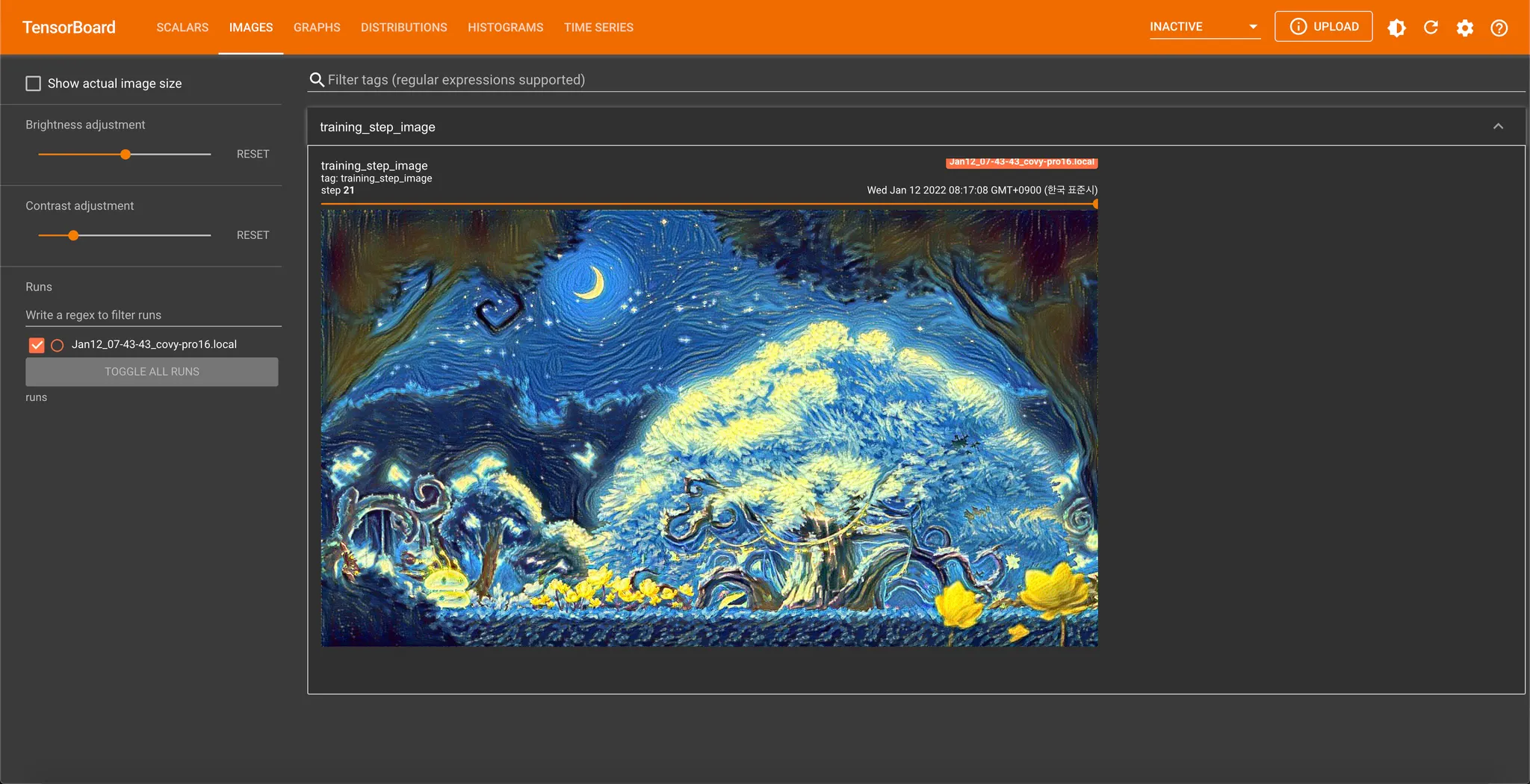
Tensorboard: Logging Images
ML 모델을 학습하다 보면 문득 다음과 같은 생각이 들 때가 있습니다.
” 지금 학습이 제대로 되고 있는 것일까? “
“ 학습 환경(ex. hyperparameters) 을 바꾸었을 때 학습이 더 잘 될 수 있을까? “
“ 작성한 모델이 원하는대로 구현이 되었을까? ”
위에 대한 의문이 들 때, 가장 먼저 생각해볼 수 있는 행동들은 단순하게 실행 도중에 원하는 것들을 확인하는 코드를 삽입하는 것입니다.
def training_step(self, batch, batch_idx):
self.input_image.requires_grad_(True)
self.model.requires_grad_(False)
self.model(self.input_image)
with torch.no_grad():
self.input_image.clamp_(0, 1)
style_score = sum([style_loss.loss for style_loss in self.style_losses])
content_score = sum([content_loss.loss for content_loss in self.content_losses])
style_loss = style_score * self.style_weight
content_loss = content_score * self.content_weight
loss = style_loss + content_loss
# 매 Batch Training Step 마다 Loss 출력
print(
f'epoch: {self.trainer.current_epoch} |
style loss: {style_loss} |
content loss: {content_loss} |
total loss: {loss}'
)
Python
복사
def training_epoch_end(self, outputs):
with torch.no_grad():
self.input_image.clamp_(0, 1)
# 매 epoch 마다 변경된 이미지 저장
save_image(self.input_image, next_path('./output_images/output_image_%s.jpg'))
Python
복사
이렇게 구현하더라도, 어느정도는 학습이 잘 되고 있는지 확인해볼 수 있습니다. 다만, 콘솔에 직접 찍는 형태이거나 디렉토리에 직접 저장하는 형태이기 때문에 모아서 보는 것이 어렵고 가시성이 떨어집니다. 다른말로 하면 한눈에 지금 어떤 상황인지 보기가 상당히 어렵습니다. 본 포스트에서는 이러한 상황에서 사용할 수 있는 라이브러리인 Tensorboard 와 그 사용법에 대해서 소개드리려고 합니다.
Tensorboard, 무엇일까?
Tensorboard 는 앞서 소개드린 상황에서 사용할 수 있는 ML 학습 시각화 툴킷입니다.

일반적으로 ML 학습과정을 개선하려면 측정이 필요하고, 측정 결과를 효과적으로 보기 위해서는 시각화가 필요합니다. Tensorboard 는 ML 모델 설계에서 원하는 metric 을 측정하여 시각화할 수 있는 도구를 제시해줍니다.
Tensorboard 에서 설명하기를, 다음과 같은 도구들을 제공한다고 합니다
1.
손실 및 정확도와 같은 측정항목 추적 및 시각화
2.
모델 그래프(작업 및 레이어) 시각화
3.
시간의 경과에 따라 달라지는 가중치, 편향, 기타 텐서의 히스토그램 확인
4.
저차원 공간에 임베딩 투영
5.
이미지, 텍스트, 오디오 데이터 표시
6.
TensorFlow 프로그램 프로파일링
지금부터는, PyTorch 프로젝트에서 Tensorboard 를 사용하여 원하는 metric 을 측정하여 시각화할 수 있는 방법에 대해서 소개드리려고 합니다.
Tensorboard 세팅하기
PyTorch 는 자체적으로 utils 로 Tensorboard 를 제공하고 있습니다. 다만, web browser 를 통해 로그 데이터를 시각화하기 위해서는 PyTorch 뿐만 아니라 Tensorboard 자체 라이브러리가 필요합니다.
(venv) $ pip install tensorboard
Shell
복사
설치를 완료했다면, tensorboard 명령어가 활성화되신 것을 확인하실 수 있으실 것입니다. web browser 를 통해 로그 데이터를 시각화 하는 명령어는 다음과 같습니다.
(venv) $ tensorboard --logdir=runs
Shell
복사
여기서, logdir 플래그는, 로그 데이터가 위치한 디렉토리의 경로를 지정해준다고 보시면 됩니다. 이후 설명드릴 SummaryWriter 가 로그 데이터를 쌓는 기본 디렉토리 경로가 runs 이기 때문에 위와 같이 지정해주었습니다.
No dashboards are active for the current data set.
이는, 해당 디렉토리 경로에 생성된 로그데이터가 없어서 나타나는 현상입니다. 이어서 로그데이터를 생성하는 방법에 대해서 소개드리려고 합니다.
Tensorboard Log Data 생성하기
Tensorboard 에서 시각화할 로그 데이터는 이전에 말씀드렸던 PyTorch 내부에 utils 로 존재하는 친구를 사용하여 생성할 수 있습니다. 정형화된 로그 데이터 쌓는 과정은 다음과 같습니다.
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
# 로그를 쌓고 싶은 데이터를 꺼낼 장소에서 다음 구문 적어넣기
writer.add_[시각화 형태](파라미터들)
Python
복사
위와 같이 SummaryWriter 인스턴스를 선언하고, 해당 인스턴스의 다양한 메소드들을 실행함으로써 로그 데이터를 쌓을 수 있습니다. 시각화 형태로는 scalar, image, histogram, graph 등이 있고, 각각의 시각화 방법에 따라서 다른 parameter 를 넣어주어야 합니다. 가장 간단한 예시로 이전에 제가 진행한 Neural Style Transfer 프로젝트에 적용한 예시는 다음과 같습니다.
def training_step(self, batch, batch_idx):
self.input_image.requires_grad_(True)
self.model.requires_grad_(False)
self.model(self.input_image)
with torch.no_grad():
self.input_image.clamp_(0, 1)
style_score = sum([style_loss.loss for style_loss in self.style_losses])
content_score = sum([content_loss.loss for content_loss in self.content_losses])
style_loss = style_score * self.style_weight
content_loss = content_score * self.content_weight
loss = style_loss + content_loss
# 매 Batch Training Step 마다 Loss 로그 데이터 생성
writer.add_scalar('Style Loss', style_loss, self.trainer.current_epoch)
writer.add_scalar('Content Loss', content_loss, self.trainer.current_epoch)
writer.add_scalar('Training Loss', loss, self.trainer.current_epoch)
Python
복사
def training_epoch_end(self, outputs):
with torch.no_grad():
self.input_image.clamp_(0, 1)
# 매 Epoch 마다 이미지 로그 데이터 생성
writer.add_image('training_step_image', self.input_image.squeeze(0), self.trainer.current_epoch)
Python
복사
위와 같이 로그 데이터를 쌓는 코드를 작성하고 기존처럼 학습을 돌리게 되면 runs 에 DATETIME 및 HOSTNAME 기준으로 로그 디렉토리가 생성됩니다.
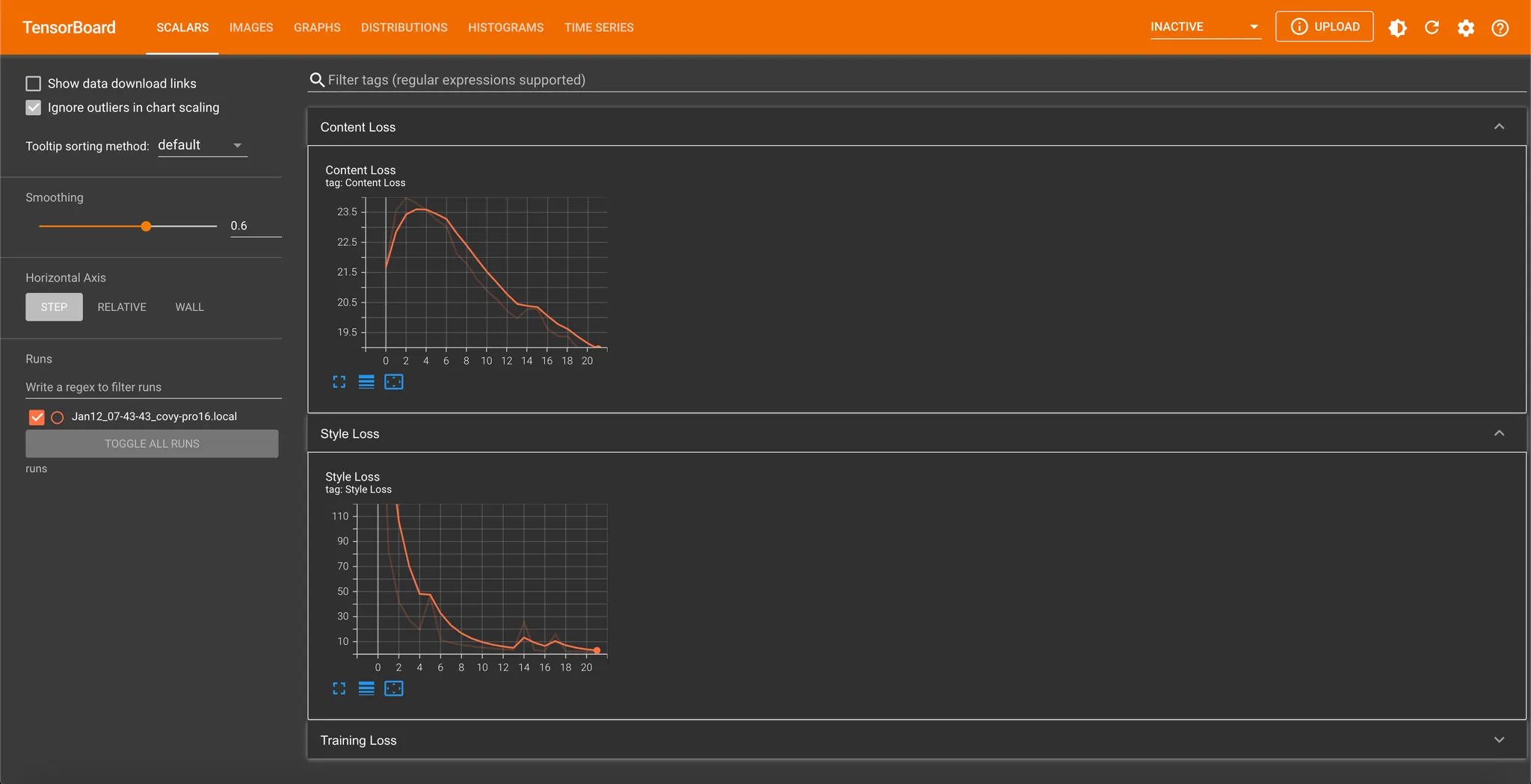
Tensorboard: Logging Scalars
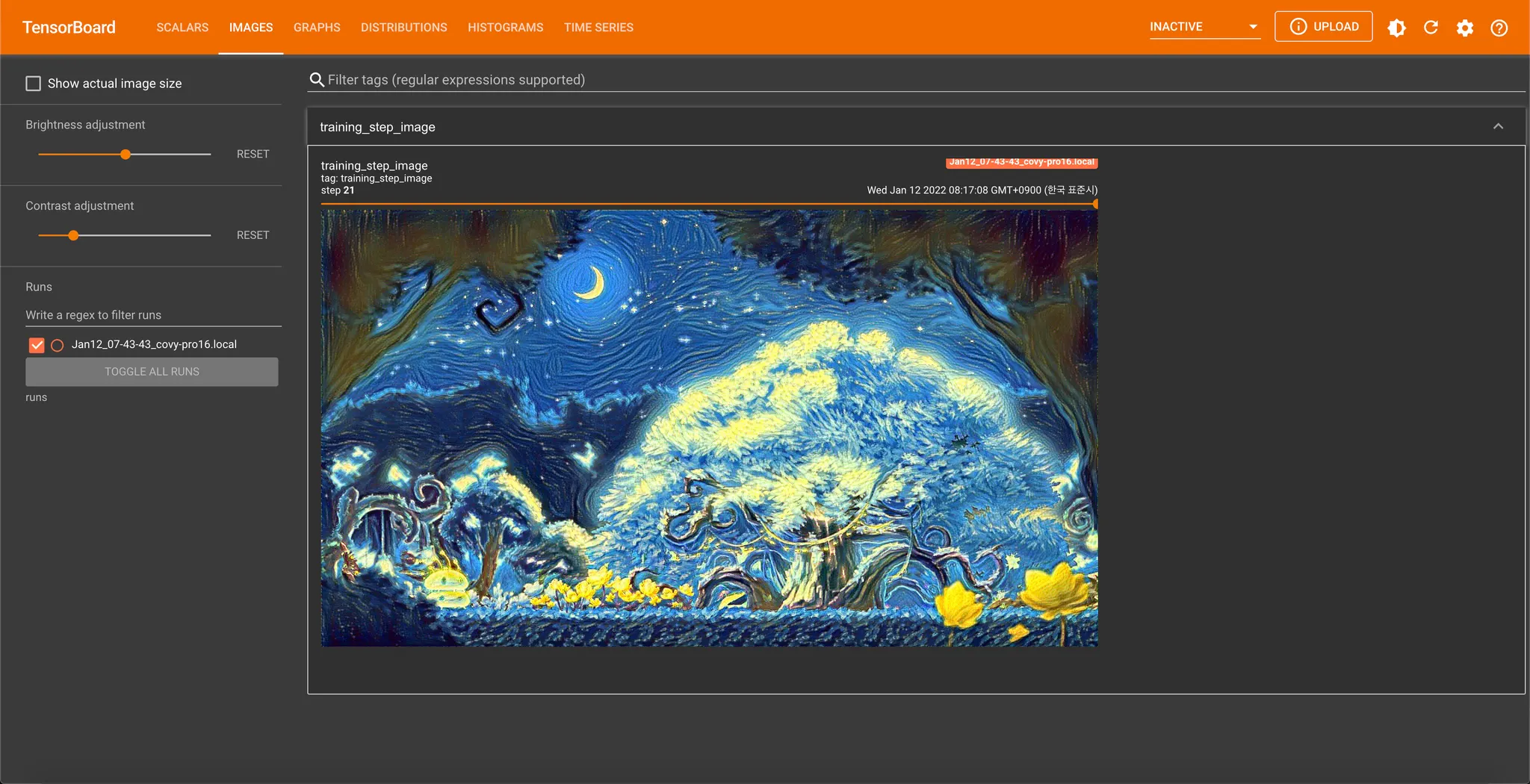
Tensorboard: Logging Images
Scalar 의 경우, 각 Epoch (x 축) 에 대한 Loss (y 축) 의 형태의 plot 을 통해 한 눈에 변화를 확인할 수 있으며, Image 의 경우, 각 Epoch (Range Slider) 를 조절하면서 이미지의 변화를 확인할 수 있습니다.
Tensorboard Log Data 모아보기
앞에서 말씀드렸던 내용 중에 “학습 환경(ex. hyperparameters) 을 바꾸었을 때 학습이 더 잘 될 수 있을까?” 가 있었습니다. 학습이 상대적으로 더 잘 진행되는지를 가시적으로 비교해보기 위해서는 여러 학습을 동시에 볼 수 있어야 합니다.
Tensorboard 에서는 특정 학습에 대한 로그데이터의 디렉토리 명칭을 지정하고 각 로그데이터를 선택하여 모아 볼 수 있는 기능이 있습니다. 한 예시로, 앞서 생성한 LR scheduler 가 적용되지 않은 학습의 로그데이터의 디렉토리 명을 general 로 변경하고, 새롭게 LR scheduler 를 적용하여 학습을 진행해보고 학습 과정을 가시적으로 비교해볼 수 있습니다.
from torch.utils.tensorboard import SummaryWriter
LR_LAMBDA_VALUE = 0.9
writer = SummaryWriter(f'lr_lambda_{LR_LAMBDA_VALUE}')
def configure_optimizers(self):
optimizer = torch.optim.LBFGS([self.input_image])
return {
"optimizer": optimizer,
"lr_scheduler": {"scheduler": LambdaLR(optimizer, lr_lambda=lambda epoch: LR_LAMBDA_VALUE ** epoch)},
}
Python
복사
저는 LR_LAMBDA_VALUE 를 0.9, 0.8 로 바꾸어 진행해보았고, SCALARS 탭에서 아래와 같이 여러 학습 로그 데이터를 좌측의 Runs 에서 모두 선택하여 plot 에 동시에 표시하는 것이 가능합니다.
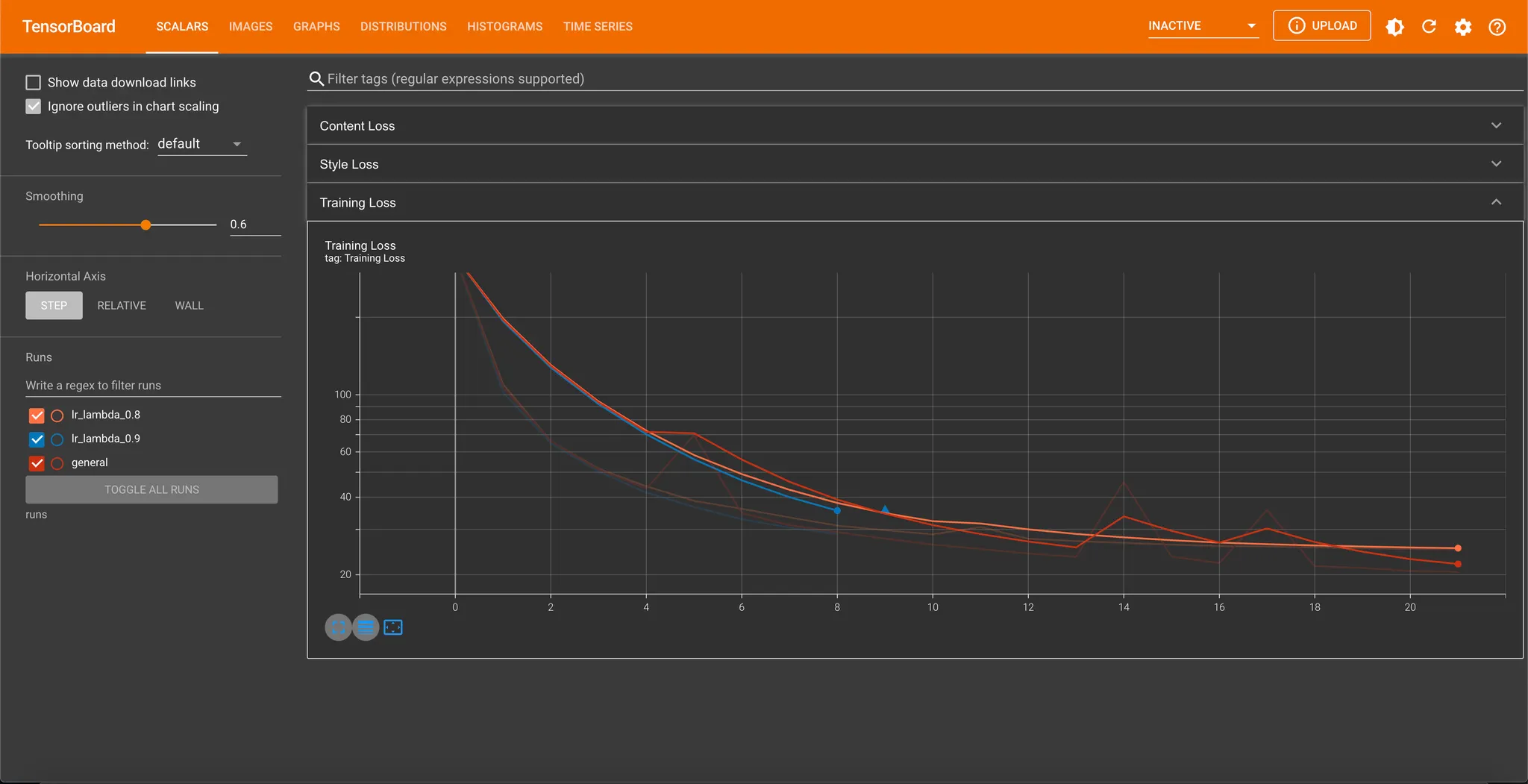
이미지도 동일하게 여러 학습 로그데이터를 동시에 표현해주는 것이 가능합니다. 물론, 저는 learning rate 의 일부만 조정했기 때문에 큰 차이는 없네요... 
다만, Learning Rate Scheduler 를 사용하지 않을 때와는 달리 learning rate 를 사용할 때 loss 의 fluctuation 이 작은 것을 실제로 관찰할 수 있었고, 감소량을 늘린 경우 조금 더 느리게 loss 가 감소함을 시각적으로 확인해볼 수는 있었습니다.
푸른 선(LR_LAMBDA_VALUE = 0.9 인 LambdaLR Scheduler 를 사용)의 경우 중간에 NaN 으로 값이 치솟았는데, 해당 친구보다 learning rate 가 큰 general 에서 해당 현상이 발생하지는 않아서 learning rate 가 크기 때문은 아닌 것 같았습니다. 이 부분은 조금 더 살펴봐야 알 것 같아요.
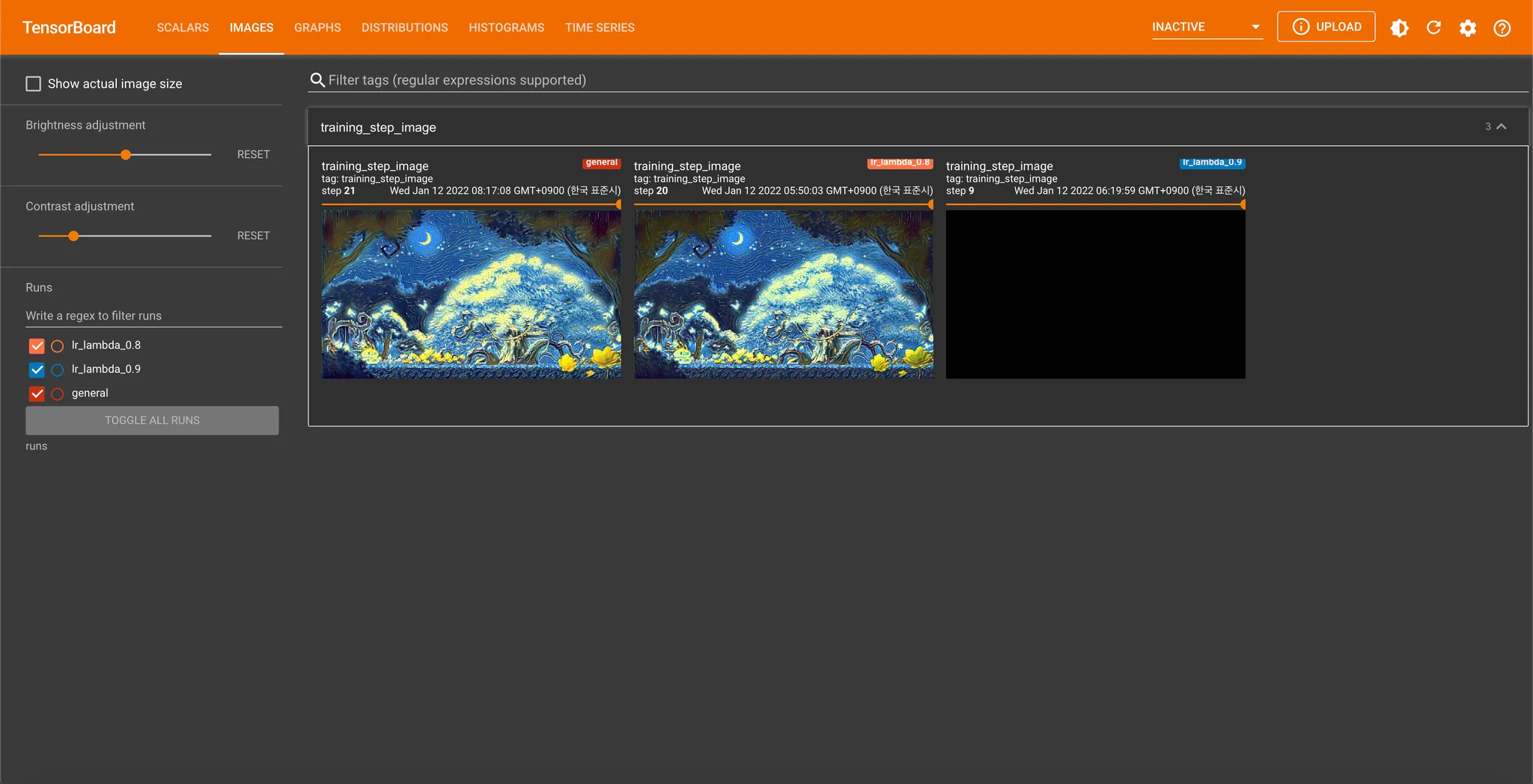
마무리
이렇게 Tensorboard 를 사용해 학습과정을 시각화하는 과정을 한 번 알아보았습니다. 소개드린 scalar, image 가 대중적으로 사용되지만, Tensorboard 에는 graph, histogram 등 다양한 시각화도구들도 있으니 관심있는 분들은 아래의 문서를 참고하여 구현해보시는 것을 추천드립니다.
개인적으로는, 대시보드 및 시각화 도구에 대해서 이전부터 한 번쯤은 살펴보아야겠다- 하고 생각했었는데 이번 기회에 가장 대중적으로 쓰인다는 Tensorboard 에 대해서 알아볼 수 있어서 좋았던 것 같습니다. 생각보다 굉장히 간단하고 한 눈에 보기 쉽게 시각화를 할 수 있어서 좋았던 것 같습니다. 개인적으로 Graph 부분도 사용해보았는데, 왜인지 제가 구현한 모델의 모습과 정확하게 일치하지는 않아 아쉬웠는데, 전반적으로 괜찮은 툴이라는 생각이 들었습니다.