본 포스트에서는 Diffusion Model 을 사용하여 2D Image 의 로컬 영역에 대한 편집을 구현한 논문에 대해서 소개드리려고 합니다.
“Blended Diffusion for Text-driven Editing of Natural Images”

Objective
“백문이 불여일견” 이라는 말과 비슷하게 영어권에서는 “a picture is woth a thousand words” 라는 어구가 있습니다. 하지만, 이러한 어구가 무색해질 정도로 최근 컴퓨터 비전 영역의 연구는 적은 단어들로도 이미지를 설명해내기 충분하다는 것을 보여주었습니다. Vision-Language Model (ex. CLIP) 의 엄청난 발전과 데이터 기반의 Image Generation 방법론 (ex. GAN) 의 활용은 텍스트 기반으로 이미지를 생성하고 조작하는 작업이 발전하는데 큰 영향을 주었습니다.

Text-driven Object/Background Replacement
특히, GAN 을 활용하여 이미지를 조작하는 많은 선행연구들이 인상적인 결과를 남겼지만, 이들은 일반적으로 GAN 이 학습된 도메인 내에서만 동작한다는 명확한 한계를 가지고 있었습니다. 더불어, GAN 을 활용한 방법론들이 이미지를 조작하기 위해서는 이미지를 Latent Space 로 매핑하는 과정이 필요한데, Latent Space 의 벡터로부터 원래의 이미지를 복원하는 능력과 이미지 편집 능력은 trade-off 의 관계를 가지고 있다는 단점도 있었습니다.
논문에서는 이를 해결하기 위해 일반적인 Real-World Natural Images 들에서도 도메인에 구애받지 않고 동작하는 텍스트 기반의 이미지 편집 방법론을 제시합니다. 한 가지 특별한 점은 논문의 방법론이 기존의 많은 선행연구들이 어려워하던, 특정 영역에 한정된 이미지 편집에 성공했다는 점입니다. 더불어 이를 구현해내면서도, 특정 영역 외의 배경과의 자연스러움을 유지한 다양한 이미지들을 산출했습니다. 위 그림에서 보이는 빨간색 영역이 mask 로 지정된 편집 영역이고, 각각의 그림의 하단에 보이는 텍스트가 편집에 사용한 설명이라고 보시면 됩니다.
Background
논문의 방법론을 이해하기 위해서는 선행연구인 Denoising Diffusion Probabilistic Models (DDPM) 에 대해서 알아야 합니다. 본 포스트에서는 앞으로 전개될 이야기들에 대한 기본적인 이해를 위해 해당 논문에 대해서 간략하게 논문에서 언급한 수준으로나마 소개할 예정입니다. 논문을 직접 읽어보실 분들은 이곳을 참고하시면 좋습니다.
Denoising Diffusion Probabilistic Models
DDPM 은 2020 년에 NeurIPS 에 Poster Session 으로 채택된 Image Synthesis 분야의 논문입니다. Image Synthesis 분야에서 자주 사용되는 GAN 종류와는 다르게 DDPM 은 Markovian Image Noising Process 의 역과정을 학습함으로써 노이즈로부터 이미지를 생성하는 능력을 가지게 됩니다.
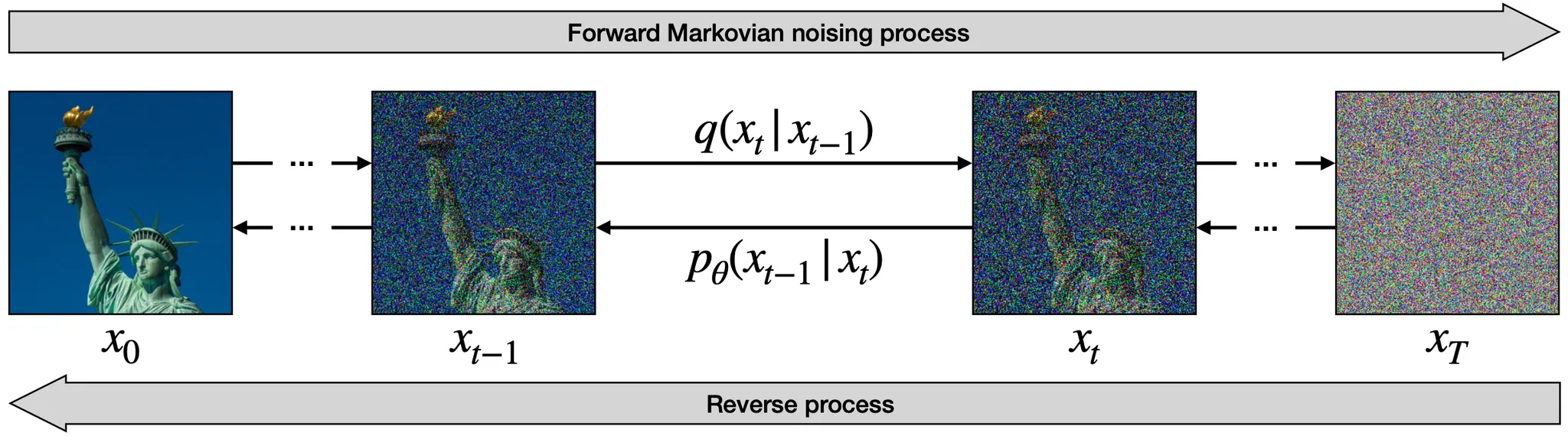
Denoising Diffusion
위의 그림은 DDPM 의 방법론을 도식화한 것입니다. 아래에서는 위 그림을 바탕으로, DDPM 의 프로세스에 대해서 설명할 예정입니다.
Forward Markovian Noising Process
좌측에서 우측으로 가는 프로세스는 Forward Markovian Noising Process 라고 불리며, 초기 이미지 분포 로부터 조금씩 Gaussian Noise 를 추가해가며 최종적으로 Normal Distribution 에 근접한 분포의 노이즈를 만들어내는 과정입니다. 이 과정을 수식으로 표현하면 다음과 같습니다.
여기서, 은 의 distribution 을 기반으로 노이즈가 추가된 의 distribution 을 만드는 변환과정이라고 보시면 됩니다. 이 과정은 아래와 같이 수식으로 표현됩니다.
위 식에서 나타난 는 의 제약을 가지며, 정성적으로 해석하면 0 에 비교적 가까운 일 때는 가 기존 의 분포를 유지한 형태임을, 1 에 비교적 가까운 일 때는 가 normal distribution 과 가까운 형태를 가지게 됨을 짐작하실 수 있습니다.
이 과정을 iterative 하게 진행하여 전개하면 다음과 같이 를 초기 입력 분포 로 표현할 수 있습니다.
위 식에서 , , 입니다. 약간의 부연설명을 하자면, 2 번째 줄에서 3 번째 줄로의 변환은 과 분포의 합산 과정으로, 이 된 것입니다. 이 변환 과정을 통해 결국 입력 분포 와 iterative step 수와 그에 해당하는 들만 정의한다면 Forward Markovian Noising Process 는 단순한 연산 문제가 됨을 알 수 있습니다.
Reverse Process
좌측에서 우측으로 가는 프로세스는 단순한 연산 과정임을 알아보았습니다. 어느정도 예상하셨겠지만, Image Generation 을 위해서는 네트워크가 노이즈로부터 이미지를 생성해내야 하고, DDPM 논문에서는 이를 위해 노이즈로부터 이미지를 복원하는 우측에서 좌측 과정을 네트워크가 학습하도록 설계했습니다. 이를 Reverse Process 및 Denoising Diffusion Process 라고 합니다.
의 역과정이라고 할 수 있는 를 로부터만 도출해내는 것은 불가능하기 때문에, DDPM 논문에서는 네트워크가 의 추론인 를 산출하도록 설계합니다. 여기에 더불어 를 직접적으로 추론하는 것보다 에서 까지의 변화에 사용된 노이즈 를 추론하여 베이즈 정리를 사용해 를 구해내는 방법을 선택합니다. 이 부분은 참고로만 알아두셔도 좋을 것 같습니다.
이렇게 추론한 역과정을 바탕으로 원본 이미지를 복원한 결과를 가지고 최종적인 loss 항목을 정의하게 되는 것 정도로 이해해주시면 될 것 같습니다.
Method
논문의 방법론은 주어진 이미지에서 특정 영역을 텍스트가 설명하는 바에 적합하도록 편집하는 것을 목적으로 합니다. 입력된 이미지와 텍스트를 각각 , 로, Region of Interest (ROI) 영역을 mask 으로, 네트워크가 최종적으로 산출하는 편집된 이미지를 라 할 때 방법론의 목적은 가 가 표현하는 바와 유사해야 하며, 은 입력 이미지와 유사해야 하는 것입니다. (참고로, 은 elementwise multiplication 이며, mask 는 특정 영역만 1, 나머지 영역이 0 인 이미지와 같은 크기의 패치로 보시면 됩니다.)
논문에서는 해당 목적을 달성하기 위해 첫 번째로 Local CLIP-guided diffusion 에 대해서 설명하고, 최종적으로 이를 개선한 Text-driven Blended diffusion 을 이어서 설명합니다.
Local CLIP-guided diffusion
앞서 언급한 논문의 목적은 크게 두 가지로 나눌 수 있습니다.
1.
Mask 로 표현된 ROI 영역이 입력 텍스트인 가 표현하는 바와 유사해야 한다.
2.
Mask 로 표현된 ROI 를 제외한 영역이 기존 이미지 와 유사해야 한다.
논문에서는 첫 번째 목적을 달성하기 위해 이미지와 텍스트의 유사도를 산출할 수 있는 Image-Text Model 인 CLIP 을 활용합니다.

CLIP?
CLIP 은 이전 논문리뷰에서 한 번 다룬 적 있는 내용이며 Image-Text Model 중 하나입니다.
CLIP 은 거대한 ImageNet Supervision 데이터를 기반으로 학습된 Image Encoder 와 Text Encoder 로 구성되며, 이미지와 텍스트를 동일한 벡터 공간으로 매핑한 뒤 해당 벡터간의 코사인 유사도를 계산함으로써 이미지와 텍스트의 유사도를 계산할 수 있습니다.
앞서 Background 에서 설명드린 Denoising Diffusion Process 의 각각의 step 에서 네트워크가 를 산출했었습니다. 논문에서는 이렇게 산출한 를 통해 원본 이미지를 다음과 같이 추론해냅니다. 아래의 식은 앞서 Forward Markovian Noising Process 의 식의 항만 단순히 조정한 것입니다.
논문에서는 이 추론된 이미지와 텍스트와의 유사도를 증가시키는 방향으로 CLIP-based Loss 를 정의하고, 이는 아래와 같이 표현됩니다.
위 식에서 는 CLIP 의 Image Encoder 를, 는 CLIP 의 Text Encoder 를 의미합니다. 결과적으로 추론한 원본 이미지에 ROI mask 를 적용한 이미지와 텍스트와의 코사인 유사도 를 계산했다고 보시면 됩니다.
앞에서 설명드린 CLIP-based loss 를 활용하면 정성적으로는 ROI 영역이 텍스트가 설명하는대로 변경될 것이라고 생각할 수 있습니다. 하지만, mask 를 적용했음에도 결과적으로 CLIP Image Encoder 에는 mask 외부가 검은색인 이미지 전체가 들어가고, CLIP-based loss 를 기반으로 back propagation 을 하면 ROI 영역 외의 영역에도 변화가 생깁니다. 때문에 기존 이미지와 전혀 다른 이미지가 생겨날 수 있었고, 논문에서는 이를 방지하기 위해 두 번째 목적을 직접적으로 유도할 수 있는 방법을 설계합니다.
논문에서는 위와 같은 수식의 Background Preservation Loss 를 정의합니다. ROI 를 제외한 영역에 대해서 두 이미지가 얼마나 비슷한지를 수치화 한 것입니다.
LPIPS (Learned Perceptual Image Patch Similarity)?
LIPS 는 The Unreasoalbe Effectiveness of Deep Features as a Perceptual Metric 이라는 논문에서 제시한 지표로, AlexNet, VGG, SqueezeNet 등의 초기 CNN 모델들의 feature extractor 를 가져와서 feature 단에서 유사도를 비교하는 형태의 지표입니다.
Feature Extractor 에 을 입력으로 하여 얻어진 layer 뒤에 산출된 나온 activation 으로,
Feature Extractor 에 을 입력으로 하여 얻어진 layer 뒤에 산출된 나온 activation 라 할 때,
크기의 activation 에 대해서 channel wise 로 가중치를 주어 크기로 만든 뒤, L2 norm 을 계산하고 크기인 로 나누어주고, 이 계산 값을 L 개의 layer 에 대해 반복한 값이라고 보시면 됩니다.
계산 자체는 복잡해보일 수 있는데, 결론적으로 MSE 가 이미지단에서의 직접적인 유사도를 측정하는 지표라면, LPIPS 는 feature 단의 유사도를 측정하는 지표입니다.
최종적으로 논문에서 제시한 Local CLIP-guided diffusion 에서는 CLIP-based Loss 와 Background Preservation Loss 를 가중치를 주어 혼합한 형태의 Loss 를 완성합니다.
Background Preservation Loss 쪽에 붙어있는 가중치 는 전체 과정에 얼마나 Background 를 유지할 수 있는 능력이 있는지를 조절할 수 있었고, 논문에서는 실제로 값에 따른 optimization 결과를 아래와 같이 보여줍니다.

Effect of in local CLIP-guided diffusion
위의 그림은 좌측의 입력 이미지와 mask 를, 텍스트로는 “dog” 를 넣었을 때의 결과입니다. 앞서 언급했던 것처럼 가 매우 작을 때는 노이즈가 입력 이미지와 완전히 동 떨어진 이미지로 변환됨을, 가 매우 클 때는 ROI 영역의 변화가 거의 없음을 확인할 수 있었습니다. 적절한 수준의 를 선택하면 ROI 영역이 비교적 텍스트와 유사한 형태로 변하고 그 외의 영역은 비슷한 형태가 유지됨을 볼 수 있습니다. 하지만 ROI 영역의 표현이 극히 제한적이고 ROI 외부 영역도 러프한 관점에서만 유사한 것이지 동일하다고 볼 수는 없었고 논문에서는 이를 개선하기 위한 시도를 합니다.
Text-driven Blended diffusion
Background preserving blending
ROI 영역은 텍스트가 설명하는 대로 편집하고, ROI 외부 영역은 입력 이미지와 동일하게 유지하면서 전체적으로 그럴듯한 이미지를 만들어내기 위해, 논문에서는 앞선 Local CLIP-gudided Process 의 각각의 step 에서 생성한 이미지와 Forward Markovian Noising Process 에서 생성한 이미지의 노이즈 추가한 버전을 혼합 (논문에서는 blend 라는 표현을 사용합니다.) 하는 과정을 각 step 마다 추가합니다.
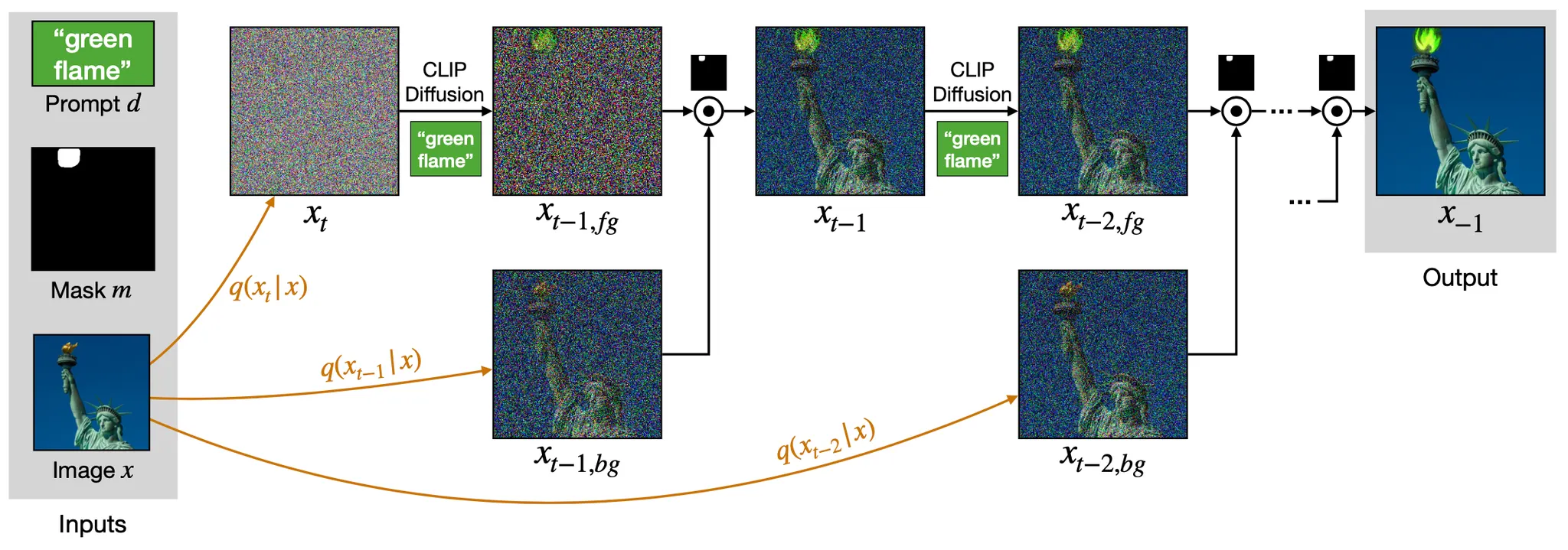
Text-driven Blended Diffusion
위의 그림에서 표현된 것과 같이 Forward Markovian Noising Process 의 마지막 단계에서 생성된 노이즈 (이자 latent) 로부터 Local CLIP-guided Process 를 진행하여 를 얻습니다. CLIP-based Loss 로 인해 노이즈의 mask 부분이 조금 변한 것을 보실 수 있습니다. 여기에 추가적으로 Forward Markovian Noising Process 의 마지막이 되기 바로 전 단계에서 나타났던 이미지를 로 하여 이 둘을 혼합하게 됩니다. 이는 수식으로 다음과 같이 표현할 수 있습니다.
여기서 와 를 혼합하는 과정에서 자연스럽지 못하게 붙여지는 현상에 대해 의문이 있을 수 있는데, 다음 Diffusion Step 이 진행되는 과정에서 ROI 의 경계에서 나타나는 이러한 부자연스러움이 해소될 것을 기대했다고 보시면 됩니다.
Extending Augmentations
Adversarial Exmaples 는 많은 네트워크들이 실패하는 경우 중 하나입니다. Optimization 과정이 온전히 픽셀 값에만 의존하여 변화하는 설계의 경우, 픽셀값을 의도적으로 섬세하게 조절함으로써 GAN 의 discriminator 나 CNN 의 classifier 등을 속일 수 있는 것입니다.
이러한 Adversarial Examples 와 비슷하게 논문의 설계는 CLIP-guided diffusion 에 의해서 픽셀값을 점진적으로 밖는 설계는 CLIP loss 자체는 떨어뜨리지만 실제로 보았을 때 무의미한 방향으로의 변화 (Semantic Unmeaningful) 를 종종 일으켰다고 합니다.
논문에서는 이를 해결하기 위해 Diffusion Step 에 간단하지만 효과적인 Augmentation 을 적용합니다. 각각의 Diffusion Step 마다 산출하는 를 통해 추론하는 를 사용해 직접적으로 Loss 를 계산하지 않고 추론한 이미지에 augmentation 을 적용하여 augmented image 들의 CLIP-based Loss 를 계산하여 평균을 내는 방식을 택합니다. 하나의 이미지를 속이기는 쉽지만, 어려 이미지를 모두 속이는 것은 어렵다- 라는 관점에서 올바른 방향으로의 학습을 유도하는 효과를 기대하여 구현한 설계라고 보시면 됩니다. 논문에서는 이러한 그들의 설계를 Extending Augmentation 이라고 칭합니다.
Result Ranking
논문의 Text-driven Blended Diffusion 은 과정 중간에 분포로 부터의 sampling 이 포함되어 있기 때문에 (단순히 Forward Markovian Noising Process 만 보아도 가 존재합니다.) 동일한 입력 이미지와 텍스트를 넣는다고 하더라도 다양한 output 이 등장할 수 있습니다. 이러한 설계는 여러 결과를 산출하고 높은 점수를 취득한 결과를 취사 선택하는 과정을 통해 긍정적으로 작용할 수 있었다고 합니다.
Results
논문에서는 그들의 방법론의 성능 및 유의미함을 입증하기 위해 다음과 같은 것들을 진행합니다.
1.
선행연구 및 baseline 과 정성적 및 정량적으로 비교합니다.
2.
Extending Augmentation 에서 설명한 Augmentation 의 효과에 대해서 검증합니다.
3.
논문의 방법론으로 가능하게 된 다양한 Application 을 소개합니다.
Comparisons
가장 먼저 논문에서는 선행연구 및 baseline 과의 정성 및 정량적 비교를 진행합니다. 비교를 진행한 대조군은 다음과 같습니다.
PaintBy-Word
Local CLIP-guided diffusion (
VQGAN-CLIP + PaintBy-Word
의 PaintBy-Word 는 2021년에 공개된 Zero-Shot Semantic Image Painting 을 위한 논문이고, regional editing 이 가능하다는 점에서 비교 대상으로 선정되었습니다. 는 논문에서 개선하기 전 처음 방법론이며, VQGAN-CLIP + PaintBy-Word 는 기존의 PaintBy-Word 에 VQGAN-CLIP 을 붙여 편집하려는 영역의 이미지를 VQGAN latent space 로 매핑하여 optimize 하는 과정을 거친 방법론입니다.

Comparisons with Previous Methods
PaintBy-Word 의 구현체를 현재 사용할 수 없었기 때문에, 논문에서는 PaintBy-Word 에서 사용한 데이터를 그대로 사용하여 비교하게 됩니다.
세 개의 대조군과 함께 정성적으로 비교한 결과는 위와 같습니다. 비교한 세 가지 방법론 모두 Background Preservation 을 유도하는 과정이 있음에도 불구하고 Background 가 변형된 것을 관찰할 수 있었습니다. 더불어 의 “blue firetruck”, 의 “sad dog”, 의 “happy dog” 등 각각의 방법론 모두 한 가지 이상의 비현실적인 결과를 산출했습니다. 이와 다르게 논문의 방법론은 Background 를 완벽하게 유지하고, 편집한 결과가 자연스럽고 배경과 일관됨을 확인할 수 있었습니다.
더불어, 구현체를 사용할 수 없는 PaintBy-Word 를 제외하고 Real World Image 를 사용하여 다시 한 번 평가를 진행했고, 그 정성적인 결과는 아래와 같습니다.

Comparisons with Previous Methods (on Real Images)
Local CLIP-guided diffusion (, VQGAN-CLIP + PaintBy-Word 는 논문의 방법론과 다르게 Background 를 유지할 수 있는 능력과 ROI 영역과 Background 영역을 일관된 모습으로 표현할 수 있는 능력이 부족함을 다시 한 번 살펴볼 수 있었습니다.
논문에서는 각 방법론끼리의 정량적인 비교 지표를 얻기 위해 사람들에게 평가를 진행했고, 그 결과를 제시합니다. 평가를 진행한 항목은 1. 얼마나 이미지가 자연스러운지 (Realism), 2. 얼마나 배경이 보존되는지 (Background Preservation), 그리고 3. 얼마나 텍스트가 이미지를 잘 설명하는지 (Text Match) 였습니다.
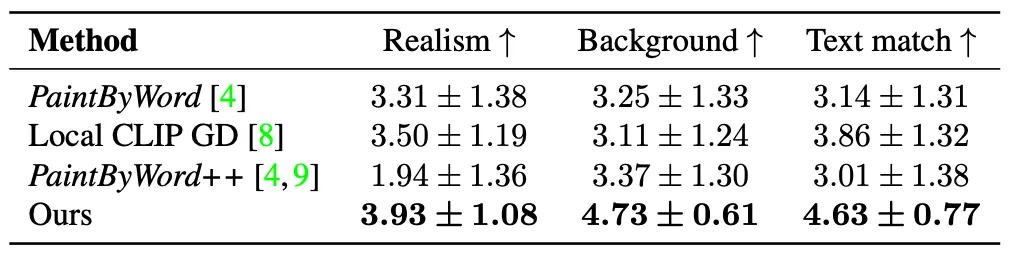
User Study Result
위 표의 결과에 따르면 논문의 방법론이 모든 평가 항목에서 다른 방법론보다 우위에 있었습니다.
Ablation of Extending Augmentations
Extending Augmentation 의 중요성을 입증하기 위해 논문에서는 Ablation Study 를 진행합니다. 논문에서는Extending Augmentation 이 있는 경우와 없는 경우의 결과를 정성적으로 제시합니다.

Extending Augmentation Ablation
위 그림의 은 Extending Augmentation 이 없는 경우이고, 는 있는 경우입니다. Extending Augmentation 이 있는 경우가 없는 경우보다 더 텍스트가 의미하는 바가 그럴듯하게 표현되어 있고 자연스럽고 일관된 형태로 표현되는 것을 확인할 수 있었습니다. 이를 통해 논문에서는 그들의 Extending Augmentation 방법론이 유의미함을 정성적으로 입증했습니다.
Applications
논문에서는 그들의 방법론이 실생활의 이미지들에 일반적으로, 다양한 방식으로 응용이 가능함을 보여줍니다. 아래는 그 예시들입니다.
Text-driven Object Editing
논문의 방법론을 사용하면 이미지 속 존재하는 물체를 추가, 제거 및 변경할 수 있습니다. 아래의 사진은 논문의 방법론이 새로운 물체를 추가할 수 있는 능력이 있음을 보여줍니다.

위의 그림에서 볼 수 있듯이 그럴듯한 다양한 결과를 산출해낼 수 있으며, 영역이 포함한 전체적인 물체를 제거하는 것이 아닌, 영역이 가르키는 부분만 텍스트가 설명하는대로 교체가 가능함을 볼 수 있습니다.

더불어, 위의 그림과 같이 텍스트를 입력하지 않으면 물체를 제거하는 것도 가능함을 확인 할 수 있습니다.
Background Replacement
Foreground 의 물체들을 편집하는 것 말고도, 논문의 방법론을 사용하면 Background 또한 변경할 수 있습니다. 이는 간단히 ROI 영역을 배경 영역으로 설정하면 됩니다. 아래는 논문의 Appendix 에 제시된 Background Replacement 결과들입니다.

Background Replacement
Scribble-guided Editing
논문의 방법론을 사용하면, 원하는 형태의 물체가 있을 때 유저가 직접 가이드를 줄 수도 있습니다. 논문의 방법론은 이미지 위에 러프하게 그린 그림을 바탕으로 자연스럽게 변경한 결과를 산출할 수 있습니다.

Scribble-guided Editing
위의 그림은 입력 scribble 을 영역을 ROI 로 하고 텍스트로 “blanket” 을 주었을 때의 산출 결과입니다. 무늬와 형태가 어느정도 자연스럽게 변경되어 산출된 것을 확인할 수 있습니다.
Text-guided Image Extrapolation
Image Extrapolation 은 주어진 입력 이미지 영역 범위 바깥으로 이미지를 확장하는 방법입니다. 논문의 방법론을 사용하면 텍스트를 사용해 적절하게 이미지를 영역 범위 바깥으로 확장할 수 있습니다.

Text-guided Image Extrapolation
위 그림은 입력 이미지의 좌측으로는 “Hell” 을, 우측으로는 “Heaven” 을 텍스트로 주어 Extrapolation 을 진행한 결과입니다. 텍스트의 설명이 어느정도 들어맞는 이미지를 자연스럽게 확장해준 것을 확인할 수 있습니다.
Conclusion
이것으로 논문 “Blended Diffusion for Text-driven Editing of Natural Images” 의 내용을 간단하게 요약해보았습니다.
최근 Generative Methods 로 자주 들리는 것이 Diffusion 이었는데, 이번 기회를 통해서 어떠한 개념인지 알 수 있어서 좋았던 것 같습니다.
다만 DDPM 의 사전지식을 완전히 배제한다면 논문에서 순수하게 novelty 있게 제시한 방법론이라고 느껴지는 것은 많이는 없었고, 정량적 평가를 User Study 로 대체하는 등 여러 방면에서 개인적으로 퀄리티가 높은 논문이라고 느껴지지는 않았던 것 같습니다. 다만 전달해주는 내용 자체는 신선하고 재밌어서 흥미롭게 읽을 수 있었던 것 같습니다.