
Vincent van Gogh - The Starry Night

Maplestory - Arcana, The Mysterious Forest

Maplestory - Arcana, The Mysterious Forest with style from Vincent van Gogh - The Starry Night
휴먼스케이프는 입사 이후 사내에서 사용할 여러 툴 (ex. Slack, Dooray, Pigma, Sentry etc.) 들에 사용될 프로필 일러스트를 디자이너 분께서 직접 그려주십니다. 제가 입사할 때까지만 해도 사내 인력 규모가 큰 편은 아니었고, 입사가 자주 일어나지 않아서 프로필 일러스트 제작에 대한 비교적 부담이 덜했던 것 같은데요... (맞겠죠?!)
최근의 휴먼스케이프는 공격적인 채용과 마미톡과의 합병으로 신규 인원이 대폭 증가했습니다. 이에 따라 프로필 일러스트를 수작업으로 그리는 것에 대한 부담이 커지게 되었는데요... 
많은 분들이 이 상황을 타개할 방법에 대한 의견을 주셨고, 최종적으로는 현재 스타일의 프로필 일러스트를 만드는 방향으로 진행이 되었는데 해당 논의에서 AI 에 관한 내용도 빠지지 않고 등장했습니다. 사실 AI 를 이용해서 Real Image 를 디자이너 분의 그림체로 변경한다- 는 내용의 고민은 제가 휴먼스케이프에 입사하고 AI 를 접목할만하면서도 회사에 유의미한 프로젝트를 찾을 때 빠짐없이 나오는 내용이었습니다. 다만, 당시의 저는 pix2pix, CycleGAN 등의 conditional GAN 류의 친구들에 빠져있을 때라서 방대한 데이터도 없고, 있더라도 원본 Real Image 를 수집해야 하는 이슈가 있는 (남에게 내 사진을...?!) 해당 프로젝트에 대한 의욕이 많이 없었습니다.
시간이 흘러 2021년 11월말, 저는 cs231n 강의를 보면서 프로젝트를 다시 떠올리게 됩니다. 개인적으로 cs231n 의 12번째 강의가 Gradient Ascent 를 비롯해 신선한 요소가 많았다고 생각하는데, 프로젝트를 다시금 떠올리게 했던 Neural Style Transfer 라는 친구도 해당 강의에서 등장한 친구였습니다.
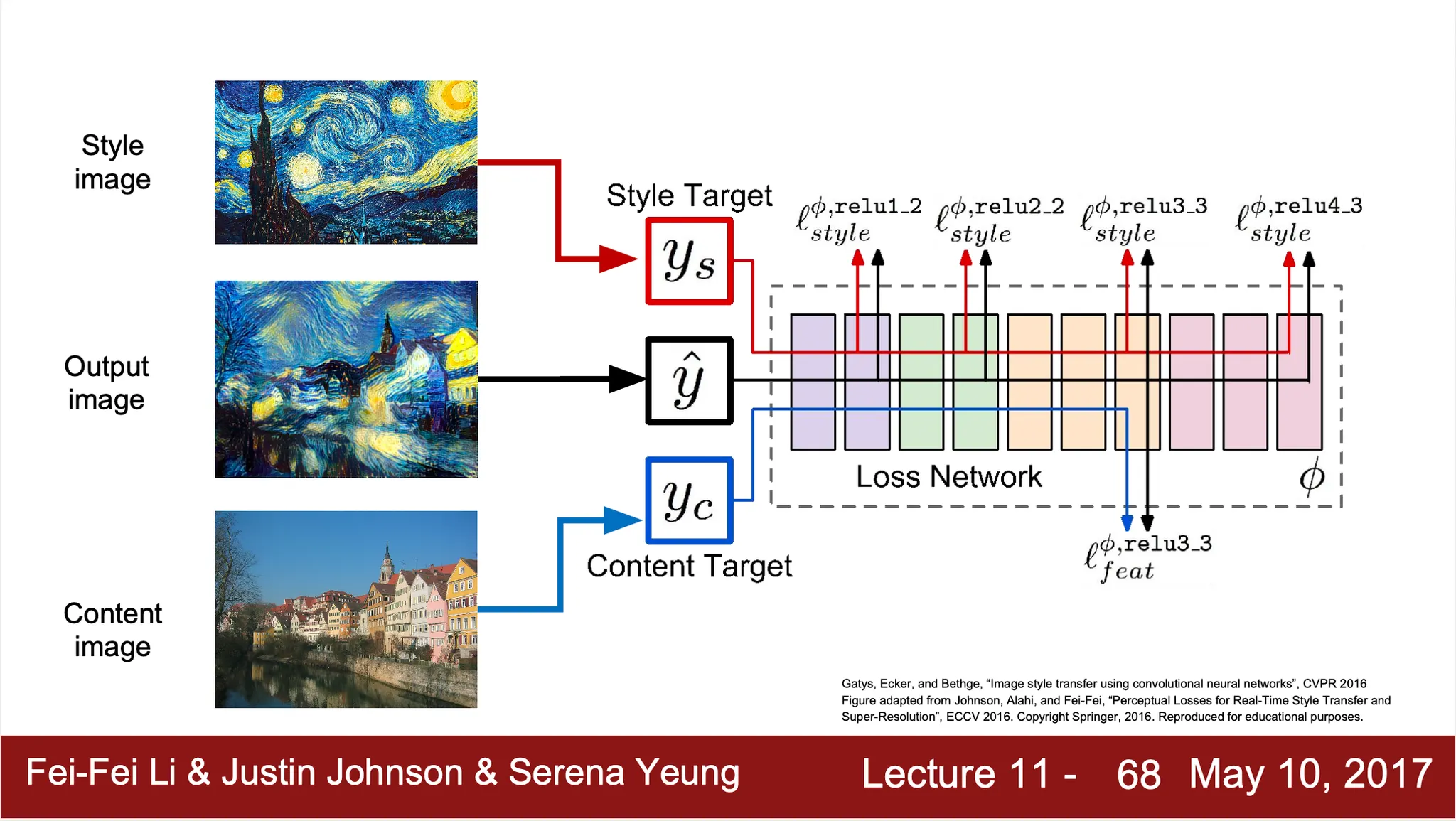
Nerual Style Transfer
Nerual Style Transfer 가 특히 기존의 다른 네트워크들과 비교해 신선하게 다가왔던 이유는 두 가지입니다.
1.
네트워크를 학습하는 것이 아니라 Input Image 를 학습
그렇기 때문에, inference 가 따로 없고 학습 과정 자체가 이미지 생성 프로세스!
2.
Ouput 과 label 을 기반으로 loss 를 정의하지 않고 base 로 주어지는 style image 및 content image 와 input image 의 feature expression 을 이용해서 loss 를 정의
위 두 가지 특성이면, 기존에 제가 고민했던 방대한 데이터의 필요성도 없고 원본 데이터를 수집해야 하는 이슈도 사라집니다. 주어진 style image 와 content image 만 있다면, content image 로부터 조금씩 이미지를 변형해가면서 styled content image 를 생성할 수 있는 것입니다. 때문에 저는 다시 어느정도 해당 프로젝트에 관심이 생겼고, 잘 되지 않더라도 시도해봄직하다고 판단하게 됩니다.
서론이 길었는데, 본 포스트에서는 제가 Neural Style Transfer 를 구현한 방법에 대해서 공유드리려고 합니다. 한 가지 언급드리자면, Neural Style Transfer 에 대한 이론적인 내용은 본 포스트에서 생략하려고 합니다. 관심 있으신 분들은 위에 제가 걸어둔 cs231n 강의 요약본을 살펴보아 주세요!
Neural Style Transfer 구현에 관련한 레퍼런스는 PyTorch document 에도 명시되어 있는데, 그냥 똑같이 구현하는 것만큼 재미없는 일도 없기에 저는 기존에 눈여겨보던 PyTorch-Lightning 라이브러리를 활용해 DL 코드를 간단하게 작성하는 방법을 곁들여 사용해보았습니다.
PyTorch-Lightning, 무엇일까?
PyTorch-Lightning 은 복잡한 boilerplating 과정 없이 연구자가 간단하게 DL 코드를 작성가능하게 제공하는 프레임워크입니다. 기존에 PyTorch 를 사용하시던 분들은 DL 학습 코드를 작성할 때 "아- 이거 어차피 다른 프로젝트여도 필요한 친구들이랑 학습 형태는 다 비슷비슷한데 정형화시키고 싶다" 라는 생각을 하셨을 것이라 믿습니다. (혹시, 저만 그랬나요..? )
) 위 레포지토리는, 이전에 제가 골연령 판독 프로젝트를 진행했을 당시 구현한 코드입니다. 모델을 선언하는 부분, 데이터를 관리하는 부분(DataLoader), hyperparameter 를 설정하는 부분(optimizer, loss, etc.), 학습하는 부분 등 적어야 할 부분이 한 두 곳이 아닌데, 이들은 제 프로젝트가 골연령 판독기라서 존재한다기보다는 기본적으로 DL 코드를 작성할 때 필수적으로 들어가는 친구들입니다. PyTorch-Lightning 은 이러한 코드들을 추상화하여 제공함으로써 코드를 간결하게 만들어줍니다.

PyTorch-Lightning 에서 설명하기로는,
1.
프로젝트마다 세팅해주어야 하는 공통적이고 많은 boilerplate 부분을 제거하면서도 순수 PyTorch 만으로 작성했기 때문에 PyTorch 와 함께 사용할 때 이슈 없이 유연하게 사용할 수 있고,
2.
엔지니어링과 리서치를 분리하여 가독성을 챙겼으며,
3.
재생산성이 뛰어나고,
4.
학습 과정을 비롯한 대부분의 엔지니어링을 자동화하여 오류로부터 상대적으로 자유로우며,
5.
하드웨어 확장성이 뛰어나다-
고 이야기하고 있습니다.
PyTorch-Lightning 은 위 5 가지를 크게 두 가지 형태의 코드 추상화를 통해서 달성합니다. 지금부터는 각각에 대해서 제가 작성한 코드의 예시와 함께 설명을 드리려고 합니다.
LightningModule: 학습의 추상화
LightningModule 은 Pytorch-Lighning 에서 학습의 추상화를 담당합니다. 여기서 학습은 기존에 작성하던 학습과정을 비롯해서 모델, optimizer 등을 포함하는 내용입니다.
import pytorch_lightning as pl
class StyleTransferNetwork(pl.LightningModule):
def __init__(self, ...):
super().__init__()
...
# Model initialize
def forward(self, x):
...
# Model 의 forward propagation 정의
def configure_optimizers(self):
...
# Optimizer 및 LR Scheduler 반환
def training_step(self, batch, batch_idx):
...
# Loss 반환
Python
복사
가장 기본적인 형태의 LightningModule 활용은 위와 같습니다.
먼저 __init__ 에서는 model 을 initialize 하고 다른 method 에서 사용할 class variable 들을 초기화합니다. 이는 기존의 PyTorch 에서 models.py 에 주로 존재했던 부분이라고 보시면 됩니다. 제가 작성한 코드에서는 아래와 같이 되어 있습니다.
def __init__(self, content_image, style_image, input_image, style_weight, content_weight, image_size):
super().__init__()
content_image = image_loader(content_image, image_size)
style_image = image_loader(style_image, image_size)
input_image = image_loader(input_image, image_size)
assert content_image.size() == style_image.size()
content_layers = ['conv_4']
style_layers = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']
model = nn.Sequential(Normalization())
content_losses = []
style_losses = []
VGGNet = models.vgg19(pretrained=True).features.eval()
index = 0
for layer in VGGNet.children():
if isinstance(layer, nn.Conv2d):
index += 1
name = f'conv_{index}'
elif isinstance(layer, nn.ReLU):
name = f'relu_{index}'
layer = nn.ReLU(inplace=False)
elif isinstance(layer, nn.MaxPool2d):
name = f'pool_{index}'
elif isinstance(layer, nn.BatchNorm2d):
name = f'bn_{index}'
else:
raise RuntimeError(f'Unrecognized layer: {layer.__class__.__name__}')
model.add_module(name, layer)
if name in content_layers:
target = model(content_image).detach()
content_loss = ContentLoss(target)
model.add_module(f'content_loss_{index}', content_loss)
content_losses.append(content_loss)
if name in style_layers:
target_feature = model(style_image).detach()
style_loss = StyleLoss(target_feature)
model.add_module(f'style_loss_{index}', style_loss)
style_losses.append(style_loss)
for i in range(len(model) - 1, -1, -1):
if isinstance(model[i], ContentLoss) or isinstance(model[i], StyleLoss):
break
model = model[: (i + 1)]
self.input_image = input_image
self.model = model
self.content_losses = content_losses
self.style_losses = style_losses
self.style_weight = style_weight
self.content_weight = content_weight
Python
복사
약간 이상함을 느끼신 분들이 있으실 것 같은데요...!
기존의 코드와 같이 nn.Module 들을 이어붙여서 모델을 정의한 것이 아니라, Pretrained Model 을 불러와서 해당 model 을 modify 해가면서 모델을 구성했기 때문입니다. 저는 Neural Style Transfer 의 목적에 맞게 미리 feature extraction 부분이 학습된 네트워크를 불러서 사용했는데, 아래와 같이 기존에 사용하시던 방식처럼 정의해도 무방합니다.
def __init__(self):
super().__init__()
self.l1 = nn.Linear(28 * 28, 10)
Python
복사
저 같은 경우에는 loss 를 뽑아낼 activation 을 산출하는 layer 의 바로 뒷단에다가 새로운 ContentLoss, StyleLoss 라는 module 을 추가하여 loss 를 계산해내도록 했습니다. 이들은 input 그대로 output 을 내는 module 이지만, forward propagation 을 진행할 시에 class variable 에 저희가 원하는 loss 를 저장하는 역할을 합니다.
from torch import nn
MSE = nn.MSELoss()
class ContentLoss(nn.Module):
def __init__(self, target):
super(ContentLoss, self).__init__()
self.target = target.detach()
def forward(self, input):
self.loss = MSE(input, self.target)
return input
Python
복사
이렇게 저장한 loss 는 이후에 다시 꺼내서 최종적인 loss 를 정의하고 backpropagation 을 하는데 사용됩니다.
다음으로, forward 에서는 model 의 forward propagation 을 정의합니다. 이 또한 기존의 코드와 크게 다를 바가 없습니다. 저는 아래와 같이 작성했습니다.
def forward(self, x):
x = self.model(x)
return x
Python
복사
다음으로, configure_optimizers 에서는 학습에 사용할 optimizer 를 정의합니다. 이 때, learning rate 나 scheduler 도 함께 정의해 줄 수 있습니다. 기존에는 학습 코드에 optimizer 의 선언 및 step 과정이 있었다면, Pytorch-Lightining 은 optimizer 를 반환해주기만 하면, 알아서 설정한 변수를 구해낸 gradient 값에 맞게update 를 해줍니다.
def configure_optimizers(self):
optimizer = torch.optim.LBFGS([self.input_image])
return {
"optimizer": optimizer,
"lr_scheduler": {"scheduler": LambdaLR(optimizer, lr_lambda=lambda epoch: 0.9 ** epoch)},
}
Python
복사
저 같은 경우에는 model 을 학습하는 것이 아닌, input image 를 학습하는 것이기 때문에 optimizer 의 첫 번째 항으로 input image tensor 를 넣은 것을 보실 수 있습니다. 또한 학습을 용이 learning rate scheduler 도 함께 지정해주었습니다.
마지막으로, training_step 에서는, 하나의 batch 에 대해서 학습에 사용할 loss 를 정의합니다. Pytorch-Lightning 내의 Train 과 함께 사용하면 해당 메소드에서 반환한 loss 와 back propagation 을 사용해서 자동으로 각 input image 의 pixel tensor 마다의 gradient 값을 계산하고, configura_optimizers 에서 정의한 optimizer 를 사용해 설정한 변수를 update 해줍니다. loss.backward(), optimizer.step() 등 고정적으로 쓰이던 PyTorch 메소드들을 감춰진 영역에서 진행해줍니다.
def training_step(self, batch, batch_idx):
self.input_image.requires_grad_(True)
self.model.requires_grad_(False)
self.model(self.input_image)
with torch.no_grad():
self.input_image.clamp_(0, 1)
style_score = sum([style_loss.loss for style_loss in self.style_losses])
content_score = sum([content_loss.loss for content_loss in self.content_losses])
loss = style_score * self.style_weight + content_score * self.content_weight
return loss
Python
복사
앞서 ContentLoss 와 StyleLoss module 에서 forward propagation 시에 class variable 에 loss 값을 계산해둔다고 이야기 드린 적 있습니다. 여기서 forward propagation 을 진행하고 진행 한 뒤에 각 module 에 남겨져 있는 loss 를 사용해 최종적인 loss 를 정의하고 반환합니다.
이렇게 간단하게 LightningModule 에 대해서 알아보았습니다.
정리하자면, LightningModule 의 도입은 코드의 추상화 레벨을 높여 학습 과정에서 반복적으로 나타날 수 있는 코드를 유저 단에서 사용하지 않아도 되도록 제거하여 하나의 코드 스타일로 자리잡게 했다- 고 보시면 됩니다. 개인적으로는 batch data 를 사용한 learning 에서 epoch 루프 부분에 필요한 코드들을 관심사에 맞게 잘 분리하여 간결하게 가져갈 수 있어서 좋았던 것 같습니다.
Trainer: 학습환경의 추상화
Trainer 는 Pytorch-Lighning 에서 학습환경의 추상화를 담당합니다. 여기서 학습환경은 precision, 하드웨어, epoch 수 등의 구성 요소를 의미합니다.
import pytorch_lightning as pl
import argparse
import pathlib
from style_transfer import StyleTransferNetwork
def train(args):
STNet = StyleTransferNetwork(**vars(args))
trainer = pl.Trainer(max_steps=300, min_steps=300)
trainer.fit(STNet, train_dataloaders=None)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--content_image', type=pathlib.Path, required=True)
parser.add_argument('--style_image', type=pathlib.Path, required=True)
parser.add_argument('--input_image', type=pathlib.Path, required=True)
parser.add_argument('--style_weight', type=int, default=1000000, required=False)
parser.add_argument('--content_weight', type=int, default=1, required=False)
parser.add_argument('--image_size', type=int, default=1, required=False)
args = parser.parse_args()
train(args)
Python
복사
위는 제가 train.py 파일을 구현한 내용입니다.
Trainer 라는 인스턴스를 저희가 설정한 학습환경을 통해서 정의하고, LightningModule 인스턴스와 DataLoader 를 함께 fit() 함수에 인자로 전달하게 되면 Trainer 가 뒷단에서 해당 모델에 정의된 메소드들을 이용해 저희가 기존에 PyTorch 코드로 하던 학습을 설정한 학습환경대로 실행시켜 줍니다.
정리하자면, Trainer 는 학습환경 구성에 주체성을 가지고 있으며 앞서 설명드린 LightningModule 의 메소드들을 학습의 순서대로 실행시켜 학습(테스트 도 가능합니다.) 이 가능하도록 뒷단에서 로직을 실행시키는 친구라고 보시면 됩니다. 개인적으로는 epoch 변경, device 지정을 일일히 학습 코드에서 특정 위치를 찾아가서 적어주지 않아도 되서 좋았던 것 같습니다.
학습해보기
지금까지 PyTroch-Lightning 의 두 가지 핵심 요소 LightningModule 과 Trainer 에 대해서 알아보았습니다. 실제로 저는 Neural Style Transfer 학습을 진행해보았는데, 앞서 공개해드린 제가 구현한 train.py 의 형태에 따라 다음과 같은 명령어로 모델을 정의하는 요소들을 지정해준 뒤에 학습을 진행할 수 있었습니다.
python train.py --content_image ./content_image.jpg --style_image ./style_image2.jpg --input_image ./content_image.jpg --image_size 512 --style_weight 1000000 --content_weight 1
Shell
복사
그 결과 본 포스트의 제일 처음에 보여드린 이미지를 얻을 수 있었습니다. 포스트에는 담지 않은, 다소 생략된 부분들이 있어 만약 full code 를 보시고 싶으시다면, 아래에 걸어둔 북마크를 통해서 제 구현을 살펴보아 주시길 바랍니다...!
마무리
이렇게 Pytorch Lightning 을 사용해 Neural Style Transfer 를 구현해보았습니다. Neural Style Transfer 가 생소하거나 Pytorch 가 생소하신 분들에게는 쉽게 다가가기 어려운 설명일 수도 있겠다는 생각이 어느정도 드는 것 같습니다. 혹시나 그러실 분들을 위해 다시 한 번 정리하자면, PyTorch Lightning 은 순수 PyTorch 를 통한 DL 코드 구현의 추상화 레벨을 높여 리서치 하는 사람들의 관심사를 엔지니어링 부분으로부터 분리하여 간결하고 깔끔한 코드 스타일을 구축해냈다고 볼 수 있습니다. 개인적으로 저는 공통되는 학습 루프를 직접 작성하지 않아도 되며 메소드마다의 관심사가 정확히 분리되어 가독성 측면에서 굉장히 마음에 들었습니다. 본 포스트에서는 DataLoader 를 따로 다루지 않았지만 (데이터가 필요 없는 주제였죠... ㅜㅜ) 이 또한 완벽하게 PyTorch 와 호환되는 구현이니 한 번 찾아보시는 것을 추천드립니다.
P.S. 이렇게만 끝내면 서론에서 말한 프로젝트는 뭐가 돼? 하실 분들을 위해 간단하게 진행해본 Style Transfer 결과입니다. 생각보다 원하는 느낌이 나오지는 않아서 아쉽긴 한 것 같아요. 기회가 되면 디벨롭 혹은 다른 방향성으로 다시 한 번 진행해보지 않을까- 생각중입니다!

(G)I-dle - 전소연

작성자의 휴먼스케이프 프로필 일러스트

Neural Style Transfer 를 거친 (G)I-dle - 전소연