휴먼스케이프의 레어노트 서비스에는 유저로부터 이미지를 입력받는 기능이 있습니다. 현재는 유저가 직접 업로드한 이미지를 유관자 분께서 직접 확인하고 처리하는 과정을 거쳐야 하는데요..! 
평소에는 크게 문제가 되지 않지만 유저가 업로드한 이미지가 선명하지 않을 경우, 작업하는데 큰 어려움이 있다고 합니다. 이러한 불편함을 해결하고자 한 이후로 스멀스멀 단일 이미지 화질 개선에 대한 이야기가 나오기 시작했는데요. (큰 목소리는 아니었던 것 같긴 한데...)
저는 해당 문제가 제기되었을 때 Super Resolution 이라는 Computer Vision Task 가 있다는 것을 처음 알게 되었습니다. 정확히 말하자면, Super Resolution 은 화질 개선이라기 보다는 기존의 보간법들에 비해서 해상도를 더욱 자연스럽게 확장하는 방법론을 연구하는 분야이기는 하지만 당시에 제가 느끼기에는 생각보다 흥미로운 분야인 것 같았습니다. 그러나 레어노트의 다른 기획들이 물 밀듯이 밀려오면서 해당 작업은 자연스럽게 잊혀졌었습니다.
단일 이미지 화질 개선 프로젝트는 2022 년 3월 중순부터 제가 휴먼스케이프에서 사내 AI 프로젝트를 디벨롭할 기회를 얻게 되면서 회사에 도움을 줄 만한 프로젝트를 모색하다가 다시금 수면 위로 올라왔습니다. 그렇게 한 번 해보자! 하는 생각으로 Image Super Resolution 분야로 Papers With Code 를 탐색하기 시작했고 가장 대중적으로 구현이 많이 되어 있는 SRGAN 쪽으로 마음이 기울어 프로젝트를 시작하게 되었습니다.
회사에 도움을 줄 만한 프로젝트를 모색하다가 다시금 수면 위로 올라왔습니다. 그렇게 한 번 해보자! 하는 생각으로 Image Super Resolution 분야로 Papers With Code 를 탐색하기 시작했고 가장 대중적으로 구현이 많이 되어 있는 SRGAN 쪽으로 마음이 기울어 프로젝트를 시작하게 되었습니다.
모델 구현하기
SRGAN 모델 구현은 논문에 있는 구조를 기본으로 사용했습니다. GAN 이기 때문에 두 개의 네트워크 Generator 와 Discriminator 를 정의해야 하고, 추가로 Feature Extractor 라는 특별한 모델을 차용하여 가져옵니다. 저는 models.py 에 위 세 가지 네트워크를, layers.py 에 세 가지 모델들을 정의하기 위해 필요한 레이어들을 정의했습니다.
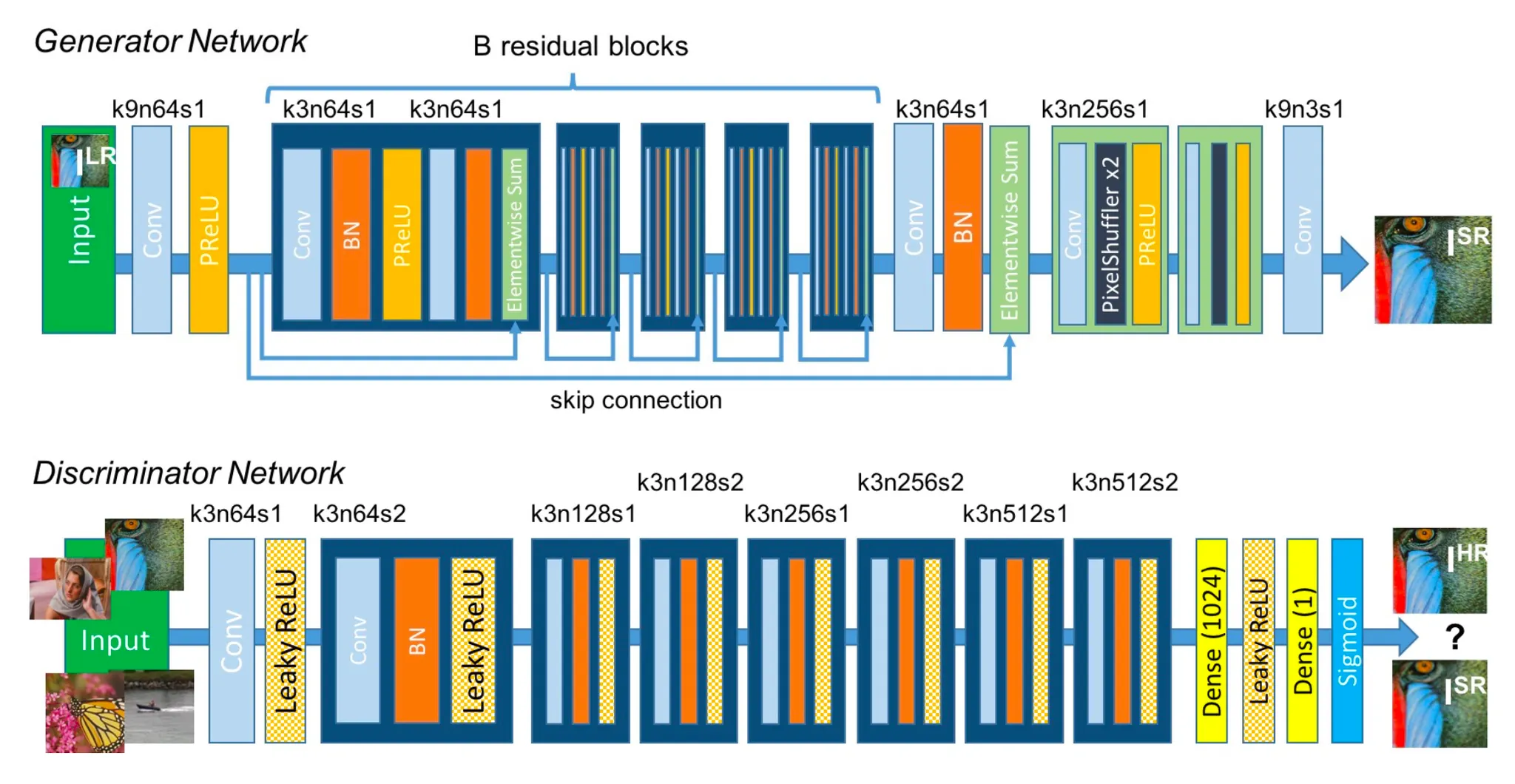
Generator
가장 먼저 살펴볼 네트워크는 Generator 입니다.
아래는 layers.py 에 정의되어 있는 Residual Block 레이어입니다. Generator 에 사용되는 B 개의 반복적인 Residual Block 을 클래스화하여 정의한 것입니다. 논문에 적혀있는 대로 구현을 했고, Elementwise Sum 같은 경우에는 forward 메소드에서 Skip Connection 을 구현했습니다.
from torch import nn
class ResidualBlock(nn.Module):
"""
Residual Block in Generator
"""
def __init__(self, channels, kernel_size, stride, padding):
super().__init__()
res_blocks = [
nn.Conv2d(
in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=stride, padding=padding
),
nn.BatchNorm2d(num_features=channels, eps=0.8),
nn.PReLU(),
nn.Conv2d(
in_channels=channels, out_channels=channels, kernel_size=kernel_size, stride=stride, padding=padding
),
nn.BatchNorm2d(num_features=channels, eps=0.8),
]
self.res_blocks = nn.Sequential(*res_blocks)
def forward(self, x):
return x + self.res_blocks(x) # Skip Connection
Python
복사
이렇게 layers.py 에 정의되어 있는 레이어들을 이용해 실제 모델은 models.py 에 정의했습니다.
from torch import nn
from torchvision.models import vgg19
from layers import ResidualBlock, UpsamplingBlock, DiscriminatorConvBlock
class Generator(nn.Module):
def __init__(self, in_channels=3, out_channels=3, num_res_blocks=16, is_train=True):
super().__init__()
self.is_train = is_train
self.conv_1 = nn.Sequential(
*[nn.Conv2d(in_channels=in_channels, out_channels=64, kernel_size=9, stride=1, padding=4), nn.PReLU()]
)
self.res_blocks = nn.Sequential(
*[ResidualBlock(channels=64, kernel_size=3, stride=1, padding=1) for i in range(num_res_blocks)]
)
self.conv_2 = nn.Sequential(
*[
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(num_features=64, eps=0.8),
]
)
self.ups_blocks = nn.Sequential(
*[UpsamplingBlock(in_channels=64, out_channels=256, kernel_size=3, stride=1, padding=1) for i in range(2)]
)
# Tanh application referenced by https://towardsdatascience.com/gan-ways-to-improve-gan-performance-acf37f9f59b
self.conv_3 = nn.Sequential(
*[nn.Conv2d(in_channels=64, out_channels=out_channels, kernel_size=9, stride=1, padding=4), nn.Tanh()]
)
def forward(self, img):
if not self.is_train:
img = img.unsqueeze(0)
conv_1_feature = self.conv_1(img)
res_blocks_feature = self.res_blocks(conv_1_feature)
conv_2_feature = conv_1_feature + self.conv_2(res_blocks_feature)
ups_blocks_feature = self.ups_blocks(conv_2_feature)
output = conv_3_feature = self.conv_3(ups_blocks_feature)
return output
Python
복사
is_train 이라는 이름으로 정의된 instance variable 은 inference 를 위해 Generator 를 활용할 때 Batch 학습을 위한 이미지의 dimension 을 추가하는 작업을 번거롭게 하지 않아도 되도록 모델 단에서 커스텀한 요소입니다. forward 메소드에서 is_train 이 False 이면 강제로 dimension 을 늘리는 것을 보실 수 있는데, 요 부분 때문에 이미지의 dimension 을 따로 건드리지 않아도 Generator 에 통과시키는 것만으로 Inference 를 진행할 수 있고 Super Resolution 이미지를 얻어낼 수 있습니다.
특별하게 설명드릴 부분은 Generator 클래스의 마지막 instance variable conv_3 속의 tanh 레이어입니다. 논문에서는 다음과 같은 설명이 있습니다.
We scaled the range of the LR input images to [0, 1] and for the HR images to [−1, 1]
- Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
이러한 설정 때문에 이미지를 준비할 때 0 ~ 1 사이의 값을 가지는 tensor 를 mean 0.5 standard deviation 0.5 로 normalization 을 진행하는데 이는 범위를 일정 범위로 제한하여 학습 속도를 챙기고 복잡하지 않은 mapping 을 학습하도록 하는 기법입니다. Generator 의 끝에 activation function 을 두지 않을 경우 나올 수 있는 값의 범위도 크며 그에 따라 튀는 값들이 생성되는 이슈가 있어 tanh 로 범위를 로 변환하고 처음 normalize 했던 것처럼 un-normalization 을 진행하는 형태로 커스텀을 진행했습니다.
그 외에 위의 구현체에서 설명드리지 않은 UpsamplingBlock 은 ResidualBlock 처럼 layers.py 에 구현되어 있는데, 아래의 토글에 해당 구현체가 있으니 원하시는 분들을 한 번쯤 보셔도 좋을 것 같습니다.
UpsamplingBlock 구현체 보기
Discriminator
다음으로 살펴볼 것은 Discriminator 입니다.
아래는 models.py 에 구현되어 있는 Discriminator 입니다.
class Discriminator(nn.Module):
def __init__(self, input_height, input_width, in_channels=3):
super().__init__()
output_height = input_height // 2**4
output_width = input_width // 2**4
self.disc_blocks = nn.Sequential(
*[
DiscriminatorConvBlock(
in_channels=in_channels if (i == j == 1) else 2 ** (i - j % 2 - 1) * 64,
out_channels=2 ** (i - 1) * 64,
kernel_size=3,
stride=j,
padding=1,
batch_norm_exists=False if (i == j == 1) else True,
)
for i in range(1, 5)
for j in range(1, 3)
]
)
# Original Paper's Classifier Structure
# self.classifier = nn.Sequential(
# *[
# nn.Flatten(),
# nn.Linear(in_features=output_height * output_width * 512, out_features=1024),
# nn.LeakyReLU(negative_slope=0.2, inplace=True),
# nn.Linear(in_features=1024, out_features=1),
# nn.Sigmoid(),
# ]
# )
# Custom Classifier Structure
# Referenced by https://machinelearningmastery.com/how-to-train-stable-generative-adversarial-networks/
self.classifier = nn.Sequential(
*[
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(in_channels=2**3 * 64, out_channels=1024, kernel_size=1, stride=1, padding=0),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
nn.Conv2d(in_channels=1024, out_channels=1, kernel_size=1, stride=1, padding=0),
nn.Sigmoid(),
]
)
def forward(self, img):
disc_blocks_feature = self.disc_blocks(img)
output = self.classifier(disc_blocks_feature)
return output
Python
복사
위 코드에 적혀있는 DiscriminatorConvBlock 는 layers.py 에 구현되어 있는 레이어입니다. 앞서 설명드린 Residual Block 처럼 반복되어 사용되는 레이어를 클래스화했다고 보시면 됩니다.
여기서 특별하게 설명드릴 부분은 클래스의 가장 마지막 instance variable 인 classifier 부분입니다. 기존의 논문에서는 Fully Connected Layer 를 사용하여 구현을 했는데, GAN 의 stabilize 를 위해서 Fully Connected Layer 의 사용을 지양해야 한다는 글을 보고 Convolution Layer 로 커스텀하여 구현했습니다. (이 변경이 얼마나 큰 의미가 있는지는 확인이 필요해보이네요... 지금 생각으로는 엄청 크지는 않아보여요) Classifier 의 결과를 LSGAN Loss 인 MSE 를 적용하기 위해 로 mapping 할 수 있는 Sigmoid Layer 를 넣은 모습을 보실 수 있습니다.
그 외에 위의 구현체에서 설명드리지 않은 DiscriminatorConvBlock 은 ResidualBlock 처럼 layers.py 에 구현되어 있는데, 아래의 토글에 해당 구현체가 있으니 원하시는 분들을 한 번쯤 보셔도 좋을 것 같습니다.
DiscriminatorConvBlock 구현체 보기
Feature Extractor
다음으로 FeatureExtractor 에 대해서 살펴봅시다. 논문리뷰에서 FeatureExtractor 의 역할에 대해서 소개드리지만, 간단하게 다시 설명드리자면 이미지의 지각적 특성을 반영할 수 있는 Feature 단에서 Loss 를 정의하는 것이 논문에서 제시한 방법론 중 하나였고 그것을 위해서 VGGNet 의 앞부분 feature extractor 를 차용하여 사용하게 됩니다.
class FeatureExtractor(nn.Module):
def __init__(self):
super().__init__()
vgg = vgg19(pretrained=True)
self.feature_extractor = nn.Sequential(*list(vgg.features.children())[0:36]) # VGG54
for param in self.feature_extractor.parameters():
param.required_grad = False
def forward(self, img):
return self.feature_extractor(img)
Python
복사
아래는 VGG-19 의 VGG54 feature 를 추출해내는 FeatureExtractor 를 정의한 것입니다. 특별히 언급할 점은 parameter 단에서 gradient 를 계산하지 않도록 설정한 부분을 추가하여 불필요한 연산을 줄였습니다.
데이터로더 구현하기
다음으로 진행할 단계는 Data Loader 를 구현하는 것입니다. Data Loader 를 구현하기 이전에 Dataset 을 정의해야 하며, 저는 dataset 으로 DIV2K dataset 을 사용했고, 아래의 링크에 들어가시면 어렵지 않게 데이터를 얻으실 수 있습니다.
여기서 Train Data (HR Images) 를 다운로드 받고 assets.py 에서 지정한 div2k_train_path 및 div2k_val_path 에 해당 데이터를 넣었습니다. assets.py 파일은 다음과 같습니다.
assets.py
이후 아래와 같이 dataloaders.py 에 DIV2KDataset 을 구현했습니다.
from glob import glob
import torch
import torchvision.transforms as transforms
from PIL import Image
from torch.utils.data import Dataset, DataLoader
from assets import div2k_train_path, div2k_val_path, DIV2KDatasetMode
class DIV2KDataset(Dataset):
hr_mean, hr_std = [torch.tensor([0.5, 0.5, 0.5]), torch.tensor([0.5, 0.5, 0.5])]
lr_mean, lr_std = [torch.tensor([0, 0, 0]), torch.tensor([1, 1, 1])]
def __init__(self, width, height, mode):
self.hr_width = width
self.hr_height = height
self.lr_width = width // 4
self.lr_height = height // 4
self.train_path = div2k_train_path
self.val_path = div2k_val_path
self.images = self.get_dataset(mode)
self.image_num = len(self.images)
self.hr_transform = self.get_hr_transform()
self.lr_transform = self.get_lr_transform()
self.original_hr_transform = self.get_original_hr_transform()
self.original_lr_transform = self.get_original_lr_transform()
def get_original_hr_transform(self):
return transforms.Compose([transforms.ToTensor()])
def get_original_lr_transform(self):
return transforms.Compose(
[
transforms.Resize(
size=(self.lr_height, self.lr_width), interpolation=transforms.InterpolationMode.BICUBIC
),
transforms.Resize(
size=(self.hr_height, self.hr_width), interpolation=transforms.InterpolationMode.BICUBIC
),
transforms.ToTensor(),
]
)
@staticmethod
def get_hr_transform():
return transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize(mean=DIV2KDataset.hr_mean, std=DIV2KDataset.hr_std),
]
)
def get_both_transform(self):
return transforms.Compose(
[
transforms.RandomCrop(size=(self.hr_height, self.hr_width)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(degrees=90),
]
)
def get_lr_transform(self):
return transforms.Compose(
[
transforms.Resize(
size=(self.lr_height, self.lr_width), interpolation=transforms.InterpolationMode.BICUBIC
),
transforms.ToTensor(),
transforms.Normalize(mean=DIV2KDataset.lr_mean, std=DIV2KDataset.lr_std),
]
)
@staticmethod
def get_reverse_normalize_transform():
return transforms.Compose(
[
transforms.Normalize(mean=[0, 0, 0], std=1 / DIV2KDataset.hr_std),
transforms.Normalize(mean=-DIV2KDataset.hr_mean, std=[1, 1, 1]),
]
)
def get_dataset(self, mode):
MODE_TO_DATASET = {
DIV2KDatasetMode.TRAIN: sorted(glob(self.train_path)),
DIV2KDatasetMode.VALIDATION: sorted(glob(self.val_path)),
}
return MODE_TO_DATASET[mode]
def __getitem__(self, index):
both_transform = self.get_both_transform()
image = both_transform(Image.open(self.images[index]))
hr_img = self.hr_transform(image)
lr_img = self.lr_transform(image)
original_hr_img = self.original_hr_transform(image)
original_lr_img = self.original_lr_transform(image)
return dict(hr=hr_img, lr=lr_img, original_hr=original_hr_img, original_lr=original_lr_img)
def __len__(self):
return self.image_num
Python
복사
특별히 언급드릴 점은 Low Resoultion Image 를 만들 때 BICUBIC interpolation 을 사용해 이미지의 크기를 줄인 점입니다. 그리고, 비교를 위해서 다시 BICUBIC interpolation 으로 이미지의 크기를 늘리면 자연스럽지 못하게 확장이 된 형태를 볼 수 있습니다. 아래는 예시입니다.

Low Resoultion Image

High Resolution Image
위 그림의 좌측 이미지를 Normalize 를 거쳐서 Generator 의 Input 으로 넣게 되고, 우측 이미지 또한 Normalize 를 거쳐서 Ground Truth 로 지정하여 학습을 진행하게 됩니다.
눈치채셨겠지만 위 DIV2KDataset 에서 정의된 각종 transform 들은 위에서 언급드린 normalization 및 위 그림처럼 Random Rotation, Horizontal Fip 및 Cropping 을 통한 data augmentation 효과를 보기 위한 메소드라고 보시면 됩니다. Tensorboard 로 실시간 학습 현황을 관찰하기 위해서 Normalization 이 되기 전 이미지를 위한 transform 및 generated image 를 un-normalize 하기 위한 transform 또한 정의되어 있는 것을 보실 수 있습니다.
이렇게 정의된 transform 은 이미지를 전달해주는 메소드인 __get_item__ 에서 사용되며, normalize 버전과 그렇지 않은 버전의 High Resoultion 및 Low Resolution 이미지를 모두 전달해주는 것을 보실 수 있습니다.
이렇게 정의한 DIV2KDataset 을 사용하여 아래와 같이 Data Loader 를 정의했습니다.
# dataloaders.py
DIV2KTrainDataLoader = DataLoader(
DIV2KDataset(height=256, width=256, mode=DIV2KDatasetMode.TRAIN),
batch_size=8,
shuffle=True,
num_workers=8,
)
DIV2KValDataLoader = DataLoader(
DIV2KDataset(height=256, width=256, mode=DIV2KDatasetMode.VALIDATION),
batch_size=8,
num_workers=8,
)
Python
복사
간혹 Batch Size 가 큰 경우 메모리 문제가 발생할 수 있으니 요 부분은 조절하셔서 사용하시길 바랍니다.
학습 구현하기
마지막으로 진행할 단계는 학습을 구현하는 것입니다. 이 부분은 이전에 소개드린 PyTorch-Lightning 을 사용해서 간단하게 진행해보았습니다.
import os
from datetime import datetime
import pytorch_lightning as pl
import torch.nn as nn
import torch.optim
from pytorch_lightning.utilities.types import EVAL_DATALOADERS, TRAIN_DATALOADERS
from torch.utils.tensorboard import SummaryWriter
from dataloaders import DIV2KTrainDataLoader, DIV2KValDataLoader
from models import Generator, Discriminator, FeatureExtractor
from utils import get_device
from assets import SR_RESNET_EPOCH, MODEL_SAVE_EPOCH_INTERVAL
MSELoss = nn.MSELoss()
device = get_device()
class SuperResolutionGAN(pl.LightningModule):
def __init__(self, is_train=True):
super().__init__()
train_id = f'{datetime.now().strftime("%Y_%m_%d_%H_%M_%S")}'
self.model_save_dir = f"./saved_models/{train_id}"
if is_train:
self.summary_writer = SummaryWriter(f"./logs/{train_id}")
self.generator = Generator(in_channels=3, out_channels=3, num_res_blocks=16, is_train=is_train)
self.discriminator = Discriminator(input_height=256, input_width=256, in_channels=3)
self.feature_extractor = FeatureExtractor()
self.generated_img = None
self.hr_img = None
self.lr_img = None
self.gen_loss = None
self.disc_loss = None
self.reverse_normalize = None
self.original_hr_img = None
self.original_lr_img = None
self.gen_gan_loss = None
self.content_loss = None
self.disc_real_loss = None
self.disc_fake_loss = None
def configure_optimizers(self):
generator_optimizer = torch.optim.Adam(self.generator.parameters(), lr=0.0001, betas=(0.9, 0.999))
generator_scheduler = torch.optim.lr_scheduler.StepLR(generator_optimizer, step_size=1000, gamma=0.2)
discriminator_optimizer = torch.optim.Adam(self.discriminator.parameters(), lr=0.0001, betas=(0.9, 0.999))
discriminator_scheduler = torch.optim.lr_scheduler.StepLR(discriminator_optimizer, step_size=1000, gamma=0.2)
return [generator_optimizer, discriminator_optimizer], [generator_scheduler, discriminator_scheduler]
def training_step(self, batch, batch_idx, optimizer_idx):
hr_img = batch["hr"]
lr_img = batch["lr"]
self.original_hr_img = batch["original_hr"]
self.original_lr_img = batch["original_lr"]
self.generated_img = generated_img = self.generator(lr_img)
# generator training process
if optimizer_idx == 0:
return self.generator_training_step(hr_img, generated_img)
# discriminator training process (SR Resnet pretrain when current epoch < SR_RESNET_EPOCH)
if optimizer_idx == 1 and self.current_epoch >= SR_RESNET_EPOCH:
return self.discriminator_training_step(hr_img, generated_img)
def generator_training_step(self, hr_img, generated_img):
generated_img_feature = self.feature_extractor(generated_img)
hr_img_feature = self.feature_extractor(hr_img)
mse_content_loss = MSELoss(generated_img, hr_img)
# SR Resnet pretraining process
if self.current_epoch < SR_RESNET_EPOCH:
self.content_loss = mse_content_loss
return mse_content_loss
self.content_loss = content_loss = 0.8 * mse_content_loss + 0.006 * MSELoss(
generated_img_feature, hr_img_feature
) # Custom MSE Loss to enhance hr and generated image similarity
discriminator_result = self.discriminator(generated_img)
self.gen_gan_loss = gan_loss = MSELoss(
discriminator_result, torch.ones_like(input=discriminator_result, device=device)
)
self.gen_loss = gen_loss = content_loss + 1e-3 * gan_loss
return gen_loss
def discriminator_training_step(self, hr_img, generated_img):
# Gaussian Noise scaling factor referenced by https://github.com/soumith/ganhacks/issues/14
scale_factor = 0.125 - 0.00005 * self.current_epoch if self.current_epoch < 2500 else 0
disc_generated = self.discriminator(
generated_img.detach() + scale_factor * torch.randn(size=generated_img.size(), device=device)
) # prevent back prop into generator
disc_hr = self.discriminator(hr_img + scale_factor * torch.randn(size=generated_img.size(), device=device))
gan_fake_loss = MSELoss(disc_generated, torch.zeros_like(input=disc_generated, device=device))
gan_real_loss = MSELoss(
disc_hr, torch.ones_like(input=disc_hr, device=device) - 0.1 * torch.rand_like(input=disc_hr, device=device)
) # kind of smoothing
self.disc_fake_loss = gan_fake_loss
self.disc_real_loss = gan_real_loss
self.disc_loss = disc_loss = (gan_fake_loss + gan_real_loss) * 0.5
return disc_loss
def validation_step(self, batch, batch_idx):
hr_img = batch["hr"]
lr_img = batch["lr"]
generated_img = self.generator(lr_img)
val_loss = MSELoss(generated_img, hr_img)
return val_loss
def train_dataloader(self) -> TRAIN_DATALOADERS:
train_dataloader = DIV2KTrainDataLoader
self.reverse_normalize = train_dataloader.dataset.get_reverse_normalize_transform()
return train_dataloader
def val_dataloader(self) -> EVAL_DATALOADERS:
return DIV2KValDataLoader
def on_train_epoch_end(self) -> None:
if self.current_epoch % MODEL_SAVE_EPOCH_INTERVAL == 0:
if not os.path.exists(self.model_save_dir):
os.makedirs(self.model_save_dir)
torch.save(
obj=dict(generator=self.generator.state_dict(), discriminator=self.discriminator.state_dict()),
f=f"{self.model_save_dir}/{self.current_epoch}th.pt",
)
original_lr_img, *_ = self.original_lr_img
original_hr_img, *_ = self.original_hr_img
generated_img, *_ = self.generated_img
self.summary_writer.add_images(
tag="lr-hr-generated",
img_tensor=torch.stack(
[
original_lr_img.squeeze(0),
original_hr_img.squeeze(0),
self.reverse_normalize(generated_img.squeeze(0)),
]
),
global_step=self.current_epoch,
)
self.summary_writer.add_scalar("gen_content_loss", self.content_loss.item(), self.current_epoch)
if self.current_epoch >= SR_RESNET_EPOCH:
self.summary_writer.add_scalar("gen_gan_loss", self.gen_gan_loss.item(), self.current_epoch)
self.summary_writer.add_scalar("gen_loss", self.gen_loss.item(), self.current_epoch)
self.summary_writer.add_scalar("disc_loss", self.disc_loss.item(), self.current_epoch)
self.summary_writer.add_scalar("disc_real_loss", self.disc_real_loss.item(), self.current_epoch)
self.summary_writer.add_scalar("disc_fake_loss", self.disc_fake_loss.item(), self.current_epoch)
Python
복사
코드의 길이를 보면 전혀 간단하지 않은데(..?) 라고 생각하실 수 있는데 각 메소드별로 살펴보면 크게 어렵지 않습니다.
training_step 메소드부터 살펴봅시다. 이 부분이 직접적인 training 과정을 명시해주는데 GAN 의 학습에서는 두 개의 네트워크를 학습해야 하기 때문에 optimizer 를 두 개 정의해야하고 정의한 optimizer 의 순서대로 학습을 진행하게 됩니다. 즉, optimizer_idx 가 0 일 때, configure_optimizers 에서 반환하는 0 번째 index 의 optimizer 로 인한 weight update 가 이루어지고 optimizer_idx 가 1 일 때 configure_optimizers 에서 반환하는 0 번째 index 의 optimizer 로 인한 weight update 가 이루어진다고 보시면 됩니다.
여기까지 오시면 Generator 의 학습과 Discriminator 의 학습을 각각 optimizer_idx 0 과 1 로 나누어 구현하면 되는구나! 라고 생각이 드실 것입니다. 여기서 더 나아가서 구현된 내용 중에 SR_RESNET_EPOCH 이라는 친구가 있는데 이 친구는 Generator 부분만 학습하는 epoch 의 수라고 보시면 됩니다. 초기 일정 epoch 동안은 SR-ResNet 의 구조를 차용한 Generator 만 학습하게 되는데 이는 처음부터 GAN Loss 를 두어 학습하게 되면 불안정하여 Global Minima 에 도달하기 어렵기 때문입니다.
이제 각각의 generator_training_step 과 discriminator_training_step 을 살펴봅시다.
generator_training_step 에서 특별하게 관찰할 수 있는 점은 현재의 epch 이 SR_RESNET_EPOCH 보다 작은 경우에는 SR-ResNet 부분을 pretraining 하는 과정이기 때문에 GAN Loss 부분을 사용하지 않는다는 점입니다. 더불어 SR_RESNET_EPOCH 이후에는 Feature Extractor 로 뽑아낸 feature 에 대한 MSE loss 를 정의하게 되는데 매우 큰 SR_RESNET_EPOCH (~ 10,000) 를 지정하지 않을 것이라면 SR_RESNET_EPOCH 이후에도 Generated Image 와 High Resolution Image 에 대한 직접적인 MSE Loss 를 포함하는 편이 이미지의 괴리감을 줄이는데 큰 도움이 되는 것을 확인하여 커스텀하여 사용했습니다. 다른 부분은 논문과 동일하여 특별하게 설명하지는 않겠습니다.
discriminator_training_step 에서 특별하게 관찰할 수 있는 점은 Gaussian Random Noise 를 High Resolution Image 와 Generated Image 에 첨가하여 Discriminator 네트워크를 통과시켰다는 점입니다. 이는 Tensorboard 의 loss 그래프 상으로 discriminator loss 가 빠르게 0으로 수렴하여 discriminator 를 penalize 하여 generator 가 좋은 퀄리티의 이미지를 생성할 기회를 주려는 시도입니다.
마무리
이렇게 SRGAN 을 처음부터 끝까지 구현 및 디벨롭해보았습니다. 사실 아직도 부족한 점이 많아 디벨롭해야 하지만, 현재 코드의 구현체 상으로 학습 과정에서 Tensorboard 에 기록된 결과물은 아래와 같습니다.

좌(Low Resolution Image) - 중(High Resolution Image) - 우(Super Resolution Image)

좌(Low Resolution Image) - 중(High Resolution Image) - 우(Super Resolution Image)

좌(Low Resolution Image) - 중(High Resolution Image) - 우(Super Resolution Image)

좌(Low Resolution Image) - 중(High Resolution Image) - 우(Super Resolution Image)