츄츄 세트가 나왔을 때 길드원들 모여서 찍은 사진...
저는 어려서부터 메이플스토리를 접한 세대였는데, 가끔씩 추억에 젖어 메이플스토리를 켜서 석 달 정도를 열심히하고 다시 안하고를 반복해 왔었습니다.
P.S 유저들이 자주 접고 자주 돌아온다는 의미로 연어게임이라고도 합니다...
얼마전까지만해도 메이플스토리를 열심히 플레이했기에, 저는 제가 재미있게 하고 있는 것을 가지고 프로젝트를 해보면 어떨까? 하는 마음에 가볍게 메이플스토리 코디 시뮬레이터 를 만들었던 적이 있습니다.

비록 완성도는 높지는 않지만, 처음으로 재미있게 개발해본 경험이었고, 이를 같이 게임을 플레이하는 길드에 공유하고 얻은 반응은 꽤나 긍정적이었습니다.
하지만, 저는 여기서 그치지 않고 제가 좋아하는 머신러닝과 메이플스토리 프로젝트를 접목할 요소가 없을까 고민을 하기 시작했습니다. 그러다가 생각난 것이 이미지를 기반으로 캐릭터의 아이템을 추출해주는 기능이었고, 저는 처음에 이 기능을 만드려고 했었습니다.
그런데, 문득 생각난 것이 사용자의 편의성을 극대화 하려면, 사용자가 이미지를 굳이 캐릭터 범위로 잘라서 주지 않아도 알아서 캐릭터를 인식하여 범위를 선택하여 그 속에서 아이템을 추출해주어야 된다는 점이었습니다. 이것을 진행하기 위해서 저는 Object Detection 이 필요할 것이라 보았고, 이 부분에 대한 논문 리뷰 등을 진행했었습니다. 하지만 논문을 읽어도 여전히 데이터셋을 준비하는 것은 어려웠고, 적은 데이터셋으로도 학습을 시키고 싶었기에 관련한 내용들을 살펴보기 시작했습니다. 그렇게, Transfer Learning 에 대해 알게 되었고 또 다시 관련한 논문을 읽고 리뷰했습니다. 물론, 지금부터 설명드릴 내용이 논문의 내용을 이해해야만 할 수 있는 것들은 아니지만 이해하고 하는 것과 아닌 것은 차이가 있다고 생각하여... 시간을 들여 공부를 했던 것 같습니다.
서론이 길었는데, 본 포스트에서는 제가 YOLOv5 와 그가 제공하는 transfer learning 을 사용하여 적은 데이터를 사용해서 이미지/동영상 속에서 메이플스토리 캐릭터를 찾아낸 방법에 대해서 설명드리려고 합니다. 꼭 메이플스토리 캐릭터가 아니더라도 같은 방법으로 여러분들도 원하는 요소를 이미지/동영상으로부터 찾아내실 수 있습니다. 
데이터셋 준비하기
가장 먼저 진행해야 할 것은 데이터셋을 준비하는 과정입니다. 적은 수의 데이터셋만으로 학습한다고 해도 어느정도의 데이터셋은 필요합니다. 저는 이를 준비하기 위해서 처음으로 크롤링이라는 과정을 진행해보았습니다. 물론, 제 방법은 굉장히 유연성이 부족한 방법이라서 "크롤링" 이라고 부르기에 적합하지 않습니다. 어느정도 예상하셨겠지만, 저는 selenium 을 이용해서 구글 검색 이미지를 다운로드 받았습니다.
거창하게 "크롤링" 이라는 이름을 붙였지만, 제가 사용한 방법은 간단합니다. Chromedriver 를 사용하여 크롬 브라우저를 selenium 을 사용해서 제가 원하는대로 컨트롤하고 이미지를 다운로드했습니다.
먼저 사용하시는 chrome 버전에 맞는 chromedriver 를 다운로드 받아야 합니다. 크롬 버전은 크롬 우측 상단의 세 개의 점 부분을 클릭 > 도움말 > Chrome 정보 로 가서 보실 수 있습니다. 저는 다운로드 받은 이후 chromedriver 를 디렉토리의 루트 경로에 놓았습니다.
from selenium import webdriver
driver = webdriver.Chrome('./chromedriver')
driver.get('http://www.google.co.kr/imghp?hl=ko')
Python
복사
위와 같이 적어주시면 chromedriver 를 initialize 하실 수 있습니다. chromedriver 의 경로를 설정하고(저는 프로젝트의 루트입니다), driver.get() method 를 사용해서 구글 이미지 검색에 접근했습니다.
# Search word
keyword = input("검색할 키워드를 입력하세요 : ")
num = int(input("개수 : "))
search_box = driver.find_element_by_name("q")
search_box.send_keys(keyword)
search_box.send_keys(Keys.RETURN)
Python
복사
구글 이미지 검색 창까지 도착하면, 제가 원하는 키워드로 검색을 할 수 있어야 합니다. 저는 키워드와 다운로드 받을 이미지의 개수를 input 으로 받아서 유동적으로 조절할 수 있게끔 크롤링을 작성했습니다. 알고 계실 분들도 있으시겠지만, 위 코드에서 보시는 것과 같이 drvier.find_element_by_name() 은 사이트를 구성하는 element 의 name 속성으로 element 를 찾아주는 method 입니다. 위에서 "q" 로 element 를 찾은 것고 구글 이미지 검색에서 "q" 라는 name 으로 검색창이 존재했기 때문입니다. 참고로 이는 관습적으로 search input 의 name 을 q 로 설정하는 것이라고도 합니다.
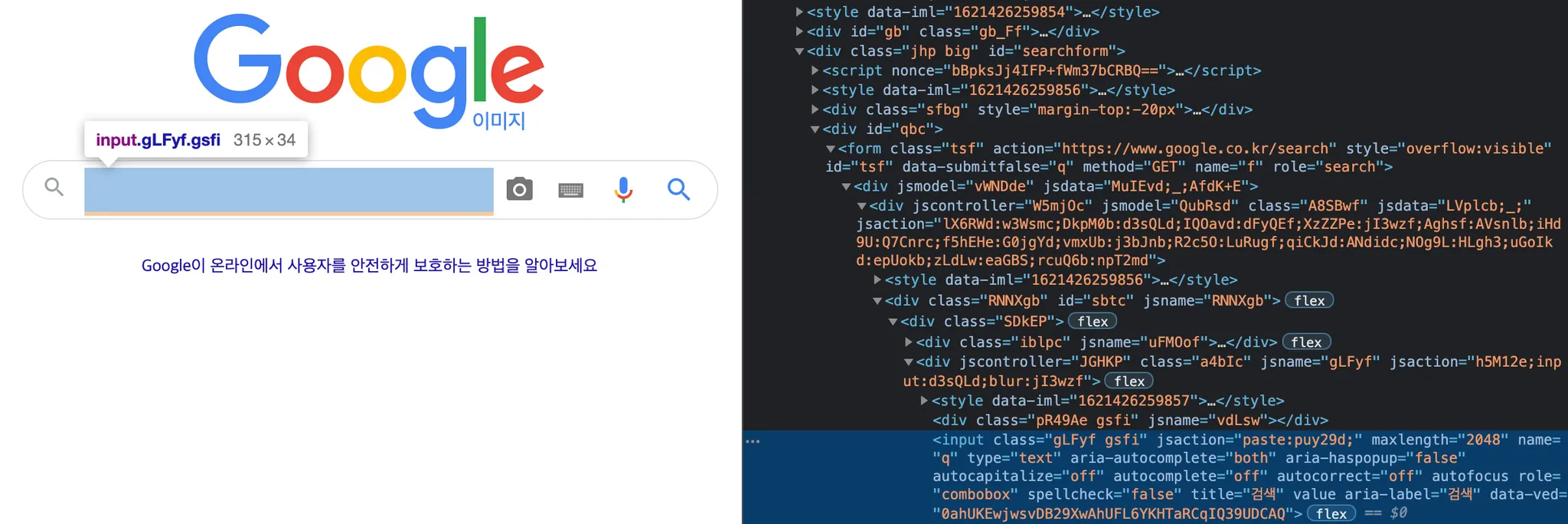
위 코드에서처럼 저는 element 를 찾아준 뒤, element.send_keys() 로 입력을 전달해주었습니다. 키워드로 입력받은 string 과 엔터(Keys.RETURN) 를 입력으로 전달해 줌으로써 설정한 키워드로 검색이 되는 효과를 얻을 수 있었습니다.
# Search setting
# 구글 이미지 검색에서 도구 클릭
detail_setting_box = driver.find_element_by_xpath("/html/body/div[2]/c-wiz/div[1]/div/div[1]/div[2]/div[2]/div/div")
detail_setting_box.click()
time.sleep(1)
# 구글 이미지 검색의 도구 > 시간 클릭
time_setting = driver.find_element_by_xpath("/html/body/div[2]/c-wiz/div[2]/c-wiz[1]/div/div/div[1]/div/div[4]/div/div[1]")
time_setting.click()
time.sleep(1)
# 구글 이미지 검색의 도구 > 시간 > 지난 1일 클릭
time_setting_selection = driver.find_element_by_xpath("/html/body/div[2]/c-wiz/div[2]/c-wiz[1]/div/div/div[3]/div/a[1]/div/span")
time_setting_selection.click()
Python
복사
다음으로, 이미지 검색의 세부 설정을 세팅하기 위해서 기분이 좋지많은 않은 코드를 작성해야 했습니다. Element 를 특정하기 위해서 사용할 수 있는 요소가 생각보다 많이 없었고, 그마저도 간단하지는 않았습니다. 그 중 제일 생각없이 간단하게 쓸 수 있는 것이 XPath(XML Path Language) 였습니다.
XPath 는 XML 문서의 특정 element 에 접근하기 위한 경로를 지정하는 언어인데, selenium 에서 이 언어를 기반으로 element 를 추출하는 method 인 driver.find_element_by_xpath() 를 제공합니다. 더불어, 크롬 개발자 도구 창에서 아래와 같이 항목을 우클릭하여 XPath 를 복사할 수 있기 때문에 XPath 를 사용하면 상당히 간단하게 element 를 지정할 수 있습니다.
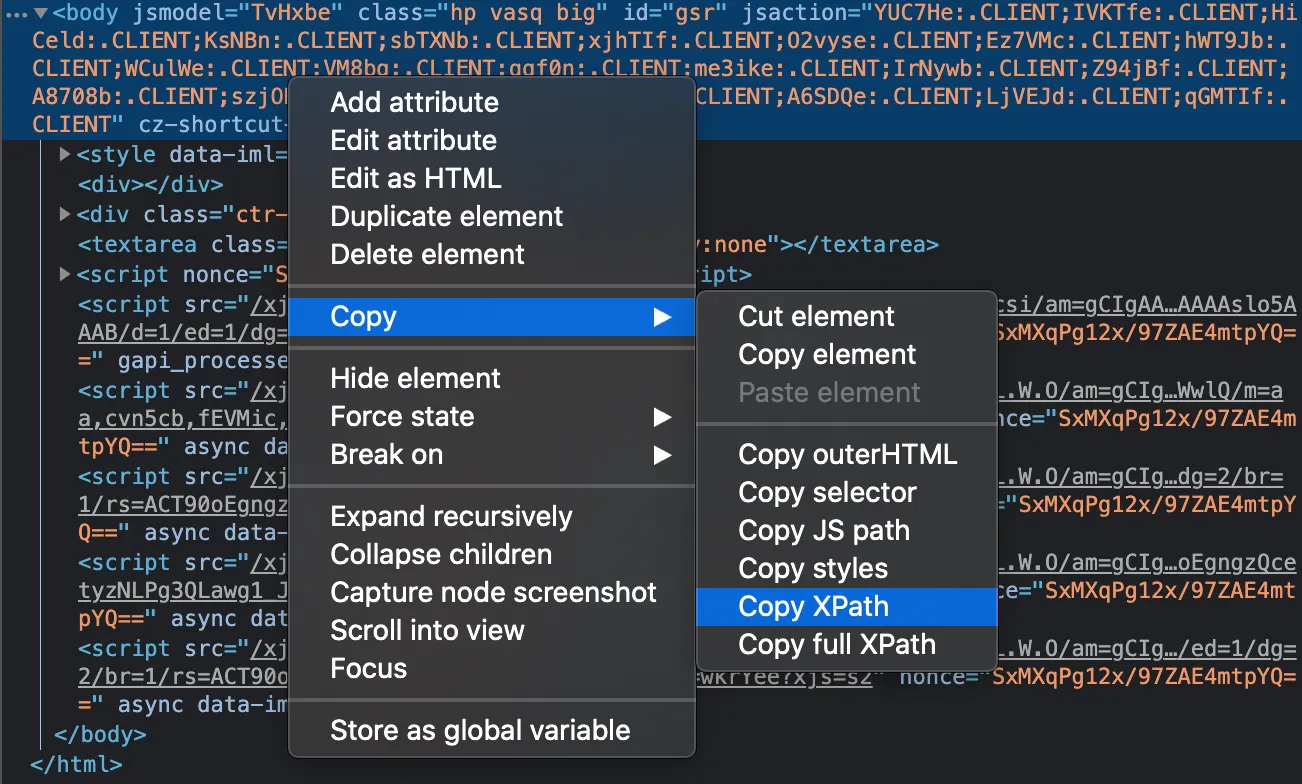
위 코드의 주석에도 적혀 있듯이, 제가 위 코드로 하려고 했던 것은, 구글 이미지 검색의 세부 설정에서 지난 1일 동안 업로드된 사진만을 찾으려고 한 것입니다. 이렇게 몇일 동안 진행을 한 내용을 바탕으로 중복없이 다량의 데이터를 얻어내려고 했습니다.
# Get all images
images = driver.find_elements_by_css_selector(".rg_i.Q4LuWd")
# Download all images
count = 0
for image in images:
try:
image.click()
time.sleep(2)
imgUrl = driver.find_element_by_xpath("/html/body/div[2]/c-wiz/div[3]/div[2]/div[3]/div/div/div[3]/div[2]/c-wiz/div[1]/div/div/div/div[2]/a/img").get_attribute("src")
urllib.request.urlretrieve(imgUrl, "./crawling-images/" + keyword + str(150+ count) + ".jpg")
count += 1
if count == num:
break
except:
pass
driver.close()
Python
복사
검색 세팅까지 마치고 나면, 이미지를 다운로드 받아야 합니다. 저는 image element 리스트를 먼저 만들고, 그 각각의 element 를 클릭해서 나타난 확대 이미지를 다운로드 받아 최대한 화질의 손실 없이 데이터를 얻었습니다. 위 코드 첫 줄이 말씀드린 image element 리스트를 css selector 를 사용해서 뽑아낸 것입니다. 저는 image element 들이 공통적으로 rg_i 와 Q4LuWd class 를 가지는 것을 캐치하고 위와 같이 설계했습니다.
이후, 각각의 이미지를 클릭하고 확대해서 보여진 element 의 XPath 에 마찬가지로 접근하여 src 를 가져오고, 그 url 을 원하는 형태로 다운로드 받는 형태로 진행했습니다. 다양한 이유로 실패할 것을 고려하여 일단은 성공한 친구들만 저장하는 방향으로 진행했기에 except case 는 pass 로 지정해두었습니다.

그렇게 위와 같은 이미지들을 모을 수 있게 되었고, 저는 모은 이미지를 한땀한땀 확인하면서, 화질이 너무 낮아보이는 이미지와 메이플스토리 캐릭터가 하나도 존재하지 않는 이미지는 제거해주었습니다. 이것을 약 4일동안 진행하여 200 개의 이미지를 저장했고 이 중 쓸모 없는 것을 제외하니 73 개의 이미지가 완성되었습니다.
데이터셋 라벨링하기
다음으로 진행해야 할 과정은 데이터셋을 라벨링하는 과정입니다. 당연하게도, Ground-Truth 에 대한 명시를 해주어야 학습데이터로 활용할 수 있습니다. 매우 다행이게도... YOLO 가 생각보다 굉장히 유명한 툴인지라, YOLO 에서 학습데이터로 활용할 수 있도록 라벨링을 지원해주는 툴들이 많이 존재했습니다. 그 중에 저는 labelImg 를 사용해서 라벨링을 진행해보았습니다. 이 툴은 패키지 형식이라 pip 나 poetry 같은 친구로 설치해주면 됩니다.
pip install labelImg 혹은,
poetry add labelImg --dev
Plain Text
복사
이후 다음 명령어로 labelImg GUI 를 켤 수 있습니다.
labelImg
Plain Text
복사
labelImg 의 사용과정은 생각보다 상당히 간단합니다.
1.
GUI 의 좌측의 라벨링 형태를 YOLO 로 선택해 주신 후에, Open Dir 를 클릭하여 라벨링을 원하는 사진의 디렉토리를 선택해줍니다.
2.
Change Save Dir 를 클릭하여 라벨 파일이 저장될 디렉토리를 선택해줍니다.
3.
Create Rectbox 를 클릭하면 영역을 드래그할 수 있는 형태로 커서가 변경되는데, 이 때 라벨링을 원하는 영역을 드래그하고 라벨을 지정해 줍니다.
아래의 그림은 제가 라벨링을 하는 과정을 캡처한 것입니다.
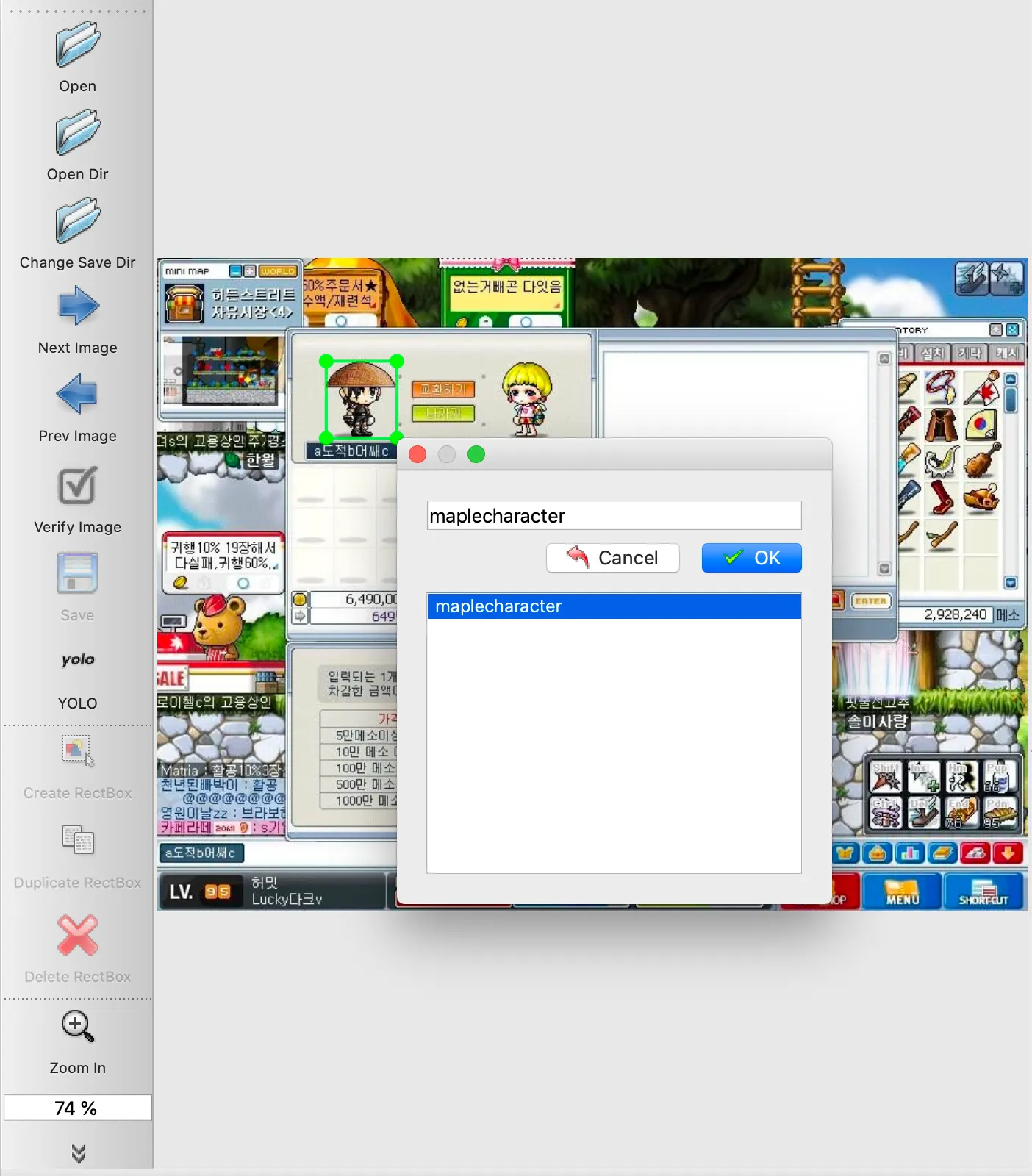
이렇게 라벨링을 한땀한땀 크롤링해서 얻은 모든 이미지에 대해서 진행해주시면 됩니다. 그렇게 되면 원하는 디렉토리에 txt file 로 설정한 bounding box 의 위치에 대한 정보들이 생성되어 있으실 것입니다.
YOLOv5 를 활용해 Transfer Learning 하기
마지막으로, YOLOv5 를 활용해 Transfer Learning 을 진행하는 과정이 남았습니다. 이 과정은 YOLOv5 를 fork 받아서 진행해야 합니다. 저 같은 경우는, 레포지토리를 생성한 뒤에, YOLOv5 로부터 필요한 파일들을 가져오는 형태로 진행했습니다.
YOLOv5 를 fork 받았다면, 먼저 폴더 하나를 루트 경로에 추가로 만든 후 하위에 images 와 labels 라는 폴더를 만들어야 합니다. 저는 train_data 라는 폴더를 생성했고, 그 폴더의 하위에 images 폴더를 두고 그 안에 이전에 크롤링했던 이미지를 담아두었습니다. 그리고 train_data 폴더의 하위에 마찬가지로 labels 폴더를 두고 그 안에 이전에 라벨링했던 txt 파일을 담아두었습니다.
이후에, data 폴더로 이동한 뒤에 추가로 학습할 요소에 대한 정보를 담은 yaml file 을 하나 추가해주어야 합니다. 저는 따로 validation 을 하지 않으려고 해서 train image 와 같은 경로로 지정을 해 주었으며, 메이플스토리 캐릭터 하나만 라벨링 했기 때문에 number of classes 를 1로, class name 은 이전에 라벨링 툴을 사용했을 때 지정한 'maplecharacter' 로 지정해주었습니다.
# maple.yaml
train: ./train_data/images # 73 images
val: ./train_data/images # 73 images
# number of classes
nc: 1
# class names
names: [ 'maplecharacter' ]
Plain Text
복사
이후 저는 다음 명령어를 통해 pretrained model 인 yolov5x 를 제 데이터셋을 사용하여 추가로 학습했습니다.
img flag 는 image resizing 의 크기이며, batch 랑 epoch 는 자유롭게 조절하셔도 됩니다. 이미지 크기가 크면 학습 속도가 느리지만 더 정확도가 높습니다.
python train.py --img 640 --batch 16 --epochs 200 --data ./data/maple.yaml --weights yolov5x.pt --nosave --cache
Plain Text
복사
명령어가 성공적으로 마무리되면, ./runs/train/exp/weights 폴더에 validation 이후 가장 좋은 성능을 보인 model 이 저장됩니다. 이 모델을 이용해 저는 제가 메이플스토리를 플레이한 영상을 분석해보았고, 다음과 같은 명령어를 사용했습니다.
마찬가지로, img flag 는 image resizing 의 크기입니다. 학습에 사용한 resizing 으로 사용해주셔야 하며, conf flag 는 confidence 가 얼마 이상일 때 detect 로 판단할 것인지에 대한 기준선입니다. 저는 데이터셋이 적어서 0.55 정도로 설정해주었습니다.
python detect.py --weights './runs/train/exp/weights/last.pt' --img 640 --conf 0.55 --source '~/maple-video-boss.mp4'
Plain Text
복사
여기까지 설명드리고, 잘 이해가 되지 않으시는 부분은 제가 완성한 코드를 보시고 참고하시면 금방 무슨 소리인지 아실 수 있을 것 같습니다.
메이플스토리 캐릭터 찾아보기
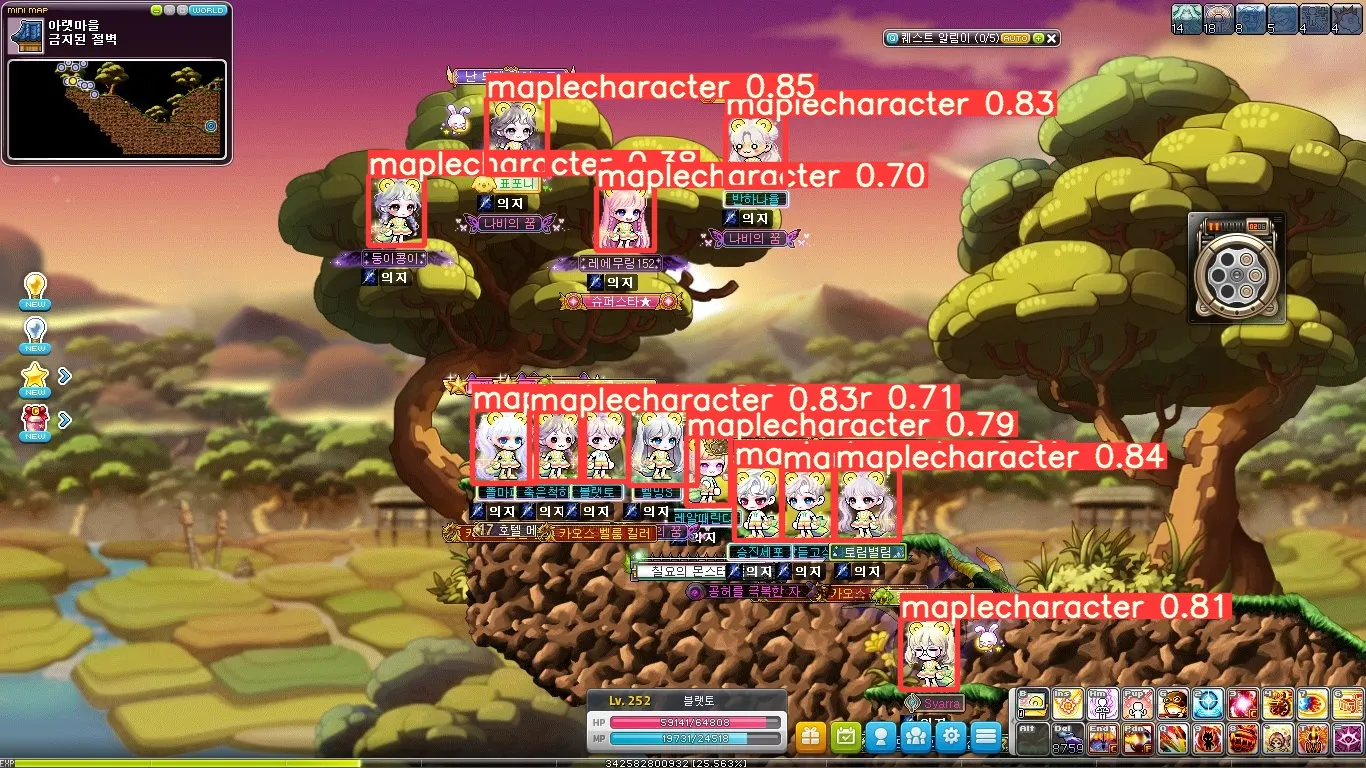
이렇게 detecting 과정까지 무사히 마치면, 이미지나 동영상 속에서 메이플스토리 캐릭터를 찾을 수 있습니다.
다음은, 제가 실제로 간단하게 메이플스토리에서 사냥하면서 찍은 영상에서 제 캐릭터를 찾아본 것입니다.
막상 해보니 들었던 생각은.......
1.
안드로이드(캐릭터 옆에 졸졸 따라다니는 캐릭터 같은 친구)도 있고,
2.
펫(캐릭터를 졸졸 따라다니는 작은 친구)도 가려지고, 몬스터도 많고,
3.
요새 하는 이벤트 때문에 이상한 친구(분홍색 꽃같이 생긴 친구)가 절 따라다니고,
4.
몬스터를 잡을 때마다 소울조각이 캐릭터로 들어와서(검은색 구슬 같은 것들)
생각보다 detecting 이 잘 되었다는 느낌이 안 드는 것 같아서 깔끔한 곳에서 다시 한 번 진행을 해 보았습니다.
확실히 여러가지 친구들(?)을 제거하고 움직임이 단조로운 보스전에서는 꽤나 잘 detecting 이 되는 것을 볼 수 있었던 것 같습니다.
약간 신기했던 점은, 라벨링 할 때 최대한 캐릭터의 아이템까지 다 볼 수 있도록 범위를 꽤나 유동적으로 잡았는데, 이것을 어떻게 캐치해서 캐릭터가 공격모션을 내릴 때 전체적으로 캐릭터의 아이템 범위가 커지는 것 까지 고려되어서 detecting 했다는 점이었습니다. 더불어, 캐릭터가 앉아 있는 모습은 훈련 데이터셋에 많이 없어서인지, 중간에 캐릭터가 용을 타면서 앉아 있는 모션을 취할 떄 생각보다 인식률이 저조한 것을 볼 수 있었습니다. 추가로, 아이템에 가려지거나, 보스의 이펙트에 가려질 떄도 당연하게도 인식률이 떨어지는 듯한 점을 볼 수 있었습니다.
마무리
이렇게 YOLOv5 + TL 을 이용해서 간단하게 메이플스토리 캐릭터를 찾아보는 작업을 진행해보았습니다. 개인적으로는 뭔가 논문리뷰를 해서 얻은 내용을 바탕으로 처음부터 구현을 하자니 데이터셋이 너무 부족했고 이미 있는 YOLOv5 를 가져다 쓰다니 생각보다 너무 간단해서 오히려 실망스러웠던(?) 것 같습니다. 별개로 느꼈던 것은 데이터셋을 직접 만드는 과정을 처음 해봤는데 생각보다 재미있지는 않았다는 점...? 이었던 것 같습니다. 저는 73 개를 만들었는데 이런걸 만 개 넘게 만들고 있을 실무진분들을 생각하니 존경스럽기도 했습니다.
간단하고 빠르게 Object Detection 을 해보고 싶다! 하시는 분들에게는 강력하게 추천드리고 싶습니다.
그러면 모두 행복한 메이플스토리 하세요..! (전... 요새는 안합니다 ㅜ)
