본 포스트에서는 기존 2D Diffusion Prior 를 기반으로 Text-to-3D task 를 수행할 때 많이 사용되었던 Score Distillation Sampling 방식을 확장하여 제안한 논문에 대해서 소개드리려고 합니다.
Project Page 및 논문을 직접 읽어보시고 싶으신 분들은 위 링크를 참고하시면 좋습니다.

Objective
3D 를 나타내는 컨텐츠와 기술들은 현실세계의 경험과 매우 유사한 환경 및 물체를 시각화하고, 이들과 상호작용하는 것을 가능하게 했습니다. 3D 컨텐츠와 기술의 빠른 발전은 건축, 애니메이션, 게임, VR & AR 등 분야를 막론하고 다양한 곳에서 이들을 사용하는 현상을 불러오게 되었습니다. 하지만, 아이러니하게도 여전히 고품질의 3D 컨텐츠를 생성하는 것은 어려운 작업으로 남아있으며, 전문적인 디자이너에게도 이는 막대한 시간과 노력이 드는 영역으로 알려져 있습니다.
이러한 문제점을 해결하기 위한 방법론으로 이전 논문리뷰에서는 DreamFields, DreamFusion 을 다룬 적 있고, 최근에는 Magic3D, Fantasia3D 와 같이 High Resolution, High Quality 에 치중한 논문들이 등장했습니다. 이들의 공통점은 모두 텍스트를 기반으로 3D 컨텐츠를 자동으로 생성한다는 것이며 이러한 점에서 이들 모두 앞서 언급한 문제를 어느정도 잘 풀 수 있는 나름 효과적이고, 잘 동작하는 방법론들입니다.
Magic3D: A DSLR photo of an ice cream sundae
위에 언급되었던 선행연구들 중 DreamFusion 은 처음으로 Score Distillation Sampling (SDS) 하는 방법론을 소개하여 2D Diffusion Prior 를 사용해 3D 를 생성해낸 것으로 유명합니다. 3D 를 임의의 뷰에서 렌더링한 이미지가 기존의 2D Diffusion Model 에서 평가했을 때 주어진 텍스트와 높은 likelihood 를 보여주도록 한 것이 그 핵심이며, 구체적으로는 U-Net Denoising Network 를 전체적으로 통과하는 과정을 생략하여 효율성을 챙김과 동시에 2D → 3D 에서 발생할 수 있는 inconsistency problem 을 score function 을 사용하여 지속적으로 update 하는 형태로 풀어내게 됩니다.
ProlificDreamer: A sliced loaf of fresh bread
DreamFusion 에서는 그들의 SDS 방법론이 Over-Saturation, Over-Smoothing, Low-Diversity 문제가 발생한다는 한계점을 지적합니다. 논문에서는 이러한 한계점과 Text-to-3D 과정에서 사용되는 configurations 들 중 Rendering Resolution 이나 Distillation Time Schedule 과 같은 항목들에 대한 연구는 진행되지 않은 영역이라고 밝히며, 이를 해결하기 위한 새로운 방법론으로 Variational Score Distillation (VSD) 를 제안합니다.
Background
ProlificDreamer 에서 다루는 내용들을 구체적으로 이해하기 위해서는 Diffusion Model (LDM), Text-to-3D (SDS), 3D Representations (NeRF) 에 대해서 모두 알아야 합니다. 때문에 논문에서도 이러한 부분들을 배경 부분에서 설명하고 있지만, 본 포스트에서는 Diffusion (LDM) 과 3D Representations (NeRF) 부분은 따로 논문으로 리뷰한 포스트가 있기 때문에 언급하지 않도록 하고, 직접적으로 비교하여 보면 좋을만한 Text-to-3D (SDS) 에 대해서만 이야기하고자 합니다. 아래는 참고하시면 좋을 리뷰들입니다.
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
본 포스트에서는 View Synthesis 분야에서 새로운 방법론을 제시한 논문에 대해서 소개드리려고 합니다. 리뷰하려는 논문의 제목은 다음과 같습니다.

NeRF: Neural Radiance Field
High-Resolution Image Synthesis with Latent Diffusion Models
본 포스트에서는 기존의 2D Image 에서 진행되었던 Diffusion Process 를 Latent Space 로 변경하여 효율적으로 다양한 가이던스에 기반하여 고해상도 이미지의 생성에 성공해낸 논문에 대해서 소개드리려고 합니다.

Latent Diffusion Model
Text-to-3D Generation by Score Distillation Sampling (SDS)

SDS 는 앞서 언급드린 것처럼 DreamFusion 에서 처음으로 제안한 Text-to-3D 에 2D Diffusion Prior 를 사용하는 방법론이며 Score Jacobian Chaining (SJC) 라고도 불립니다. 이는 현재 3D 를 임의의 뷰에서 렌더링된 이미지의 text-conditioned distribution 와 pre-trained 2D Diffusion Model 의 text-conditioned distribution 의 KL-Divergence 항목으로 학습의 objective 가 정의됩니다.
위 식에서 로 sampling 할 수 있는 Diffusion Model 의 timestep 이며, 로 sampling 할 수 있는 initial noise 입니다. 는 3D 를 이미지로 렌더링하는 미분가능한 렌더러 (Differentiable Renderer) 이고 이에 따라, Diffusion Model 의 forward process 로 위의 첫 번째 식이 나오게 됩니다.
위 loss 를 에 대한 gradient 를 구하게 되면 아래와 같은 형태로 근사할 수 있다는 것이 SDS 의 주요 내용입니다. KL-Divergence 항목을 미분하게 되면, distribution 의 logarithm 의 차이로 나타낼 수 있는데 이것이 으로 나타난 부분입니다. 특이한 점은 하나의 에 대해서 진행하고 expectation 을 계산하는 형태이기 때문에 U-Net 전체를 통과하는 과정이 생략되어 있고 이에 대한 back propagation 의 부분도 당연히 없음을 볼 수 있습니다.
Method
논문에서 제안한 Variational Score Distillation (VSD) 가 SDS 와 차별적인 점은 3D 를 표현함에 있어서 3D distribution 을 고려한 점입니다. 기존의 SDS 는 3D 를 표현하는 parameter 인 가 하나 주어진다면 하나의 3D 를 나타낼 수 있었고 이 를 주어진 condition 을 이용해 optimize 하는 형태를 취하고 있었습니다. 논문에서는 를 target 3D distribution 을 표현할 수 있는 항목으로 취급합니다.
Sampling from 3D Distribution as Variational Inference
특정 text prompt 가 주어졌을 때, 로 표현되는 3D representation 이 가질 수 있는 distribution 를 고려해볼 수 있습니다. 앞서는 가 최적화를 위한 항목이자, 결과였는데 VSD 에서는 distribution 를 최적화하는 형태를 고려한 것이며, 이 때문에 Background 에서 이야기했던 항목들이 조금씩 바뀌게 됩니다.
3D 를 임의의 뷰에서 렌더링된 이미지의 text-conditioned distribution 는 로 바꾸어서 생각해야 하고, 이를 이용해 그대로 이전 수식을 작성하게 되면 다음과 같습니다.
놀랍게도, VSD 에 대한 수식적인 “컨셉” 은 이게 끝입니다.
논문에서는 처음에 우리가 관심 있는 일 때의 marginal distribution 에 대한 수식을 이야기하지만, LDM 에서와 마찬가지로 해당 수식을 하나의 를 사용하여 표현해내는 것은 어렵고, iterative 한 구조를 차용합니다. 때문에 각 를 sampling 하고 해당 에서의 KL-Divergence 항목으로 loss 를 정의하는 동일한 과정을 진행하여 하나의 3D 를 표현하는 가 3D 의 distribution 을 표현하는 로 치환된 식이 나타난 것입니다.
Update Rule for Variation Score Distillation
다만, 한 가지 의문점이 남는 것은 그냥 를 로 바꿔도 되는가- 입니다.
하나의 3D 를 optimize 하는 문제에서는 그냥 각 timestep 에서 rendering 된 이미지의 text-conditioned distribution 과 pre-trained 2D Diffusion Model 의 text-conditioned distribution 를 일치하도록 를 최적화하는 과정이었습니다. 렌더링된 이미지가 distribution 상으로 pre-trained 2D Diffusion Model 의 conditional 하게 생성된 이미지와 유사하며, 3D 상으로도 plausible 한 결과가 나온다는 생각으로 쉽게 이어집니다. 하지만, 를 로 바꾸어 distribution 을 최적화한다는 개념이 잘 와닿지는 않습니다.
사실 앞선 세션에서 말씀드린 수식적인 컨셉을 실현화하는 가장 간단하고 쉬운 방법은 에 대한 parameteric generative model 을 설계하는 것입니다. Distribution 을 최적화한다는 것은 앞서 많은 generative model 연구들에서 특정 도메인의 학습 데이터를 사용해 학습할 때 줄곧 해왔던 내용이기 때문입니다. 하지만 이러한 방법은 computation cost 와 optimization complexity 측면에서 효과적인 방법은 아닙니다.
때문에, 논문에서는 특별하게 최적화의 대상인 의 initial 상태인 로부터 시작하여 를 sampling 한 뒤에 ODE 를 해결함을 통해서 임의의 update timestep 로부터 를 sampling 할 수 있음을 Appendix 에서 보입니다. 저는 해당 수식에 대한 유도과정은 직접 살펴보지 않았는데, 궁금하신 분들은 Appendix 를 찾아보시는 것을 추천드립니다.
위 식에서 항목은 noisy real image 에 대한 score 이고, 항목은 noisy rendered image 에 대한 score 입니다. 앞의 항목은 이전에도 나왔던 pre-trained 2D Diffusion 의 text-conditioned distribution logarithm 의 gradient 입니다. 여기서 중요하게 살펴볼 점은 논문에서는 뒤의 항목 (noisy rendered image 에 대한 score) 을 구현하기 위해서 또 다른 noise prediction network 인 를 도입합니다.
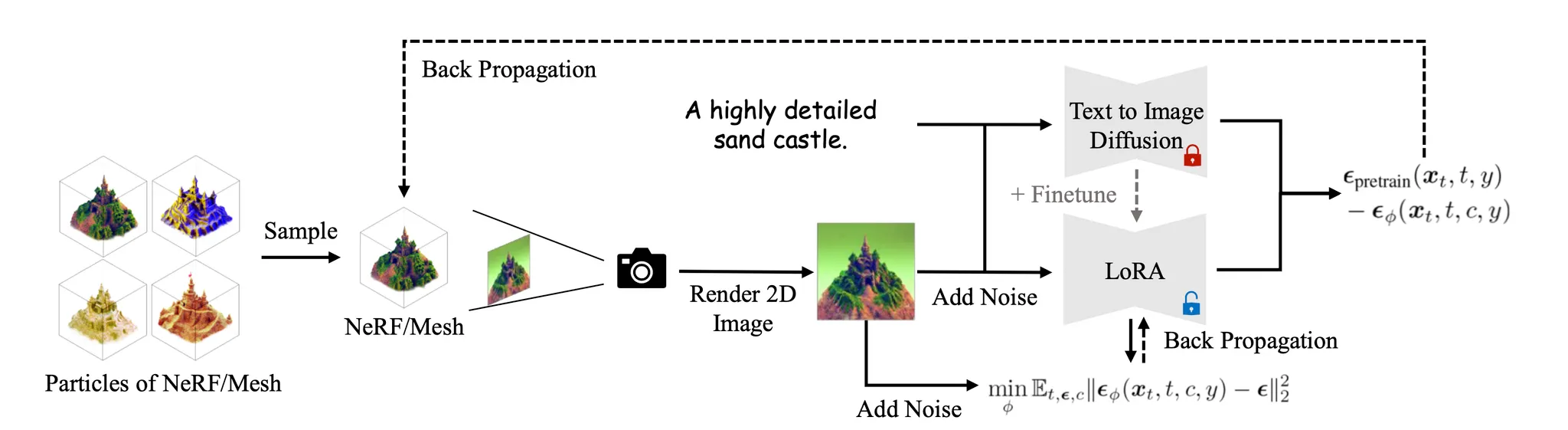
Overview of VSD
풀어서 설명하자면, 가 주어졌을 때 text-conditioned distribution 의 logarithm 의 gradient 항목을 산출하라는 용도로 또 다른 네트워크를 만들었다고 보시면 되며, 이러한 네트워크의 구조로 작은 U-Net 이나 LoRA 를 사용하게 됩니다. 기존 SDS 에서는 가 주어졌을 때 text-conditioned distribution logarithm 의 gradient 항목만 필요했고 이는 사실 상 이미지에 뿌려 준 noise 으로 사용할 수 있었는데, 이제는 해당 방식을 사용할 수 없기 때문에 네트워크를 구성하여 score 를 예측하게 한 것입니다.
이 때 사용하게 되는 LoRA 네트워크의 학습은 일반적인 Diffusion Model 의 학습 과정을 그대로 따르게 되는데, 단지 학습과정에서 사용하는 데이터셋을 3D 에서 렌더링된 이미지로 사용할 뿐입니다. 이 과정을 수식으로 나타내면 아래와 같습니다.
그리고, 각각의 ODE time 에 대해 가 현재 distribution 의 text-conditioned distribution 의 logarithm 의 gradient 와 맞아떨어져야 하기 때문에 통해 각 를 기존 SDS 방식과 동일하게 update 할 수 있습니다. 이는 다음과 같은 수식에 의해 구현됩니다.
Experiments
Resuls of ProlificDreamer
논문에서는 VSD 방법론을 사용해 Text-to-3D 를 구현한 ProlificDreamer 를 선보였고, 그 정성적인 결과를 아래와 같이 공개했습니다. 논문에서는 공정한 비교를 위해 SDS 의 경우에는 VSD 에서의 particle 을 사용하여 결과를 비교했다고 합니다.

Generated Results from ProlificDreamer
위 결과 뿐만 아니라, 논문에서는 3D 의 distribution 을 학습하는 것을 보여주기 위해서 같은 text 를 이용해 다양한 결과를 생성할 수 있음을 정성적으로도 보여줍니다. 아래는 그 결과입니다.

Diverse Results from ProlificDreamer
Object-Centric Generation
논문에서는 그들의 결과를 DreamFusion, Magic3D, 그리고 Fantasia3D 와 비교합니다. 이 세가지 baseline 은 모두 SDS 에 기반한 방법론들이고 이들의 source 가 아직 공개되지 않았기 때문에 해당 논문들에서 공개한 이미지들을 이용해 비교를 합니다.

Comparison with SDS Baselines
위 그림에서 볼 수 있는 것처럼, ProlificDreamer 는 다른 SDS 기반의 논문들의 결과보다 높은 fidelity 와 섬세한 디테일을 가진 3D 를 표현할 수 있음을 확인할 수 있었습니다.
Large Scene Generation
논문에서는 scenes 또한 높은 fidelity 와 fine detail 을 가지고 표현할 수 있다는 것을 보여줍니다. 그 결과는 아래와 같습니다.

Large Scene Generation (NeRF) Results
Depthmap 정보를 함께 제공해줌으로써, 논문의 결과가 단순히 이상한 structure (e.g., sphere) 에 texture 만 입힌 형태가 아니라, 적절한 geometry 를 가지고 있음을 알 수 있음을 강조합니다.
Ablation Study
Ablation on NeRF Training
논문에서는 NeRF Training 에서 도입했던 방법론 하나하나에 Ablation Study 를 진행합니다. 그 정성적인 결과는 다음 그림과 같습니다.
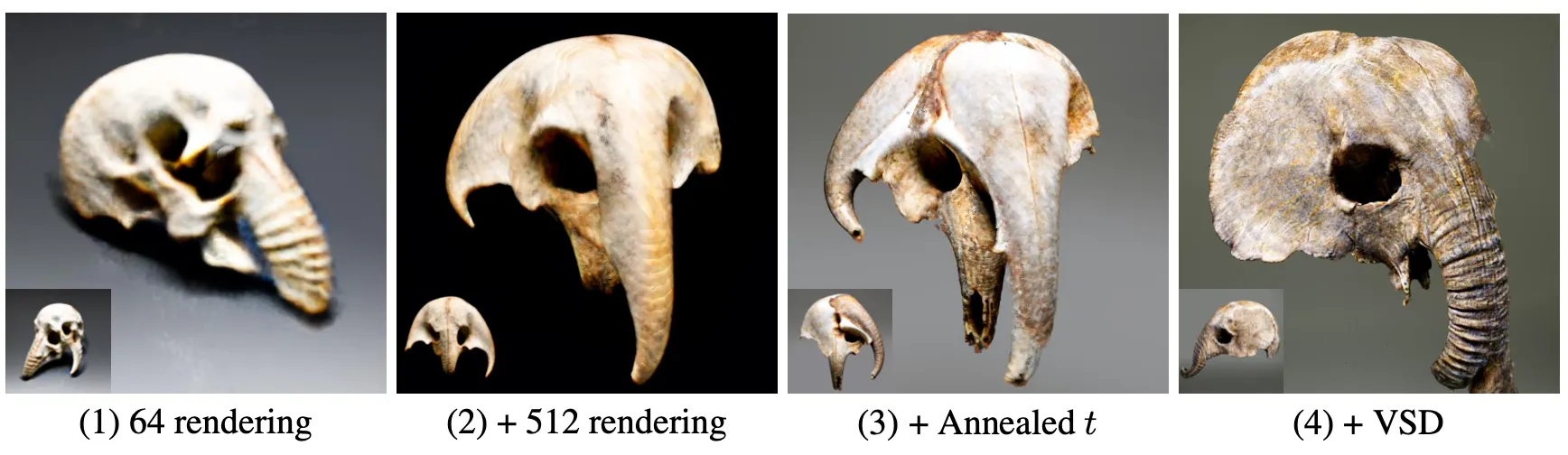
Ablation on NeRF Training
가장 왼쪽부터 (1) SDS + 64 Resolution Rendering, (2) SDS + 512 Resolution Rendering, (3) SDS + 512 Resolution Rendering + Annealed Time Schedule, (4) SDS + 512 Resolution Rendering + Annealed Time Schedule + VSD 입니다. 구체적으로 어떠한 점이 좋아졌는지 논문에서 언급하지는 않지만, 정성적인 결과만 보았을 때 (2),(3) 에서는 blurriness, smoothness 가 줄어들었고, (4) 에서는 fidelity, detail 이 추가된 것으로 보입니다.
Ablation on Mesh Fine-Tuning
논문에서는 SDS 와 VSD 를 Mesh Fine-Tuning 측면에서 Ablation Study 를 진행합니다. 먼저 논문의 방법론인 VSD 로 High Fidelity 를 가지는 NeRF 를 학습하여 이로부터 다시 NeRF 로 geometry 를 추출한 뒤, VSD 와 SDS 로 다시 Fine-Tune 하여 비교한 것입니다.
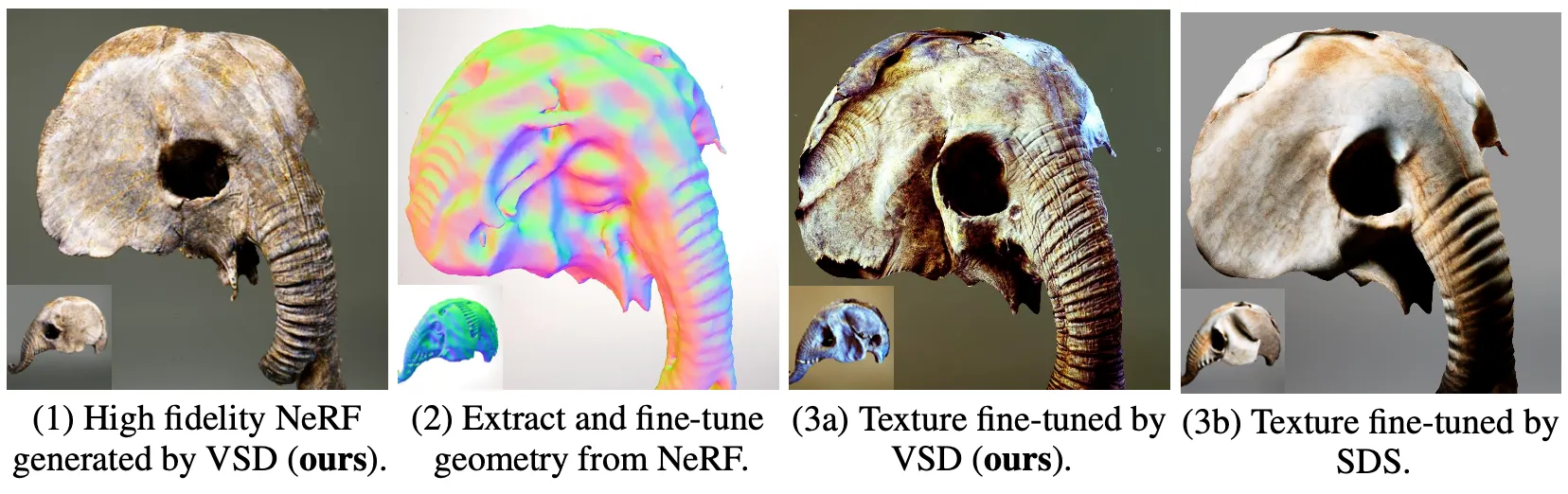
Ablation on Mesh Fine-Tuning
논문에서는 처음에 high quality NeRF 를 얻어내야 VSD 의 표현력을 잘 살릴 수 있다고 주장하면서 VSD 방법론으로 NeRF 를 학습합니다. 이후 texture 를 fine-tune 할 때 VSD 방법론이 SDS 보다 fidelity 측면에서 우월했고, 이러한 비교는 둘 모두 high-fidelity 의 동일한 NeRF 에서 시작했기 때문에 공정하다고 주장합니다.
Ablation on CFG
논문에서는 CFG (Classifier Free Guidance) 가 생성되는 3D 의 다양성에 어떤 영향을 미치는지에 대해서 실험했고, 그 결과 작은 CFG 가 다양성에 긍정적인 영향을 준다는 것을 알 수 있었다고 합니다.

Ablation on CFG
SDS 방법론이 작은 CFG 에 대해서 그럴듯한 결과를 생성해내지 못한 것과 달리 논문의 VSD 방법론은 작은 CFG 에서 잘 동작하여 다양한 결과들을 생성해낸 것을 확인할 수 있습니다.
Conclusion
이것으로 논문 “ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation” 의 내용을 간단하게 요약해보았습니다.
이 논문은 트위터에서 논문들을 살펴보다가 기존의 SDS 기반의 Text-to-3D 를 개선하는 새로운 방법론을 제안했다고 해서 관심있게 보던 논문이었습니다. 안 그래도 SDS 로 양산되는 3D Generation, Stylization 연구 트렌드를 보면서 지루하다고 느껴질 참이어서 더욱 반가웠던 것 같습니다.
하지만, 내용이 수학적으로 생각보다 난해하고 어려워서 마냥 즐겁게 읽지만은 못했던 것 같습니다. Conceptual 하게만 접근할 것이라면 짧은 시간에 괜찮은 intuition 을 얻어갈 수 있을 것 같긴 했는데 개인적으로 짧은 시간에 이해될 정도로 깔끔하게 글이 작성된 느낌은 아니라고 생각했습니다. (제가 멍청해서 일지도…)
총평은, 이 논문은 수학을 깊게 파고 싶은 분들은 풀로 읽으셔도 괜찮을 것 같습니다만, 그렇지 않다면 리뷰나 개괄적인 부분만 가져가시는 걸 추천드립니다. 저 또한 Appendix 에 유도과정까지 가지 않았고, 아직 ODE 의 유도와 해당 유도에서 나타난 항목을 렌더링한 이미지를 사용한 LoRA 로 estimate 한 부분에 대해서 추가로 공부가 필요한 것 같습니다.