BentoML 이 자동으로 생성해준 API docs (Swagger UI)
때는 2021 년 5월 중순, 평화롭게 개발을 하던 평소같던 하루였습니다.
당시에 저는 제가 재미있게 할만한 프로젝트로 "이미지로부터 메이플스토리 캐릭터의 착용 아이템 추출하기"를 생각했던 적이 있고, 이의 시작으로 "메이플스토리 캐릭터 찾기" 를 진행했던 경험이 있습니다.
저는 해당 프로젝트의 최종적인 형태를 API 요청을 받아 딥러닝 모델을 거쳐 산출한 결과를 돌려주는 것으로 기획했었습니다. 하지만, 기존에 이러한 형태를 구현할 때 딥러닝 모델을 서빙하는 것이 생각보다 어려웠던 경험도 있었습니다.
그렇게 프로젝트가 서서히 제 뇌에서 잊혀지고 있던 와중, 최근에 우연히 정보의 바다를 해매다가 생각보다 재미있어 보이는 친구를 만나게 됩니다.

제가 참여하고 싶어했던 (그렇지만 훈련소 일정 때문에 놓쳤던) 글또를 운영하고 계신 변성윤님께서 작성한 글을 보고 BentoML 이라는 머신러닝 모델 서빙을 위한 라이브러리를 알게되었고, 1. 나온지 별로 되지 않음 + 2. 정말 적은 코드로 프로덕션 서비스가 가능함 이라는 두 포인트에 강한 이끌림을 받아 아- 나중에 한 번 살펴봐야지! 해서 사내에 공유드린 경험이 있습니다.
그렇게 소개만 드린 채 저는 국가의 부름을 받아 산업기능요원 훈련소에 들어가게 되고.... ^^7 (군-바!)
나오고 나서도 약 4개월이라는 시간이 흘러 지금 시점이 되서야 BentoML 을 한 번 살펴보게 되었습니다. 구차한 변명을 대자면, 산업적 기능의 프로젝트에서 1. 데이터 확보와 2. 컴퓨팅 능력이 모델의 성능에 가장 주요한 두 가지 척도라는 생각이 강했었는데 그 두 가지 모두를 가지지 못해서인지 완성도를 챙기지 못할 것만 같은 프로젝트에 흥미가 많이 떨어졌었어요... (머쓱)
서론이 길었는데, 본 포스트에서는 제가 BentoML 을 사용하여 간단하게 API 를 서빙할 수 있는 방법에 대해서 살펴본 내용을 설명드리려고 합니다. 그냥 강아지/고양이 분류기를 서빙하는 것 만큼 재미없는 일도 없기에 저는 이전에 제가 공유드렸던, 메이플스토리 캐릭터 찾기 API 를 서빙하는 것을 목적으로 진행해보았습니다. 
BentoML, 무엇일까?
BentoML 의 핵심적인 아이디어 및 기능은, 데이터 사이언티스트가 그들이 학습해낸 모델을 큰 공수 없이 쉽게 프로덕션 서비스로 배포/통합할 수 있게 하는 것이라고 합니다.

BentoML 에서 Core Concept 로 가져가는 모델 서빙의 과정은 다음과 같습니다.
1.
모델을 학습하는 과정은 기존에 하시던대로 해도 무방합니다. BentoML 은 학습한 모델을 쉽게 서빙을 시켜주는 일만을 합니다.
2.
모델 사용 및 API 구현을 위해서 BentoService 를 정의합니다. 이는 class variable 로 기존의 학습 모델에 접근할 수 있고, class method 로 inference API 를 정의할 수 있는 형태입니다.
3.
2번의 모델 접근을 하기 위해서 학습한 모델을 패키징하여 저장하는 작업이 필요합니다.
4.
저장한 배포할 때 필요한 파일들을 배포합니다.
놀랍게도, 4번이 끝입니다. 위 네 가지만 해주면 학습한 모델을 사용하는 inference API 를 구축할 수 있습니다. 저는 이 4 개의 과정 각각을 예시를 들어서 설명을 드리려고 합니다.
1. 모델 학습하기
모델 학습은 기존과 동일하게 진행하면 됩니다.
Pytorch 를 이용하실 경우의 예시를 들자면, checkpoint 에 torch.save() 로 저장한 pt file 을 사용하여 해당 파일에 저장된 weight 로 초기화된 model instance 를 다시 정의할 수 있으면 됩니다.
간단하게 pretrained 된 모델을 이용해서 모델을 학습하실 경우의 예시를 들어보겠습니다.
import torch.nn as nn
from torchvision import models
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
def initialize_model(num_classes, feature_extract, use_pretrained=True):
base_model = models.efficientnet_b0(pretrained=use_pretrained)
set_parameter_requires_grad(base_model, feature_extract)
num_ftrs = base_model.classifier[1].in_features
base_model.classifier[1] = nn.Linear(num_ftrs, num_classes)
return base_model
Python
복사
위와 같은 형태로 torchvision 에서 제공하는 pretrained model 을 사용해 원하는 학습을 진행하실 수 있습니다. 저 같은 경우에는 다른 프로젝트를 진행해보려고 적어둔 코드를 가져왔는데, efficientnet_b0 인스턴스를 가져와 마지막 classifier 만 원하는 클래스 개수로 바꿔치기하는 형태로 모델을 initialize 했습니다.
이후에, 원하는 학습을 진행하실 경우에 다음과 같은 코드를 작성하실 것입니다.
trained_model = train(model, optimizer, num_epoch, ...)
Python
복사
학습이 완료된 시점이나, 학습 중간중간에 다음과 같은 코드를 삽입하여 chekpoint 모델을 저장할 수 있습니다.
torch.save(trained_model.state_dict(), PATH)
Python
복사
위와 같이 적게 되면, 다음과 같이 불러와서 다시 학습된 모델 인스턴스를 재구성할 수 있게됩니다.
def reinitialize_model(checkpoint):
model_state_dict = torch.load(checkpoint)
model = initialize_model(num_classes, feature_extract, use_pretrained=True)
model.load_state_dict(model_state_dict)
Python
복사
이 경우에는 pretrained 된 모델의 예시를 들었지만, 직접 모델을 구성했더라도 동일한 방법으로 checkpoint 에서의 모델의 weight 를 저장하고 다시 모델 인스턴스를 정의한 뒤 weight 를 덮어씌우는 형태로 학습된 모델 인스턴스를 재구성할 수 있습니다. 번외로, 모델 전체를 저장하는 방법도 있지만, 이 방법은 load 시에 모델을 정의하는데 필요한 파일을 경로형태로 저장하여 load 해주기 때문에 파일의 위치가 바뀌게 되면 유연하게 대응하지 못하는 단점이 있습니다.
이 단계까지 오셨다면, 학습한 모델이 존재하고 해당 모델 인스턴스를 재구성할 수 있으실 것이라 믿습니다!
2. BentoService 정의하기
다음은 거의 유일하게 작성해야 하는 코드이기도 한, BentoService 에 대해서 설명을 드리려고 합니다.
import bentoml
from bentoml.adapters import ImageInput
@bentoml.env(requirements_txt_file="requirements.txt")
@bentoml.artifacts([PytorchModelArtifact("model_mcd")])
class MapleCharacterDetector(bentoml.BentoService):
@bentoml.api(input=ImageInput())
def detect(self, img):
model = self.artifacts.model_mcd
image = Image.fromarray(img)
output_image = detect(model, image, ...)
return output_image
Python
복사
위 코드는 제가 작성한 BentoService 클래스입니다. 저는 메이플스토리 캐릭터를 찾아주는 기능을 하는 API 를 서빙할 것이기 때문에, MapleCharacterDetector 라고 명명해보겠습니다.
앞서 BentoService 클래스는 class variable 로 학습한 모델에 접근할 수 있고, class method 로 inference API 를 정의할 수 있다고 말씀드렸었습니다. 해당 부분을 class 에 데코레이터로 붙은 @bentoml.artifacts 와 class method 인 detect 에서 볼 수 있습니다.
@bentoml.artifacts 데코레이터에는 인자로 해당 class 에서 사용할 다양한 ML 모델을 프레임워크랑 artifact 이름으로 전달해줍니다. 저 같은 경우에는 Pytorch 를 사용해서 구현한 모델이며 그리고 이를 model_mcd 라는 이름으로 패킹하였기 때문에 위와 같이 적어주었습니다.
detect 메소드에는 해당 메소드가 API 로 동작하기 위한 데코레이터인 @bentoml.api 가 붙어있습니다. 해당 데코레이터에는 인자로 input 과 output 의 형태를 받습니다. 이는 Input 및 Ouput 의 형태를 검증 및 자체 변환하는 역할을 합니다. (DRF 의 Serializer 와 유사한 듯 합니다.) 저는 Input 으로 이미지를 받고 싶었기 때문에 ImageInput 을 사용했습니다. 해당 adapter 를 사용하기 위해서는 imageio 라이브러리가 꼭 필요합니다.

detect 메소드 내부를 보면, 이전에 class variable 을 통해서 모델에 접근한다고 이야기한 부분이 등장합니다. self.artifacts.[ARTIFACT_NAME] 과 같은 형태를 사용해 모델에 접근할 수 있습니다. 보통은 input 을 받고 해당 input 을 모델에 넣어 input 에 대한 conditional 한 output 을 만드는 경우가 많은데, BentoML 은 이러한 기능을 API 단에서 받은 input 과 class variable 로 접근한 모델을 사용해 output 을 만들어내는 코드를 굉장히 간단하게 작성할 수 있었습니다.
BentoService 에서 마지막으로 언급드릴 부분은 클래스에 붙어있는 @bentoml.env 데코레이터입니다. 해당 데코레이터는 BentoService 와 관련 로컬 코드가 함께 배포 환경에 저장될 때 로컬 환경과 배포 환경의 기능 차이가 나타나지 않기 위해서 함께 저장되어야 하는 라이브러리를 명시합니다. pip_packages 라는 kwargs 로 명시할 수도 있고, 저 처럼 로컬 경로의 requirements.txt 로 명시할 수도 있습니다.
여기까지 오셨다면, 모델 사용 및 API 구현을 위한 클래스인 BentoService 를 작성하는 방법에 대해서 아실 것이라고 믿습니다! 하지만, 아직 어떻게 해당 클래스가 프레임워크와 artifact 이름으로 저희가 원하는 모델에 접근할 수 있는지에 대해서 설명드리지 않았습니다. 그 과정이 바로 아래에서 설명드릴 학습한 모델을 패키징하는 과정입니다.
3. 학습한 모델을 패키징하여 저장하기
학습한 모델을 패키징하는 과정을 하기 위해서 1번과 2번의 과정이 필요합니다. 학습한 모델이 준비되어야하고, 어떤 BentoService 와 함께 패키징될지를 명시해주기 위해서 BentoService 의 구현이 필요합니다. 이 두 과정이 완료 되었다면, 모델을 BentoService 에 패키징하는 과정을 진행할 수 있습니다.
def save_to_bento(checkpoint):
model_state_dict = torch.load(checkpoint)
model = initialize_model(num_classes, feature_extract, use_pretrained=True)
model.load_state_dict(model_state_dict)
bento_service = MapleCharacterDetector()
bento_service.pack("model_mdc", model)
saved_path = bento_service.save()
print("BentoService saved in ", saved_path)
Python
복사
위 함수의 앞 세 줄은 앞에서 보여드렸던 학습된 모델 인스턴스를 재구성하는 과정임을 보실 수 있습니다. 해당 과정 이후에 재구성한 네트워크 모델을 BentoService 에 pack 하는 과정을 진행할 수 있습니다. 이 때, 해당 모델을 불러올 artifact 의 이름이 pack() 함수의 첫 번째 인자로 들어가게 됩니다.
이후 BentoService 클래스의 save() 함수를 호출하게 되면, BENTOML_HOME 이라는 환경변수가 정의되어 있지 않으면 /Users/[사용자 이름]/bentoml/repository/[BentoService 이름]/[BentoService 버전]/ 의 경로로 배포에 필요한 파일들이 저장됩니다.

이전에 언급드렸던 requirements.txt 와 MapleCharacterDetector 속에 BentoService 의 구동에 필요한 로컬 파일들이 함께 들어 있는 것을 볼 수 있습니다.
이 단계까지 오면, 로컬에서 해당 기능이 제대로 동작하는지 테스트해볼 수 있습니다.
bentoml serve MapleCharacterDetector:latest
Python
복사
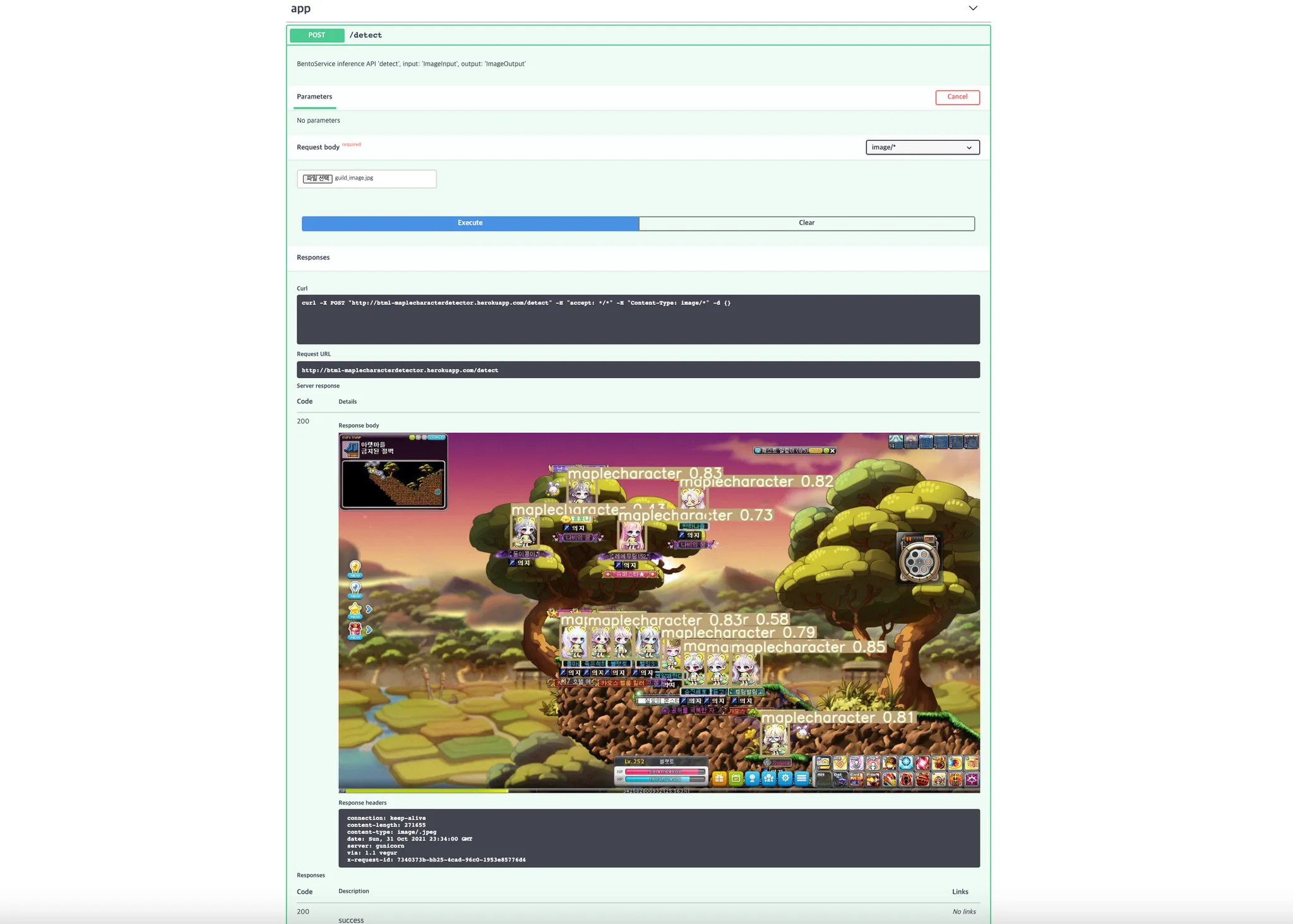
프로젝트 경로에서 위와 같이 입력하게 되면, BENTOML_HOME 으로 지정된 경로의 BentoService bundle 파일의 최신 버전을 로컬에서 실행하여 로컬호스트의 5000 번 포트로 접근했을 때 확인할 수 있습니다. 브라우저를 통해 해당 포트에 접근하면 아래와 같은 Swagger UI 가 보이게 됩니다.
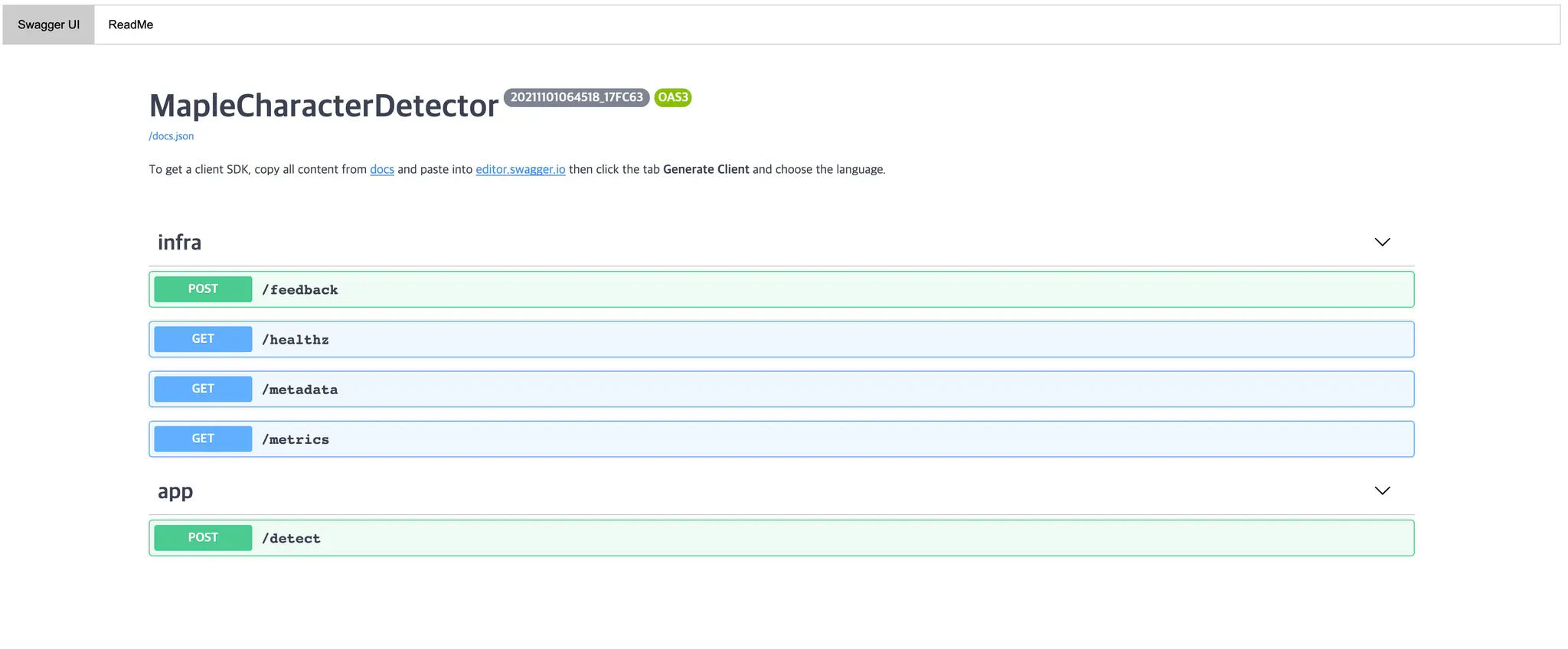
이 때 app 에 생성되어 있는 POST API 가 저희가 구현한 inference API 입니다. 이를 통해 테스트를 진행하고 배포환경에 배포할 수 있습니다.
여기서 Output 형태를 정의하지 않으면, object class 가 id 와 함께 전달된다거나 base64 로 encoding 한 값이 response 로 전달되게 되는데, 우선 Swagger UI 에서 직접적으로 보여준다- 를 목표로 한다면, base64 로 변환한 이미지를 body 에 넣어 response 로 보내주면 된다고 합니다. 해당 링크에서 커스텀하게 구현한 OutputImage 라는 adapter 를 사용할 시에, imageio 객체만을 inference API 로 넘겨주면, 자동으로 데이터를 가공하여 response 로 반환하게 됩니다. BentoML 쪽에서도 해당 기능을 고려해두고 있다는데, 1.0 릴리즈 때 포함한다고 합니다. (현재 최신은 0.13.1 입니다.)
이러한 대목을 보면 아직 나오지 얼마 되지 않은 라이브러리라는 점이 느껴지는 것 같기도 하네요..!
Client 관점에서 본다면, 스토리지나 버킷에 산출된 이미지를 저장하고, 그 이미지에 대한 접근 권한이 주어진 url 을 만들어 주는 것이 일반적- 이라고 생각은 하는데, 리소스 이슈로 인해 base64 인코딩 후 클라이언트에서 디코딩하는 형태로 client 에서 어떻게 사용할 수 있을지 간단하게 살펴보았습니다.
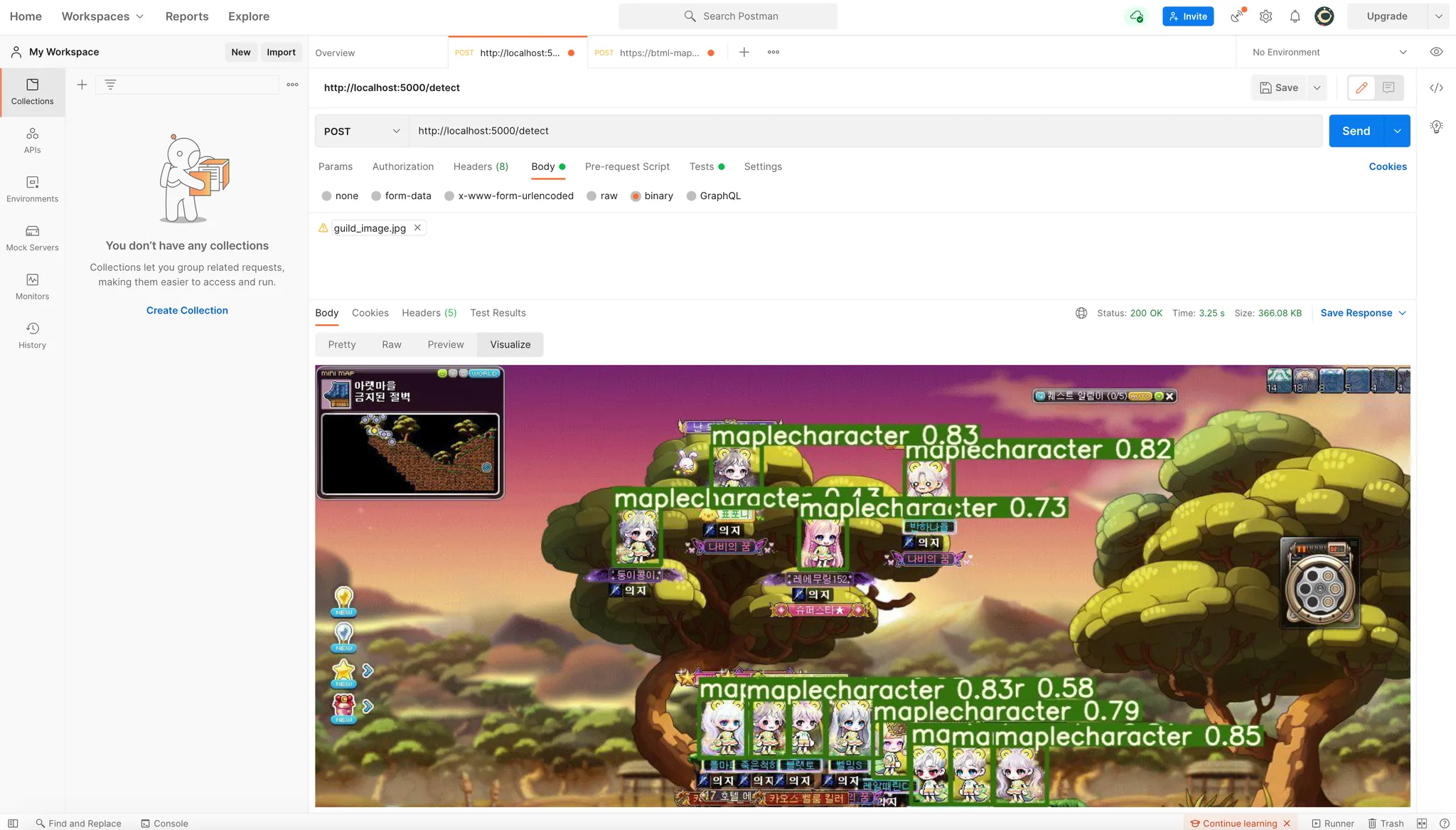
Postman 을 통해 확인해본 클라이언트 테스트
Postman 의 test 기능을 사용해서 API response 로 전달한 base64 이미지를 클라이언트에서 decode 하여 띄워줄 수 있을지 확인해 보았습니다.
let template = `
<img src='{{img}}'/>
`;
pm.visualizer.set(template, {
img: "data:image/jpg;base64," + pm.response.json()
});
JavaScript
복사
위와 같이 postman response 에 base64 image 임을 명시하는 텍스트와 함께 src 에 넣은 뒤 visualize 탭에서 확인한 결과, 생성한 이미지를 잘 확인할 수 있었습니다.
4. 배포하기
모델 배포는 모델을 패키징하여 저장한 과정에서 생성된 requirements.txt, 로컬 파일들, 그리고 Dockerfile 을 이용해서 진행할 수 있습니다.
저는 (가난해서...) Heroku 를 통해서 배포를 진행해 보았습니다. 이전에 Heroku 에서 메일 온 것에 따르면 완전 무료(제한은 있지만 영구 지속) 였던 것에 비해서 free dyno (애플리케이션을 실행하는데 필요한 환경- 정도로 이해했습니다!) 가 정해져 있어 사용이 완료되면 무료로 더 이상은 못 쓰게끔 변경이 되었다고 들었었는데, 이번에 직접 해보니까 진짜 막혔더라구요... ㅠㅠ 그래서 아쉽지만, 새로운 계정을 파고 다시 배포를 진행해보았습니다.
간단한 배포 과정은 BentoML 의 모토였으니만큼 기대를 했는데 진짜로 간단했습니다. 지금 당장 제 글을 덮고 BentoML 의 Deployment Guides > Deploying to Heroku 를 보러 가시라고 말씀을 드리고 싶지만, 저는 친숙한 한글어로 글을 한 번 적어보겠습니다. 한 번 읽어봐 주세요!
먼저, 배포 이전에 로컬환경에서의 테스트는 3. 학습한 모델을 패키징하여 저장하기 단계에서 완료하셨을 것이라 믿습니다! 이후의 배포 과정은 heroku-deploy 라는 repository 를 clone 하여 진행합니다.
$ git clone https://github.com/bentoml/heroku-deploy.git
$ cd heroku-deploy
$ python3 -m venv venv
$ source venv/bin/activate
(venv) $ pip install -r requirements.txt
(venv) bentoml get MapleCharacterDetector:latest --print-location -q
Users/[사용자 이름]/bentoml/repository/MapleCharacterDetector/[BetoService 이름]/[BentoService 버전]
(venv) python deploy.py [위 경로] [배포할 앱 이름] heroku_config.json
Shell
복사
놀랍게도 끝입니다!
다만, heroku-cli 와 docker 가 설치되어 있어야 하는데 저는 이전에 설치한 이력이 있어서 굉장히 간단하게 느껴졌습니다. 그런데 과정이 간단하다고 해서 간단하게 되는 것은 아니었습니다.
제가 겪은 크게 두 가지 시행착오를 말씀드리자면,
1.
꼭 로컬에서 사용한 가상환경의 패키지들을 requirements.txt 에 담는 과정을 한 번 확인하세요!
2.
프로젝트에서 open-cv 를 사용하고, 앱 배포 로그에 해당 에러가 나타난다면, Docker 에서 open-cv 를 설치할 때 나는 오류를 해결하기 위해 Dockerfile 에 수동으로 libgl1-mesa-glx 를 설치해주세요!
위 두 가지 시행착오를 거치고 성공적으로 Heroku 에 배포할 수 있었습니다. 배포된 서버는 아래에서 확인하실 수 있습니다.
관심 있으신 분들은 한 번쯤, 메이플스토리 캐릭터가 포함된 사진을 input 으로 POST 해보시면, 캐릭터 찾기가 완료되어 bounding box 가 그려진 사진이 response 로 오는 것을 확인하실 수 있으실 것입니다 ㅎㅎㅎ
(다만, Heroku 무료 버전은, 수명이 짧아서 이 글을 보실 때 죽어있을지도 몰라요... )
)마무리
이렇게 BentoML 을 이용해서 머신러닝 모델을 쉽고, 빠르게 서빙하는 방법에 대해서 알아보았습니다. 개인적으로는 1. 기존의 모델 학습 방법을 그대로 가져가도 되는 점, 2. 코드 작성 및 배포가 간단한점 은 굉장히 장점이라고 생각이 드는데, 퍼포먼스적으로 해당 라이브러리를 챌린지해보지는 않아서 해당 부분에 대해서는 말을 아끼게 되는 것 같습니다. 더불어 아직은 ImageOutput 등의 Adapter 가 없어서 custom 으로 써야하는 상황이나, 이슈에 직면했을 때 레퍼런스가 많이 없었다는 점 등 초기 라이브러리의 아쉬운 점들이 보였는데 이 부분은 차츰 해결되어가지 않을까 기대해봅니다.