본 포스트에서는 다중 카테고리에 대해서 단일 이미지로부터 3D Shape 를 재구성해내는 단일 모델을 설계한 논문에 대해서 소개드리려고 합니다.
“Pre-train, Self-train, Distill: A simple recipe for Supersizing 3D Reconstruction”

Objective
Semantic Recognition, 이미지 속에서 물체를 판별하는 task 를 성공으로 이끌 수 있었던 주요한 원인은 풍부한 학습 데이터셋이 supervision 으로 활용되었기 때문이라고 보아도 과언이 아닙니다. 수천개의 카테고리를 가진 거대한 데이터셋은 Classification, Detection, Segmentation 등 다양한 task 에 활용될 수 있었고 2D 비전 영역의 발전을 가져왔습니다.
하지만, 2D 공간과는 다르게 3D 공간에서는 일반적인 (1000+ 개의 카테고리를 가지는) 물체들의 supervision 을 얻기는 굉장히 어렵습니다. 가장 크다고 알려진 3D 데이터셋 또한 수십개에 남짓한 카테고리를 가질 뿐이며 이 또한 Real-World 의 물체들의 복잡도를 가지고 있다고 보기엔 어렵습니다.

SIngle Self-Supervised 3D Shape Reconstruction above Various Categories
위의 3D supervision 의 문제점 때문에 시각적 공간을 유의미하게 해석하는 방법론이 점점 발전하고 있지만, 단일 뷰의 이미지만으로 3D Shape 를 재구성하는 방법론의 SOTA 조차도 시각적 공간을 구성하는 물체들의 극히 일부만을 다룰 수 있다는 문제가 있습니다.
이러한 문제점을 해결하기 위해 선행연구들은 3D 에 비해서 비교적 풍부한 데이터셋을 보유한 2D 이미지와 Foreground Mask 를 supervision 으로 사용하려는 시도를 합니다.

Foreground Mask?

Example of Foreground Mask
Reference: https://support.apple.com/ko-kr/guide/motion/motn176925ff/mac
이미지 내에서 표현하고자 하는 물체의 영역을 지칭해주는 데이터입니다. 물체가 존재하는 영역이 1, 그렇지 않은 영역이 0 으로 구성되어 있습니다. 보통 그냥 Mask 라고도 표현하지만, 배경 영역을 지칭해주는 Background Mask 와 대비하여 사용했다고 보시면 됩니다.
하지만, 이러한 시도들은 구성하고자 하는 기본적인 형태 (Primitive Shape) 와 같은 3D prior 를 사용하지 않았기 때문에 추가적인 constraint 나 regularization 을 사용해야만 했고 대게 이러한 설계는 하나의 카테고리에서 적용되었던 모델이 다른 카테고리에서 적용될 수 없는, Generalization Problem 을 야기했습니다.
논문에서는 이렇게 2D supervision 을 사용하는 기존 접근의 Generalization Problem 을 해결하기 위해 카테고리가 제한된 3D supervision 으로 학습된 pre-trained 네트워크를 활용하여 fine-tuning 하는 방법론을 제안하게 됩니다.
Approach
논문의 목적은 2D supervision 을 통해 부족한 3D supervision 을 해결해보려는 선행연구의 시도에서 나타났던 Generalization Problem 을 해결하는 것입니다. 즉, 기존에 단일 이미지로부터 3D Shape 를 추론해내는 하나의 모델이 하나의 카테고리만을 추론할 수 있었던 것에서 벗어나 수백개의 카테고리 내에 속하는 단일 이미지들 모두로부터 3D Shape 를 추론해낼 수 있는 단일 모델을 구현하는 것입니다.
이를 위해서 논문에서는 기존의 선행연구들이 2D supervision 에만 의존했던 것과는 다르게 적은 카테고리이지만 존재하는 Sythetic 3D Dataset 을 이용해 보완하려는 시도를 합니다. 그들이 구현한 Multi-Stage Training Approach 는 다음과 같습니다.
1.
Synthetic 3D Dataset 을 활용해 Image-Conditioned Implicit Reconstruction 을 수행하는 네트워크를 학습합니다.
2.
1 번에서 학습한 네트워크를 카테고리 별로 구성되어 있는 in-the-wild 2D 이미지들로 fine-tuning 합니다.
3.
2 번에서 학습된 카테고리별 네트워크의 학습 정보를 distillation 을 통해 하나의 통합된 네트워크로 이전합니다.
아래에서는 논문에서 구성한 방법론의 큰 틀에 대한 이해를 돕기 위해 설계의 전반적인 내용에 대해서 간략하게 논문에서 언급한 수준으로나마 설명할 예정입니다.
Image-conditioned Implicit Reconstruction
논문의 네트워크는 기본적으로 이미지를 입력으로 하여 latent vector 를 산출하는 encoder 와 latent vector 와 특정한 xyz 좌표 를 입력으로 하여 해당 좌표의 volume density 와 color 을 산출하는 decoder 로 구성되어 있습니다.
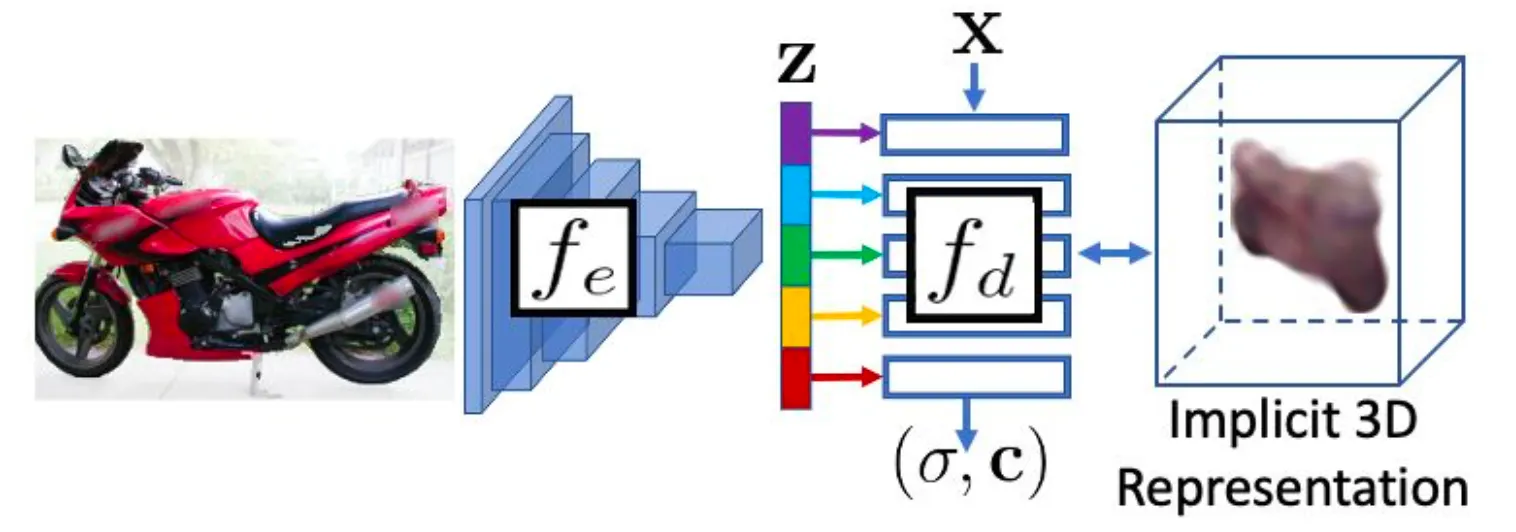
Network Architecture
위 그림은 논문의 네트워크를 도식화한 것입니다. 최종적으로 산출해낸 volume density 와 color 는 NeRF 에 등장했던 formulation 과 동일하게 color estimation 을 사용한 volume rendering 을 통해 특정한 query view point (카메라 시점) 에서의 이미지를 생성해낼 수 있습니다.
Volume Rendering
앞서 논문에서 volume density 와 color 를 사용해 3D Shape 를 implicit 하게 표현하고 있음을 확인했습니다. 이렇게 표현한 implicit 하게 표현한 3D Shape 를 라 칭했을 때, 논문에서는 view point 에서 바라보았을 때의 이미지 속 특정 pixel 위치 의 값을 아래와 같이 표기합니다.
더불어, mask 를 rendering 하는 과정을 으로 (물체가 있는 곳을 1로 이외의 영역을 0으로 표현하는 렌더링), color 를 rendering 하는 과정을 로 (색상까지 입혀진 렌더링) 구별해서 표현합니다.
Method
앞서는 논문에서 제시한 방법론의 전체적인 배경 및 맥락에 대해서 설명드렸습니다. Method 세션에서는 Approach 에서 간략하게 세분화한 논문의 세분화된 방법론 각각의 과정을 구체적으로 설명할 예정입니다.
Pre-Training from Synthetic 3D data
논문의 방법론, 그 첫 번째 과정은 Image-Conditioned Implicit Reconstruction 입니다. 논문에서는 Synthetic 3D Dataset 을 활용하여 multiview 에서 획득한 이미지들을 입력으로 하여 implicit 한 3D Shape 을 재구성하는 형태로 네트워크를 학습합니다.
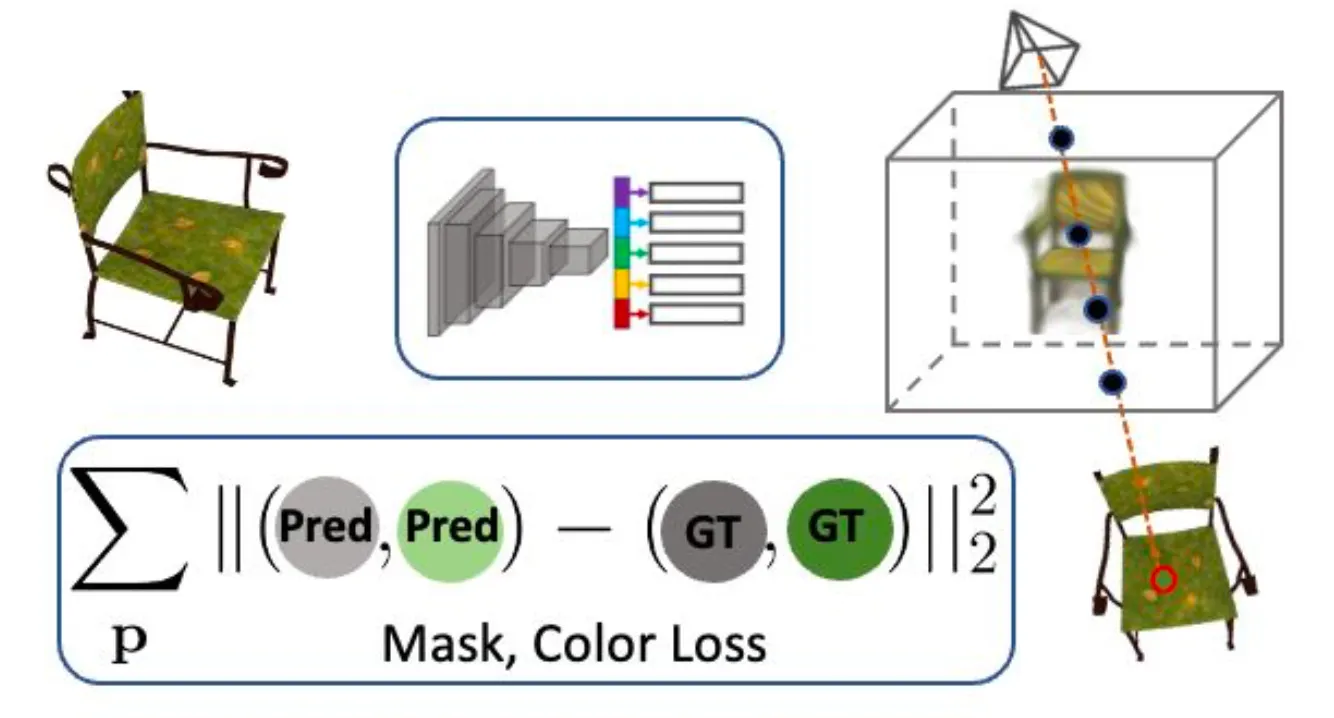
Novel-View Rendering Loss
입력으로는 이미지 가 들어가게 되고, encoder 와 decoder 를 통과하여 얻어낸 3D Shape 의 Implicit 한 표현은 로 표현될 수 있습니다. 이렇게 구성해낸 3D Representation 이 가지고 있는 supervision 인 ground truth 와 일치하게 유도하기 위해서 논문에서는 다음과 같은 Reconstruction Error 기반의 loss 를 설계합니다.
이 때 는 3D 물체의 형태를 잘 나타낼 수 있는 camera viewpoint 이며, 는 해당 viewpoint 에서 ground truth 인 Sythetic 3D Shape 를 렌더링한 이미지입니다. 정성적으로 설명하자면 매우 간단하게 네트워크를 통해서 재구성한 3D 물체가 정해진 novel-view 에서 바라보았을 때 ground truth 와 얼마나 유사한지를 픽셀별로 L2 Norm 을 구했다고 보시면 됩니다. 논문에서 구체적으로 명시되어 있지는 않지만 iteration 마다 이 novel-view 를 다르게 설정하여 multi-view 관점에서의 학습을 진행하는 것으로 보입니다.
이 과정을 통해서 네트워크의 encoder 는 적어도 준비된 카테고리 내에서는 이미지로부터 3D Shape 을 재구성할 수 있는 주요 특성들을 추출할 수 있는 능력을 얻게 되고, decoder 는 그렇게 추출한 특성들로부터 3D Shape 를 표현하는 Implicit Function 의 역할을 할 수 있게 됩니다. 이 전체 과정은 카테고리 내에서 일반화된 네트워크를 Pre-Training 하는 과정이라고 볼 수 있습니다.
Self-Training from Image Collections
앞서는 논문의 방법론의 첫 단계인, 3D Synthetic Dataset 을 사용해 Image-Conditioned Implicit Reconstruction Network 를 pre-train 하는 과정을 알아보았습니다. 논문에서 궁극적으로 원하는 것은 일반적인 카테고리에 대해서 3D Shape 를 재구성할 수 있는 네트워크를 구성하는 것인데, 앞서도 살펴보았지만 일반적인 카테고리를 지원하는 3D Supervision 이 없기 때문에 multi-view 로 학습을 진행할 수 없고, 첫 단계만 사용해서는 논문의 목적을 달성할 수 없습니다. 이에 논문에서는 3D 에 비해서 비교적 풍부한 2D 이미지를 활용하여 구성한 네트워크에서 렌더링한 이미지와 입력 이미지간의 일치를 유도할 수 있는 방법론을 제안합니다.
Volume Rendering with Multi-hypothesis Cameras
3D supervision 에서 특정한 viewpoint 에서 렌더링한 이미지와 네트워크가 생성해낸 3D Shape 의 해당 viewpoint 에서 렌더링한 이미지를 비교했던 첫 단계와는 다르게, 입력으로 사용하는 이미지를 2D supervision 으로 하는 경우에는 해당 이미지가 어느 viewpoint 에서 렌더링된 이미지와 유사하게 유도할 것인지를 확정지을 수 없습니다.
논문에서는 비슷한 상황에서 선행연구들이 사용한 방법은 다양한 viewpoint 를 후보로 두어 해당 viewpoint 들에서 렌더링한 결과와 유사하도록 유도하는 loss 를 차용합니다.
이 때 로 나타내어지는 multi-hyphothesis viewpoint 이며 들이 각각의 viewpoint 를, 들이 해당 viewpoint 가 이미지와 짝지어질 적합한 렌더링 viewpoint 확률입니다. 기존의 Reconstruction Error 기반의 loss 에서 viewpoint 의 probability 에 따른 weighted sum 항목만 추가된 것을 확인하실 수 있습니다. 여기서 사용된 weight 가 probability 라는 점에서 위식은 Expected Value of Reconstruction Error Loss 라고 보시면 됩니다.
Finetuning 3D Inference in-the-wild
앞선 multi-hypothesis 를 사용한 Volume Rendering 에서 viewpoint 의 후보들이 학습에 걸쳐서 고정적인지에 대한 물음이 생길 수 있습니다. 논문에서는 multi-hypothesis 를 사용한 선행연구를 따라서 학습을 크게 두 단계로 나누게 됩니다.
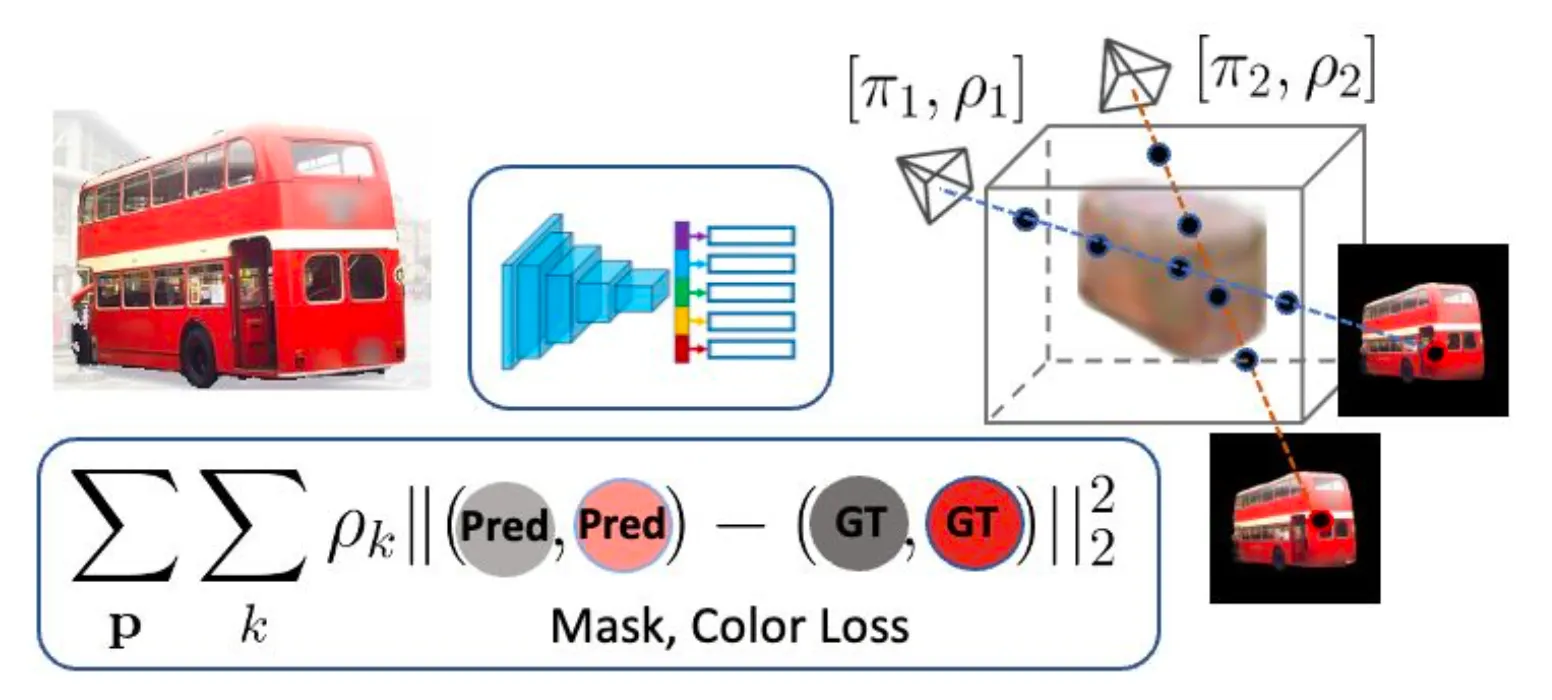
Single-View Rendering Loss with Multi-Hypothesis
첫 단계에서 이 로 명시된 multi-hypothesis 를 최적화하여 초기 viewpoint 의 후보군을 설정한 뒤에, 두 번째 단계에서 multi-hypothesis 의 최적화와 네트워크의 최적화를 동시에 진행하게 됩니다. 이러한 최적화 과정은 준비된 2D supervision 이미지와 해당 이미지의 마스크의 집합인 에 대해서 아래의 식을 따릅니다.
여기서 은 위에서 언급한 Expected Value of Reconstruction Error Loss 항목입니다. 단순하게 해석하면 모든 준비한 이미지에 대해서 multi-hypothesis 를 사용한 loss 를 더한 값을 최소화하는 방향으로 최적화를 진행하는 것이며, 정성적으로 보면 Synthetic 3D dataset 을 통해 어느정도 의미 있는 형태가 나올 것을 기대한 초기 3D 형태에서 이미지와 매칭될만한 viewpoint 들의 후보군을 먼저 러프하게 학습한 뒤에 3D 형태와 viewpoint 들의 후보군을 같이 조금씩 변경해나가면서 이미지가 3D Shape 에 매칭되도록 유도했다- 라고 보시면 됩니다. 더불어, 이 전체 과정은 multi-hypothesis 가 올바르다는 가정 하에 loss 를 계산하고 multi-hypothesis 및 네트워크를 변경해나간다는 관점에서 Self-Training 과정으로 볼 수 있습니다.
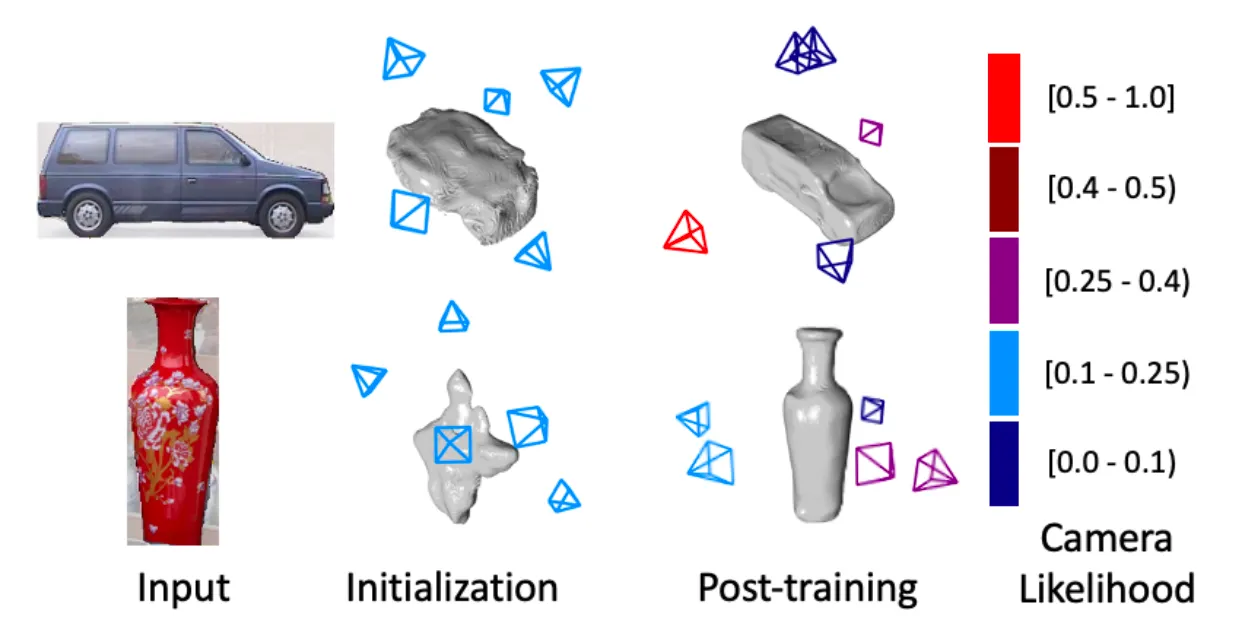
Shape and Camera Optimization in Self-Training
참고로, 기존의 연구와 다른 점은 초기 viewpoint 의 후보군 설정에 있어서 template 3D Shape 를 활용하지 않았다는 점입니다. 이러한 논문의 설계 때문에 3D supervision 이 없는 다양한 물체 카테고리에 대해서 동작하는 단일 네트워크를 구현해낼 수 있었던 것입니다.
Multi-category Distillation
앞서 설명드린 논문의 두 번째 단계인, Self-Training 은 카테고리별 이미지들을 활용하여 하나의 네트워크를 fine-tuning 하는 과정이기 때문에 최종적으로 학습된 네트워크는 Self-Training 과정에서 사용된 카테고리 내에서만 동작합니다. 논문에서 궁극적으로 원하는 것은 단일 네트워크가 일반적인 카테고리에 대해서 3D Shape 를 재구성할 수 있는 능력을 가지는 것이기 때문에 두 번째 단계에서 생성해낸 카테고리별 네트워크들의 학습 정보를 다른 네트워크로 지식을 전수하는, distillation 방법론을 차용합니다.
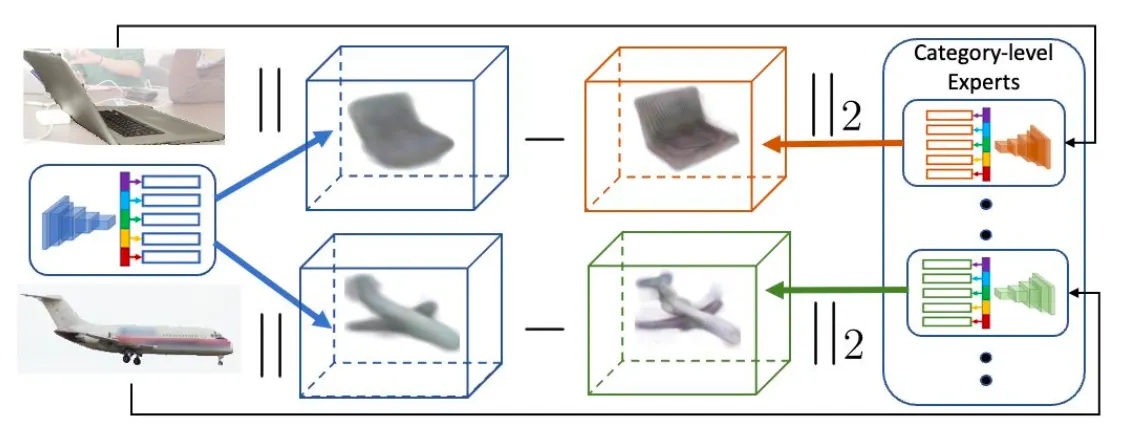
Distillation
위의 그림과 같이 Self-Training 을 통해 각각의 카테고리에 대해서 학습된 Expert (일반적으로 distillation 에서는 사용되는 Teacher 개념입니다.) 가 특정한 이미지에 대해서 산출하는 결과와 학습하고자 하는 최종 단일 네트워크의 결과의 L2 norm 형태로 구성했다고 보시면 됩니다. 이는 카테고리의 집합 와 특정 카테고리 에 대한 이미지들의 집합 에 대해서 아래와 같이 표현됩니다.
이 때 L2 norm 을 계산하게 될 요소로 volume density 와 color 모두가 포함되어 4 차원의 벡터에 대해서 계산됩니다.
Experiments
Datasets
논문에서는 그들의 방법론의 평가하기 위해 Pre-Train 을 위한 Synthetic Dataset 과 Self-Train 을 위한 In-the-wild Image Collections 를 준비합니다.
Synthethic Dataset
논문에서는 Pre-Train 을 위한 Synthetic Dataset 로 3D warehouse 에서 제공하는 CAD 모델로부터 가져온, 51개의 카테고리의 40,000 여장의 3D Shape 를 활용했습니다. 학습 과정에서 필요한 multi-view sampling 을 위해 azimuth 와 elevation 에서 20 장의 이미지를 렌더링 했다고 합니다.
In-the-wild Image Collections
논문에서는 Self-Train 을 위한 In-the-wild Image Collections 로는 다음 다섯 개의 데이터셋을 사용했습니다.
CUB-200-2011
Quadrupeds from ImageNet
PASCAL3D+
Open Images
Co3D
Evaluation Setup
Training 에 대한 detail 한 setup 은 아래의 토글을 눌러 확인해보실 수 있습니다. 관심있는 분들은 한 번 살펴보셔도 좋을 것 같습니다.
Training Details
Baselines
논문에서 평가의 baseline 으로 사용하는 것은 논문의 formulation 과 유사하게 2D 이미지와 그 Foreground Mask 를 이용하여 일반적인 3D Shape 를 구성하는 task 의 SOTA 인 SSMP 모델 입니다. 더불어 논문에서 제시한 각 단계에서의 성능 향상을 보여주기 위해 Synthetic Data 만 사용하여 Pre-Train 을 마친 네트워크 (Synth.) 와 카테고리별로 Self-Train 을 마친 네트워크들 (Cat-spec.) 도 부가적으로 비교하게 됩니다.
Evaluation
논문의 방법론이 최종적으로 산출하는 3D Shape 는 implicit 한 형태입니다. 논문에서는 평가에 용이하게 활용하기 위해서 Mescheder et al. 의 Matchig Cubes 방법론을 차용하여 explicit 한 mesh 형태로 변경하게 됩니다. 이렇게 Mesh 로 변경한 이후 PASCAL3D+ Dataset 에서 제공하는 3D Shape 와의 IoU 를 계산하고, Mesh 에서 Point Cloud 를 sampling 하여 Co3D Dataset 에서 제공하는 Point Cloud 와의 Chamfer Distance 를 계산하여 평가를 진행합니다.
IoU?
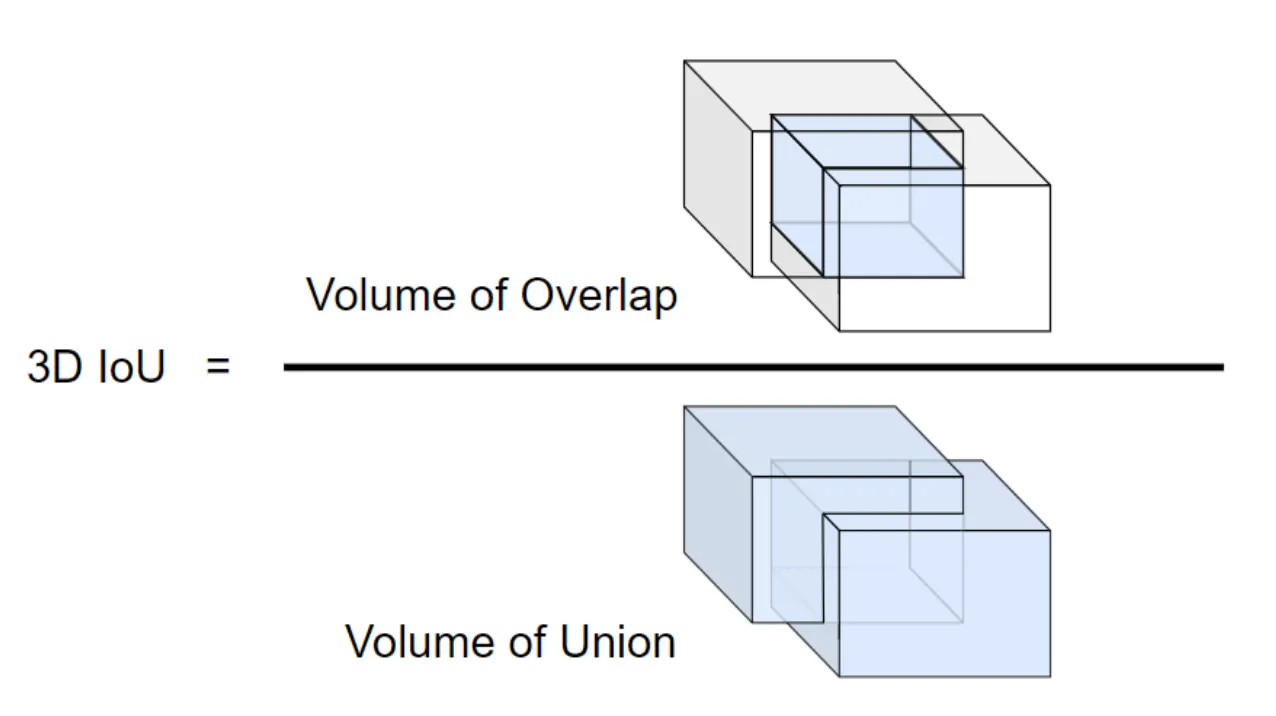
3D IoU
Reference: https://arxiv.org/pdf/2006.14837.pdf
Intersection of Union 의 약자로, 어떤 두 객체의 Union 대비 Intersection 의 비율을 나타내는 것입니다. 3D Mesh 에서의 IoU 는 두 Mesh 가 합쳐서 차지하는 범위 대비 두 Mesh 가 겹쳐서 차지하는 범위의 비율로 보시면 됩니다.
Results
Quantitative Results
앞서 Evaluation 에서 언급했던 것과 같이 논문에서는 PASCAL3D+ Dastaset 으로 진행한 IoU 평가와 Co3D Dataset 으로 진행한 Chamfer Distance 평가를 정량적으로 진행합니다.
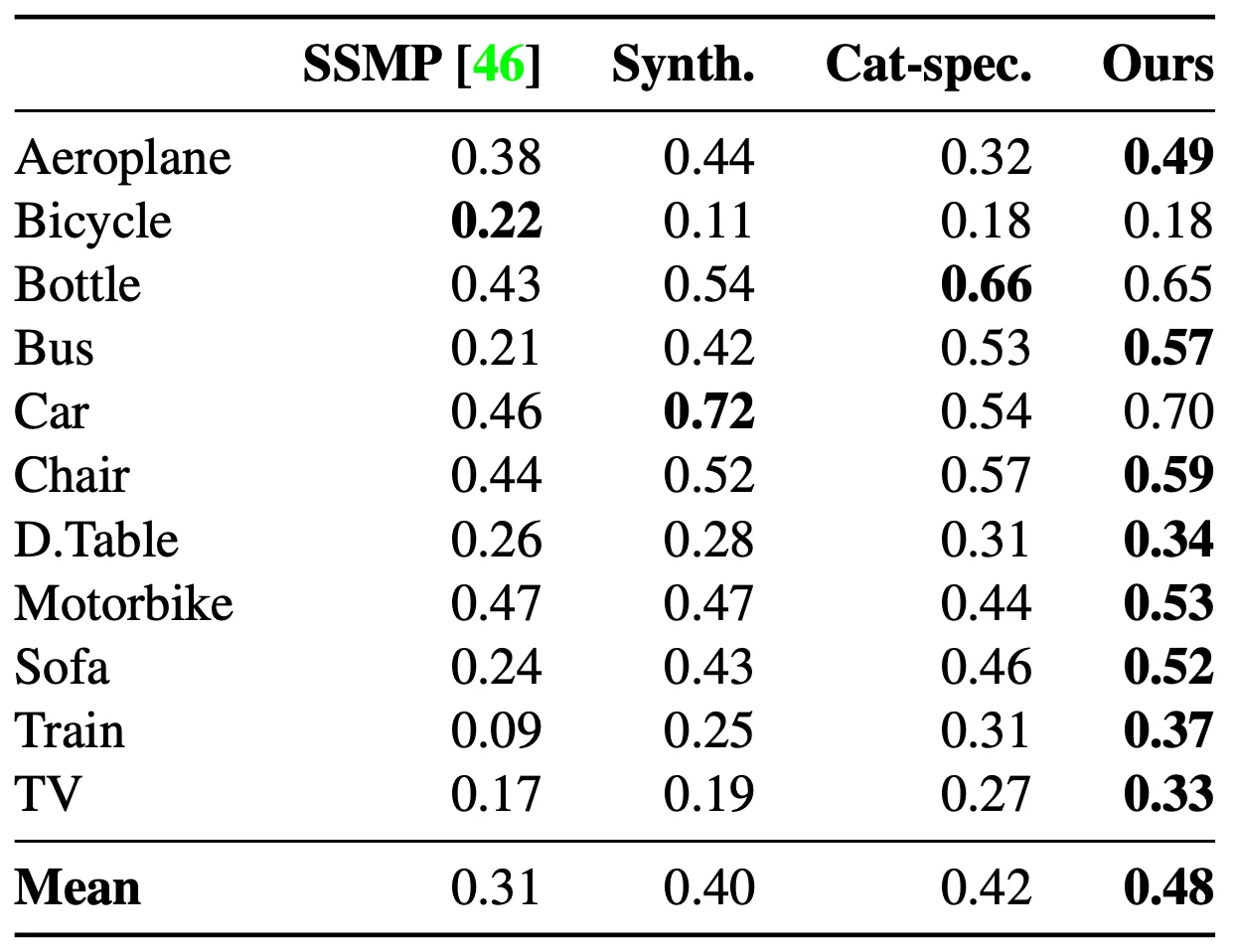
IoU metric Comparison on PASCAL3D+
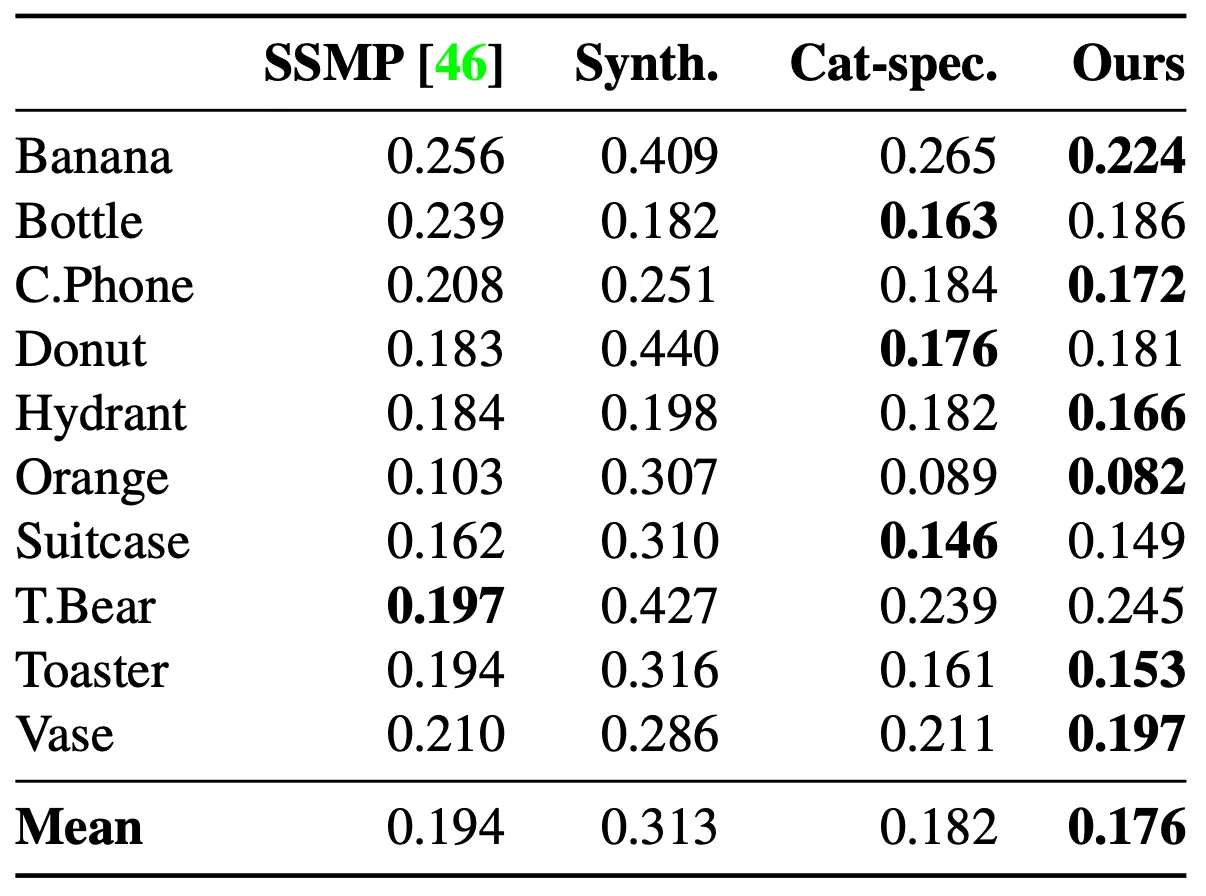
Chamfer Distance Comparison on Co3D
IoU 수치는 높을수록, Chamfer Distance 수치는 낮을수록 좋은 reconstruction 이라고 볼 수 있는데, 확실히 SSMP 에 비해서 개선된 수치를 보여줌을 살펴볼 수 있었습니다. 더불어 몇몇 카테고리에 대해서는 지식을 distillation 해준 expert 보다도 논문의 최종적인 네트워크가 결과가 좋음도 확인할 수 있었습니다.
Qualitative Results
논문에서는 정성적인 결과 분석도 함께 진행합니다. 논문에서는 실생활의 다양한 카테고리의 이미지들을 높은 퀄리티로 reconstruction 해낼 수 있다는 것을 보여주기 위해 아래와 같은 실험 결과를 보여줍니다.

In-the-wild Results
그러면서도, 물체의 가려짐이나 Shape 자체가 어려운 물체의 경우에는 방법론이 종종 실패하는 경우가 있음 또한 보여줍니다.

Failure Modes
Zero-Shot Reconstruction
단일 모델로 Single Image 기반의 3D Shape Reconstruction 을 수행하는 것은 해당 단일 모델이 다중 카테고리에 대해서 공통적으로 학습하고 있는 정보에 기반해서 학습에 사용되지 않은 카테고리에 대해서도 어느정도 동작할 것을 기대할 수 있다는 장점이 있습니다. 논문에서는 그들의 방법론의 이러한 능력을 평가하여 보여줍니다.
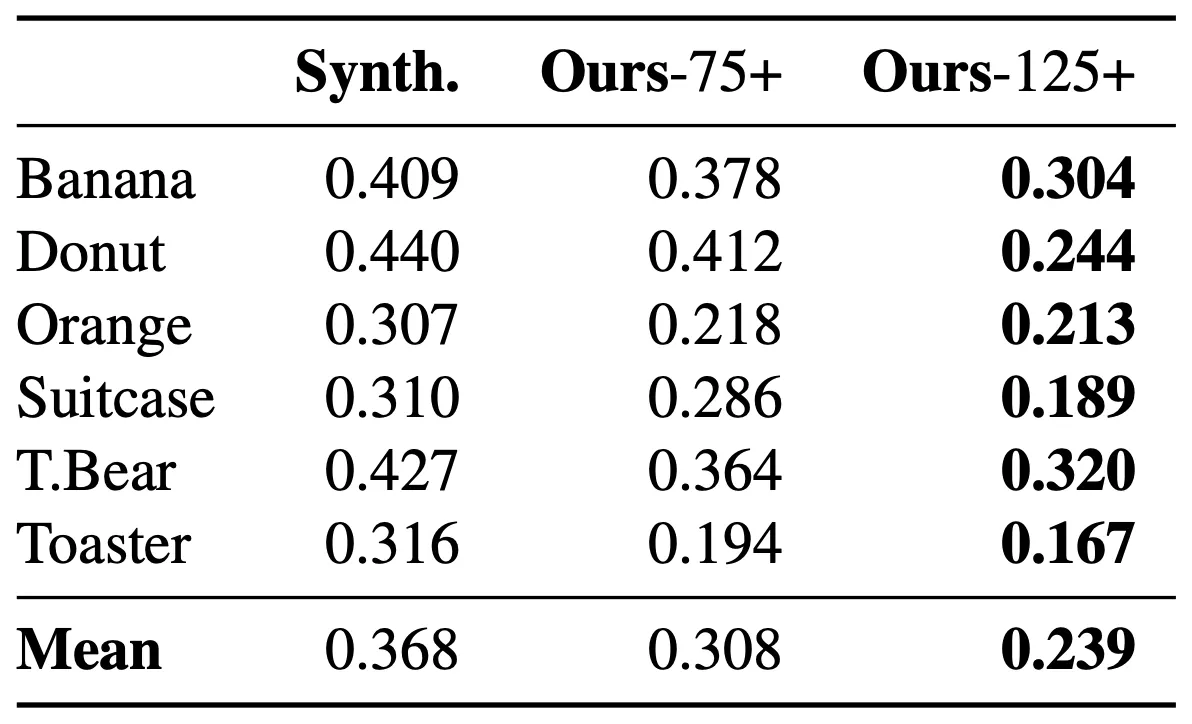
Chamfer Distance Loss of Zero-Shot Reconstruction
논문에서는 크게 75+ 개와 125+ 개의 expert 로부터 distillation 하여 생성된 Ours-75+ 와 Ours-125+ 를 평가에 사용했고, 위의 표는 Co3D Dataset 으로 학습하고 해당 데이터셋에 존재하지 않는 카테고리에 대한 Chamfer Distance Loss 를 나타낸 것입니다. 그 결과 distillation 에서 더 많은 expert 를 사용할 때 해당 데이터셋에 존재하지 않는 카테고리에 대한 reconstuction 성능이 오름을 확인할 수 있었다고 합니다.
Conclusion
이것으로 논문 “Pre-train, Self-train, Distill: A simple recipe for Supersizing 3D Reconstruction” 의 내용을 간단하게 요약해보았습니다.
단일 이미지를 입력으로 하여 3D Shape 를 생성해내는 것이 얼마나 어려운 작업인지 겪어봐서 알지만, 이러한 시도가 있다는 것을 새롭게 알게 되어서 좋았던 것 같습니다. 특히 Self-Training 과정이 잘 되지 않는다고 해도 이상하지 않을 정도로 모호한 아이디어라고 생각이 드는데 어느정도 성능을 뽑아낸 것이 신기했던 것 같습니다.
개인적으로는 설계 자체에 대한 아이디어나 설명 자체는 어렵지 않게 이해할 수 있었지만 해당 아이디어가 왜 잘 동작하는지에 대한 (정량적이진 않더라도) 설명이 없는 점이 상당히 아쉬운 논문이었습니다.