
본 포스트에서는 3D object 의 style 을 편집하는 새로운 방법론인 Text to Mesh 를 제시한 논문에 대해서 소개드리려고 합니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“Text2Mesh: Text-Driven Neural Stylization for Meshes”

Objective
Underlying content 를 유지하면서 특정 Visual Data 를 원하는 형태로 편집하는 것은 Computer Graphics 및 Vision 분야에서 꾸준히 연구되던 주제입니다. 해당 분야의 주된 목적은 Content 와 Style, 그리고 구성요소들을 의도한대로 올바르게 편집하는 것입니다.
여기서 언급되는 Content 는 3D Mesh 를 통해서 표현되는 전체적인 물체의 표면과 위상을, Style 은 local geometric 이나 색상 등으로 정의되는 세부적인 물체의 형태를 의미합니다. 논문에서는 이들을 편집하도록 가이드해줄 레퍼런스를 선택할 때, 화가가 언어를 통해서 작품을 의뢰받는 형태를 떠올립니다. Natural Language 인 Text Prompt 를 통해 전달받은 Stylization 에 대한 레퍼런스로 Underlying Content 를 편집할 아이디어를 낸 것입니다.

Text2Mesh Predictions
이처럼, 논문에서는 Neural Style Transfer 에서 Content Image 를 Style Image 의 Texture 를 반영하는 형태로 수정한 것과 같이 Content 3D Mesh 를 Text Prompt 의 Style 을 반영하는 형태로 편집하는 것을 목적으로 연구를 진행합니다. 이러한 목적을 달성하기 위해 논문에서는 그들이 설계한 특별한 네트쿼크인 Neural Style Field 를 소개합니다.
Method
논문에서 제시한 방법론은 아래의 그림으로 설명할 수 있습니다. 논문의 방법론은 Neural Style Transfer 와 비슷하게 네트워크가 일반적인 inference task 를 위해 학습되는 것이 아니라 네트워크의 학습과정 자체가 inference task 가 됩니다. 즉, 학습과정에서 정의한 Loss 를 기반으로 고정된 Text Prompt 및 Content 3D Mesh 를 Stylization 하는 네트워크를 학습하는 것입니다. 이렇게 학습되는 네트워크를 논문에서는 Neural Style Field 라고 명칭합니다. 이는 아래 그림의 갈색 박스 영역에 있는 네트워크입니다.
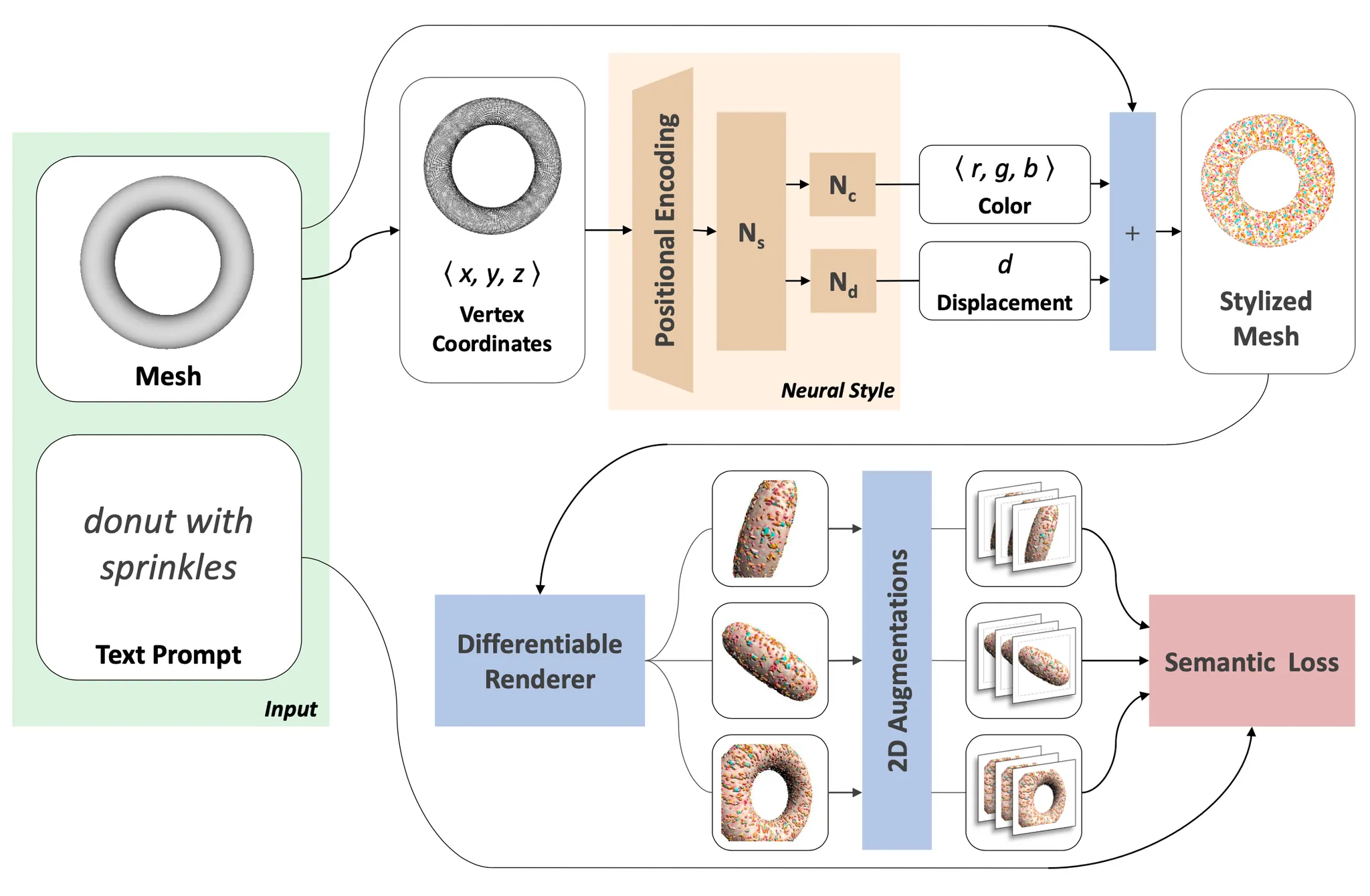
Text2Mesh: Network Architecture
Neural Style Field 를 거쳐서 나오게 된 결과들로 Stylized Mesh 를 형성하면, 형성된 Mesh 가 얼마나 Text Prompt 와 유사한지를 판별해 유사도를 기반으로 Loss 를 정의하고 이를 최소화하는 방향으로 네트워크를 학습하게 됩니다. 이 단계에서 논문에서는 2D image 와 Text Prompt 사이의 유사도를 판단해줄 수 있는 모델인 pretrained CLIP 을 활용하기 위해서 3D Mesh 로부터 Differentiable Renderer 를 사용해 2D images 들을 추출해냅니다. 이를 기반으로 2D Augmentation 들을 진행하여 최종적인 Semantic Loss 를 계산해 weight update 하는 과정을 진행하는 것입니다.
각각의 과정은 아래에서 자세하게 다루도록 하겠습니다.
Neural Style Field Network (NSF)
Neural Style Field Network (NSF) 는 3D Mesh 의 vertex 내의 points 들을 입력으로 받아 특정 point 에 대해서 각 point 가 가져야할 normal 방향의 displacement 와 vertex color 들을 산출합니다. Point 의 normal 방향으로만의 이동을 강제한 constraint 는 레퍼런스로 제공된 input mesh 로부터의 과도한 변경을 방지하는 역할을 했다고 합니다.
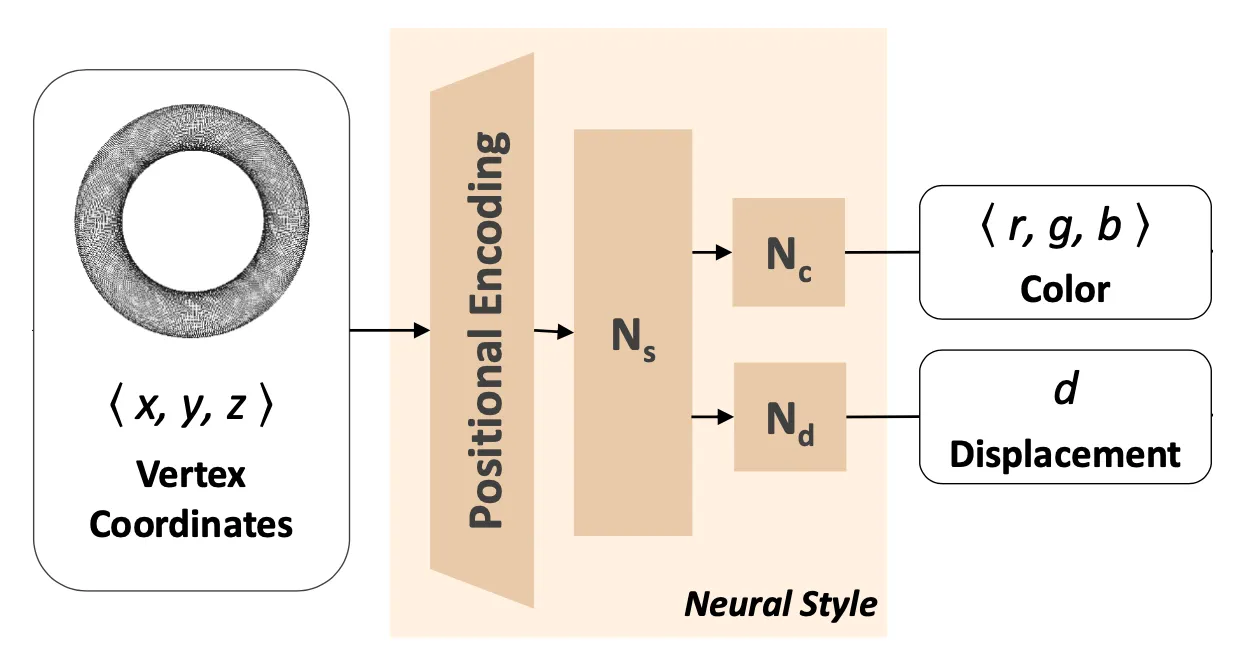
Neural Style Field Network (NSF)
NSF 에 input 으로 들어간 들은 가장 먼저 unit bounding box 에 속하게끔 normalize 됩니다. 이후에 각각의 point 들은 NSF 를 구성하는 첫 번째 요소인 Positional Encoding 에 의해 변환됩니다. 기존의 NSF 에 input 으로 들어갈 데이터는 coordinate 형태였고, 이를 가공 없이 그대로 사용할 경우 네트워크가 간단한 function 을 학습하도록 편향되는 spectral bias 가 나타날 수 있습니다. High-frequency detail 을 가지는 결과물을 산출하기 위해서 논문에서는 positional encoding 방법론을 사용했고 이는 다음과 같이 특정 point 를 high dimension 으로 mapping 하는 과정입니다.
이 때, 이며 의 각의 항목은 에서 랜덤하게 sampling 되었다고 합니다. 따라서 이를 계산하면 dimension 의 tensor 가 나오게 됩니다. 이 때 는 학습하는 style function 의 frequency 를 조절하는 hyperparameter 로 작용하게 됩니다. 부가적으로, 가 랜덤하게 sampling 되기는 하지만, 하나의 네트워크를 정의할 때는 (랜덤하게 sample 된) 고정된 를 사용하게 됩니다.
Positional Encoding 으로 dimension 이 확장된 input 은 MLP 에 들어가게 됩니다. 이렇게 로 한 번 feature extraction 을 진행한 뒤에 나타나는 feature 는 다시 각각 vertex normal 방향으로의 displacement 를 나타내는 값을 regress 하는 네트워크 와 해당 vertex 의 color 값을 regress 하는 네트워크 로 들어가게 됩니다. 네트워크에서 의 결과물로 normal 방향의 displacement 를 산출하고, 의 결과물로 vertex 의 color 값인 를 산출하게 됩니다. 앞서 displacement 가 normal 방향으로만 주어진 constarint 가 content 와 괴리가 큰 결과물을 산출하지 않기 위함이라고 말씀드린 것처럼, 여기서도 이라는 constraint 를 주어 content 와 심하게 차이나는 결과를 생성하지 않도록 제한했습니다.
최종적인 stylized mesh prediction 를 얻어내기 위해 각각의 point 는 로 displacement 가 이루어지고 로 colorized 됩니다. 다만, training 과정 중에 color 가 적용되지 않은 displacement-only mesh 도 논문에서 사용하여 최종적인 loss 를 정의하는데 사용하게 됩니다. 이는 이후의 ablation study 에서 한 번 더 다룰 예정입니다.
Text-based correspondence & Augmentation
NSF 로 생성된 stylized mesh 에 대해서 Text 기반의 유사도를 CLIP 으로 측정하기 위해서는 3D Mesh 로부터 differentiable rendering 을 통해 2D image 를 산출해내는 과정이 필요합니다.
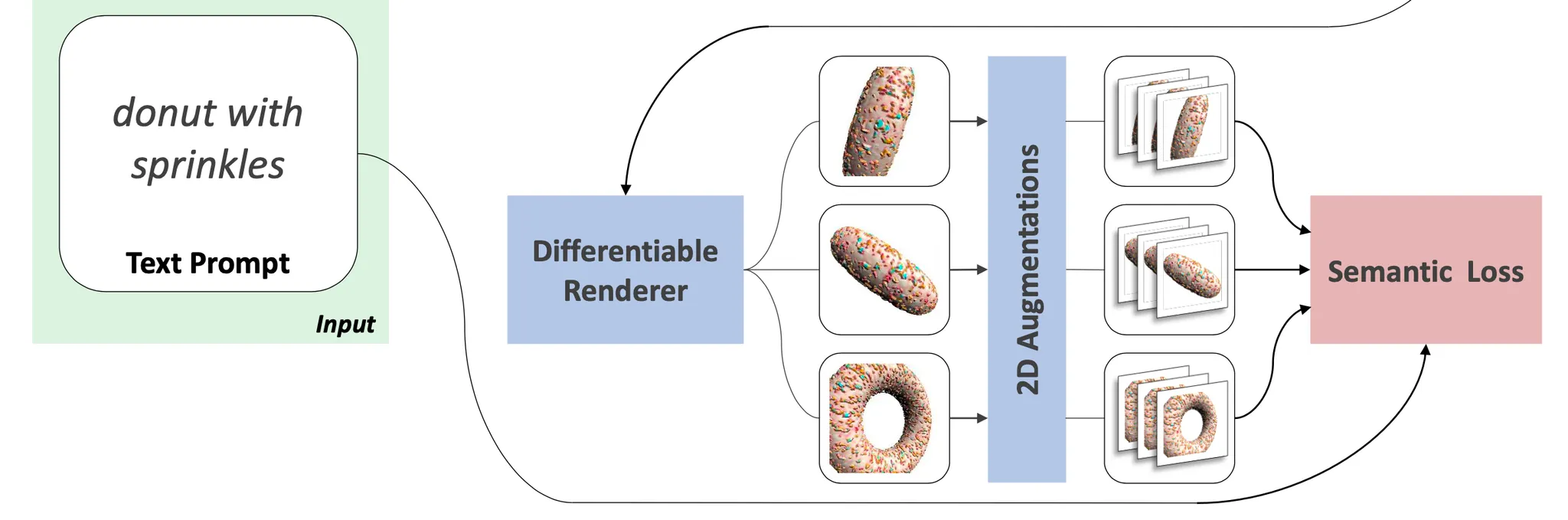
Text-based correspondence
가장 먼저 진행하는 것은 Content 3D Mesh 에 대해서 anchor view 를 찾는 과정입니다. 이 과정은 초기에 한 번만 진행하는 과정으로, 어떤 view 근처에서 CLIP 이 가장 유사도를 측정하기 용이한지를 찾아내는 과정입니다. 이를 위해서 3D Mesh 를 감싸는 구에서 일정한 간격의 view 를 렌더링 하여 CLIP similarity 를 계산하고 그것들 중에서 가장 높은 점수를 가진 view 를 anchor view 로 설정하게 됩니다.
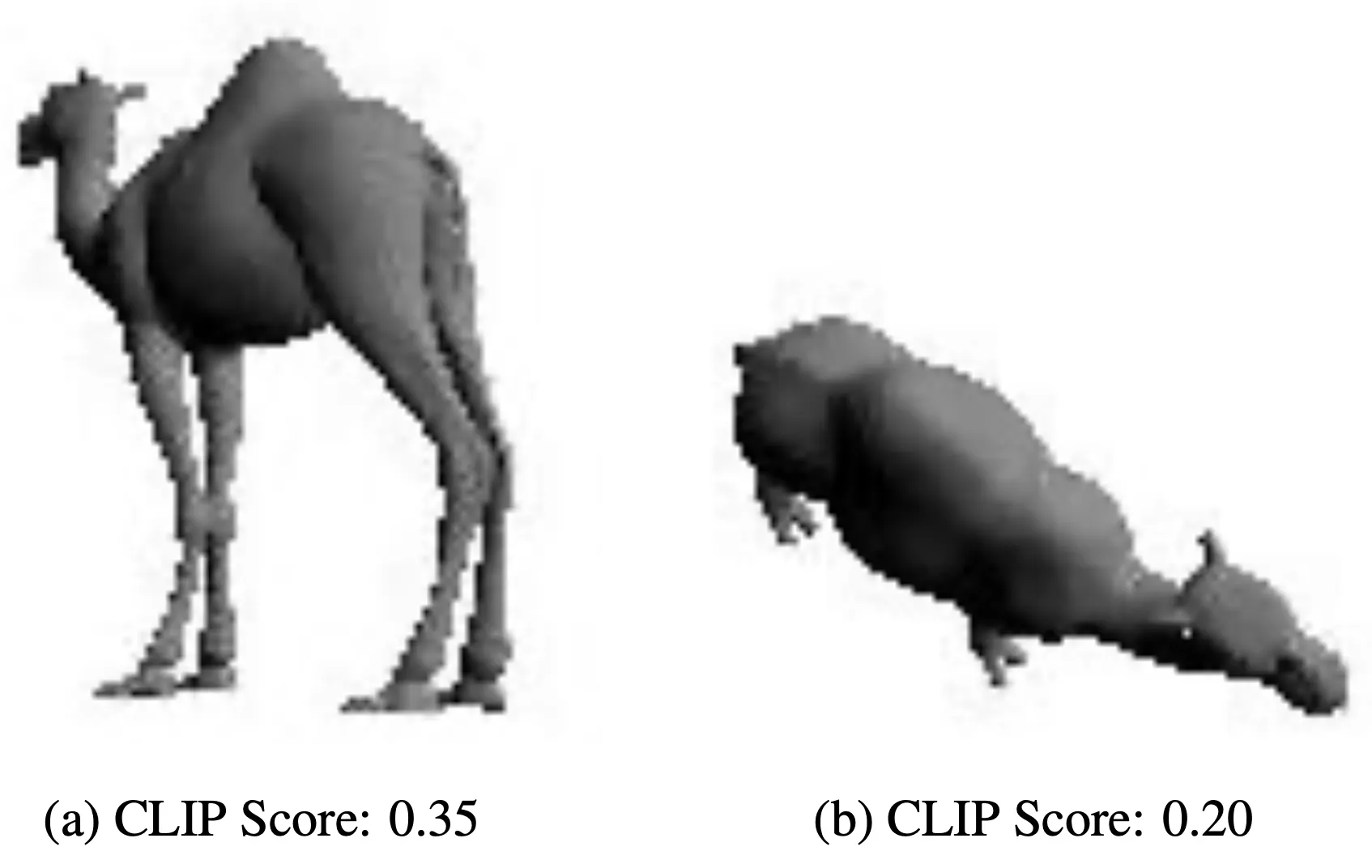
Finding Anchor View
위의 그림처럼 낙타를 더 잘 표현해줄 수 있는 view 를 찾는 과정이라고 보시면 됩니다. 이렇게 anchor view 를 찾은 이후에, 해당 view 근처에서 개의 view 를 sampling 하고 이를 differentiable renderer 를 통해 2D image 로 렌더링합니다. 이 때, 동일한 view 에 총 두 개의 이미지를 렌더링해내는데 하나는 에서 렌더링한 , 다른 하나는 에서 렌더링한 입니다.
이렇게 하나의 view 당 2개의 이미지를 얻어냈다면, 이를 다시 2D Augmentation 을 진행합니다. 이는 네트워크가 degenerated solutions 들을 산출하는 것을 방지하기 위해 사용한 방법론이라고 합니다. 논문에서는 augmentation 을 크게 과 로 나누어 정의하는데, 은 random perspective transform 만을, 은 random perspective transform 과 기존 이미지의 10% 크기의 random crop 이 포함된 augmentation 을 사용했습니다. 의 random cropping 은 이후 설명할 CLIP 에 입력으로 넣을 이미지를 localized 한 영역에 집중할 수 있도록 하여 Text Prompt 로 부터 localized geometry 도 반영할 수 있게끔 설계한 것으로 보입니다.
이렇게 정의한 2D Augmentation 을 앞서 얻어낸 view 에 적용하게 되는데 에는 과 을 각각 적용하고, 에는 만을 적용했다고 합니다. 논문에서 자세한 이유는 설명해주지는 않지만, 개인적으로 에 두 augmentation 을 적용한 기본 버전에 비해서 localized region 에 대한 improvement 를 위해 추가적으로 색상에 치중하지 않은 정보를 기반으로 추가적인 loss term 을 정의한 것으로 보고 있습니다. 이렇게 view 마다 산출해낸 이미지들에 2D Augmentation 을 적용한 값 CLIP embedding 를 거친 뒤에 average 연산을 하여 최종적인 augmented representation 을 아래와 같이 정의하게 됩니다.
이렇게 정의한 augmented representation 들에 대해서 최종적인 loss 는 아래와 같이 정의합니다.
위 식에서 은 Text Prompt 에 대한 CLIP embedding 이며, 연산은 벡터간의 cosine 유사도 를 의미합니다. 논문에서는 하나의 iteration 에서 이 과정을 번 반복하여 augmentation 을 진행한다고 합니다.
더불어, 과 은 기반으로 생성된 representation 이기 때문에 모두의 paramter update 에 영향을 주지만 은 기반으로 생성된 representation 으로 의 output 을 가지고 생성된 정보가 아니기 때문에 의 paramter update 에만 영향을 주게 됩니다. 이러한 geometry-only loss 와 geometry-and-color loss 의 분리는 논문의 방법론에 긍정적으로 기여했다고 합니다.
Experiments
논문에서는 그들의 방법론을 COSEG, Thingi 10K, ShapeNet, Turbo Squid, ModelNet 등의 다양한 input source mesh 와 Text Prompt 들에 대해서 평가합니다. 전체적으로 논문에서는 특별한 quality constraint 및 preprocessing 없이 넓은 범주의 3D shape 들을, low-quality mesh 임에도 불구하고 비교적 짧은 시간 (less than 25 minute on a single GPU) stylize 할 수 있었음을 시사합니다.
Neural Stylization and Controls
가장 먼저 논문에서는 논문의 방법론으로 생성해낸 Stylized Result 에 대해서 보여줍니다.

1. Stylized Meshes
위 그림에서 Vase 를 Content 3D Mesh 로 하여 Colorful Crochet 이라는 target text prompt 가 주어진 경우 생성된 3D Mesh 가 Vase 의 기하학적 구조를 유지하면서 다양한 색깔의 knit pattern 을 잘 보여주는 것을 볼 수 있습니다. 더 나아가, 논문의 네트워크는 날카로운 곡선과 특징에 알맞은 구조화된 질감을 생성해줍니다. 이는 Text Prompt 가 Brick 으로 주어진 경우에서 잘 드러납니다.

2. Various Stylization of Human Bare Mesh
위 그림은 Human Bare Mesh 를 input 으로 주어 다양한 Text Prompt 를 이용해 stylization 한 결과입니다. 이 결과를 통해 논문의 방법론이 human 의 global semantic 에 대한 이해를 표현해낼 수 있음을 보여주었습니다. 다리, 머리, 근육 등 human 의 각기 다른 부분이 그 각각의 semantic role 에 기반하여 stylize 된 것을 확인할 수 있었고 그러면서도 이들이 서로 괴리감 없이 합쳐진 모습을 볼 수 있었습니다.

3. Stylization Applied on Entire 3D shape
위 그림은 논문의 네트워크가 일관적인 형태로 3D shape 전체를 stylization 해주는 것을 보여주는 그림입니다. 이러한 stylization 은 질감의 자연스러운 변화를 표현해줄 수 있다고 합니다.
논문에서는 이어서 논문의 방법론을 인위적으로 조절할 수 있는 몇가지 메커니즘들을 소개합니다.
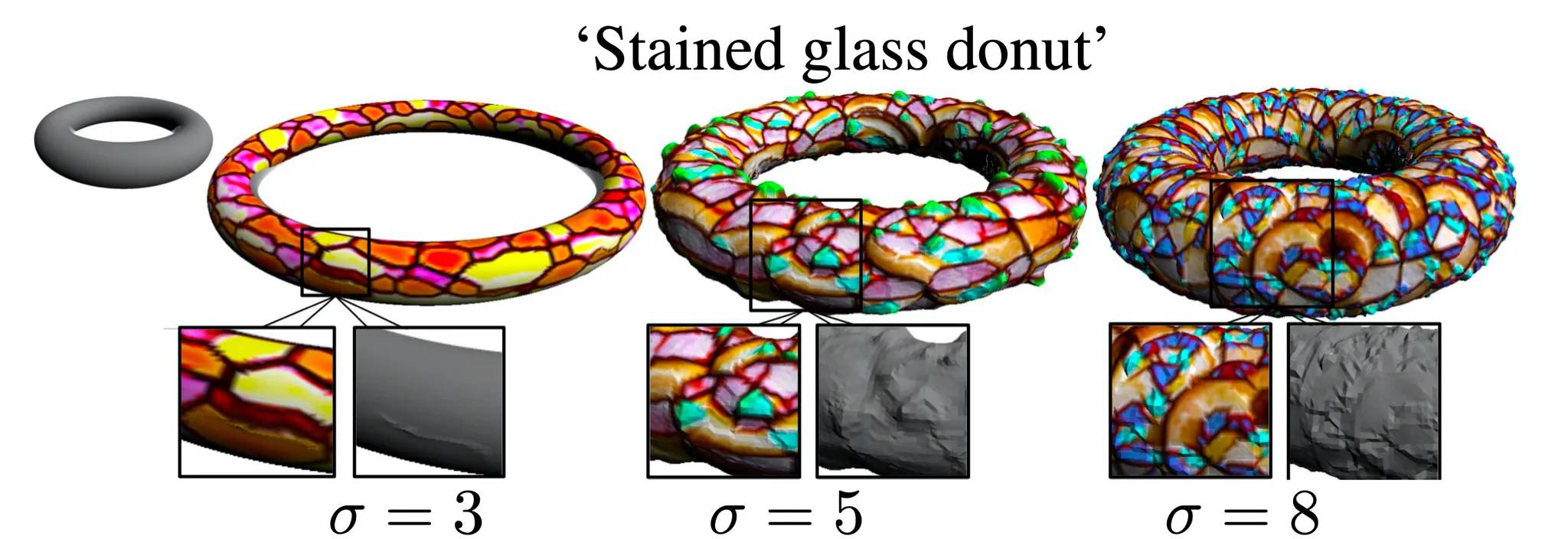
4. Fine Grained Controls
위의 그림은 positional encoding 단에서 등장한 matrix 의 각 요소들을 sampling 한 distribution 의 standard deviation 의 값에 따른 결과의 변화를 나타낸 것입니다. 의 값이 커질수록 3D Mesh 를 표현하는 값들의 frequency 가 커지게 되고 이에 따라 normal 방향으로의 displacement 의 크기에 대한 frequency 도 커지게 됩니다. 이렇게 논문에서는 그들의 방법론이 specificity 의 level 에 따라 다양한 style 을 형성할 수 있는 능력을 가지고 있음을 보여줍니다.

5. Varying Levels of Text Prompt Specificity
위의 그림은 Text Prompt 를 점차 세분화하여 주었을 때 네트워크가 생성해낸 3D Mesh 의 모습 변화입니다. 위의 그림의 첫 번째 행은 좌측부터 Lamp, Luxo Lamp, Blue Steel Luxo Lamp, Blue Steel Luxo Lamp with corrugated metal 을 Text Prompt 로 주었을 때의 결과입니다. 논문에서는 Text Prompt 가 세분화 되기 후에도 세분화 되기 전의 스타일 특성들을 유지한 채 스타일이 추가되는 형태의 3D Mesh 생성을 보여주었다고 하며, 이를 통해 어느정도 생성하고 싶은 3D Mesh 의 형태를 조절할 수 있음을 시사했습니다.

6. Various Levels of Sphere Protrusion
위의 그림은 같은 Text Prompt 인 Cactus 를 주었을 때, Content 3D Mesh 로 사용한 Sphere 의 protrusion 정도의 세분화에 따른 생성된 3D Mesh 의 모습 변화입니다. 결과물은 기존의 Content 3D Mesh 의 protrusion 을 유지한 채로 stylization 이 된다는 것을 알 수 있었고 이를 통해 네트워크가 Text Prompt 가 같더라도 Content 3D Mesh 의 형태를 유지하여 style 을 반영할 수 있다는 사실을 보여주었고 그러면서도 stylization 의 quality 가 손상되지 않았다는 것을 보여줍니다.

7. Morphing between Two Text Prompt
위의 그림은 동일한 Content 3D Mesh 를 사용하고, Text Prompt 로 wooden chair 를 준 경우와 Text Prompt 로 colorful crochet chair 를 준 경우 사이의 RGB 와 displacement 를 구해서 그 사이를 linear interpolation 하는 형태로 morphing 하여 생성한 3D Mesh 들입니다. 논문에서는 이렇게 특정 두 결과물 사이의 값으로 최종 결과물을 생성하기 위해서 morphing 을 활용하여 조절할 수 있다는 것 또한 보여줍니다.
Text2Mesh Priors
논문의 방법론은 GAN 과 같은 생성모델이 필요하지 않게 해준 여러가지 prior 들로 구성되어 있습니다. 논문에서는 그들이 사용한 prior 들이 유의미함을 보여주기 위해 ablation study 를 진행합니다.

8. Ablation Study of Priors
의 경우는 NSF 를 사용하지 않은 경우입니다. NSF 를 제거한 대신 직접적으로 color 와 displacement 를 optimize 했습니다. 그 결과 생성된 3D Mesh 가 굉장히 nosiy 하고 arbitrary 한 displacement 를 보여주었습니다.
의 경우는 2D Augmentation 을 진행하지 않은 경우입니다. Exploring text-to-drawing synthesis through language image 논문에서 이 과정이 필수적이었다고 했던 것과 상응하게, 논문에서도 해당 과정을 진행하지 않았을 때 target Text Prompt 와 완전히 부합하지 않는 결과물이 생성됨을 확인할 수 있었습니다.
의 경우는 Fourier Feature Encoding 을 진행하지 않은 경우입니다. 앞서 말씀드렸던 positional encoding 을 하지 않은 경우라고 보시면 됩니다. 그 결과 input dimension 이 줄어든만큼 fine detail 들을 잃은 결과물이 생성됨을 확인할 수 있었습니다.
의 경우는 cropping augmentation 만 제거한 경우입니다. 이 또한 local region 에 대한 세부적인 detail 을 잃은 결과물을 보실 수 있습니다.
의 경우는 의 geometry-only component 를 제거한 경우입니다. 이는 geomtric refinement 를 제거하여 전체적인 모양은 그럴듯하지만 세부적인 느낌을 제대로 묘사하지 못한 결과물을 보실 수 있습니다.
의 경우는 3D Content Mesh 가 없는 경우이고 3D space 에서 2D plane 을 input 으로 넣어 얻어진 결과물입니다. 논문에서도 딱히 보여주기만 하고 언급이 없어 이 결과에 큰 의미를 부여하지는 않은 것 같아 보입니다.
결과적으로는 모든 ablation case 들보다 모든 prior 들을 보유하고 있는 의 경우가 가장 높은 CLIP similarity score 를 가짐을 알 수 있었습니다. 별개로 또한 꽤나 높게 점수가 할당되었는데 이러한 예시가 CLIP 이 degenerative solutions 들을 고평가하게 되는 안 좋은 예시인 것 같다고 합니다.
논문에서는 부가적으로 을 구성하는 각각의 요소들이 최종적인 결과에 긍정적으로 작용한다는 것을 추가적으로 보여줍니다.
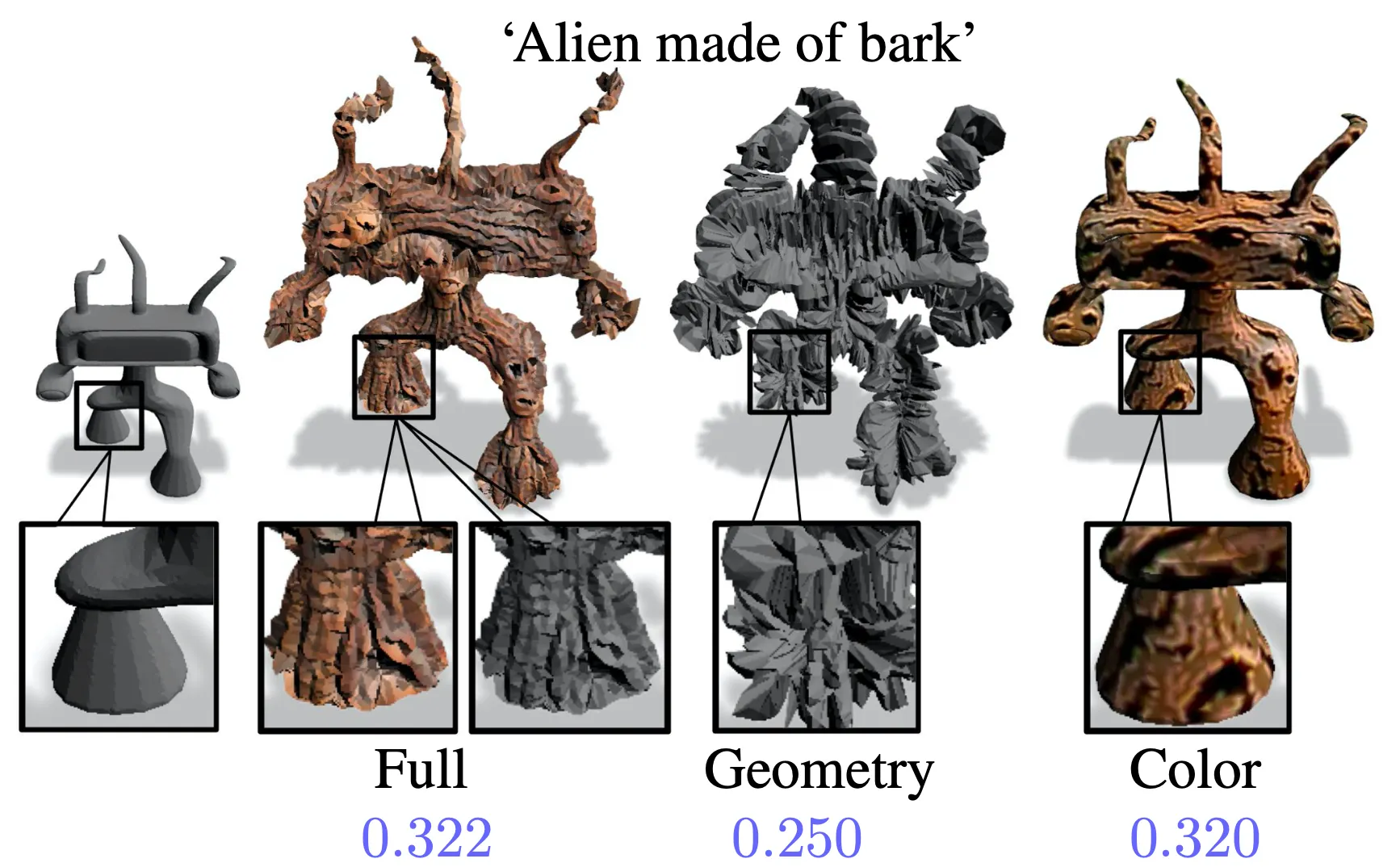
9. Interplay of Geometry and Color
먼저, Geometric 만 추론하려고 학습하는 것은 geometry 와 color 를 모두 학습하는 것에 비해서 좋지 못한 기하학적 구조를 보여줍니다. 이는 구조의 displacement 변화를 이용해 반강제적으로 음영을 만들어 CLIP score 를 높이는 방향으로 학습을 진행하기 때문으로 보고 있습니다. 이는 2번 사진의 배트맨의 예시에서 발견할 수 있는 side effect 인데, 해당 3D Mesh 에서 배트맨 문양을 만들기 위해 깊게 파인 구조를 통한 음영을 생성했습니다.
비슷하게, Color 만 추론하려고 학습하는 것은 반대로 돌출 부위 등의 gemoetric detail 을 검은 색상으로 칠해 있는 것마냥 생성해버리는 결과가 나타납니다. 이는 결과적으로는 CLIP score 측면에서 높을지 몰라서 flat 하고 좋지 못한 3D texture 를 생성해내는 등의 좋지 못한 구조를 보여주는 원인이 됩니다.
따라서 이들을 요소를 모두 활용하는 것이 좋다고 하며, 실제로 위 그림의 같이 색감 및 기하학적 구조도 좋으면서 CLIP score 도 높게 가져갈 수 있는 형태의 3D Mesh 가 생성됩니다.
Stylization Fidelity
논문의 방법론은 일반적인 Text 기반으로 Mesh 를 stylize 하는 task 에 기반하고 있습니다. 하지만, 기존에 이러한 task 에 대한 접근이 일절 없었기 때문에 논문에서는 VQGAN-CLIP 의 방법론을 확장하여 비교한 결과를 보여줍니다. VQGAN-CLIP 은 3D source shape 에 대한 투영된 colorized 된 binary 2D mask 를 생성해주기 때문에 이를 렌더링된 이미지로 취급하여 논문의 방법론을 적용했을 때의 생성된 3D Mesh 기반으로 비교하게 됩니다.

10. Stylization Fidelity
논문에서는 이렇게 생성된 3D Mesh 를 가지고 user study 를 구상합니다. 57 명의 user 에게 랜덤한 8 개의 Content Mesh 로 생성한 3D Mesh 를 제공하고 이들에게 각각 다음과 같은 질문을 합니다.
3D Mesh 가 얼마나 Content 및 Style 을 반영하고 있나요?
3D Mesh 가 얼마나 Content 를 반영하고 있나요?
3D Mesh 가 얼마나 Style 을 반영하고 있나요?
각각의 질문에 대한 답변으로는 까지의 점수를 매길 수 있고, 3D Mesh 가 text 와 맞지 않는 경우를 제공한 결과 평균적으로 의 평가 수치를 보였다고 합니다.
이렇게 설계한 user study 에서 논문의 방법론이 위의 표와 같이 모든 질문에서 우세한 결과를 보여주었습니다. 더불어 아래의 그림처럼 생성된 3D Mesh 자체도 논문의 것이 조금 더 좋아보였습니다.

11. Stylization Fidelity - 2
논문에서는 이러한 결과를 VQGAN-CLIP 에서 생성한 colorized binary 2D mask 가 3D Mesh 를 생성하기 위해 좋은 정보를 제공해주지는 않기 때문으로 보았습니다. 논문에서는 이에 특화되어 렌더링된 이미지를 찾도록 anchor view 를 설정하는 등의 작업을 거쳤기 때문으로 보입니다.
Beyond Textual Stylization
Text-based stylization 이외에도 논문의 방법론은 다른 target modalities 들로도 stylization 이 충분히 가능합니다. 단순히 을 계산할 때 사용되는 을 CLIP Text Embedding 을 사용하는 것이 아니라, image modality 라면 image-based embedding 을, 3D Mesh modality 라면 해당 Mesh 의 2D rendering 들의 image-based embedding 들의 average embedding 을 사용하면 됩니다. 또한 다른 modality 들을 적절히 섞고 싶다면 이들을 단순히 을 계산 때 합해주면 됩니다.

12. Image based 3D Mesh Stylization
위 그림은 image modality 를 사용한 image-based stylization 이며,
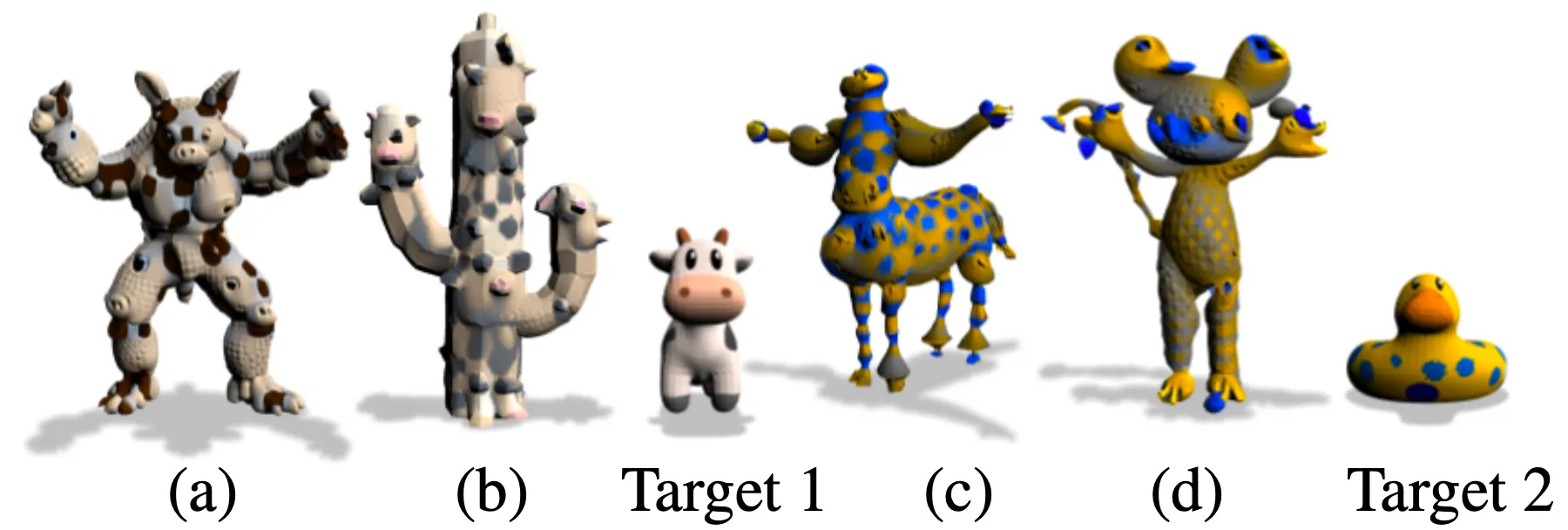
13. 3D Mesh based 3D Mesh Stylization
위 그림은 3D Mesh modality 를 사용한 3D Mesh-based stylization 입니다. 와 의 경우에는 각각 a cactus that looks like a cow 와 a mouse that looks like a duck 이라는 text modality 와 target 3D Mesh modality 를 합한 형태로 을 정의한 뒤 생성한 3D Mesh 라고 합니다.
Incorporating Symmetries
논문에서는 특별하게 Content 3D Mesh 에 대한 prior knowledge 를 어느정도 학습에 반영할 수 있는 방법을 제시합니다. 3D Mesh 에 자체적으로 Symmetric 한 구조를 가지고 있는 경우에 대해서 생성될 3D Mesh 에서도 해당 constraint 를 유지하게끔 설정하여 조금 더 나은 결과물을 산출할 수 있는 방법입니다.

14. Incorporating Symmetries
이는 positional encoding 과정에서 제어할 수 있습니다. 만약 plane 상에서 symmetric 한 구조를 가지고 있는 3D Mesh 가 있다면 값의 양/음 에 따른 positional encoded vector 의 값에 차이를 두지 않으면 됩니다. 이 때 대신에 를 사용하여 해당 방향으로의 크기가 같다면 최종적인 positional encoded vector 의 값이 같도록 제어해준다면 최종적인 결과물도 해당 constraint 를 유지한 채로 등장할 수 있는 개념입니다.
위 그림의 UFO 는 colorful UFO 라는 Text Prompt 로 생성된 3D Mesh 인데 우측의 Symmetry Prior 는 대신에 를, 대신에 를 사용해주면 생성되는 그림처럼 보입니다. 확실히 prior 가 있는 경우가 조금 더 UFO 는 대칭적이다라는 일반적인 통념이 적용된 듯한 결과물이라서 그럴듯해 보이는 것 같습니다.
Limitations
논문의 방법론은 기본적으로 3D Conent Mesh 와 target Text Prompt 사이의 어느정도의 연관성이 있다는 것을 가정한다고 합니다. 이는 상대적으로 서로 무관한 3D Mesh 와 Text Prompt (ex. 드래곤 모양의 3D Mesh 와 stained glass 라는 Text Prompt) 를 이용해 3D Mesh Stylization 을 진행했을 때 결과가 Content 3D Mesh 를 어느정도 무시하는 형태로 나온 것으로부터 확인할 수 있었다고 합니다. 이를 어느정도 보완하기 위해 논문에서는 Text Prompt 에 stained glass dragon 과 같은 형태로 object category 를 추가했고, 이는 실제로 어느정도 content preservation 에 도움을 주었다고 합니다.
Conclusion
이것으로 논문 “Text2Mesh: Text-Driven Neural Stylization for Meshes” 의 내용을 간단하게 요약해보았습니다.
이전에 리뷰했던 논문 이전에 처음으로 Text2Mesh 를 제시한 논문이라서 그런지 조금 더 디테일한 내용들이 많이 포함되어 있었던 것 같습니다. 더불어 논문에서 제시한 방법론을 구성하는 각각의 요소들의 유의미함을 보이기 위한 실험들을 굉장히 많이 진행했다는 점이 인상깊었습니다.
해당 논문이 3D Mesh Stylization 분야를 GAN 에서 벗어나게끔 해준 논문이었다는 점에서 굉장히 의미있는 논문이 아니었나 싶습니다.