


 Note Taking
Note Taking
Lecture 3 요약
•
Loss
◦
prediction/score () 이 얼마나 나쁜지를 평가하는 척도
◦
SVM Loss
◦
Regularization - 복잡한 Model 에 대한 정규화 (penalize specific/general weight scale)
•
Optimization
◦
Loss 를 최소화하는 적합한 찾기
◦
Gradient Descent
▪
Numerical Gradient - Slow, Approximat, Easy to Write
▪
Analytic Gradient - Fast, Exact, Error-Prone
Analytic Gradient 를 구하는 방법: Computational Graph
•
Computational Function 을 graph 로 표현
•
각 node 를 computation 으로 정의
•
Back Propagation 을 사용할 수 있다는 장점이 있음
◦
재귀적으로 chain rule 을 사용하여 각 변수에 대한 gradient 를 계산
◦
특히 CNN (AlexNet), Neural Turing Machine 등의 복잡한 계산 시 이점을 가짐
Back Propagation
•
각 요소(weight) 에 대한 gradient 계산
◦
Computational Function (모델이 나타내는 computation)
◦
◦
computation 를 기준으로 computation graph 를 그림
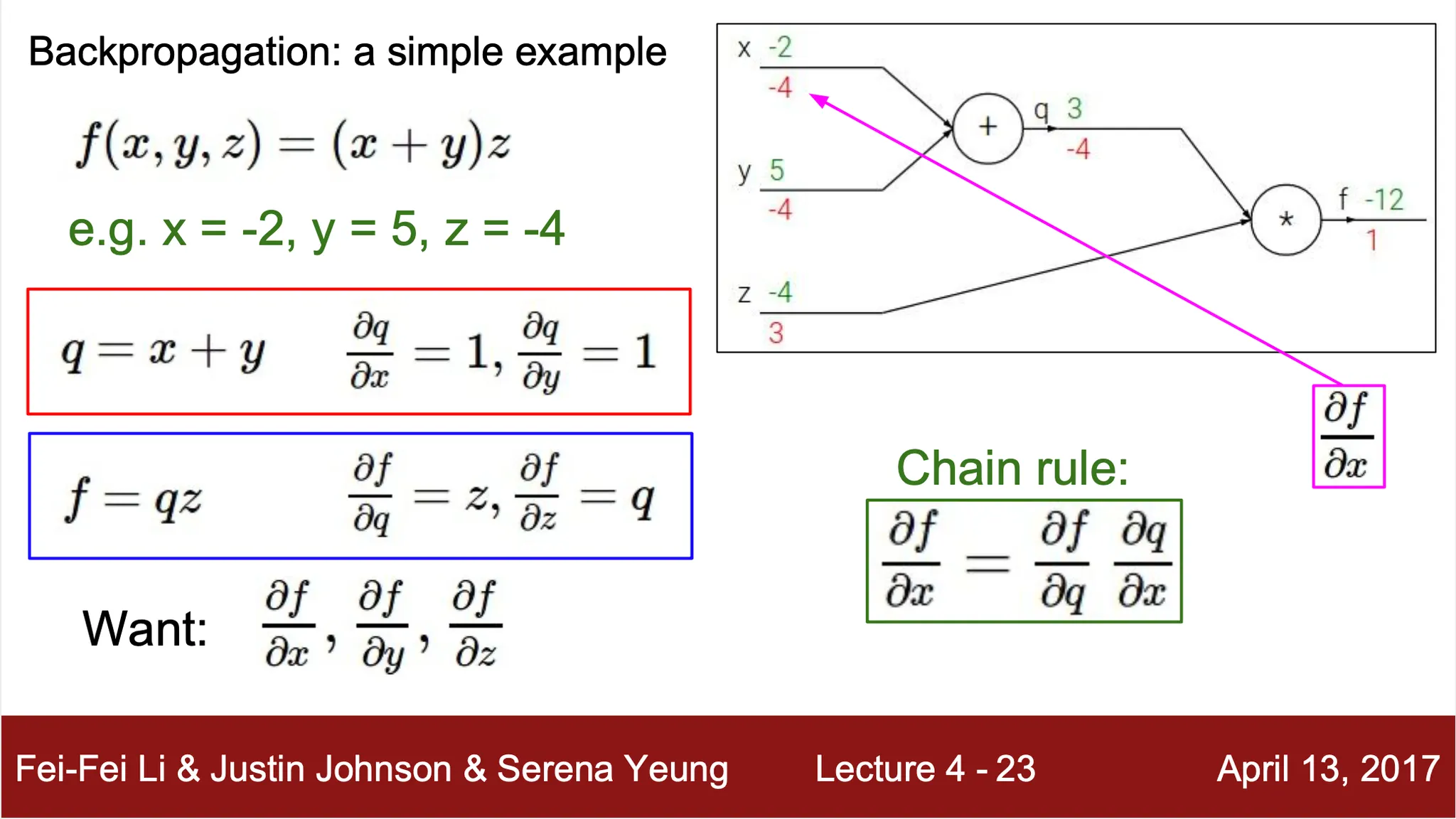
◦
, 이에 따라
◦
, 이에 따라
◦
위 두 식을 이용해서 에 대한 최종 computation 의 편미분은 chain rule 로 구해낼 수 있음
◦
,
◦
이 편미분 값은 computation 를 최소화하기 위한 각 요소의 변화 방향을 제시해줌
•
Computation Node 관점에서의 Back Propagation
◦
Upstream gradient + local gradient + chain rule 를 사용해 downstream gradient 를 계산
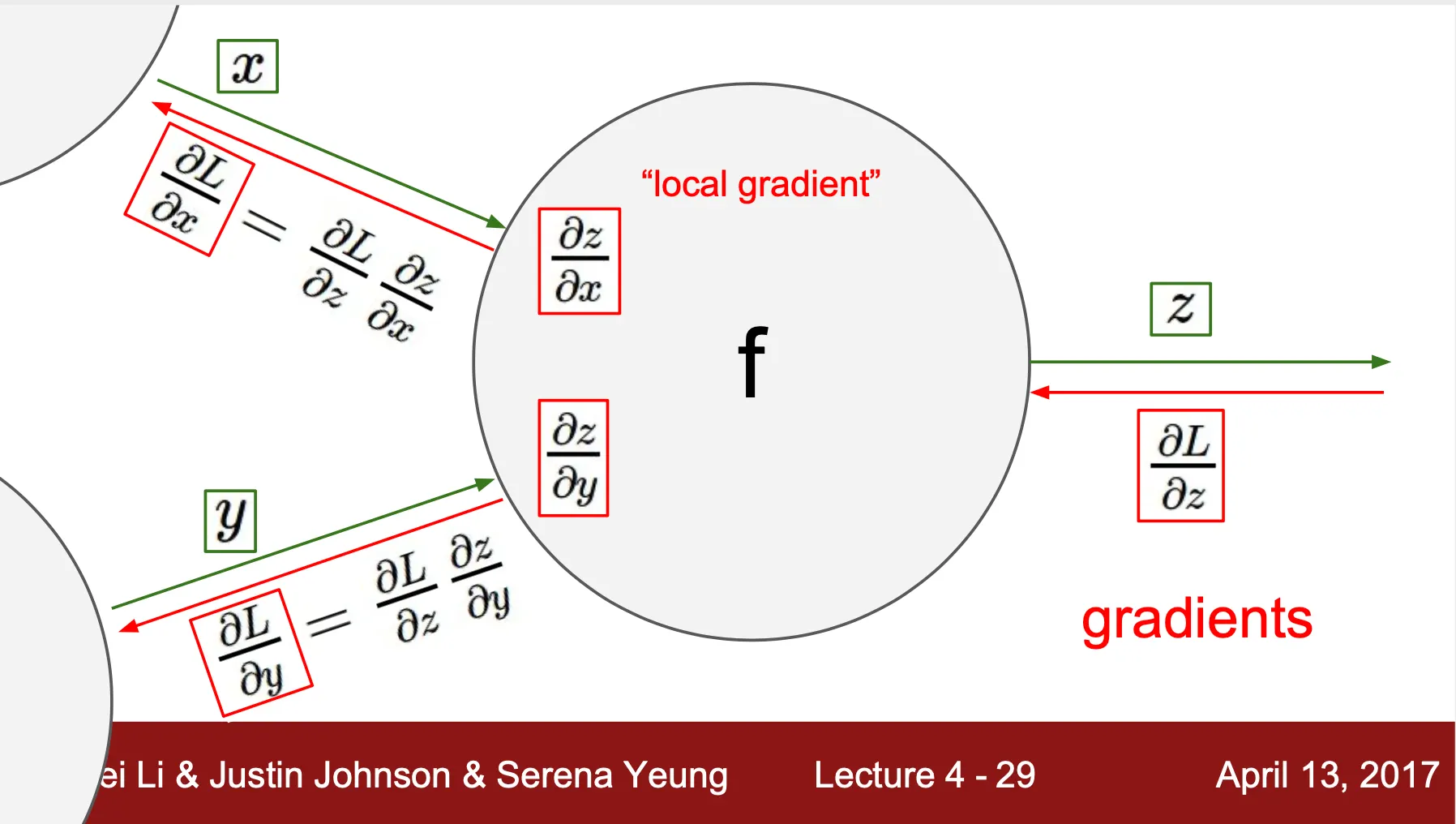
◦
Upstream gradient:
◦
Local gradient: ,
◦
Chain rule: , 을 통해 downstream gradient 계산
◦
재귀적으로 Back Propagation 을 진행할 수 있음을 시사
•
Complex Function 에서의 Back Propagation
◦
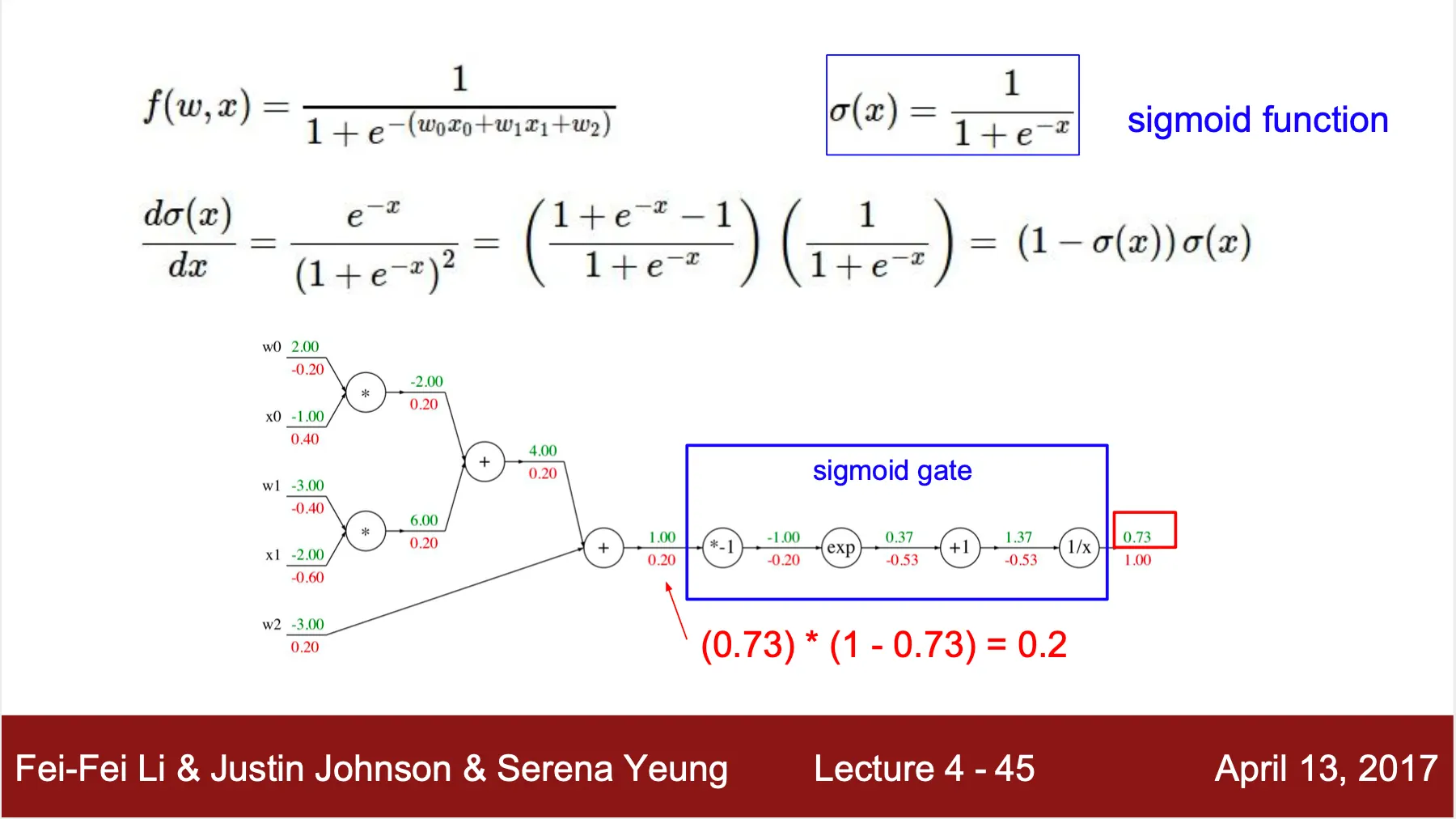
◦
여러 computation 을 하나로 묶어 gate 로 정의할 수 있으며, 이 때의 back propagation 도 동일하게 진행할 수 있음 (sigmoid )
•
Patterns in backward flow - 각 computation node 의 표현?
◦
: gradient distributor
▪
Local gradient 가 1 이기 때문에 upstream gradient 를 그대로 가져옴
◦
: gradient router
▪
Non-max 쪽은 관계가 끊기는 것과 같아 0
▪
Max 쪽은 local gradient 가 1 이기 때문에 upstream gradient 를 그대로 가져옴
◦
: gradient switcher
▪
Local gradient 가 피연산 변수 값이므로 upstream gradient 피연산자 값 으로 계산됨
•
Vectorized variable 에서의 Back Propagation
◦
기본적인 연산은 기존의 Back Propagation 과 동일하나, gradient 가 Jacobian Matrix 로 표현 (reference vector 의 번째 항목이 loss vector 의 번째 항목에 미치는 영향에 대한 결과)
◦

◦
▪
▪
◦
▪
◦
Upstream gradient: 로 설정 ()
◦
Chain rule step 1:
◦
Chain rule step 2: ,
◦
◦
•
Modularized Implementation
◦
Forward - computation 진행, input 을 class variable 로 저장
◦
Backward = 저장한 class variable 과 upstream gradient 로 downstream gradient 반환

Neural Network
•
Neural Network 의 구성?
◦
기존에 다룬 linear score function 이 stack 된 형태
◦
Linear score function 사이의 non-linearity 존재
◦
최종적으로 non-linear complexed function 을 표현
•
Architecture
◦
기본적인 구조는 각 layer 의 연산이 matrix multiply (Fully-Connected)
◦
Input, Output Layer 사이의 layer 들은 hidden layer
◦
전체 layer 수에서 input layer 는 세지 않음 (총 4개의 layer 존재 시 3-layer Neural Network)
◦
Hidden layer 의 수로 명시하기도 함 (2-hidden-layer Neural Network)
Activation Function
•
자세히는 다음 시간에 언급
•
Sigmoid
•
tanh
•
ReLU
•
Leaky ReLU
•
Maxout
•
ELU
Feed-Forward Computation
•
입력을 정방향으로만 이동시키는 연산 (feed-forward)
•
단일 layer 연산을 Matrix Multiplication 의 형태로 모듈화 하여 구현 가능
•
전체 연산의 경우 모듈을 반복하여 합성함수 연산 진행