본 포스트에서는 Transfer Learning(전이학습) 에 대해 실험적으로 분석한 논문에 대해서 살펴보려고 합니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“How transferable are features in deep neural networks?”

Objective
논문의 배경은 Modern Deep Neural Network 에서 나타나는 의심스러운 현상에서 시작합니다. Natural images 들을 이용해서 학습을 진행할 때, 학습된 네트워크의 첫 번째 layer 의 feature 가 Gabor filters 나 Color blobs 와 닮아 있는 양상이 공통적으로 나타났던 것입니다.

Gabor Filters
학습 모델의 feature 를 추출해보신 분들은 위와 같은 그림을 자주 보신 적이 있으실 것입니다. 첫 번째 layer 의 양상이 위와 닮아 있는 경우가 많은 특성은 실제로 학습 후 위와 같은 특성이 나타나지 않으면 software bug 나 hyperparameter 선택의 실수를 의심할 정도로 일반적으로 나타난다고 강하게 인식된 이미지 기반 학습 모델의 특성입니다. 더불어 이러한 현상은 dataset 이나 training object (ex. image classification, object detection, generative model) 에 국한된 현상이 아니라는 점에서 그 일반성을 찾아볼 수 있습니다.
앞에서 제가 일반성에 대해서 언급을 드렸습니다.
논문에서는 이러한 첫 번째 layer 의 특성을 일반성, Generality 라고 명명합니다.
또한 한편으로는, 마지막 layer 의 feature 가 선택한 dataset 이나 trainging object 에 많이 의존합니다. 이는 상당히 간단한 예시에서도 살펴볼 수 있는데, supervised classification 문제의 경우 그 마지막 layer 가 N-dimensional softmax 의 형태임은 물론, 각각의 데이터가 준비한 라벨 하나하나를 의미한다는 것을 알 수 있습니다. 특히, 마지막 layer 를 거쳐서 최종적인 output 이 나오기 때문에 마지막 layer 는 dataset 이나 training object 에 의존적인 feature 를 가지는 특징성을 보유하고 있습니다.
앞에서 제가 특징성에 대해서 언급을 드렸습니다.
이렇게 특정 dataset 이나 trainging object 등에 의존적인 특성을 특징성, Specificity 라고 명명합니다.
위에서 이미지 기반의 네트워크에서 보이는 Generality 와 Specificity 에 대해서 살펴보았습니다. 논문에서는 여기까지 생각을 이어가다가 다음과 같은 의문을 품습니다.

첫 번째 layer 에서 Generality 가 보이고, 마지막 layer 에서 Specificity 가 보인다면, 네트워크 내에서 general to specific 으로의 transition 이 나타나야 하지 않을까?
이 과정에서 부가적으로 다음과 같은 세 가지의 의문점이 생겼습니다.
1.
어떤 layer 가 specific 하고 general 한지를 구분할 수 있는 척도를 정량화할 수 있을까?
2.
Transition 이 하나의 layer 에서 갑자기 발생할까, 여러 layer 에 퍼져서 나타날까?
3.
Transition 이 네트워크의 초반, 중반, 후반 등 구체적으로 어느 지점에서 나타날까?
특히, 논문에서는 위와 같은 의문점은 Transfer Learning 의 성능 증가에 대한 구체적인 방향성을 제시해줄 수 있다고 생각하여 위 세 가지의 의문에 대한 정량적인 실험을 통해 결과를 도출하는 것을 목적으로 논문을 시작합니다.
Transfer Performance
앞서, Transfer Learning 의 성능 증가에 대한 이야기를 했습니다.
Transfer Learning (전이학습) 이란?
Transfer Learning 은 base dataset, base task 로 base network 를 train 하고, 이 train 으로 학습된 feature 를 repurpose 하는 과정(이를 transfer 라고 부릅니다.)을 거쳐서 두 번째 target network 의 initial feature 를 설정한 이후 target dataset 과 target task 에서 train 하는 기법입니다. 이 기법은 feature 를 general feature 와 specific feature 로 나눌 수 있다고 보고, base 와 target tasks 모두에 적용 가능할만한 general feature 를 미리 학습된 base network 로부터 가져와 train parameter 수가 적고 general feature 를 학습할 필요가 없기 때문에 빠른 학습과 적은 데이터 수로 학습이 가능하다는 장점이 있습니다.
논문에서는 이러한 Transfer Learning 에서의 performance 비교를 위해 다음과 같이 실험을 설계합니다.
•
ImageNet dataset 의 non-overlapping dataset 으로 학습할 classification task A 와 task B 를 정의합니다.
•
1000 개의 ImageNet dataset classes 중 500 classes 씩 나누어 각 645,000 개의 이미지를 task A 와 task B 를 위한 학습 데이터로 assign 합니다.
•
Task A 와 task B 의 dataset 은 서로 similar 할 수도 있고 different 할 수도 있습니다. Similar 한 경우는 의도적으로 assign 할 classes 를 random 하게 결정하고, different 한 경우는 특정한 조건으로 classes 를 분배합니다.
Similar classes 의 예시로 비슷한 biological family 에 놓인 felidae 를 들 수 있습니다.
위 집합 속 하나하나가 class 이며, 위 친구들은 서로 similar 하다고 보는 것입니다. 그리고 각 task 에 assign 할 class 를 random 하게 assign 해줌으로서, 위 class 가 거의 반반에 가깝게 task A 와 task B 에 나누어 들어갈 것을 기대한 것입니다.
반대로, different classes 의 예시로 man-made classes 와 natural classes 를 들 수 있습니다. Man-made classes 는 인공적으로 만들어진 물체 classes 이고, natural classes 는 자연적으로 만들어진 물체에 대한 classes 입니다. 이러한 구분은 ImageNet 의 hierarchy of parent classes 를 기반으로 정의됩니다.
•
Task A 와 task B 의 네트워크는 8-layer CNN 으로 설정합니다.
•
첫 layer 부터 몇 번째 layer 까지를 transferred 된 featured layer 로 사용할지에 대해서 결정하기 위한 변수 n 을 정의하고, 를 만족합니다. 그리고 모든 n 에 대해서 실험을 진행합니다.
•
다양한 상황의 task 를 다음과 같이 정의합니다.
◦
AnA 는 pretrained 된 task A network 를 n layer 를 transfer 하여 task A 를 train 한 task 입니다. 이 때 transferred layer 는 frozen 상태로, 학습하지 않습니다. Base task 와 target task 가 같아서 selffer network 입니다.
◦
AnA+ 는 pretrained 된 task A network 를 n layer 를 transfer 하여 task A 를 train 한 task 이되, transferred layer 가 non-frozen 상태로, 학습하는 요소입니다. Base task 와 target task 가 같아서 selffer network 입니다.
◦
AnB 는 pretrained 된 task A network 를 n layer 를 transfer 하여 task B 를 train 한 task 입니다. 이 때 transferred layer 는 frozen 상태로, 학습하지 않습니다. Base task 와 target task 가 달라서 transfer network 입니다.
◦
AnB+ 는 pretrained 된 task A network 를 n layer 를 transfer 하여 task B 를 train 한 task 이되, transferred layer 가 non-frozen 상태로, 학습하는 요소입니다. Base task 와 target task 가 달라서 transfer network 입니다.
◦
BnB, BnB+, BnA, BnA+ 는 위의 설명에서 A 와 B 의 위치를 바꾼 task 입니다.
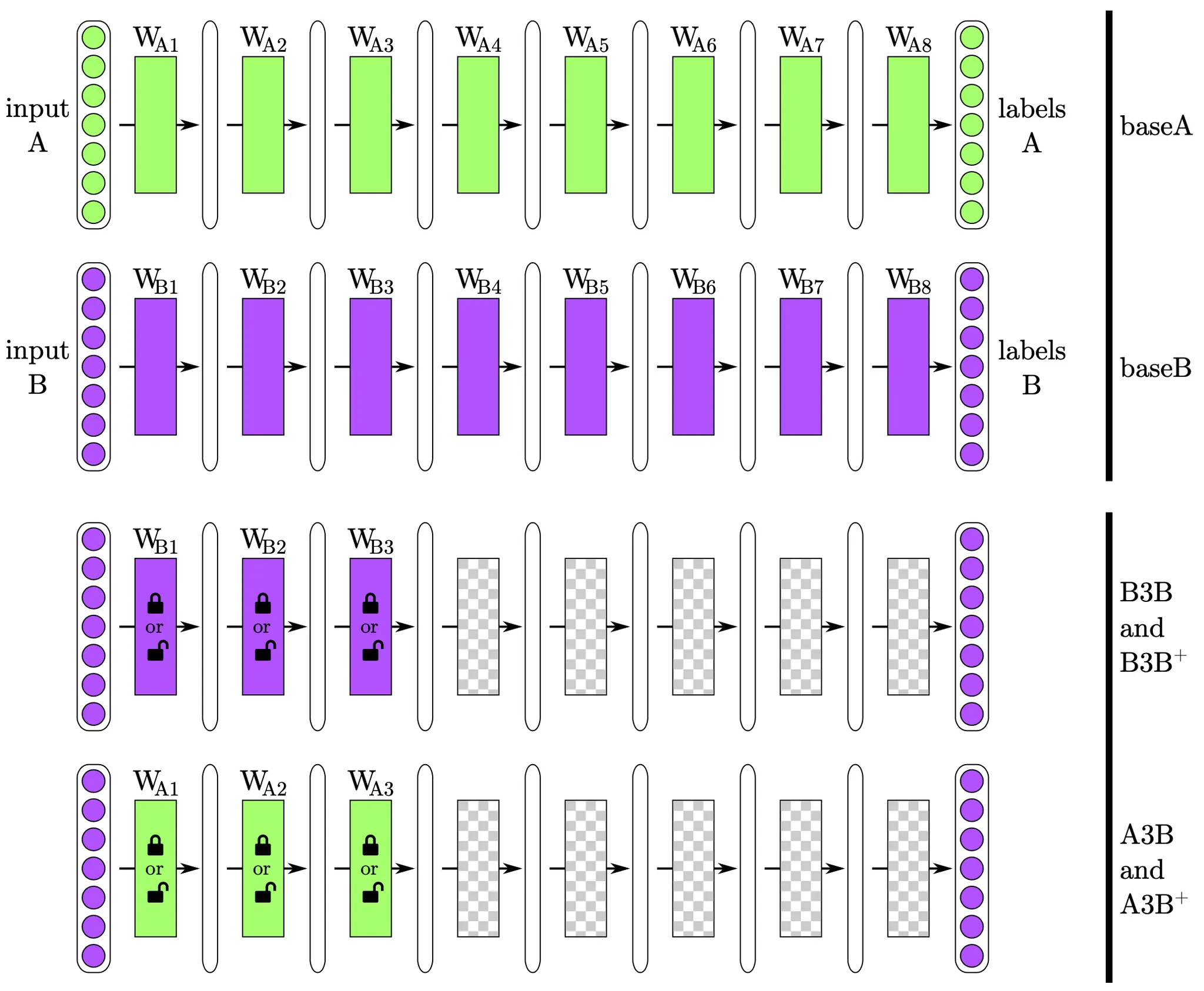
Overview of the experimental treatments and controls
위 그림에서 제일 위 두 네트워크가 baseA 와 base B 이며, 각각 task A 와 task B 를 진행하는 가장 기본적인 네트워크입니다.
다음으로 오는 네트워크가 B3B 혹은 B3B+ 로, B3은 앞 3개의 layer 가 baseB 학습으로부터 구해진 feature 로 initialize 됨을 나타냅니다. 끝의 B 는 네트워크의 task 가 B 임을 뜻합니다. + 의 존재여부는 그림에서의 앞 3개의 trasffered layer 의 잠금 표시 유무를 나타내고, + 가 존재하는 경우 잠금이 풀리는 표시에 대응되어 transferred layer 도 학습에 포함됩니다.
마지막으로 오는 네트워크가 A3B 혹은 A3B+ 로, 바로 위에서 설명한 B3B, B3B+ 에서 한 가지만 달라집니다. B3B, B3B+ 는 transferred layer 를 baseB 에서 가져왔다면, A3B, A3B+ 는 baseA 에서 가져옵니다.
이처럼 Transfer Performance 를 측정하기 위한 실험의 설계에 대해서 알아보았습니다. 다음으로는 실험 setup 과 결과에 대해서 알아보도록 하겠습니다.
Experimental Setup
Krizhevsky et al. 이 ImageNet 2012 competition 에서 우승하고 난 뒤에 large convolutional model 에서 hyperparameter 를 조정해가는 것에 대한 관심이 많았습니다. 하지만, 논문에서는 모델의 절대적인 performance 를 증가시키는 것이 목적이 아니라, transfer performance 에 대해서 알아보고 비교하는 것이 목적이었습니다. 따라서, 많은 연구자들 사이에서 비교할 수 있고, 확장가능성이 넓은 Jia et al 의 구조를 baseline 으로 하여 실험을 진행합니다.
Results and Discussion
사실 이 논문의 중요 내용은 지금부터 시작입니다. 많은 논문들이 보통 그들의 모델 설계, 알고리즘 설계, 방법론, 기법 소개 등 실험 및 검증 단계 이전에 논문에서 이야기 하고 싶은 주요 내용들을 언급하는 것이 많은데, 이 논문의 경우 다른 논문과는 다르게 실험을 통해 증명을 하는 것이 아니라 결과를 도출하는 것이기 때문에 실험의 결과가 논문에서 주요하게 설명하고 싶은 바가 됩니다. 논문에서는 총 세 가지로 나누어 실험을 진행합니다.
Similar Datasets: Random A/B splits
가장 먼저 소개한 것이, similar datasets 로 task A 와 task B 를 진행한 것입니다. 아래에서는 baseB 와 n 이 1~7 까지 일 때의 BnB, BnB+, AnB, AnB+ 에 대해서 여러번 실험한 결과의 Top-1 Accuaracy 와 그 여러번 실험의 average 로 그래프를 그린 도표를 나타내고 있습니다.
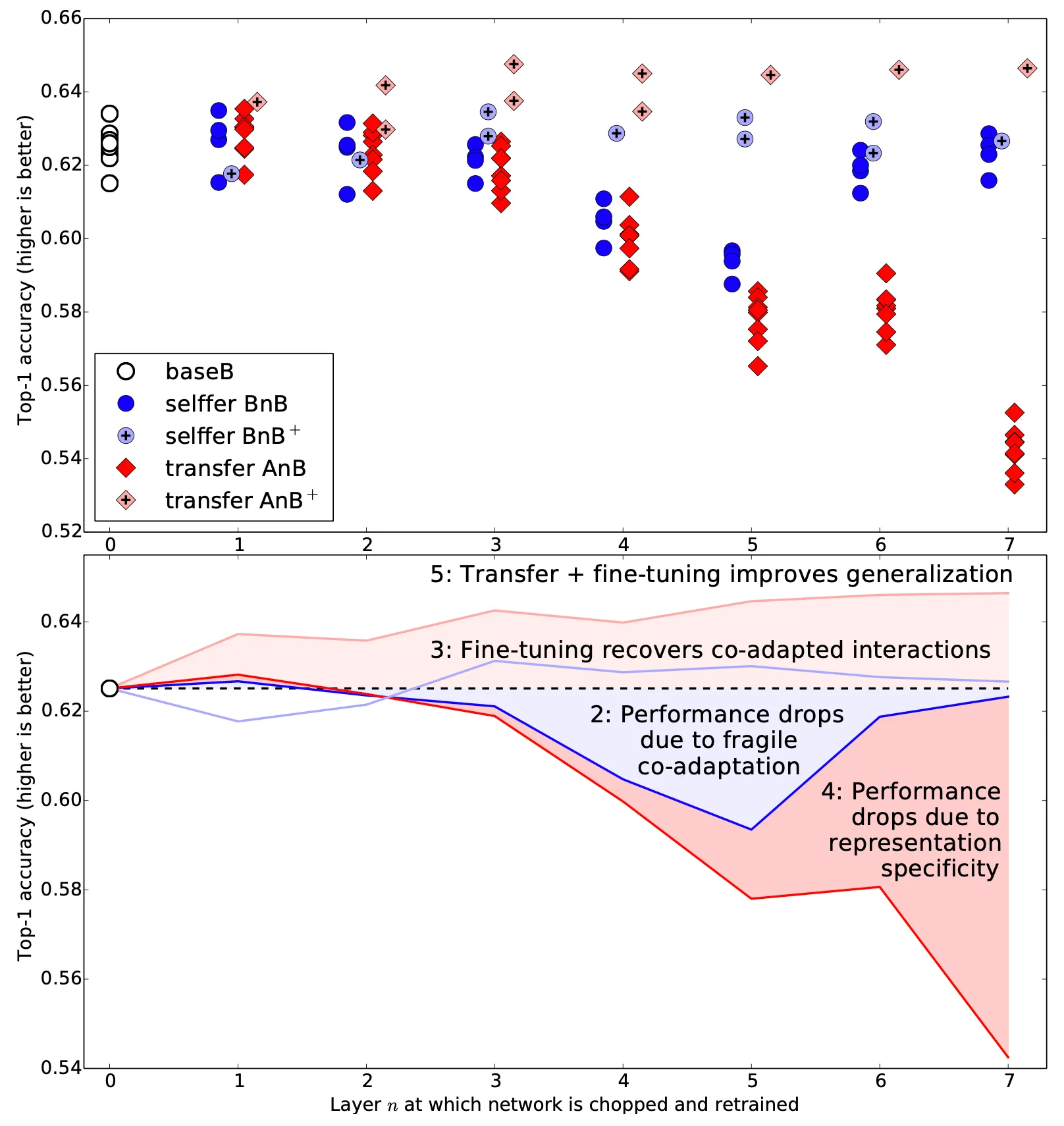
논문에서는 위 실험의 결과로 크게 다섯 가지의 내용을 도출해냅니다.
1.
위 그림의 비어있는 원 라벨인 base B 의 경우 ImageNet 의 random 한 500 classes subset 으로 학습하여 top-1 accuracy 로 0.625 라는 수치를 얻어낼 수 있었습니다. 이는 1000 classes network 로 학습했을 때 나타난 결과 0.575 보다 높은 수치입니다. 단순하게 생각하면, 데이터 수가 적으니까 더 accuracy 가 낮아야 한다고 생각할 수 있는데 그것 이상으로 학습의 output 으로 판단해야 할 label 의 수가 반으로 줄었기 때문에 가능한 일이라고 해석했습니다.
2.
푸른색 원 라벨인 BnB 의 경우 상당히 의심스러운 양상을 보였습니다. 어느 정도 예상했듯이, layer 1 과 layer 2 의 초기 layer 에 대해서는 base B 로 부터 큰 차이를 보이지 않았습니다. 이는 layer 1 과 layer 2 에서 보이는 feature 들이 앞서 설명한 Gabor features 와 color blobs 등을 학습했기 때문입니다. 실제로 이들을 고정하고 다른 feature 를 retrain 하면 원래의 성능이 나오게 됩니다. 하지만, layer 3, 4, 5, 그리고 6 까지 transfer 를 한 결과 성능이 눈에 띄게 감소했습니다. 이러한 성능의 감소는 기존의 성공적이었던 base 네트워크가 깨지기 쉬운 co-adapted features 를 가지고 있었기 때문입니다.
Co-Adaptation(동조화) 이란?
Co-Adaptation 는 각각의 feature 들이 서로 다른 feature detector 로 동작하길 바라는 것과는 달리 두 개 이상의 feature 들이 동일한 feature 를 반복적으로 capture 하는 현상입니다. Co-Adaptation 이 나타나면 네트워크의 capacity 를 최대한 효율적으로 사용하지 못하는 것이며, 이를 해결하기 위해 dropout 을 사용하기도 합니다.
즉, co-adpated 된 feature 들의 복잡한 상호관계를 initialized 된 시점에서부터 학습을 하기 어려웠기 때문에 학습 능력의 저하가 나타난 것으로 보고 있습니다. 하지만 n 이 다시 커져서 6, 7 이 되면 서서히 성능이 다시 오르기 시작하는데 이는 기존의 성공적인 네트워크의 feature 를 거의 다 initialize 한 뒤에 학습할 feature 가 별로 남지 않았기 때문으로 보고 있습니다. 결과적으로 학습할 feature 들 중에서 co-adapted 된 feature 의 존재 개수와 학습할 feature 의 수 간의 trade-off 로 중간 layer 까지 transfer 한 모델에서는 낮은 성능을, 후반 layer 까지 transfer 한 모델에서는 높은 성능을 보인 것입니다.
3.
연한 푸른색의 원 라벨인 BnB+ 의 경우 base B 의 경우와 performance 가 크게 다르지 않았습니다. 이는 BnB 에서 나타난 performance drop 을 fine-tuning 과정이 방지해주었기 때문입니다. BnB 의 경우와는 다르게 co-adpated feature 를 학습할 수 있었던 것입니다.
4.
붉은색 원 라벨인 AnB 의 경우가 실제로 논문에서 보고 싶었던 한 network 에서 다른 network 로의 transfer ability 를 보여줍니다. Layer 1 과 layer 2 까지의 transfer 는 거의 완벽하게 성능이 보존되었고, 다른 task 임에도 불구하고 첫 두 layer 까지 Gabor features 와 color blobs 등을 general 하게 가짐을 실험적으로 보여주었습니다. Layer 3 부터는 서서히 성능이 감소하기 시작하는데, 이는 푸른색 원 라벨 BnB 에서 본 결과처럼 co-adapted 된 feature 의 영향과 specific 한 feature 의 영향(뒤 쪽의 layer 까지 general 한 layer 로 간주하고 initialize 를 했기 때문)을 합쳐진 결과로 볼 수 있었습니다. 때문에 BnB 에서보다 더 성능의 저하가 클 수 밖에 없었던 것으로 보고 있습니다. Layer 6 과 layer 7 에서는 co-adapted 된 feature 의 영향이 전혀 사라지고 specific 한 feature 의 영향만이 남아 performance 가 급격하게 감소한 것입니다.
5.
연한 붉은색 원 라벨인 AnB+ 의 경우는 상당히 놀라운 결과를 보여주었습니다. Transferring features 와 fine-tuning 을 모두 거친 AnB+ 의 경우 기존 target dataset 을 직접 학습한 base B 보다 높은 성능을 보여준 것입니다. 기존의 transfer learning 의 사용 의의는 small target dataset 을 이용해서 overfitting 없이 학습을 진행하는 것에 있었는데, 이 새로운 결과는 transferring features 가 dataset 이 많더라도 geralization performance 를 높여줄 수 있다는 새로운 사실을 시사합니다. 이 결과가 그냥 학습 iteration 이 많아서 (base iteration + target iteration) 이라고 생각할 수도 있는데, 이는 BnB+ 도 마찬가지이므로 iteration 수에 기반한 결과는 아니라고 보았습니다.
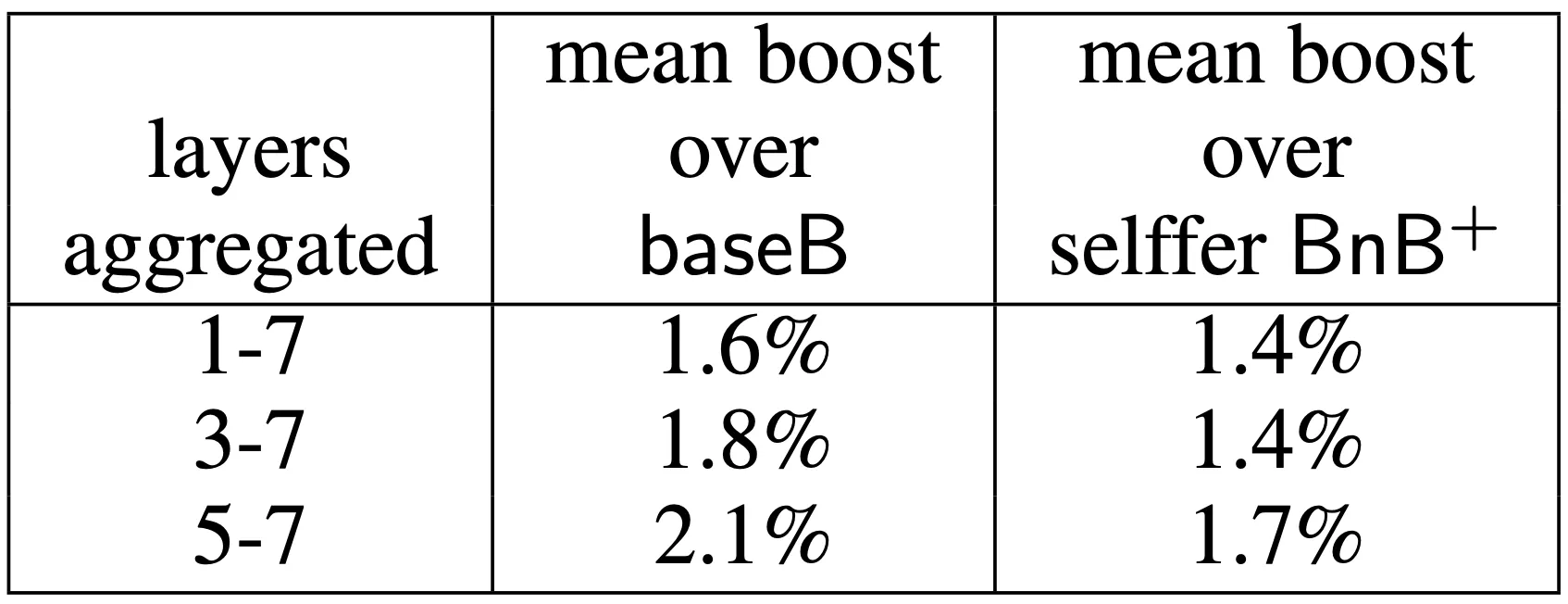
그럴듯한 설명으로는 fine-tuning 을 진행하는 iteration 동안 base dataset 에서 가지고 있었던 효과(결과적으로는 dataset B 로만은 학습할 수 없는, 더 일반성에 기여할 수 있는 방향으로의 효과로 보고 있습니다.)가 어떠한 형태로든 영향을 주어 generalization performance 에 기여하지 않았을까라고 보고 있으며, 이 설명이 맞다면 수 많은 iteration 을 거쳐서도 남아있다는 것은 놀라운 결과였습니다. 아래의 결과는 집계된 layer 별 top-1 accuracy 의 boosting 정도를 나타내는 표입니다.
Dissimilar Datasets: Man-made and Natural Classes
지금까지 similar dataset 에서 trasferring features 가 야기하는 결과를 알아보았습니다. 다음으로 논문에서는 dissimilar datset 에서의 결과를 보여줍니다.
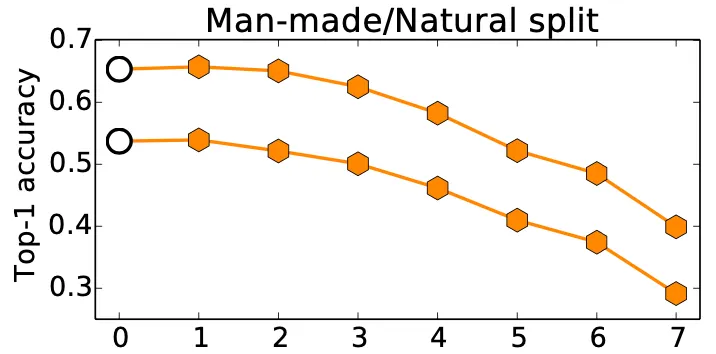
위 그림에서 비어 있는 원 라벨은 각각 위에서부터 base A (Natural), base B (Man-made) 이며 주황색 육각형 라벨은 각각 BnA, AnB 입니다. Natural classes 의 경우 class 가 449 개, Man-made classes 의 경우 class 가 551 개이기 때문에 상대적으로 class 의 수가 적은 natural classes dataset 으로 학습을 진행한 base A 의 top-1 accuracy 가 높은 것을 볼 수 있었습니다.
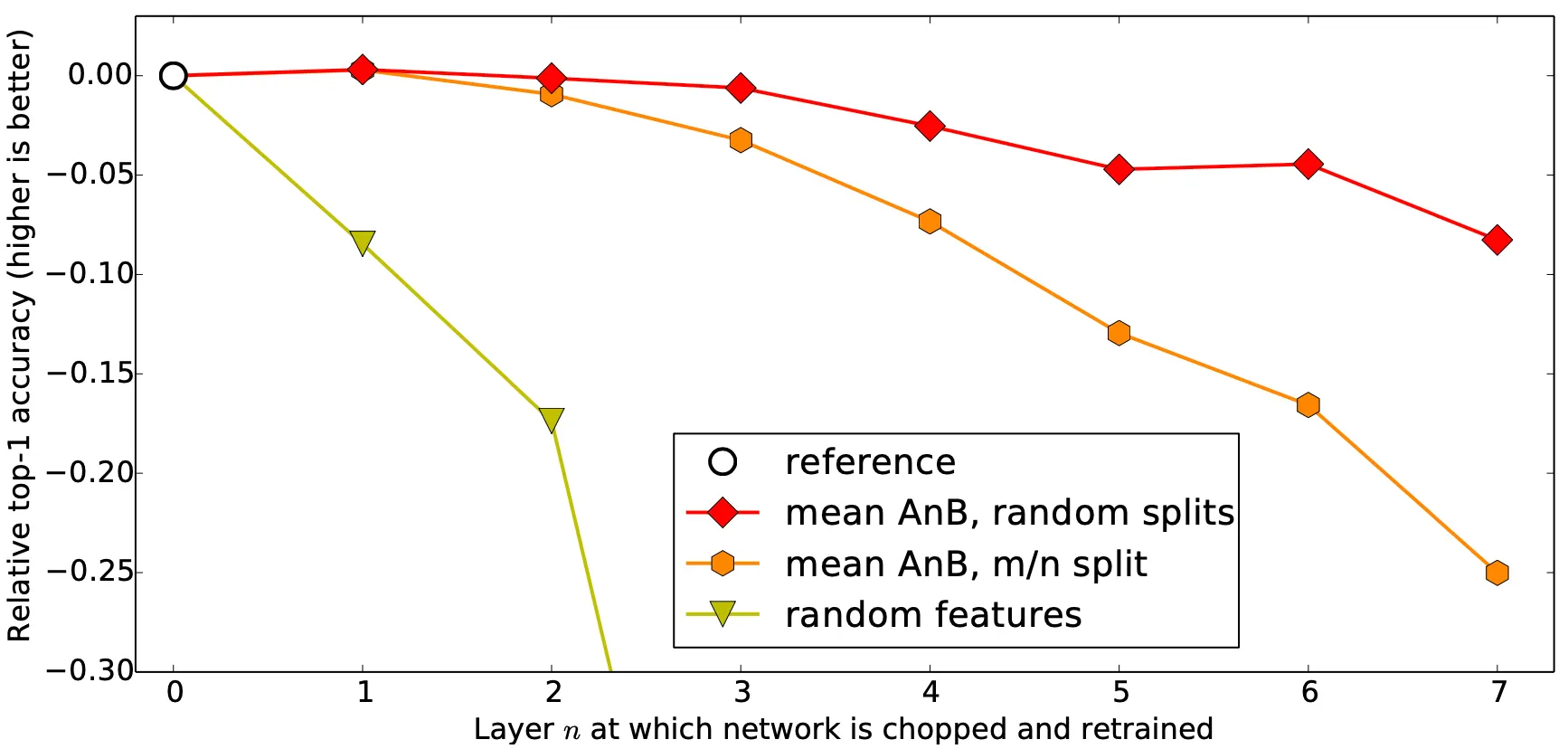
더불어, feature transfer 의 효과가 random split 때보다 작아졌다는 것을 위 그래프를 통해서 알 수 있었습니다. Mean AnB, random splits 의 경우보다 mean AnB, m/n split 의 경우가 top-1 accuracy 가 모든 구간에서 더 낮습니다. 더불어 아래에서 설명할 Random Weight 의 적용은 dissimilar 한 경우보다 성능이 좋지 못했다는 점 여기서 미리 언급하고 넘어가도록 하겠습니다.
Random Weights
마지막으로, 논문에서는 특이한 시도를 합니다. Jarrett et al. 에서 random convolutional filter, rectification, pooling, 그리고 local normalization 이 learning feature 만큼의 성능을 낼 수 있다고 발표한 것에 기반한 시도로, transffering features 로 random filter 를 활용해본 것이었다.
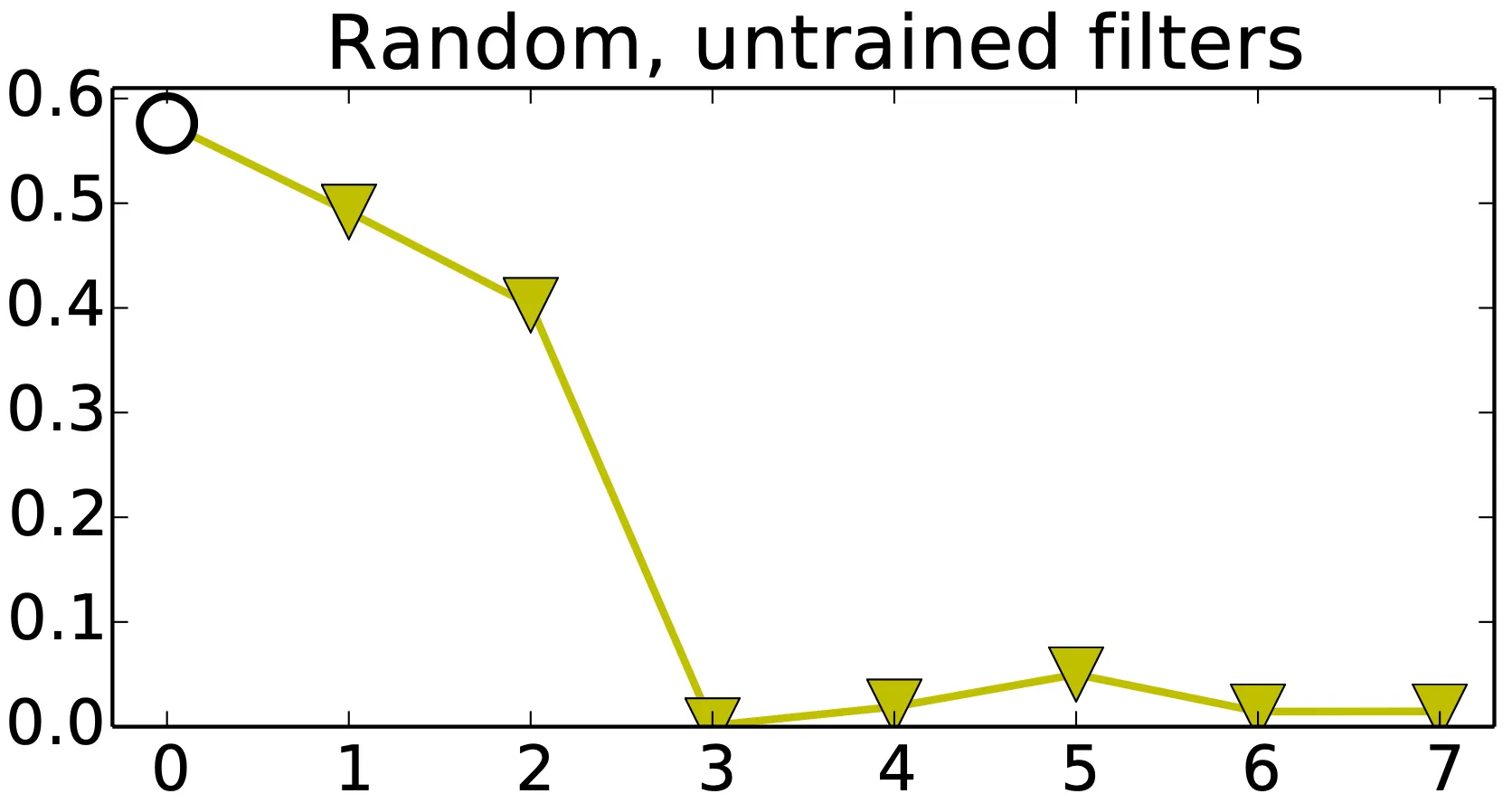
위 그림에서 비어 있는 원 라벨은 각각 위에서부터 base task 입니다. 그리고 초록색 역삼각형 라벨이 random, untrained filters 를 추가하여 진행한 task 입니다. 결과적으로, layer 1 과 layer 2 에서 performance 가 급격하게 저하되었고, layer 3 이후부터 거의 0 에 가까운 accuracy 를 보여주었습니다. 이 결과를 통해서 random weight 를 CNN 에 적용하는 것은 Jarrett et al. 에서처럼 적은 network size 와 적은 dataset 에 적용하는 것보다 성능에 있어서 효과적이지 못함을 알 수 있었습니다.
하지만 이는 Jarrett et al. 에서의 경우와 세부적인 상황이 많이 달랐기 때문에 나타난 결과로 볼 수 있었습니다. Jarrett et al. 에서와 같이 max pooling 과 local normalization 을 사용했지만, 대신에 를 사용했고, 다른 layer number 와 size 를 가지고 있었고, Jarrett et al. 에서는 오직 두 개의 layer 에만 random weight 를 적용했습니다.
논문에서는 정리하는 단계로 다음과 같은 세 가지 요소를 언급합니다.
1.
실험을 통해 transferability 는 크게 network 의 중간 부분에서 주로 나타나는 co-adapted layer 의 효과와 higher layer 에서 나타나는 specialization 효과에 의해서 저해됨을 알 수 있었습니다. 그리고 이는 실제로 feature 가 어느 부분(초반, 중반, 후반)에서 transfer 되는지에 따라 위 두 효과가 얼마나 지배적인지가 정해진다는 것도 보여주었습니다.
2.
실험을 통해 transferability 가 두 task 간의 similarity 에 긍정적인 영향을 받는다는 것을 보여주었습니다. 하지만, similarity 가 작은, distant 한 task 도 random 한 weight 를 transfer 하는 것보다는 좋은 효과를 나타냄을 보여주었습니다.
3.
단순히 적은 데이터를 이용한 학습의 용도 뿐만 아니라, generalization performance 를 높이는 데에도 transfer learning 이 사용될 수 있음을 보여주었습니다.
Conclusion
이것으로 논문 “How transferable are features in deep neural networks?” 의 내용을 간단하게 요약해보았습니다.
적은 데이터로 학습해볼 일이 생길 것 같아서 transfer learning 에 흥미를 가지고 있었는데, Transfer Learning 이 동작하는 원리를 비롯하여 transfer learning 의 효율을 정량적으로 분석해 주어 어느정도의 효과를 가지는지에 대한 대략적인 정보를 얻을 수 있었던 것 같습니다. 특히 generalization performance 를 높이는 부분은 굉장히 신선하게 다가왔던 것 같습니다.
Transfer Learning 에 관심이 있으신 분들은 한 번 꼭 읽어보시기를 추천합니다.
