




 Note Taking
Note Taking
Lecture 11 요약
•
Semantic Segmentation
◦
이미지의 각 픽셀 class 를 도출해내는 task
◦
Cropped Image 의 중앙 픽셀에 대한 classification → 중복되는 연산이 많아 비효율
◦
Fully Convolutional Network → 연산 수 자체가 많아 비효율
◦
Downsampling + Upsampling Convolutional Network
▪
Downsampling - Convolution Layer, Pooling
▪
Upsampling - Transponse Convolution Layer, UpPooling
•
Classification + Localization
◦
단순 Classification 에 해당 단일 object의 위치까지 도출해내는 task
◦
Multitask Loss
▪
Feature Extracted 된 vector 로부터 두 개의 다른 네트워크를 동시에 학습
▪
Classifier (Fully Connected Layer) + Localizer (Fully Connected Layer)
•
Object Detection
◦
다수 object 에 대한 classification + localization task
◦
R-CNN
▪
Selective Search (Object 가 존재할 법한 영역 추출)
▪
Selective Search 영역 (Region Proposal) 으로 Crop Image
▪
각각의 Cropped 된 image 영역에 대한 Conv Layer 를 통과시켜 Multitask Loss 계산
▪
Back Propagation
◦
Fast R-CNN
▪
Selective Search (Object 가 존재할 법한 영역 추출)
▪
이미지를 Convolutional Network 를 통해 featured map 을 추출
▪
추출한 featured map 위로 Region Proposal 을 projection
▪
Projection 한 featured map 을 ROI pooling 을 통해 size 를 일원화
▪
일원화된 영역을 Fully Connected Network 를 통과시켜 Multitask Loss 계산
▪
Back Propagation
◦
Faseter R-CNN
▪
Region Proposal Network (Region Proposal 영역을 학습) 하는 네트워크 존재
▪
Featured map 을 input 으로 받는 Region Proposal Network 로 Region Proposal 추출
▪
추출한 Region Proposal 로 Fast R-CNN 에서와 마찬가지로 영역을 projection 하여 crop
▪
잘려진 영역을 Fully Connected Network 를 통과시켜 Multitask Loss 계산
▪
Back Propagation
◦
YOLO
▪
Region Proposal 을 찾는 단계 및 해당 Region Proposal 로 Crop + Projection 한 영역을 Fully Connected Network 를 통과 시키는 단계를 하나의 단계로 일원화
▪
이미지를 Grid 로 나누어 해당 Grid 별 potential bounding box 를 정의해 둔 뒤 각 box 별 box 위치와 물체 존재 여부 Confidence 에 대한 regression 과 Class Score 산출
•
Instance Segmentation
◦
Object Detection 은 bounding box 를 찾는 task 이지만, Instance Segmentation 은 classification mask 를 찾는 task
◦
Mask R-CNN
▪
Faster R-CNN 에 비해서 Feature map 을 Region Proposal 영역으로 projection 한 input 을 Convolutional Network 에 통과시킨 후 classification mask 를 찾는 기능이 추가
What's going on inside ConvNets?
•
First Layer: Visualize Filters

◦
First Layer 의 learned weight 를 관찰로 해당 filter 가 무엇을 의미하는지 어느정도 유추 가능
▪
Template vector 와의 Inner product 로 activation 을 maximize 하기 위한 arbitrary vector 는 template vector 와 같을 때
▪
비슷한 맥락으로, loss function 을 minimize 하기 위한 arbitrary weight 는 image 의 표현형과 유사할 때(?) 로 볼 수 있다는 직관
◦
신기한 점은, 어떤 학습데이터를 사용하던, 어떤 목적으로 학습을 하던 First Convolutional Layer 의 weight 는 다들 비슷하게 생김
◦
Oriented Edges & Opposing Color
•
Intermediate Layer
◦
좋은 First Layer Convolution 이 어떻게 생긴지에 대한 intuition 이 없기 때문에 Second Layer 의 learned weight 를 visualize 하는 것은 크게 의미가 없음
•
Last Layer: Nearest Neighbors

◦
Last Layer 가 뽑아낸 feature representation 의 유사도는 이미지의 유사도를 나타낼 수 있음
▪
Elephant 사진의 제일 좌측이랑 세 번째는 elephant 의 위치가 다르기 때문에 이미지 자체의 MSE 는 크지만, Last Layer 가 뽑아낸 feature 는 유사
•
Last Layer: Dimensionality Reduction

◦
Last Layer 가 뽑아낸 feature representation 을 2-dimension 으로 줄여 (PCA, t-SNE) 비슷한 친구들끼리 묶는 작업들도 가능!
◦
2-demension 으로 줄인 친구들을 가장 가까운 pixel 위치에 배치한 그림이 우측 (Continuous Semantic Notion 을 볼 수 있음)
•
Intermediate Layer: Trials for Analyze
◦
Maximally Activating Patches
▪
특정 Convolutional Layer 의 특정 channel 의 output 이 maximize 되는 patches 들을 모아, 어떤 특징들을 가지고 있는지 보고 해당 channel 이 이미지의 어떤 특성을 capture 하는지 관찰하는 방법론 ( kernel filter 3 개가 앞에 있다면 5 번째 에는 receptive field 를 가지고 그 중 어느 것이 최대를 만드는지!)
◦
Occlusion Experiment
▪
이미지의 특정 부분을 지우고, 그 부분을 이미지 픽셀의 mean-value 로 채워넣고, Network score 의 변화를 drastic 하게 바꾸는 지점을 찾아, 어느 image patches 가 네트워크가 해당 이미지를 해당 class 로 추론하는데 중요한 정보로 사용하는지 찾아내는 방법론
◦
Saliency Map
▪
Input pixel 의 값 변화가 class score 에 얼마만큼 영향을 주는가- (Gradient of class score WRT image pixels) 를 이용해 class pixel 이 얼마만큼 네트워크가 해당 이미지를 결과 class 로 추론하는데 중요한 정보를 제공하는지 찾아내는 방법론
▪
Class score 이 아니라, intermediate value 를 기준으로 해당 방법론을 적용할 수 있음
이 때, Guided Backpropagation 이라 하여, back propagation 시에 positive influence 만을 반영하는 방법이 있는데, 깊게는 설명 X → 어느 Input 부분이 영향을 주는지 더 깔끔한 이미지를 얻을 수 있음!
Gradient Ascent
•
어떠한 형태의 이미지가 주어진 학습 네트워크에서 class score 를 maximize 하는가?!
•
Weight 고정
•
Input image 픽셀 학습 (변화)
•
◦
는 이미지가 class score 만 맹목적으로 높게하는 형태로 학습되지 않고 어느정도 natural image 처럼 보이게 하는 regularization term
◦
가장 기본적인 는 L2 norm
◦
L2 norm 에 학습 도중 주기적으로 다음 사항들을 추가하여 보기 좋은 이미지를 만드려는 시도도 있음!
▪
Gaussian blurring
▪
Small piexl 값들을 0으로 clipping
▪
Small gradient 를 가지는 pixel 값들을 0으로 clipping
•
Fooling Image 도 가능!
◦
특정 class 값을 maximize 하도록 input pixel 을 학습하여 조작
DeepDream: Amplify Existing Features

•
특정 Layer 까지만 forward propagation
•
정한 특정 Layer 의 activation 이 Upstream Gradient 라고 가정하고 back propagation 진행
•
Image pixel 을 gradient 에 해당하는 만큼 update
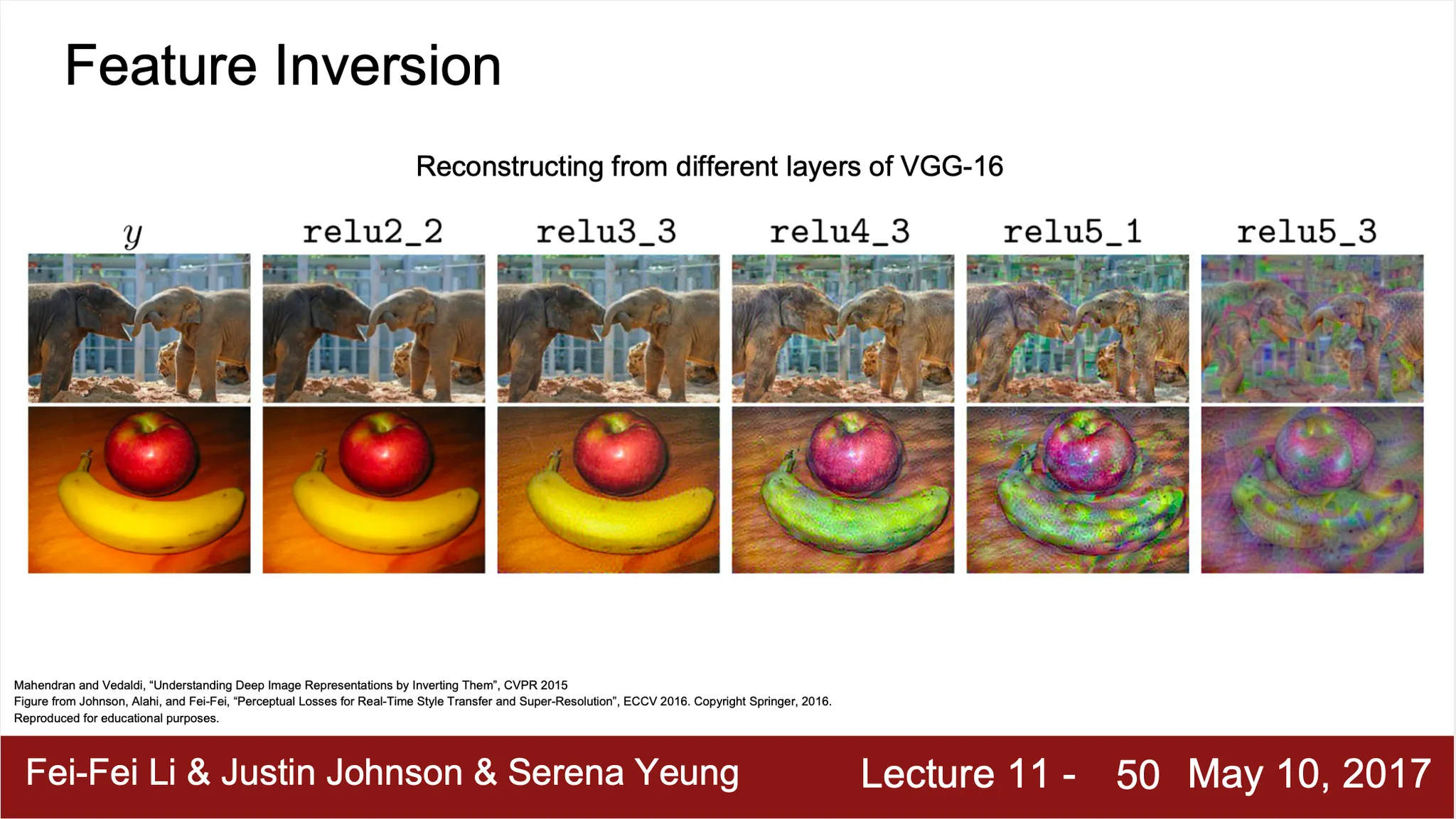
Feature Inversion
•
주어진 feature vector 로부터 자연스러운 image 를 reconstruction 하는 방법론
•
주어진 feature vector 와 generated image 의 computed feature vector 의 차이를 최소화하는 형태로 설계
•
•
◦
Total Variational Regularizer 로, 주변 pixel 과의 차이로 정의되어 smoothness 를 보장
•
더 먼 곳의 feature vector 로부터 생성한 이미지가 low level detail 이 부족한 경향을 볼 수 있음! (information 이 손실되는 과정)
Texture Synthesis
•
Input patch of texture 을 받아 large image 를 생성해내는 task
•
Classical 하게 이를 진행하는 여러 방법들이 존재
◦
Nearest Neighor Approach - Scanline order 로 새로 만들 지점과 인접한 이미 만든 pixel 들의 nearest neighbor 를 input patch 에서 찾고, copy 하여 붙여넣음!
◦
복잡한 texture 의 경우 동작 X
•
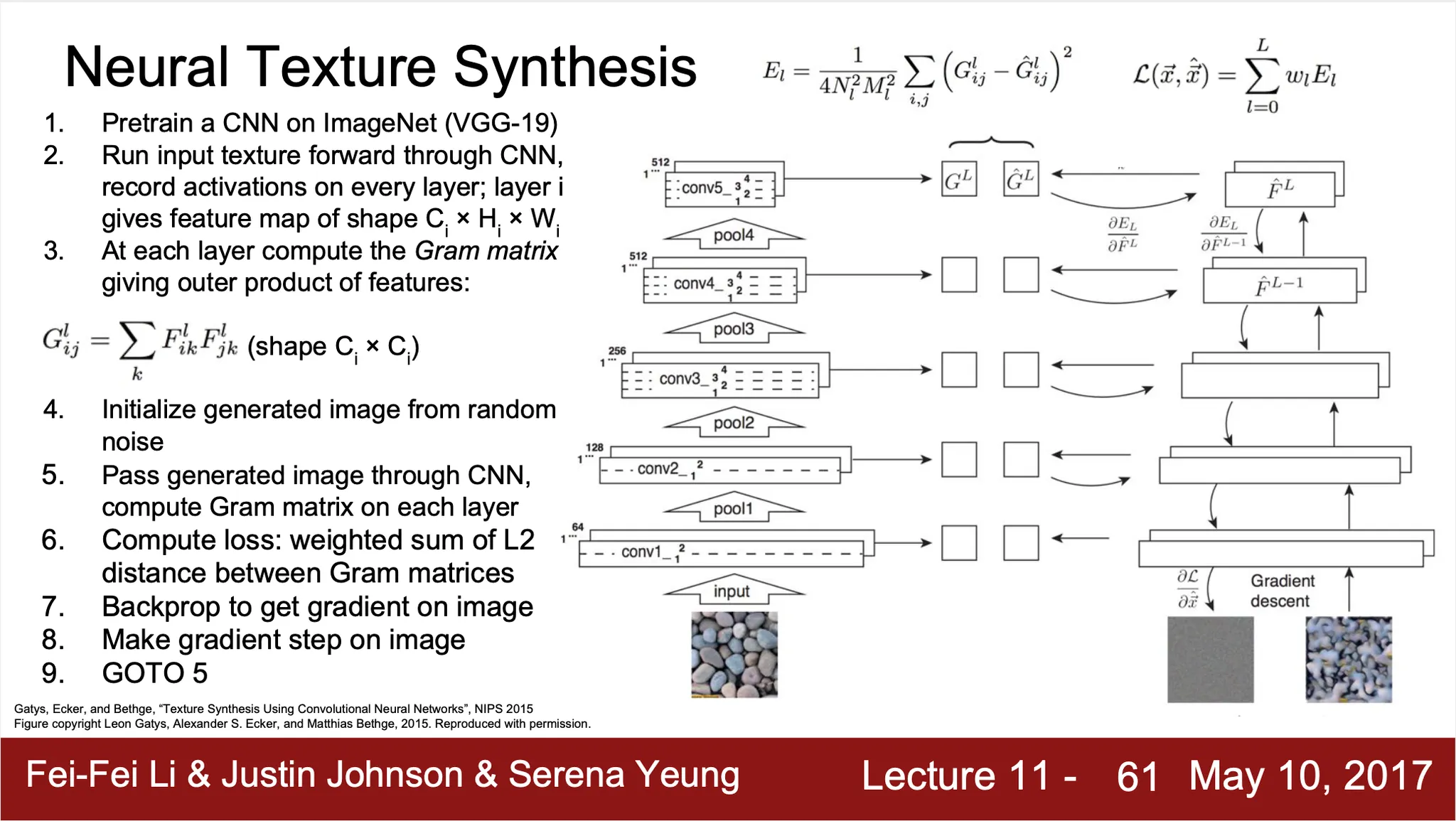
Neural Texture Synthesis: Gram Matrix
◦
특정 Layer 가 의 activation map 을 출력한다고 가정
◦
개의 dimensional vector 에 대해서 2 개씩 쌍을 지어 각각의 outer product 를 하면 matrix 가 생성됨
◦
개의 조합 마다 생성되는 matrix 의 average 가 Gram Matrix
◦
Feature volume 에 존재했던 spatial Information 을 버리고, 2-dimension co-occurence statistics 만을 가져서 texture 에 대한 좋은 descriptor 가 됨
◦
True covariance 를 사용하지 않는 이유는 computation 이 싸기 때문
◦
Noise input 으로부터 Gram Matrix 를 형성할 수 있는 방향으로 input pixel 을 조정하여 Texture Synthesis 진행
Neural Style Transfer
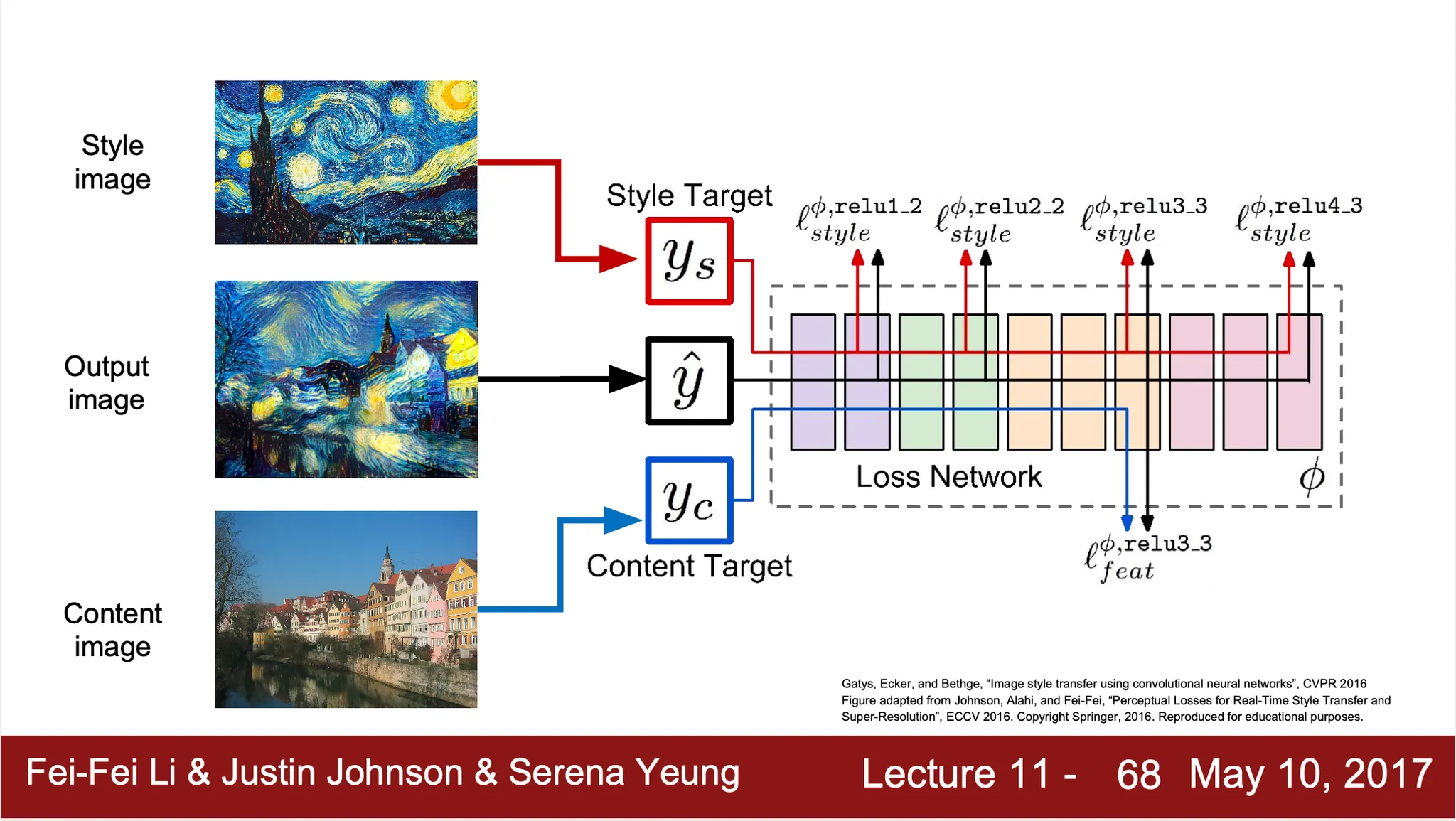
•
Content Image 와 Style Image 를 이용해서 특정 Content 를 특정 Style 로 묘사할 수 있는 방법론
•
Content Image 와 Style Image 를 동시에 input 으로 넣고, Gram Matrices 와 feature vectors 를 생성해내어 loss 를 계산해냄 (Feature Reconstruction Loss of Content Image + Gram Matrix Loss of Style Image)
•
계산한 loss 를 바탕으로 gradient ascent 를 적용하여 input image 업데이트 반복
•
다만, 위의 방법은 굉장히 느린 단점이 있어서, Fast Style Transfer 를 고안
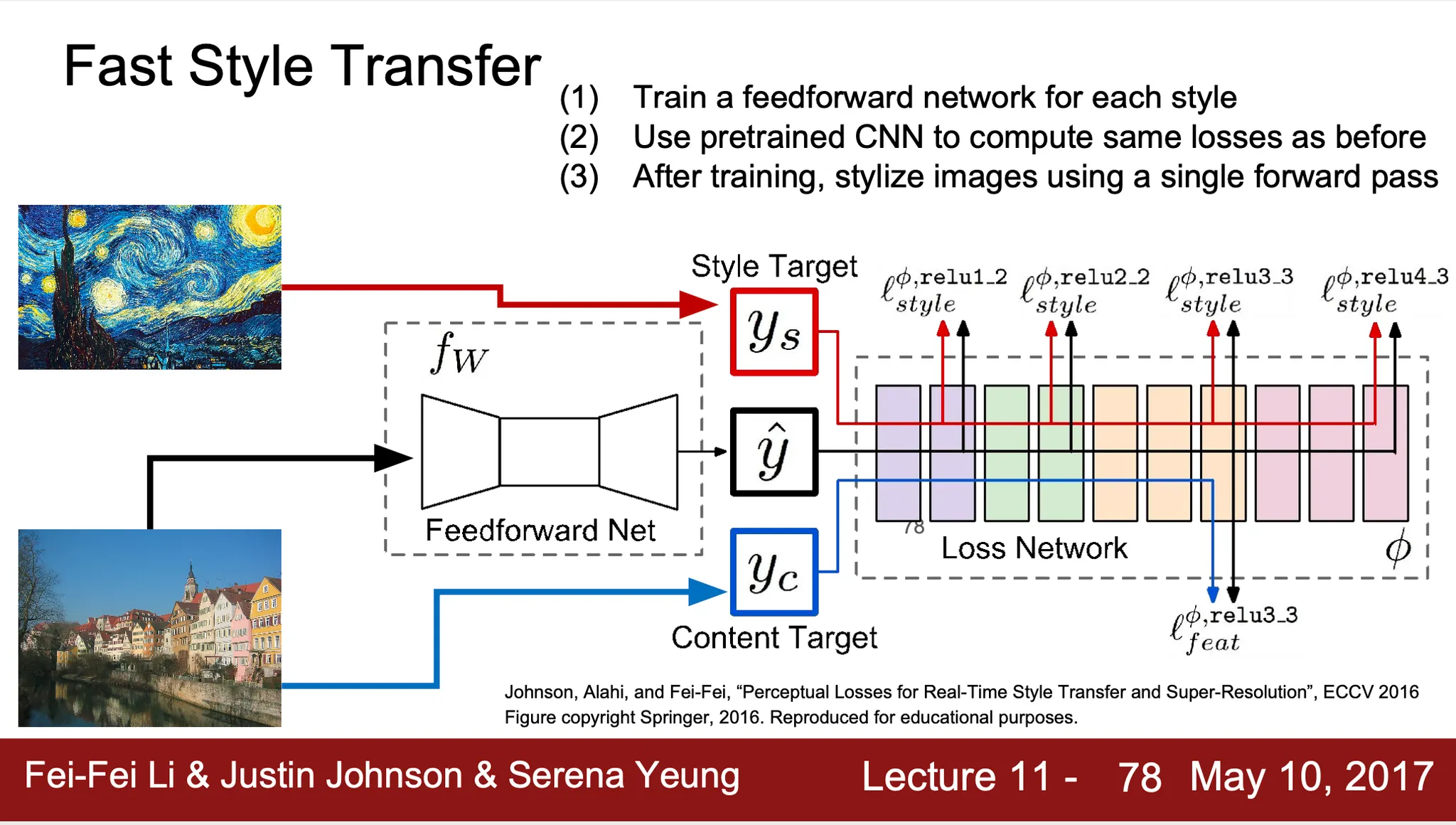
◦
매 조합마다 학습으로 이미지를 generate 하는 것이 아닌, stylize 를 진행하는 Feed Forward Network 를 학습하는 방법