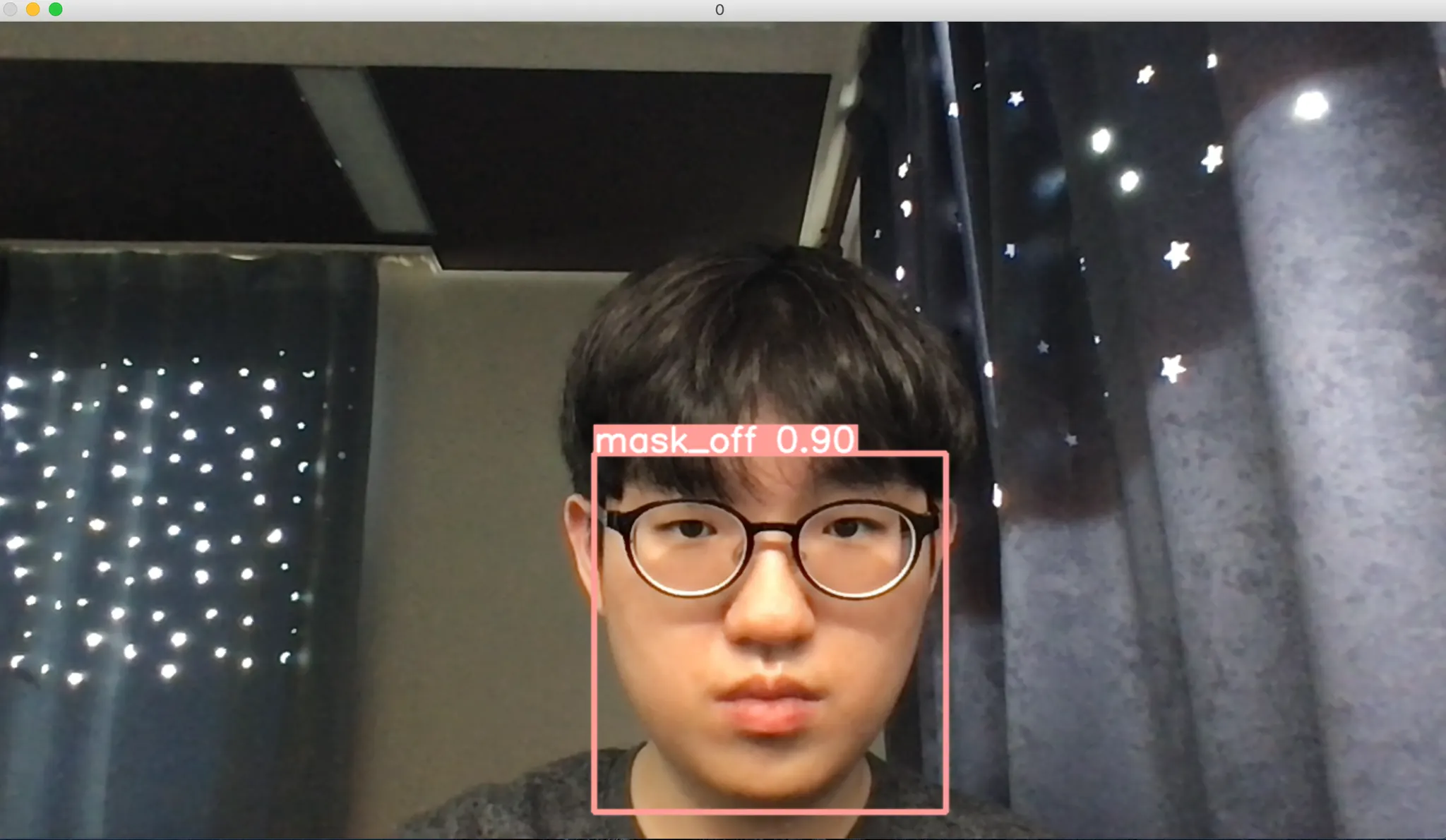
실시간 마스크 착용여부 탐지를 사용 중인 작성자의 부끄러운 얼굴
휴먼스케이프 개발직군은 입사 후 일정 기간동안 개개인의 개발 능력을 뽐낼 수 있는 온보딩 프로젝트를 진행합니다. 그 동안 여러 개발자들이 입사하시면서 다양한 온보딩 프로젝트가 선보여졌었는데요! 서비스에 직접 적용할 가능성이 있는 복약 알림 앱, 사내 자산관리 시스템, 회의실 예약 시스템 등 쓸모있으면서도 재미있는 프로젝트들이 많이 개발되었습니다. 
하지만, 이런 멋진 결과물 뒤에는 개발자들의 피, 땀 , 눈물 이 포함되어 있습니다. 그 첫 시작은 단연 주제 선정이라 할 수 있는데요! 휴먼스케이프의 구성원들은 개발직군 신규 입사자가 생기면 하나같이 힘을 합쳐 아이디어를 모아줍니다.
, 땀 , 눈물 이 포함되어 있습니다. 그 첫 시작은 단연 주제 선정이라 할 수 있는데요! 휴먼스케이프의 구성원들은 개발직군 신규 입사자가 생기면 하나같이 힘을 합쳐 아이디어를 모아줍니다.
June 의 온보딩 프로젝트 주제 선정
제가 온보딩 프로젝트의 주제를 브레인스토밍할 때 항상 나왔던 주제 중 하나가 실시간 마스크 착용여부 탐지였습니다. 헬스케어 스타트업답게 코로나 시대에 발맞추어 방문객 및 근무자들의 마스크 착용여부를 탐지하여 알림, 혹은 경고를 보낼 수 있다면 사내에 유용하게 사용될 수 있으면서도 컴퓨터 비전에 관심이 많은 제가 흥미를 가지고 프로젝트를 진행해볼 수 있겠다- 싶어서였습니다.
이 아이디어를 처음 떠올렸을 당시에는 막연한 생각만 가지고 있었습니다. Dataset 구축, Object Detection 구현, 실시간 카메라 구동 등 넘어야 할 산이 너무 많아보였습니다. 하지만, 시간이 지나 컴퓨터 비전 영역에서 생각보다 많은 지식이 쌓였고, YOLOv5 + TL 로 메이플스토리 캐릭터 찾기를 진행했던 경험을 통대로 생각보다 간단하게 해볼 수 있겠다- 는 생각이 들었고 이전에 진행했던 메이플스토리 캐릭터 찾기와는 다르게, 실시간 탐지 기능을 추가하여 구현해보려는 시도를 하게 되었습니다. (마치 제가 작은 규모의 온보딩 프로젝트를 하는 것 같네요 )
)서론이 길었는데, 본 포스트에서는 제가 YOLOv5 + TL + OpenCV 의 VideoCapture 를 사용하여 마스크 착용 여부를 실시간으로 탐지하는 기능을 구현한 방법에 대해서 소개드리려고 합니다. YOLOv5 + TL 의 사용은 이전 포스트에 나와 있지만, 이번 포스트에서도 간략하게 언급드릴 예정입니다.
데이터셋 준비 + 라벨링 형태 변경하기
YOLOv5 + TL 을 사용해 커스텀한 Object Detection 을 하기 위해서는 데이터셋을 준비해야 합니다. 다행히도, Kaggle 에 아래와 같이 Face Mask Detection 이라는 이름으로 라벨링까지 완료된 데이터셋을 제공해 주었고, 저는 이 데이터셋을 가공하여 사용하였습니다.

Kaggle 에서 제공하는 데이터셋은 853 개의 이미지와 3 개의 class 로 라벨링된 xml 파일로 구성되어 있습니다. 3 개의 class 는 다음과 같습니다.
1.
마스크를 착용한 얼굴 (with_mask)
2.
마스크를 착용하지 않은 얼굴 (without_mask)
3.
마스크를 잘못 착용한 얼굴 (mask_weared_incorrect)
해당 3 개의 class 정보를 비롯하여 bounding box 의 위치 정보를 라벨링하는 파일은 다음과 같은 형태를 가지고 있었습니다.
<annotation>
<folder>images</folder>
<filename>maksssksksss0.png</filename>
<size>
<width>512</width>
<height>366</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>without_mask</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>79</xmin>
<ymin>105</ymin>
<xmax>109</xmax>
<ymax>142</ymax>
</bndbox>
</object>
<object>
<name>with_mask</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>185</xmin>
<ymin>100</ymin>
<xmax>226</xmax>
<ymax>144</ymax>
</bndbox>
</object>
<object>
<name>without_mask</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<occluded>0</occluded>
<difficult>0</difficult>
<bndbox>
<xmin>325</xmin>
<ymin>90</ymin>
<xmax>360</xmax>
<ymax>141</ymax>
</bndbox>
</object>
</annotation>
XML
복사
해당 xml 은 Kaggle 데이터셋의 첫 번째 데이터에 대한 라벨입니다. 저희는 YOLOv5 를 사용하려고 하기 때문에 해당 xml 파일을 사용해 YOLOv5 가 원하는 형태의 라벨로 변환하는 과정을 진행해야 했습니다. YOLOv5 는 다음과 같은 형태의 라벨을 정의해주어야 합니다.
# label_1.txt
[CLASS_INDEX_1] [X_MEAN_1] [Y_MEAN_1] [X_LENGTH_1] [Y_LENGTH_1]
[CLASS_INDEX_2] [X_MEAN_2] [Y_MEAN_2] [X_LENGTH_2] [Y_LENGTH_2]
...
Shell
복사
위처럼 YOLOv5 는 하나의 row 에 하나의 object 에 대한 bounding box 의 class index, 중앙 x 좌표, 중앙 y 좌표, x 좌표 길이, y 좌표 길이를 전체 이미지 사이즈에 대한 비율로 적어 넣은 형태의 txt 파일을 라벨로 사용합니다.
# utils.py
import glob
import xml.etree.ElementTree as ET
CLASS_TO_INDEX = dict(with_mask=0, without_mask=1, mask_weared_incorrect=2)
def xml_to_txt(input_directory, output_directory):
for xml_file in glob.glob(input_directory + "/*.xml"):
tree = ET.parse(xml_file)
root = tree.getroot()
file_name = root.find("filename").text
txt_file = open(output_directory + file_name.split(".")[0] + ".txt", "w")
for member in root.findall("object"):
width, height = int(root.find("size")[0].text), int(root.find("size")[1].text)
dw = 1.0 / width
dh = 1.0 / height
object_class = CLASS_TO_INDEX[member[0].text]
x_mean = (float(member[5][0].text) + float(member[5][2].text)) / 2.0 * dw
y_mean = (float(member[5][1].text) + float(member[5][3].text)) / 2.0 * dh
x_length = abs(float(member[5][0].text) - float(member[5][2].text)) * dw
y_length = abs(float(member[5][1].text) - float(member[5][3].text)) * dh
txt_file.write(f"{object_class} {x_mean} {y_mean} {x_length} {y_length}\n")
txt_file.close()
Python
복사
저는 디렉토리의 utils.py 에 위와 같은 코드를 작성하여 기존에 Kaggle 데이터셋이 xml 로 제공해주었던 라벨을 txt 파일로 변경하여 저장할 수 있었습니다. 간략한 설명을 덧붙이자면, input_directory 에 있는 *.xml 형태의 파일들에 각각 접근하여 ET 로 이미지 내 object 들의 정보를 parsing 했고, parsing 한 정보를 바탕으로 필요한 class index, 중앙 x 좌표, 중앙 y 좌표, x 좌표 길이, y 좌표 길이를 구하여 파일에 써내려간 것입니다.
위 코드를 실행시켜 생성한 첫 번째 데이터의 txt 파일 형태의 라벨은 다음과 같습니다.
1 0.18359375 0.337431693989071 0.05859375 0.10109289617486339
0 0.4013671875 0.3333333333333333 0.080078125 0.12021857923497267
1 0.6689453125 0.3155737704918033 0.068359375 0.13934426229508196
Plain Text
복사
이제 YOLOv5 + TL 을 활용해 완성한 데이터셋으로 학습을 진행하는 방법에 대해서 소개드리려고 합니다.
YOLOv5 를 활용해 Transfer Learning 하기
YOLOv5 + TL 을 활용하기 위해 먼저 YOLOv5 를 fork 하는 과정이 필요합니다. 저 같은 경우는, 레포지토리를 생성한 뒤에, fork 한 YOLOv5 로부터 필요한 파일들을 가져오는 형태로 진행했습니다.
YOLOv5 를 fork 받았다면, 먼저 폴더 하나를 루트 경로에 추가로 만든 후 하위에 images 와 labels 라는 폴더를 만들어야 합니다. 저는 train_data 라는 폴더를 생성했고, 그 폴더의 하위에 images 폴더를 두고 그 안에 Kaggle 에서 다운로드 받은 이미지 파일들을 넣어두었습니다. 그리고 train_data 폴더의 하위에 마찬가지로 labels 폴더를 두고 그 안에 txt 로 형태를 변환했던 라벨링 파일들을 담아두었습니다.
이 때, 저는 이전에 메이플스토리 캐릭터 찾기를 진행할 때와 다르게 풍부한 데이터셋을 가지고 있었기에, 853 개의 이미지 중 100 개의 이미지를 validation 에 활용하기 위해서 빼두었습니다. 이 빼놓은 이미지와 라벨링 파일들은 또 validation_data 라는 폴더를 생성하여 그 하위의 images, labels 폴더에 담아두었습니다.
이후에, 학습할 요소에 대한 정보를 담은 yaml file 을 하나 추가해주어야 합니다. 저는 루트 경로에 train.yaml 파일을 생성했고, 아래와 같이 training 데이터셋 및 validation 데이터셋의 경로, 총 class 수, 각 class 의 이름을 적어두었습니다. 이 때, 라벨링 된 class index 에 해당하는 class (ex. class index 0 은 마스크 착용 을 의미) 가 배열에서 해당 class index 위치에 오도록 해야 합니다. 이 이름은 나중에 detection 단계에서 bounding box 를 그려줄 때에 사용이 됩니다.
# train.yaml
train: ./train_data/images # 753 images
val: ./validation_data/images # 100 images
# number of classes
nc: 3
# class names
names: [ 'mask_on', 'mask_off', 'mask_wrong' ]
Plain Text
복사
이후 저는 다음 명령어를 통해 pretrained model 인 yolov5s 를 제 데이터셋을 사용하여 추가로 학습했습니다. 처음에는 yolov5x 모델을 사용해서 학습했었는데, 큰 모델을 사용할 경우 연산량이 많아져 실시간 탐지에 활용하기 불편할 정도로 inference time 이 길어져서 가장 작은 모델을 사용했습니다.
img flag 는 image resizing 의 크기이며, batch 랑 epoch 는 자유롭게 조절하셔도 됩니다. 이미지 크기가 크면 학습 속도가 느리지만 더 정확도가 높습니다. 메이플스토리 캐릭터 찾기 때와 다른 점이 있다면 —nosave flag 를 제외하여 epoch 마다 꾸준히 학습 모델을 저장 및 갱신하도록 바꾸었습니다. 이는 간단히 실험해본 결과 생각보다 적은 epoch 으로 원하는 수준의 결과가 나오지 않았고 긴 epoch 의 train 에서 학습 과정이 중단되면 처음부터 다시 진행하는 대참사가 생길 수도 있기 때문이었습니다.
python train.py --img 512 --batch 16 --epochs 200 --data train.yaml --weights yolov5s.pt --cache
Shell
복사
해당 명령어를 통해 학습을 진행해보면서 느낀 것은 데이터셋도 많고 cpu 로 학습을 진행해서인지 학습이 꽤나 느리다는 점이었습니다. 때문에 학습이 잘 되는지 확인하기 위해 tensorboard 를 활용했습니다. 제일 처음에는 training 데이터셋 100 개, validation 데이터셋 100 개로 학습을 진행하여 빠르게 결과를 얻으려고 했는데, 200 epoch 을 돌고 나서 확인해본 결과가 그리 좋지 않았었습니다.
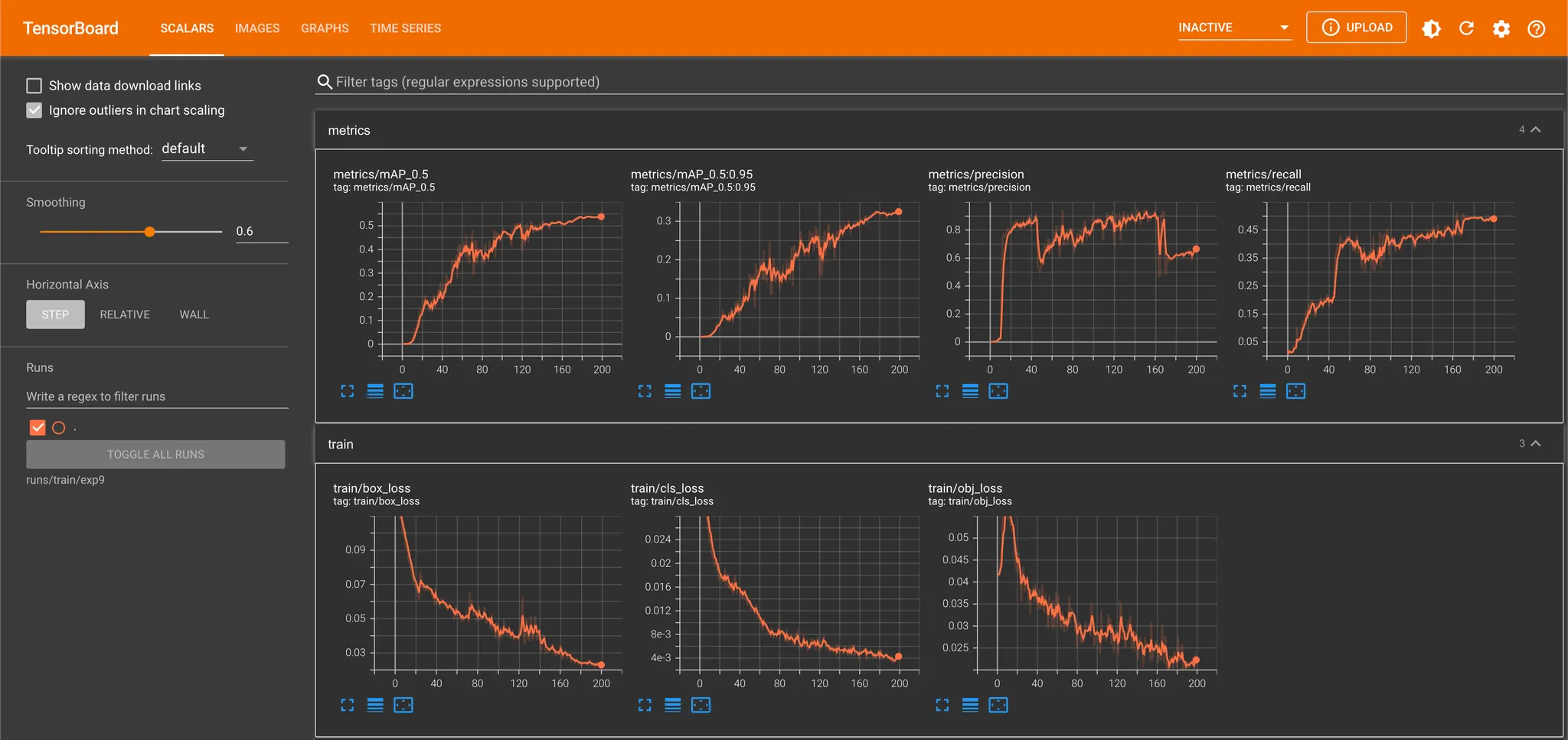
100 Training Dataset + 100 Validation Dataset
평가 지표인 loss 와 mAP 는 각각 꾸준히 내려가는 양상, 올라가는 양상이었지만, 최종적인 recall 및 precision 이 높지 않았습니다. 초기에 precision 이 높다가 떨어지는 이유는 major 한 object 가 mask-on 인 데이터셋에 기반한 것으로 판단했습니다. 대부분의 상황 mask-on 으로 판단을 내려버리는 것이 mAP 상으로 유리했고, 이러한 방향으로의 학습이 빠르게 precision 을 올렸다고 보고 있습니다. 어느 순간부터 mask-off 및 mask-wrong 의 판단이 늘어가면서 precision 이 낮아지면서 recall 을 올리는 것이 mAP 상으로 이득인 시점이 찾아왔다고 보았습니다.
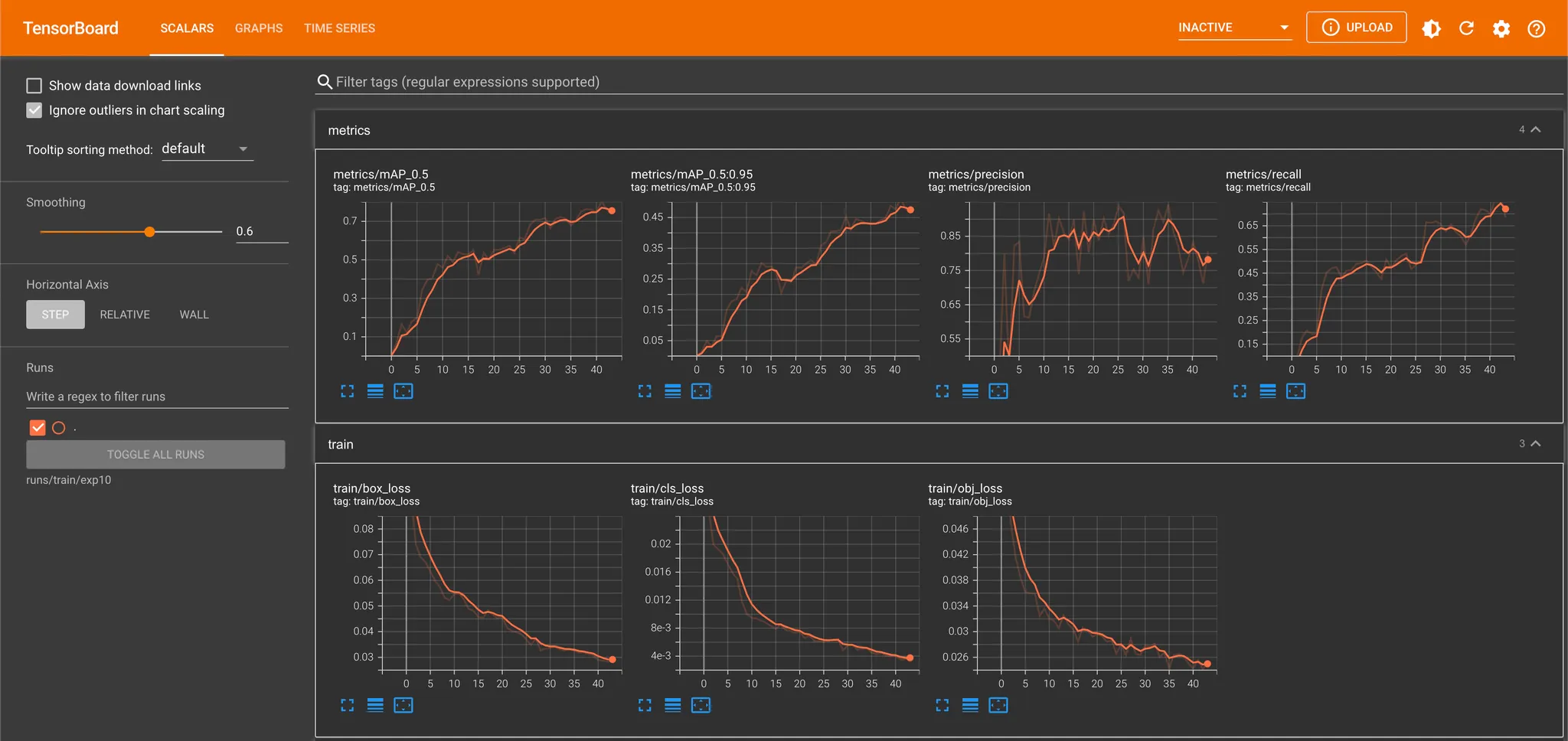
753 Training Dataset + 100 Validation Dataset
Loss 가 제대로 감소하고 mAP 가 제대로 증가한다는 것을 통해 전체적인 학습의 세팅에는 문제가 없다고 보았습니다. 더불어 Training set 에서조차 Precision 및 Recall 모두 어중간하게 나타나는 것은 모델이 데이터로부터 특성을 이해하기 어려워하고 있다- 고 보았습니다. 때문에 데이터의 수를 늘려보았고, 어느정도 Precision 과 Recall 을 챙길 수 있었습니다.
OpenCV VideoCapture 로 실시간 탐지하기
학습한 모델을 사용해 실시간으로 탐지하기 위해서는 모델에 연속적인 이미지를 넣고 뽑아내야 합니다. 이는 프로그램을 실행하는 환경의 내장 카메라를 사용하는 OpenCV 의 VideoCapture 를 사용해 진행할 수 있었습니다. 그 방법 또한 매우 간단합니다.
import cv2
import torch
video_capture = cv2.VideoCapture(0)
model = torch.hub.load("ultralytics/yolov5", "custom", path="runs/train/exp1/weights/last.pt")
while True:
_, frame = video_capture.read()
result = model(frame)
result.display(render=True)
cv2.imshow("canvas", result.imgs[0])
if cv2.waitKey(30) == 27: # ESC
break
Shell
복사
위처럼 cv2 의 VideoCapture 인스턴스를 정의하고 반복문을 돌면서 해당 인스턴스의 read() 메소드를 통해 한 프레임씩 이미지를 가져와 모델을 통과시킨 후, 해당 결과를 캔버스에 그려주는 방식으로 실시간 탐지 결과를 보여줄 수 있습니다. 다만, 이렇게 할 경우 모델의 inference time 만큼의 delay 가 생겨 약간씩 끊겨서 보이는 현상이 존재합니다.
때문에, YOLOv5 에서는 자체적으로 OpenCV 의 VideoCapture 를 사용해 멀티쓰레딩을 구현하여 영상이 끊김없이 보여줄 수 있도록 조치를 해두었습니다. YOLOv5 에서 제공하는 실시간 탐지를 시도해보려면 다음 명령어를 실행하면 됩니다.
python detect.py --weights './runs/train/exp1/weights/best.pt' --img 512 --conf 0.5 --source 0
Shell
복사
위의 VideoCapture 를 직접 사용하거나, YOLOv5 의 detect 에서 제공하는 실시간 탐지를 사용하면 아래와 같은 화면이 뜨면서 마스크를 착용여부가 인식이 됩니다.
어디에 내놓아도 부끄러운 작성자의 얼굴에 마스크를 끼웠다 빼보았다-
마무리
이렇게 YOLOv5 + TL, 그리고 OpenCV VideoCapture 를 사용해서 실시간 마스크 착용여부 탐지를 진행해보았습니다. 최근 들어서 컴퓨팅 파워가 많이 필요하지 않은 주제들로만 알차게 구성을 하고 있었고, 이 주제도 어느정도 그럴 것이라 예상했는데 생각과는 다르게 class 가 많아서인지 적은 epoch 만으로는 탐지가 잘 안되었습니다. 그래서 Cpu 로 해당 내용 학습을 돌리는데 애를 좀 많이 먹었는데, 최근에 휴먼스케이프에 AI 용 머신을 들여놓았다는 이야기가 있어서 해보지 못했던 재미있고 풍성한 주제들을 많이 다룰 수 있게 될 것 같아 기대가 됩니다. 결과물도 생각보다 크게 나쁘지는 않아서 다시 한 번 YOLOv5 개발진에게 박수를 보내봅니다-