본 포스트에서는 학습 데이터 없이, 텍스트 기반으로 원하는 뷰를 생성하는 방법론을 제시한 논문에 대해서 소개드리려고 합니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“Zero-Shot Text-Guided Object Generation with Dream Fields”

Objective
디테일한 3D 모델들은 게임, VR, 그리고 영화와 같은 멀티미디어 경험을 하는데에 있어서 중요한 요소로 자리매김하고 있습니다. 이러한 멀티미디어 어플리케이션들은 수천개의 3D 모델들로 구성되어 있고, 이들은 일반적으로 디지털 소프트웨어를 사용한 전문가들의 손을 통해서 만들어집니다. 하지만, 이렇게 전문가를 필요로 하는 3D 모델의 생성과정은 시간과 가격 측면에서 효율적이지 못한 경우가 많습니다.

Zero-Shot Text-Guided Object Generation
이러한 비효율을 개선하기 위해 기존의 선행연구들은 3D 데이터셋을 기반으로 학습한 GAN 을 활용하여 다양한 형태 (e.g Point Cloud, Voxel Grid, Triangular Mesh, Implicit Function) 의 3D 모델들을 생성했습니다. 하지만 2D 공간과는 다르게 3D 공간에서는 라벨링된 데이터셋이 현저하게 적기 때문에 매우 한정된 카테고리 내의 3D 모델들만을 생성할 수 있었고, 넓은 범위의 형태 및 질감을 가지는 3D 모델들을 필요로 하는 멀티미디어 어플리케이션의 특성 상 이러한 방법론들은 많은 어플리케이션에 적극적으로 사용되지 못했습니다.
이러한 점을 해결하기 위해, 논문에서는 3D 학습 데이터를 전혀 사용하지 않고도 원하는 3D 모델을 생성할 수 있는 방법론을 제시합니다. 원하는 3D 모델을 정의하는 방법으로는 Text Prompt 를 택하였고, 논문에서는 텍스트를 통해서 원하는 3D 모델을 정의할 수 있게 설계한 것은 사용자로 하여금 원하는 3D 모델을 쉽게 정의할 수 있게 하는 것은 물론, 텍스트 데이터의 구성 자체가 형태, 색깔, 스타일 등의 요소들을 유연하게 조절할 수 있게 하는 장점을 가지고 있기 때문이라고 설명합니다.
Background
논문의 방법론은 크게 다음의 두 가지로 나누어 설명할 수 있습니다.
1.
Neural Radiance Field
2.
Image-Text Loss
Neural Radiance Field (이하 NeRF) 는 NeRF 논문리뷰에서 다룬 적 있는 주제이며, Image-Text Loss 또한 Text2Mesh 논문리뷰에서 간단하게나마 다룬 적이 있습니다. 본 포스트에서는 앞으로 전개될 이야기들에 대한 기본적인 이해를 위해 해당 주제들에 대해서 간략하게 논문에서 언급한 수준으로나마 소개할 예정입니다.
Neural Radiance Fields
NeRF 는 2020 년에 ECCV 의 Oral Presentation 로 채택된 View Synthesis 분야의 논문입니다. View Synthesis 는 특정 물체를 특정한 위치의 카메라에서 보았을 때 보이는 뷰를 생성해내는 분야로, 직접적으로 3D 모델 (ex. Point Cloud, Mesh, etc…) 을 생성해내는 것이 아니라, 관찰자의 위치에 따른 물체의 뷰를 연속적으로 생성해내는 능력을 학습함으로써 간접적으로 3D 모델을 생성하는 효과를 내는 분야입니다.
NeRF View Synthesis
NeRF 에서 제시한 네트워크는 3차원 좌표 를 입력으로 받아 해당 좌표의 color 와 volume density 를 산출합니다.

Volume Density?
Volume Density 는 해당 좌표가 뷰에 미치는 영향이 얼마나 큰가- 에 대한 척도로 봐주시면 됩니다.
Volume Density 가 클수록 뷰에 유의미한 영향을 주는 좌표이고, 작을수록 뷰에 주는 영향이 적습니다.
연속된 모든 좌표에서 와 를 산출하도록 설계된 네트워크에서 아래의 식 같은 Volume Rendering 과정을 거치면, 특정 시점에서 바라보았을 때의 뷰를 구성하는 특정 픽셀에 대한 색상 값 () 을 산출할 수 있고 이를 Color Estimation 이라고 합니다. 이들을 종합하면 뷰에 대한 정보를 완성할 수 있습니다.
위 식에서 , 가 현재 네트워크의 parameter 를 기준으로 생성된 color 와 volume density 입니다.
는 Rendering 을 위해 사용할 ray 의 parametric representation 입니다. 어떤 특정 픽셀의 색상을 결정하기 위해 그 픽셀과 이어지는 ray 위의 모든 점들을 에 대한 변수로 표현한 것이며, 값이 결정되면 가 하나의 3D 좌표가 되는 것입니다.
는 ray 상의 특정 좌표의 transmittance 값입니다.
Transmittance?
관찰자가 위치에서 바라보았다고 가정했을 때, 특정 ray 위의 좌표 가 다른 particle 등에 의해 막히거나 흡수되지 않고 까지 도달하여 뷰에 영향을 미칠 수 있을 확률을 의미합니다. Transmittance 가 큰 좌표일수록 가로막는 particle 등이 없기 때문에 뷰에 큰 영향을 줄 수 있습니다.
이 때 Transmittance 는 ray 상에서 자신보다 앞에 있는 좌표들의 Volume Density 들이 얼마나 큰지를 기반으로 정량적으로 계산되며 NeRF 논문에서는 이를 아래의 식으로 나타냅니다.
하지만, ray 위의 셀 수 없이 많은 모든 좌표들을 이용해서 뷰 이미지의 픽셀 색상 를 계산해내는 것은 계산 불가능한 과정이기 때문에 이를 계산할 수 있는 과정으로 변환하기 위해서 NeRF 논문에서는 ray 를 여러 개의 구간으로 나누어 각 구간에서 점을 sampling 하여 discrete 한 계산 과정으로 변환하게 됩니다.
이 때 이며 Color Estimation 에서 주요하게 변한 의 도입은 해당 수식의 사용이 성능 개선에 도움이 된다는 선행연구 (Max et al.) 의 결과에 기반한 변화 정도로 봐주시면 될 것 같습니다.
여기까지가 NeRF 의 기본적인 설계에 대한 설명입니다.
부가적으로, NeRF 에서는 입력 정보가 가지고 있는 적은 차원의 수를 늘려서 high frequency detail 을 산출해내기 위해 부가적으로 Positional Encoding 이라는 방법론을 사용하는데, 이는 앞선 NeRF 의 논문리뷰를 참고하시기 바랍니다. 논문에서는 NeRF 의 Positional Encoding 에서 벗어나 Mip-NeRF 의 Integrated Positional Encoding (이하 IPE) 을 사용했다고 하는데, 이는 대략적으로 기존의 Positional Encoding 이 단일 좌표에 대한 encoding 이었다면 IPE 는 로컬 영역에 대한 정보를 포함한 encoding 으로 봐주시면 될 것 같습니다.
Image-Text Loss
이미지와 그에 해당하는 텍스트로 구성된 방대한 양의 데이터셋은 특정 이미지와 해당 이미지가 주어진 텍스트에 잘 대응되는지를 판단하는 모델들을 학습하는데 사용될 수 있었습니다. 이러한 모델들은 일반적으로 Image Encoder 와 Text Encoder 가 존재하여 이미지와 텍스트를 공유된 embedding space 로 매핑할 수 있게 설계되었습니다.
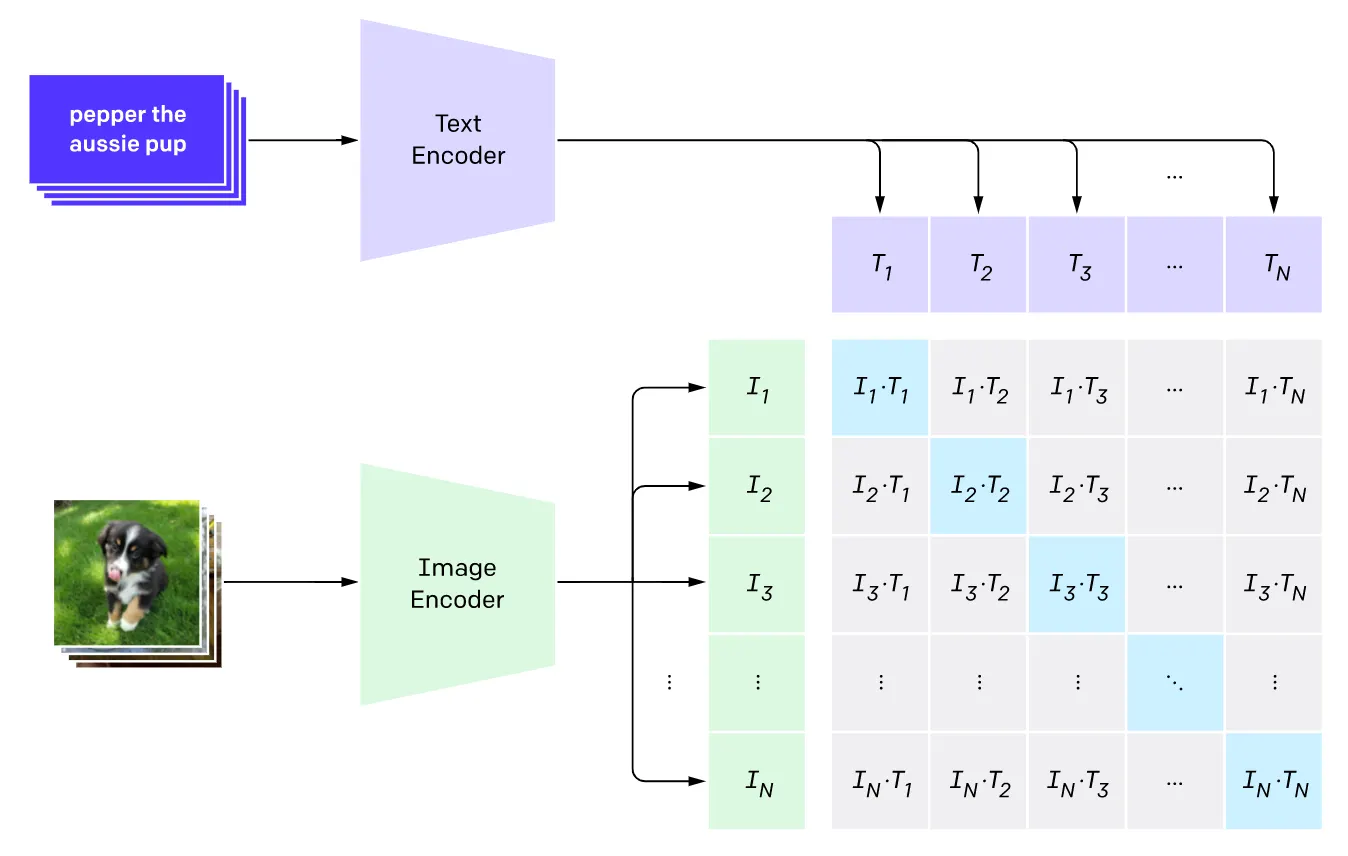
Image-Text Model, CLIP
예시로 이미지 와 텍스트 에 대해서 를 score 로 정의하고, 해당 score 가 높으면 해당 텍스트가 해당 이미지에 대한 좋은 설명이 되는 것으로 판단하는 것입니다. 이러한 구성은 이미지와 텍스트가 얼마나 유사한지 산출하는 좋은 방법론으로 사용할 수 있었고 많은 downstream tasks 에서 활용되었다고 합니다.
Method
논문의 방법론 (Dream Fields) 은 앞서 Background 에서 언급한 NeRF 와 Image-Text Model 인 CLIP 에 기반합니다. NeRF 에서는 특정한 관점에서 살펴본 ground truth 이미지들을 학습 데이터로 하여 좌표별 color 와 volume density 를 얻어냈다면, Dream Fields 에서는 해당 ground truth 대신 CLIP 을 통해 산출된, 렌더링된 이미지와 입력한 텍스트 간의 유사도 score 를 사용하는 것이 주된 차이점입니다.
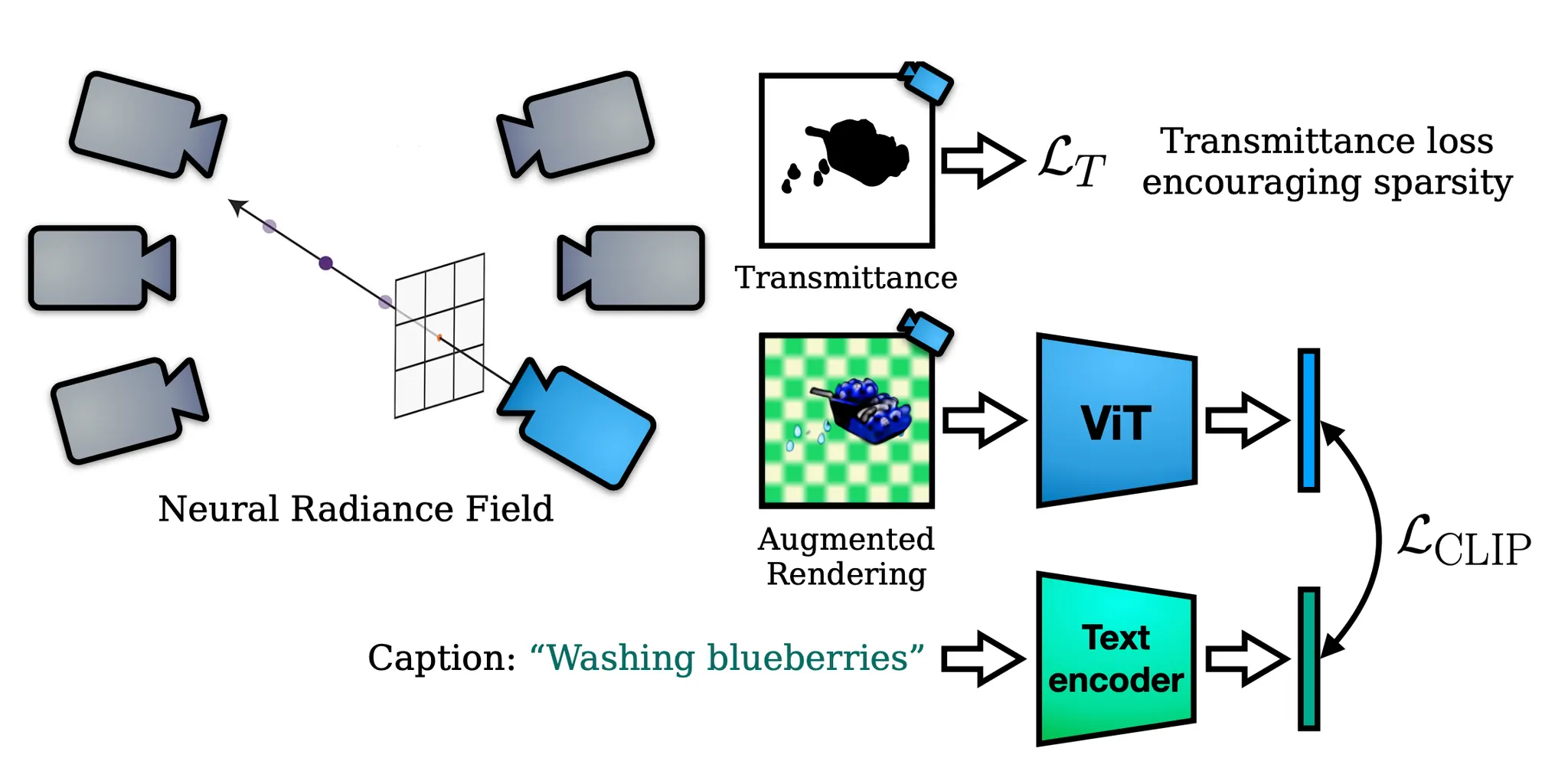
Dream Fields
즉, ground truth 에 가까운 이미지가 렌더링되게하는 color 와 volume density 가 산출되도록 네트워크를 학습하는 것이 아니라, 입력한 텍스트와의 유사도가 큰 이미지가 렌더링되게하는 하는 color 와 volume density 가 산출되도록 네트워크를 학습하는 것입니다. 이러한 목표를 달성하기 위해 논문에서는 다음과 같은 loss 를 설정합니다.
여기서 는 camera pose 이며, camera direction 은 따로 식에 고려되어 있지 않습니다. 이는 NeRF 와는 다르게 ground truth 이미지를 획득한 직접적인 camera pose 및 direction 에 맞게 렌더링을 진행해야 할 필요가 없기 때문으로 보이며, 실제로 논문에서도 camera direction 의 고려가 의미가 없었다고 언급하고 있습니다.
는 caption 이며, 생성하고자 하는 3D 뷰에 대한 Text Prompt 정도로 보시면 됩니다.
는 현재 네트워크의 학습 parameter 인 와 camera pose 를 기반으로 렌더링된 이미지입니다.
와 는 앞서 Image-Text Loss 에서 언급한 notation 처럼 각각 CLIP 의 Image Encoder 와 Text Encoder 입니다.
결과적으로, 최종적인 loss 를 최소화하는 방향으로 진행되는 학습은 CLIP score 를 높게 만들어 렌더링된 뷰가 최대한 텍스트의 설명과 비슷하도록 학습되는 것을 기대한 것입니다. 실제로 이러한 의도로 CLIP 을 사용한 예시로 논문에서 DietNeRF 를 언급하는데, 해당 논문에서는 렌더링된 뷰가 레퍼런스 이미지와 유사하도록 네트워크를 학습하는 방법을 채택했습니다. 해당 논문에서 언급된 문장으로 “a bulldozer is a bulldozer from any perspective” 가 있는데, 이는 해당 논문의 기반이 된 아이디어이자 Dream Fields 에서도 근간으로 삼고 있는 아이디어입니다.
Pose Sampling
DeepDream 을 비롯한 선행연구들에서 Random Cropping 과 같은 Image Data Augmentation 은 흔히 사용되는 방법론입니다. 논문에서는 산출된 color 와 volume density 로부터 다양한 2D 이미지들을 렌더링하기 위해서 각 학습 iteration 마다 다른 camera extrinsic 을 sampling 합니다.
이 때, azimuth 의 경우 영역에서 균일하게 sampling 하였고, elevation 과 focal length 는 augmentation 효과가 없었기 때문에 활용하지 않았다고 합니다. 실제로 azimuth 의 sampling 영역이 좁으면, 평평하고 넓은 판 모양의 geometry 가 등장하는 등의 현상이 발생했다고 합니다.
중요하진 않지만, optimization 과정에서는 focal length 인 로 두어 맺히는 물체의 크기를 1.2 배로 확대하는 과정을 진행했다고 합니다.
Challenges with CLIP guidance
NeRF 는 mutiview 의 일관된 object 를 관측한 이미지들만 있으면 학습된다는 유연한 설계 덕분에 굉장히 다양한 real-world scene 을 정확하게 표현할 수 있었습니다. NeRF 에서 사용한 ground truth 이미지와의 loss 에 기반한 reconstruction loss 는 다양한 관점에서의 ground truth 이미지들이 존재한다는 가정 아래에서 artifact 를 줄일 수 있었습니다.
Challenges of text-to-3D synthesis
하지만 논문의 만을 단독 loss 로 사용하게 되는, 기존의 NeRF 에 비해서 unconstraint 한 환경에서는 NeRF 는 은 작지만 인간이 보았을 때 좋지 못할 정도의 심각한 artifact 들을 나타냈습니다. 일례로, 위 그림의 에서와 같이 high-frequency 이면서 partially-transparent 한 일명 “floating region” 들을 학습했습니다. 또한 특정 object 를 생성하기보다는 전체적인 camera viewport 로 채워진다는 문제점도 있었습니다. 이러한 문제점들을 개선하기 위해 논문에서는 다양한 것들을 도입합니다.
Encouraging coherent objects through sparsity
Partially-transparent 한 “floating region” 을 포함한 near-field artifacts 와 spurius density 문제를 해결하기 위해 논문에서는 Dream Field rendering 의 opacity 를 최대화하는 Sparsity Regularization 을 추가합니다. 논문에서 얻어낸 최고의 결과는 ray 를 따라 존재하는 discrete 한 좌표들의 transmittance 의 average 값을 최대화함으로써 얻어낼 수 있었다고 합니다. (논문에서 자세히 설명해주진 않지만, 아마 하나의 ray 가 아니라, 하나의 렌더링된 뷰에 사용된 모든 ray 관점인 것 같습니다.)
이러한 설계는 기존의 NeRF 에서 만을 단독으로 사용했을 때 나타났던 문제점을 해결하기 위함이었습니다. Transmittance 를 최대화하여 흐릿한 영역을 최소화하고 선명한 이미지를 얻고 싶었다- 라고 보시면 됩니다. 다만, 완전히 투명해버리면 안되기 때문에 적절한 수준의 transmittance 를 목표로 해야했고, 이러한 설계는 아래와 같은 수식으로 드러나게 됩니다.
위 식에서 가 목표로 하는 target transmittance 라고 보시면 됩니다. operator 를 통해 목표치 이상으로 transmittance 가 커지는 것을 식에서 유도하고 있지는 않은 것을 보실 수 있습니다. 이러한 목표치는 대략 정도로 사용했다고 하며, 더불어 500 iterations 뒤에 목표치를 정도로 내려 학습을 진행했다고 합니다. 다른 세팅의 실험에서 해당 regularization 의 도입하는 경우를 고려해 논문에서는 이러한 의 설정으로 를 제안했습니다.
하지만, transmittance 가 목표치인 에 가까워지면서 발생했던 문제점들도 있었다고 합니다. 렌더링 과정에서 사용한 black, white background 를 optimization 과정에서 뷰를 생성할 때 해당 배경을 가지도록 학습하는 부작용이 관찰되었고, 논문에서는 background 와 view 를 분리하여 background 가 view 에 포함되지 않도록 하기 위해 optimization 과정에서 background augmentation 을 진행했습니다.

Background Augmentation
논문에서는 Gaussian Noise, Random Fourier Textures, Checkerboard Pattern 등을 background 로 사용했고, 여기에 랜덤하게 sampling 된 standard deviation 에 기반한 gaussian blurring 을 거쳤다고 합니다.
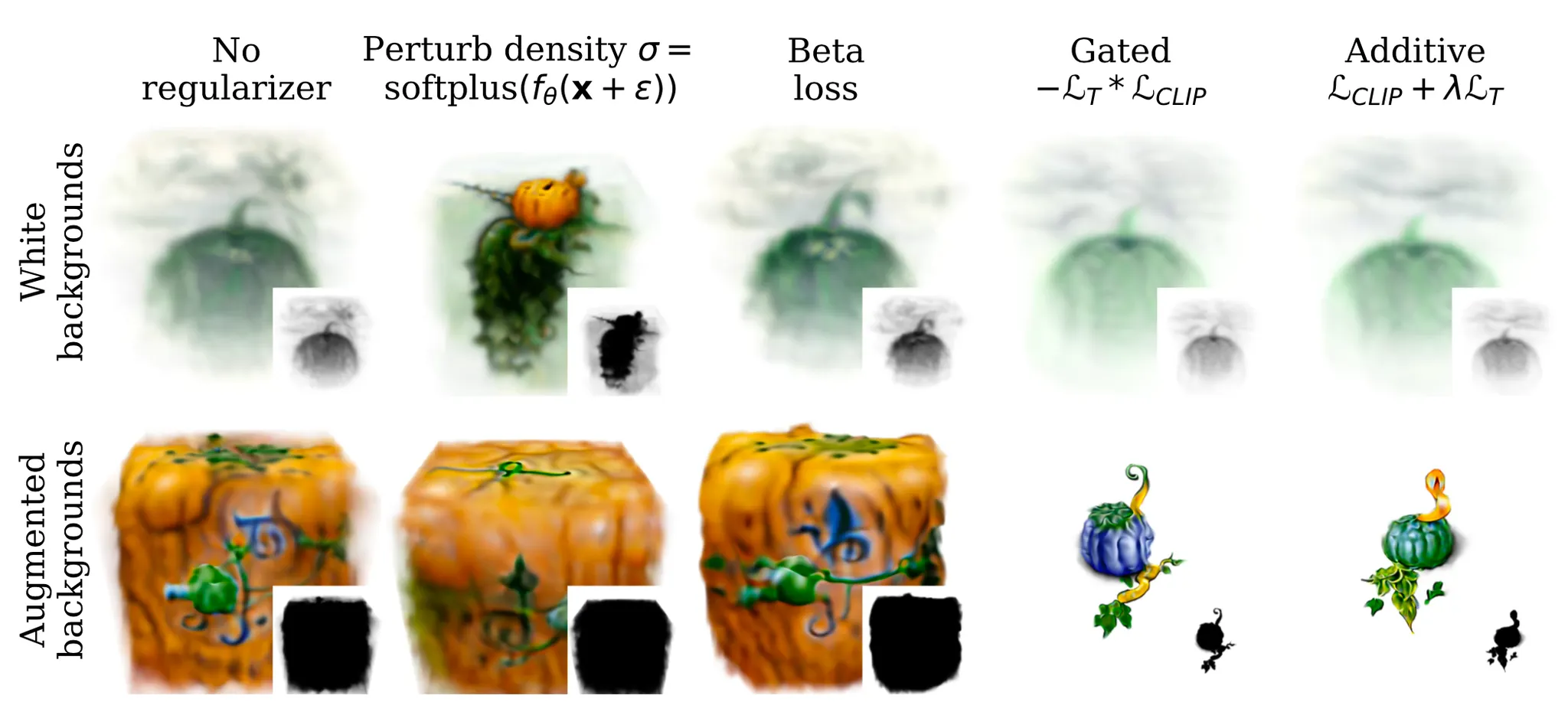
Complementary of Transmittance and Background Augmentation
이러한 논문의 두 설계가 실제로 유의미했다는 것을 보여주기 위해 논문에서는 위 그림을 들고 옵니다. Background Augmentation 없이는 Transmitance Regularization 를 도입하더라도 low density strucuture 들을 지울 수 없었고 (우측 상단), 반대로 Background Augmentation 이 있어도 Transmittance Regularization 없이는 background 에 불투명한 물체가 생성되는 현상 (좌측 하단) 이 발생했다고 합니다. Background Augmentation 과 Transmittance Regularization 을 모두 사용했을 때 (우측 하단) 비로소 선명하고 뚜렷한 물체를 얻어낼 수 있었습니다.
Localizing objects and bounding scene
NeRF 가 학습될 때는, 학습 데이터셋으로 사용되는 이미지들의 중심과 같은 기준으로 Scene 을 구성하고 있는 요소들이 동일한 기준으로 align 될 수 있습니다. 즉, 따로 무언가 손을 쓰지 않더라도 데이터셋의 구성 자체가 중심점이 서로 일치하기 때문에 이들을 기반으로 뷰를 성공적으로 재구성할 수 있었던 것입니다.
하지만, Dream Fields 는 ground truth 가 아닌, CLIP 기반이 Text-Image Loss 로 학습이 되기 때문에 설정한 중심을 기준으로 학습을 진행해도 CLIP loss 를 작게 유지하면서 center 로부터 멀리 떨어진 곳에 density 를 할당할 수 있는 문제점이 있었습니다.
이 때문에, 논문에서는 매 training 마다 현재 학습된 네트워크의 기준으로 산출된 rendering density 를 사용해 이들의 이동평균을 계산하여 전체적인 3D 물체의 중심점을 예측하고, 이 중심점을 기준으로 ray 를 shifting 하는 과정을 진행했다고 합니다. 더불어, 물체가 너무 멀리 움직이는 것을 방지하기 위해 Cube 범위 내에 scene 을 bounding 시키기 위해 density 를 할당하는 형태를 사용했다고 합니다. (구체적으로 설명은 되어 있지 않네요.)
Neural scene representation architecture
NeRF 에서 공개한 그들의 Network Architecture 는 아래와 같습니다. 8 개의 MLP 로 volume density 를 출력해내고, camera direction 정보를 추가하여 color 를 출력해냅니다.
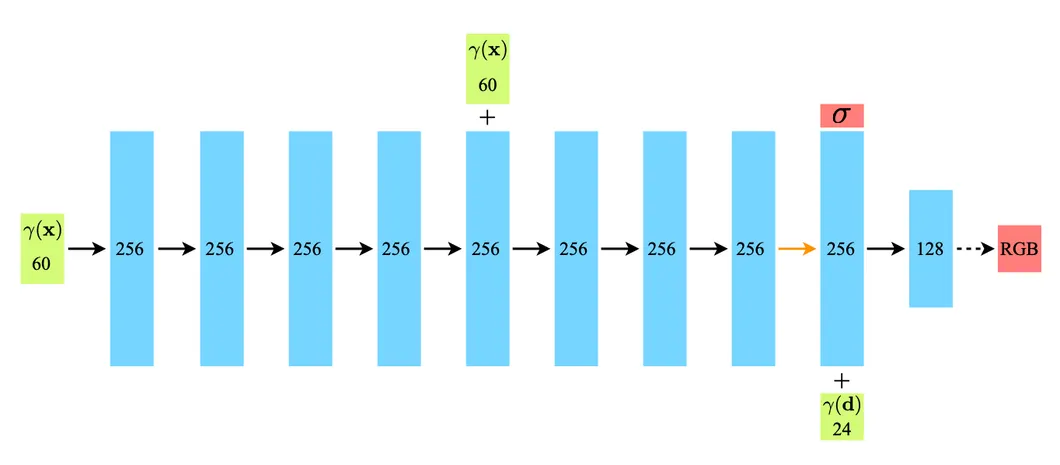
NeRF Network Architecture
논문에서는 이러한 NeRF 의 기본적인 네트워크 구조에 residual connections 를 두 개의 layer 간격마다 추가합니다. 더불어 처음에 Layer Normalization 을 사용하고, feature dimension 을 증가시키는 변화를 주는 것이 성능에 좋음을 찾아냈다고 합니다. 특히 Layer Normalization 을 사용하는 것이 어려운 텍스트에 대한 뷰 생성에 도움을 주었다고 합니다. 이 외에도 ReLU 를 Swish 로 변화시키고, 를 rectify 하는데 softplus 를 사용하는 등의 변화를 주었다고 합니다.
Evaluations
일반적으로 3D reconstruction task 의 평가는 ground truth 레퍼런스 모델과의 Chmfer Distance 와 같은 metric 으로 진행하지만, 논문의 task 는 레퍼런스가 될 모델이 없기 때문에 평가하기에 어려웠습니다. 이러한 상황에서 논문에서는 렌더링된 이미지가 얼마나 텍스트를 잘 표현하는지를 측정하는 지표로 CLIP R-Precision metric 를 선택하여 모델을 평가하게 됩니다. (기존에 설명드렸던 CLIP 의 Text-Image 유사도와 같습니다만, 특정 텍스트에 대한 retrieval 로 precision 을 뽑는다는 점에서 이렇게 명명한 것 같습니다.)다만, Dream Fields 를 학습할 때 사용한 CLIP 과는 다른 것을 평가할 때 사용하여 학습한 데이터로 평가를 하게 되는 것과 비슷한 형태의 오류를 범하지 않도록 설계합니다.
이렇게 설계한 평가에서 논문에서는 크게 다음과 같은 항목들을 평가합니다.
1.
생성된 물체와 장면 표현이 주어진 텍스트와 일관된 형태로 잘 표현되는지에 대한 평가
2.
정성적인 결과물에 대한 평가
3.
Ablations 에 대한 평가
Analyzing retrieval metrics
논문에서 제시한 세부적인 방법론 각각을 평가하기 위해서, 논문에서는 Simplified NeRF 로부터 하나하나 prior 를 추가해가면서 평가를 진행합니다. COCO GT Image 로부터 caption 을 따와 텍스트로 사용했고, 하나의 텍스트 당 두 번의 생성 과정을 거쳤으며, 총 306 개의 생성을 진행한 결과를 평가했다고 합니다. 평가를 진행한 CLIP 모델은 와 로, 텍스트와의 alignment 를 측정했습니다.
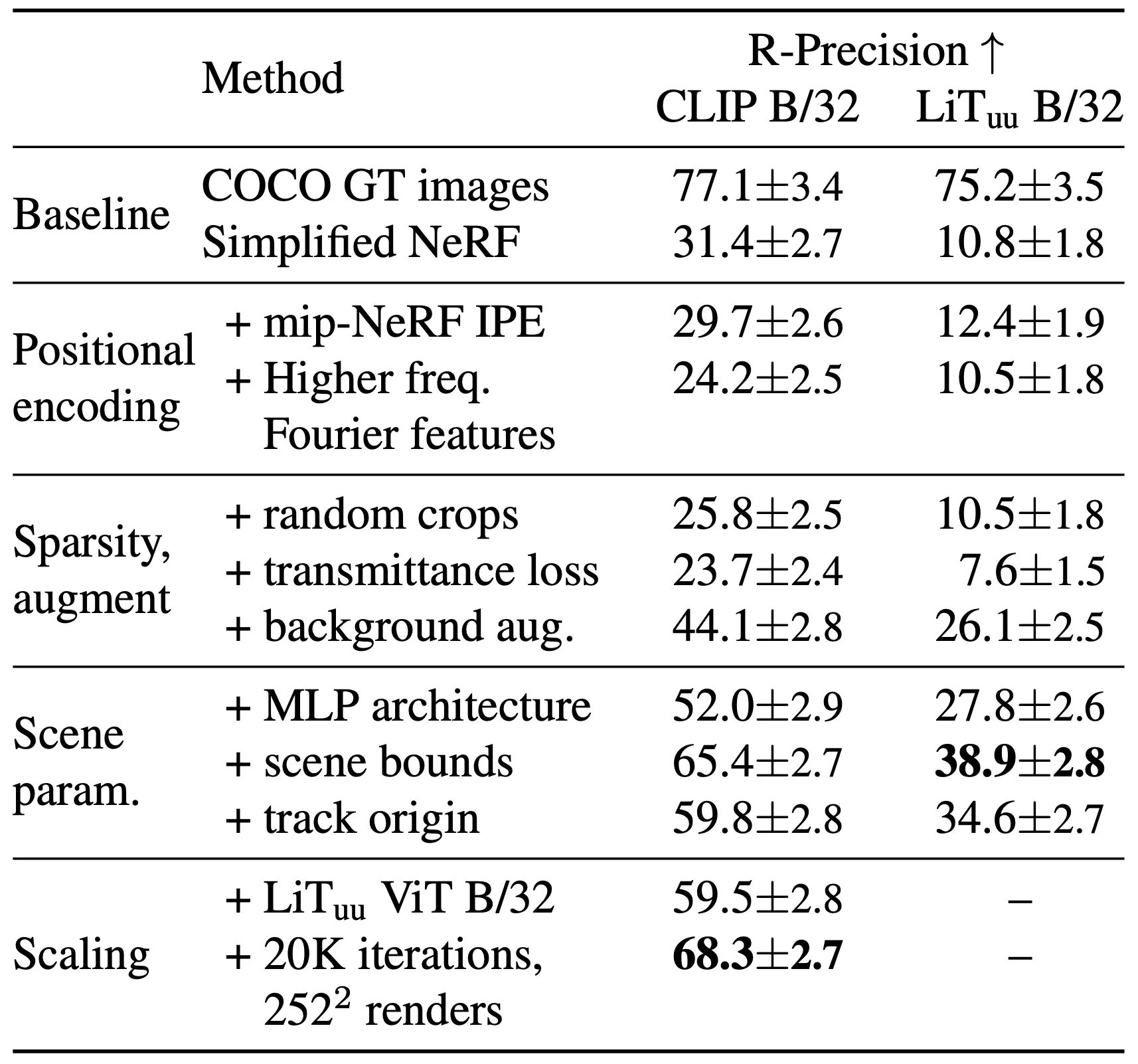
Analyzing Retrieval Metrics
기존 NeRF 의 PE 에서 벗어나 mip-NeRF 의 IPE 를 사용한 것은 정성적인 결과로 보았을 때는 axis 에 aligned 되는 bias 를 제거해주는 등의 개선이 있었지만, 정량적인 R-Precision 으로 보았을 때는 Simplified NeRF 에 비해서 큰 상승을 가져다 주지 못한 것을 확인할 수 있었습니다.
Transmittance loss 혼자서는 오히려 좋지 못했던 성능이 Background Augmentation 을 합쳐짐으로써 것은 CLIP R-Preision 을 각각 와 를 올려 준 것을 확인할 수 있었습니다. 이는 이전에 Transmittance Loss 와 Background Augmentation 의 Complementary 에서 간략하게 설명드린 적 있던 부분입니다.
더불어 기존의 NeRF 에서 Residual Connection, Layer Normalization 를 추가하고 Bottleneck-Style feature dimension (초반에 feature dimension 증가), Smooth 한 Nonlinearity (Swish, softplus) 로 교체한 것을 통틀어 MLP Architecture 로 묶었고, 이는 와 의 성능 상승이 있었습니다.
Scene 을 Cube 범위 내로 bounding 시킨 것 또한 와 의 성능 상승이 있는 주요한 변화였음을 확인할 수 있었습니다.

Varying the Image-Text Model
마지막으로 논문에서는 사용한 Text-Image Model 을 CLIP 에서 로 변경하는 작업을 진행합니다. 이는 기존에 사용하던 것보다 더 큰 training dataset 으로 구성된 pretrained model 이며, high resolution 의 이미지를 input 으로 받습니다. 이는 수치 상으로는 큰 변화를 주지는 않았지만, 정성적인 결과로 볼 때 visual quality 와 sharpness 를 확보할 수 있었다고 합니다.
Compositional generation
논문에서는 COCO GT Image 의 caption 뿐만 아니라, 다양한 조합의 compositional 한 텍스트에서도 생성이 잘 되는지에 대해서 평가합니다. 뼈대가 되는 물체와 구성하는 물질 및 질감들을 독립적으로 다양화하면서 실험을 진행합니다.

Compositional Object Generation
비슷한 실험이 DALL-E 에서 있었지만, 2D 에 한정되어 있었던 반면 논문에서는 3D 에서도 fine-grained 한 다양성을 확보할 수 있었음을 위 결과를 통해 보여줍니다. 반면, 달팽이의 눈이 몸체에 달려 있는 것이나 초록색 vase 가 blurry 한 것 등 디테일이 unrealistic 한 부분들도 있는 것을 확인할 수 있었습니다.
Model ablations
Ablating sparsity regularizer
논문에서 Transmittance 를 regualarize 할 때, 고려할 수 있는 선택지들이 꽤나 있었습니다. 논문에서는 각 선택지들에 대해서 간단하게 소개하고, 그들에 대한 평가결과를 설명해줍니다.

Sparsity Regularizers
Perturb 는 네트워크의 결과에 약간의 섭동을 주는 것입니다. Gaussian Noise 인 만큼의 변화와 softplus 의 activation 으로 정의되는데, 처음 보았을 때 Sparsity Regularizer 로 보기는 힘든 것 같았지만 이러한 설계가 작은 density 를 가지는 결과들을 종종 0 으로 보내버리는 효과를 가져와 sharper boundary 를 만드는데 도움을 주었다고 합니다.
Beta prior 은 Neural Volumes 라는 논문에서 차용한 것이며, Trasmittance 가 아예 높던지, 아예 낮던지로 유도되도록 하는 loss 입니다. 물체가 존재하는 부분은 확실하게 있게, 없는 부분은 확실하게 없게 하자- 는 intuition 에서 온 loss 인 것 같은데, 다음과 같이 계산된다고 합니다. 이는 에 적힌 식입니다.
Gated T 와 Clipped gated T 는 모두 Multiplicative Loss 의 종류인데, 이는 opacity scaling 에서 차용한 것이라고 합니다. Clipped 의 차이는 target transmittance 의 존재여부인데, 앞서 설명한 것처럼 Clipped 에서는 를 로 바꾸어버립니다. 일정 수준 이상의 transmittance 는 오히려 독이 된다고 판단하여 추가한 설계라고 보시면 됩니다. 이는 에 적힌 식이며 다음과 같습니다.
Clipped additive T 는 CLIP Loss 와 Transmittance Loss 를 multiplicative 하게 가져가지 않고 additive 하게 가져가려는 설계입니다. 이는 에 적힌 식이며 앞서 Sparsity Regularizer 를 처음 설명드릴 때 알려드렸던 식입니다.
다시 성능 평가 결과로 돌아와서, Density perturbation 과 Beta prior 는 각각 R-Precision 을 와 상승시킨 것을 확인할 수 있었습니다. 반면 가장 좋았던 clipped mean transimittance regularization 종류는 의 성능 상승을 보여주었습니다. 확실히 논문에서 사용한 방법론의 성능 상승이 제일 크다는 것을 볼 수 있습니다.

The target transimttance affects the size of the generated objects
성능과 별개로 Beta prior 의 경우에는 높거나 낮은 transmittance 모두 유도하기 때문에 종종 불투명한 물체로 가득차는 모습을 볼 수 있었고, Multiplicative 는 clipped 와 함께일 때 black background 에서도 잘 동작했지만, 섬세한 hyperparameter 의 조정이 필요했다고 합니다. 위의 그림은 hyperparameter 중 하나인 target transmittance 값에 따른 생성 물체의 변화인데, transmittance 가 낮을수록 큰 물체가 생성됨을 볼 수 있습니다.
Varying the image-text model
다음으로 ablation 을 진행한 것은 Text-Image Model 입니다.
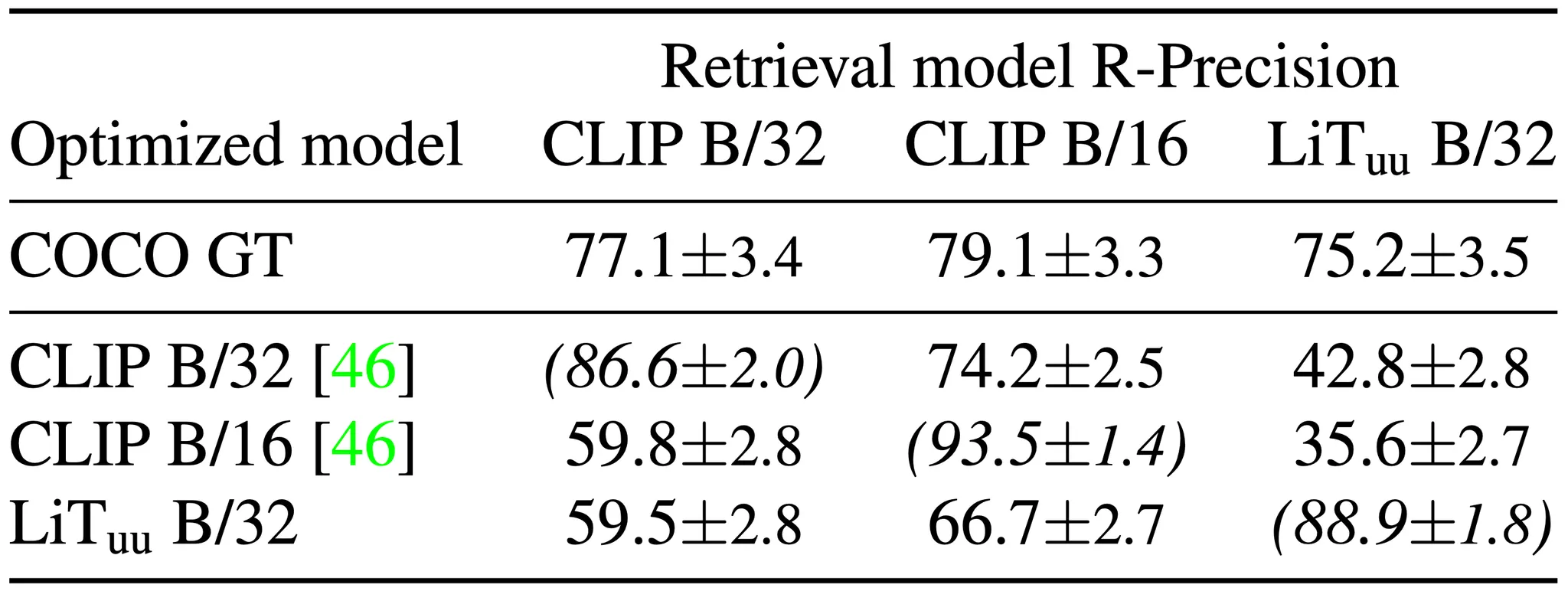
Image-Text Models
논문에서는 크게 세 가지의 Text-Image Model 을 고려사항에 두었고, 각각으로 R-Precision 을 측정한 결과를 평가 지표로 제시하면서 논문의 선택이 최선이었음을 보여줍니다. 이 가장 좋은 성능 지표를 보여주었지만, 정성적인 결과로는 가 가장 디테일한 구조를 보여주었다고 이야기합니다.
Varying optimized camera poses
마지막으로 ablation 을 진행한 것은 camera pose 의 sampling range 입니다. 어찌보면 당연하다고 느낄 수 있는 포인트인데, 논문에서는 sampling range 를 다르게 하여 평가한 것들을 정성적으로 보여줍니다.
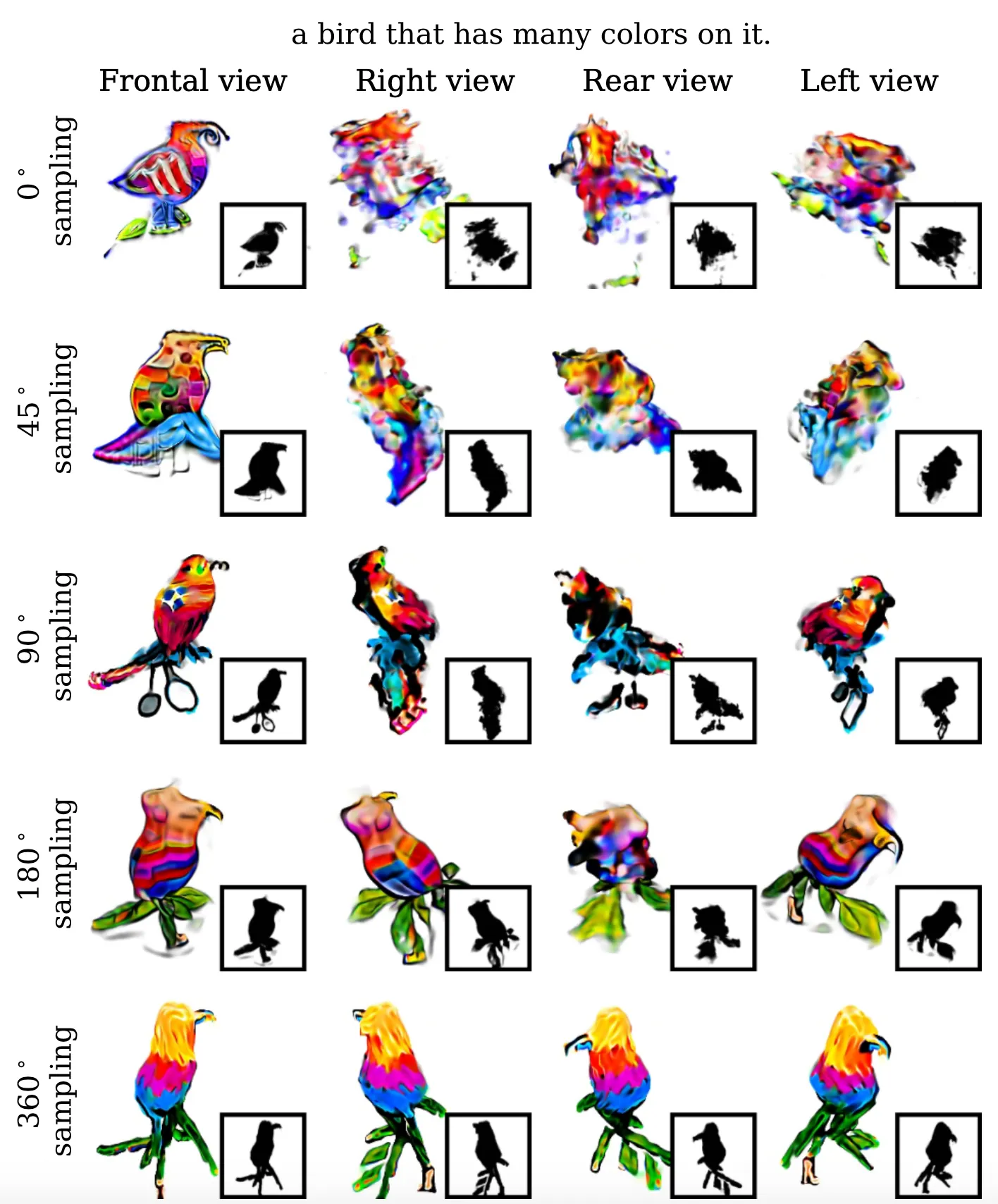
Camera Pose Sampling Range
Frontal view 같은 경우는 range 의 기준이 되는 지점이기 때문에 모든 range 에서 그럴듯한 결과를 볼 수 있었지만, right view, rear view, left view 모두에서 결과가 가장 좋았던 것은 의 azimuth 에서 sampling 한 결과였습니다.
Conclusion
이것으로 논문 “Zero-Shot Text-Guided Object Generation with Dream Fields” 의 내용을 간단하게 요약해보았습니다.
Image-Text Model 인 CLIP 을 활용하는 연구 중에 Optimization 이 아니라 Generation 쪽도 있는 것을 처음 알게 해준 논문이었는데, 코어가 되는 아이디어는 예상한 것보다는 훨씬 간단했던 것 같습니다.
다만, 그 아이디어를 유의미한 성능으로 끌어올리기 위해서 부가적으로 사용했던 Sparsity Regularizer 의 도입, 그리고 이것과 연계하여 사용하는 Background Augmentation, 큰 성능을 가져왔던 MLP Architecture 의 수정 등 생각보다 아이디어만으로 연구가 쉽게 이루어지지는 않는다는 사실을 많이 느꼈던 것 같습니다.