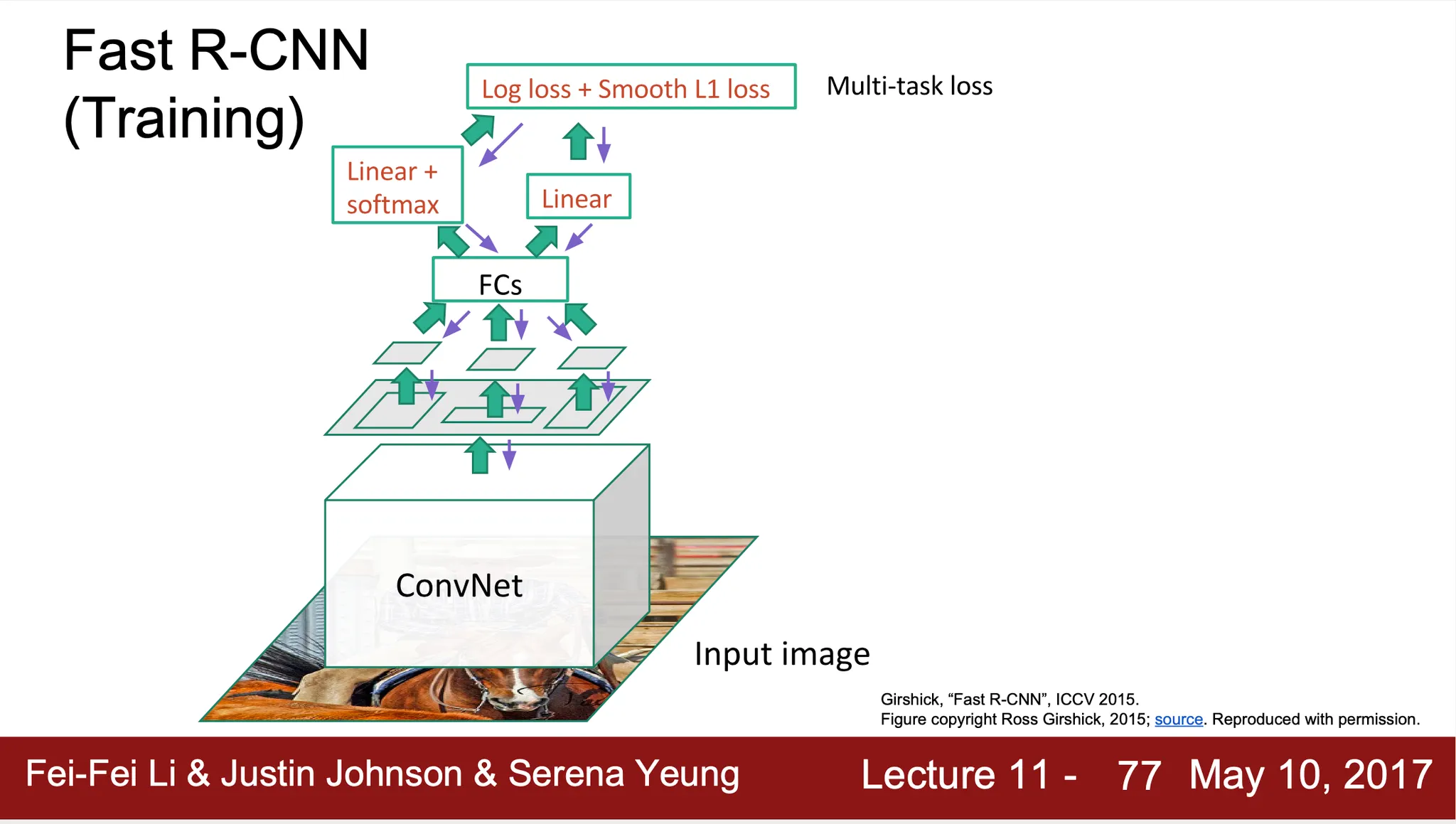
◦
Convolutional Layer 를 먼저 거쳐서 feature map 을 추출해냄
◦
Region Proposal feature map 에 projection 하여 해당 영역을 feature map 으로 부터 잘라냄
◦
ROI Pooling Layer 로 잘려진 feature map 영역을 동일한 크기로 변형함
◦
이후 Fully Connective Layer 를 통과하여 classificaiton loss 및 bounding box loss 를 뽑아내고 이를 더해 최종적인 multi-task loss 를 계산
◦
Region Proposal 별 ConvNet 을 거쳐야 하는 것 아닌, 이미지 전체가 ConvNet 을 거치기 때문에 R-CNN 에 비해서 학습이 빠름
◦
Inference time 대부분이 Region Proposal 에 쓰임 (bottlenecked by Region Proposal)
•
Faster R-CNN
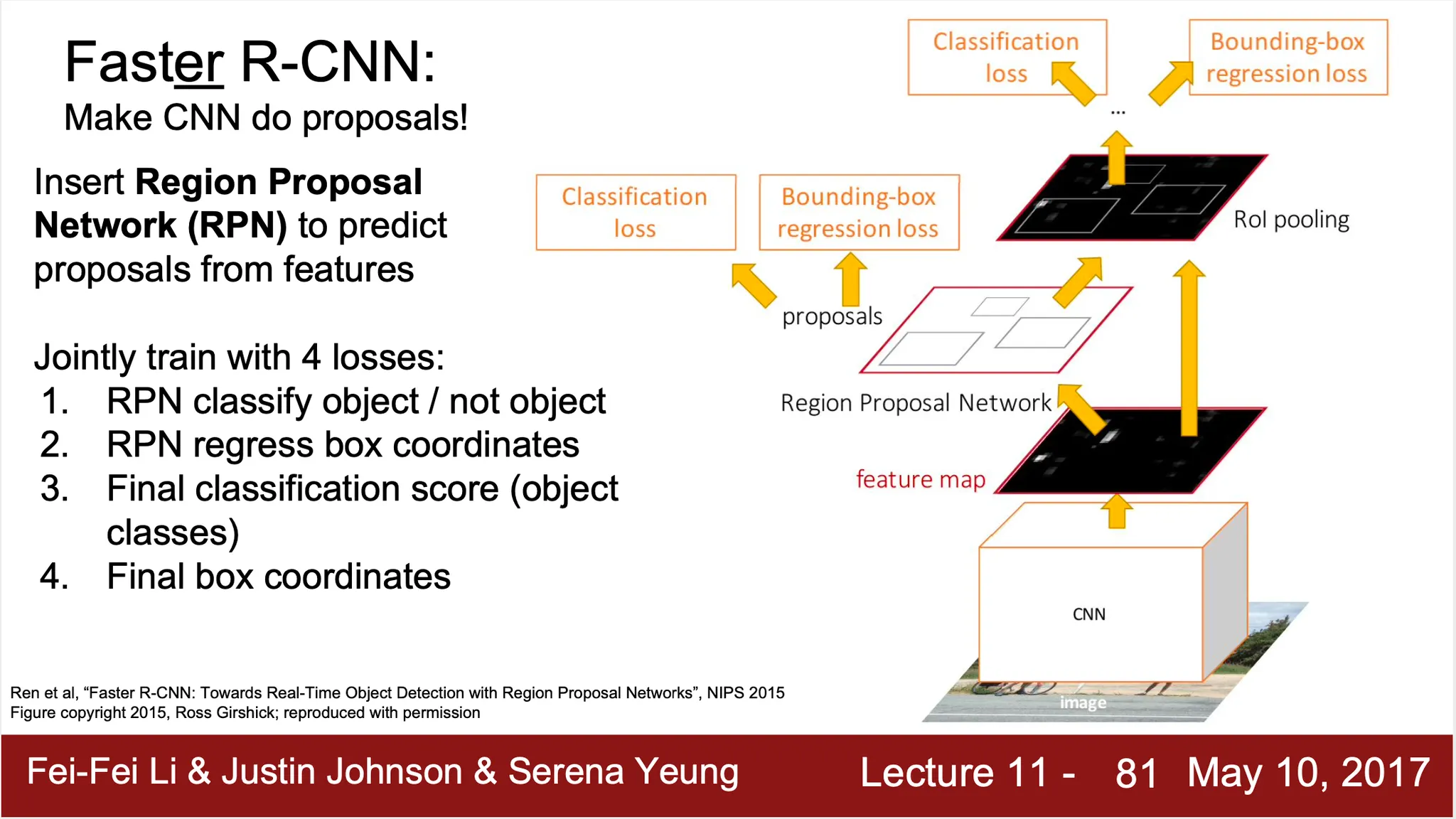
◦
Learnable Region Proposal Network 존재
◦
Loss 에 RPN 가 생성해낸 Region Proposal 에 대한 항목 2 개(object existance, coordinate) 와 최종적인 classificaiton, bounding box reggresion 항목 존재
◦
기존 Region Proposal 알고리즘이 잘 동작하지 않는 영역에서도 잘 동작
◦
Inference time 이 굉장히 빠름
•
YOLO/SSD
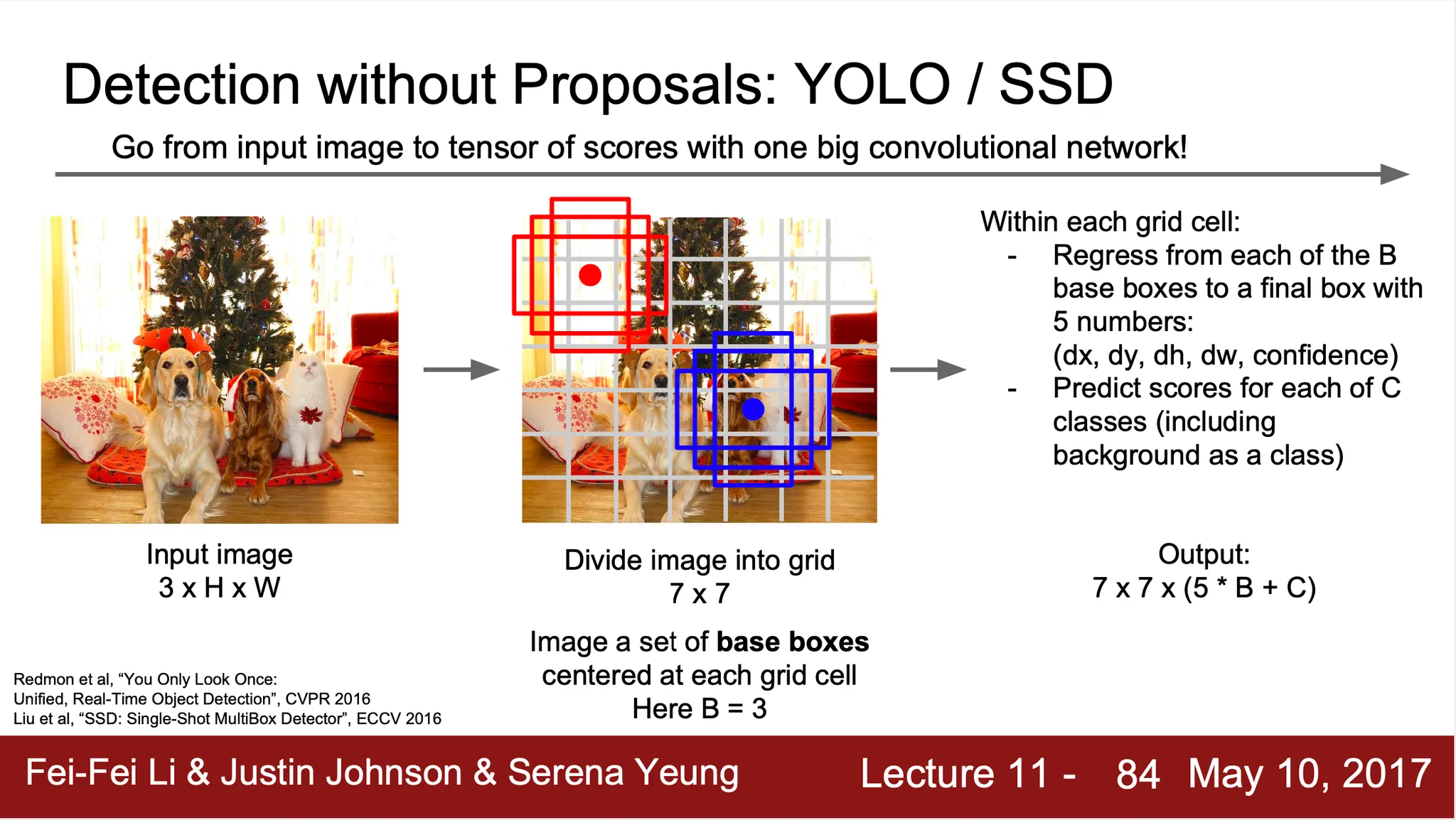
◦
Region Propsal 을 찾고 해당 영역을 잘라서 학습하는 2단계 학습에서 벗어나 1단계만에 학습이 진행될 수 있는 형태로 변경
◦
전체 이미지를 그리드로 나눈 뒤 각 그리드마다 potential bounding box 를 B 개씩 지정
◦
학습의 결과는 각 그리드 마다의 bounding box 위치, 물체 존재 가능성, 그리고 class 에 대한 정보를담은 dimension 의 vector
Instance Segmentation
•
Object Detection 과 비슷하지만, bounding box 를 그리는 것에서 segmentation mask 를 입히는 것으로 변경된 task
•
Mask R-CNN
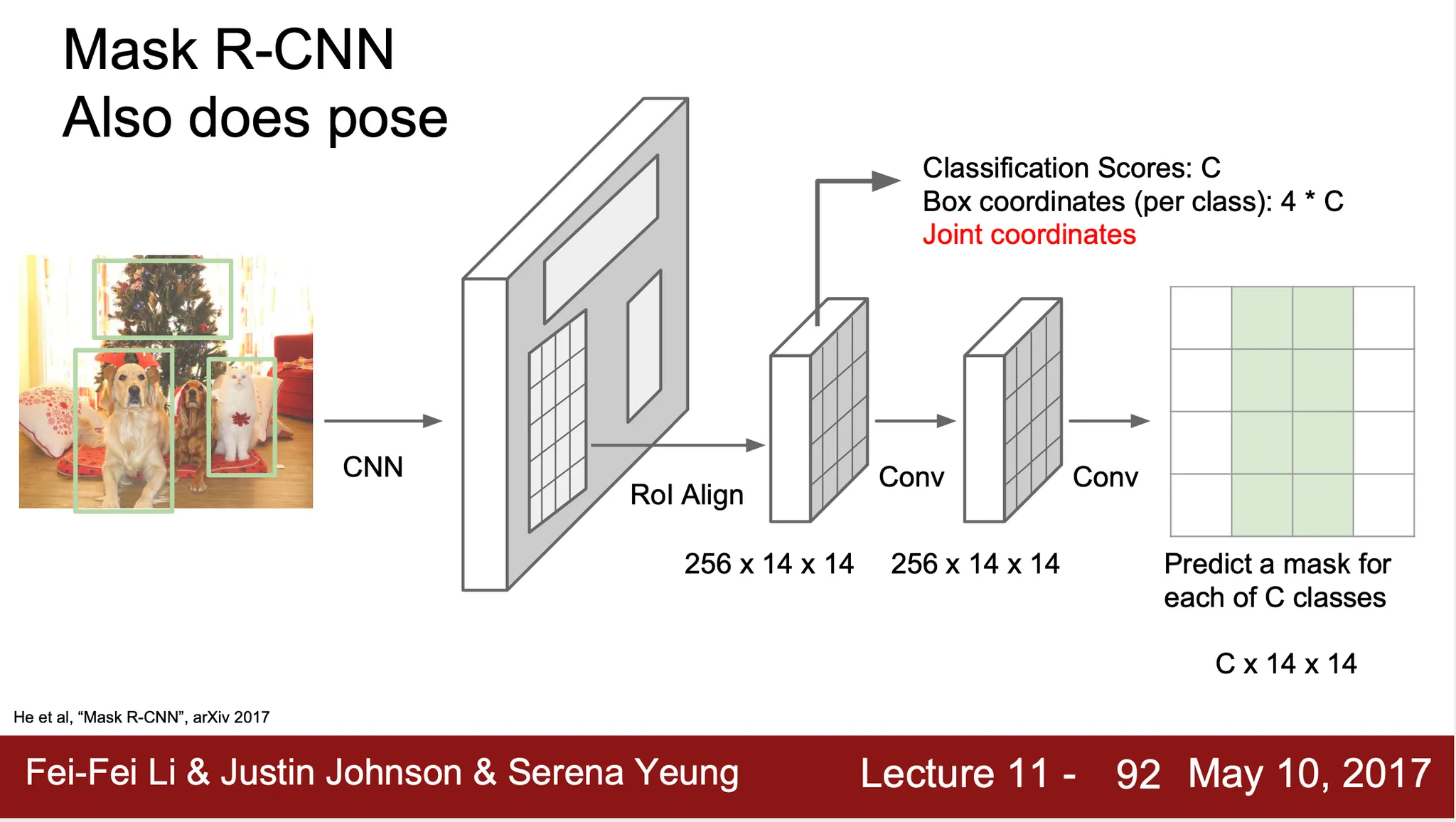
◦
RPN 를 통해 Region Proposal 을 찾고 feature map 으로부터 projection 한 영역을 잘라낸 뒤 ROI Pooling 을 하는 것까지 Faster R-CNN 과 동일
◦
이후 두 개의 branch 로 나누어짐
▪
하나는 Faster R-CNN 과 완전히 동일한, classification class 와 bounding box coordinate 를 산출하는 ConvNet
▪
하나는 C 개의 class 에 대한 각 pixel 의 mask 를 찾아내는 ConvNet