본 포스트에서는 Super Resolution 분야에서 새로운 방법론을 제시한 논문에 대해서 소개드리려고 합니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network”

Objective
Super Resolution 은 저해상도의 이미지로부터 해당 이미지의 고해상도 버전을 예측해냄으로써 해상도를 증가시키는 task 입니다. 간단히 부연설명을 하자면 이미지를 확대할 때 확대된 영역에서 부족해지는 데이터를 자연스럽게 손실 없는 것처럼 채워넣는 task 라고 보시면 됩니다. 일반적인 방법으로는 linear, bicubic interpolation 또는 pooling 등이 있는데 인간이 보기에 자연스러운 해상도 증가를 표현해주지는 않습니다.
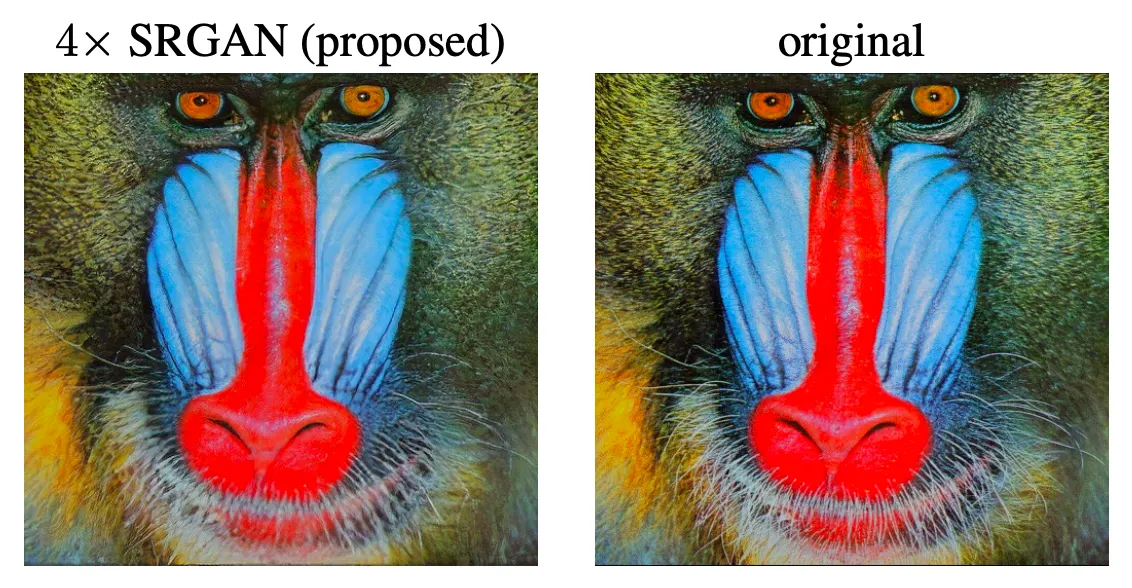
기존 Super Resolution 연구 분야에서 깊고, 빠른 Convolutional Neural Network 를 사용하면서 어느정도의 정확도와 속도를 챙길 수 있었지만, 높은 upscaling factor 에 대해서 예측해낸 고해상도의 이미지에서 섬세한 이미지의 디테일까지 챙길 수는 없었습니다.

특히나, 기존의 Convoultional Neural Network 에서 고전적으로 사용하던 PSNR 같이 pixel-wise MSE 를 활용하는 Loss function 으로는 이미지의 지각적 특성을 반영할 수 있는 능력이 떨어졌다고 합니다. 이는 위의 사진으로도 어느정도 관찰할 수 있는데, PSNR 이 높은 SRResNet 에 비해 PSNR 이 낮은 SRGAN 의 결과가 original 에 비해서 조금 더 깔끔하고 부드러워 보이는 결과를 산출했습니다.
논문에서는 위와 같이 Upscaling Factor 가 높은 상황에서 photo-realistic 한 이미지를 생성하지 못하는 기존의 네트워크들을 보완했습니다. 에 해당하는 upscaling factor 를 처음으로 구현해냈고 이를 달성하기 위해 SRGAN 이라는 새로운 구조의 네트워크를 제안했습니다. 그리고 해당 네트워크를 학습하는데 있어 이미지의 지각적 특성을 반영할 수 없는 기존의 PSNR 에서 벗어나 새로운 Perceptual Loss 를 제안했습니다.
Single Image Super Resolution
Single Image Super Resolution (SISR) 의 목적은 저해상도의 이미지 로부터 고해상도의 이미지 를 산출해내는 것입니다. 학습에 사용될 은 준비한 고해상도의 이미지인 에 gaussian filter 를 적용한 뒤에 만큼의 factor 를 사용하여 downsampling 하여 얻어낼 수 있습니다.

Gaussian Filter 란?
대표적인 Blurring 기법 중 하나로, 이미지 픽셀 값을 새롭게 정의할 때 주변의 값들을 포함한 범위를 Gaussian Filter 를 통과시켜 얻는 방법입니다. Mean Filter 에 비해서 중앙 값 (대상 픽셀) 의 값에 가중치가 커서 조금 더 Smooth 한 결과를 가져온다고 알려져 있습니다.
때문에 학습 데이터로 사용할 이 라면, 은 입니다.
이렇게 학습 데이터를 정의한 뒤 논문에서는 SISR 를 구현함에 있어 Generator 네트워크 를 사용한다고 합니다. 이 때 는 예상하시다시피 Generator 네트워크의 weigth 입니다. 이 값은 SISR 에 특화된 Loss Function 인 를 통해 학습한다고 합니다. 이렇게 Loss Function 을 함수화했을 때 논문에서 구하고자 하는 는 다음과 같은 수식을 통해 얻어집니다.
특별한 내용은 없습니다. 단순히 loss 를 최소화한다는 weight 를 찾는다는 식일 뿐이고, 논문에서는 다음 세션에서 해당 에 대해서 특별하게 설명을 합니다. 여기서는 해당 loss 를 정의할 때 과 Generator 가 생성한 이미지인 를 사용한다- 정도만 보고 넘어가셔도 충분하실 것 같습니다.
Adversarial Network Architecture
앞서 정의한 에 대한 설명을 하기 이전에 논문에서는 Goodfellow et al. 의 GAN 구조를 차용하여 만든 논문의 네트워크 구조에 대해서 소개합니다. GAN 에서는 Generator 와 Discriminator 가 존재하여 두 네트워크가 min-max problem 을 풀도록 설계되어 있습니다.
자세한 사항은 GAN 논문리뷰를 참고해주시면 감사하겠습니다. 여기서는 간단하게 Discriminator 는 해당 식을 최대화하는 것을 목표로 학습이 진행되어 Generator 가 생성한 이미지가 진짜 High Resolution Image 인지 생성된 가짜 High Resolution Image 인지를 구별해는 능력을 학습하게 되고, Generator 해당 식을 최소화하는 것을 목표로 학습이 진행되어 생성한 이미지가 Discriminator 를 속일 수 있는 능력을 학습하게 됩니다. 이렇게 경쟁적으로 학습이 진행되면서 Generator 가 생성하는 이미지가 High Resolution Image 와 구별되지 못할 정도로 완성도 있는 모습이 나오게 되는 결과가 나오는 것입니다.
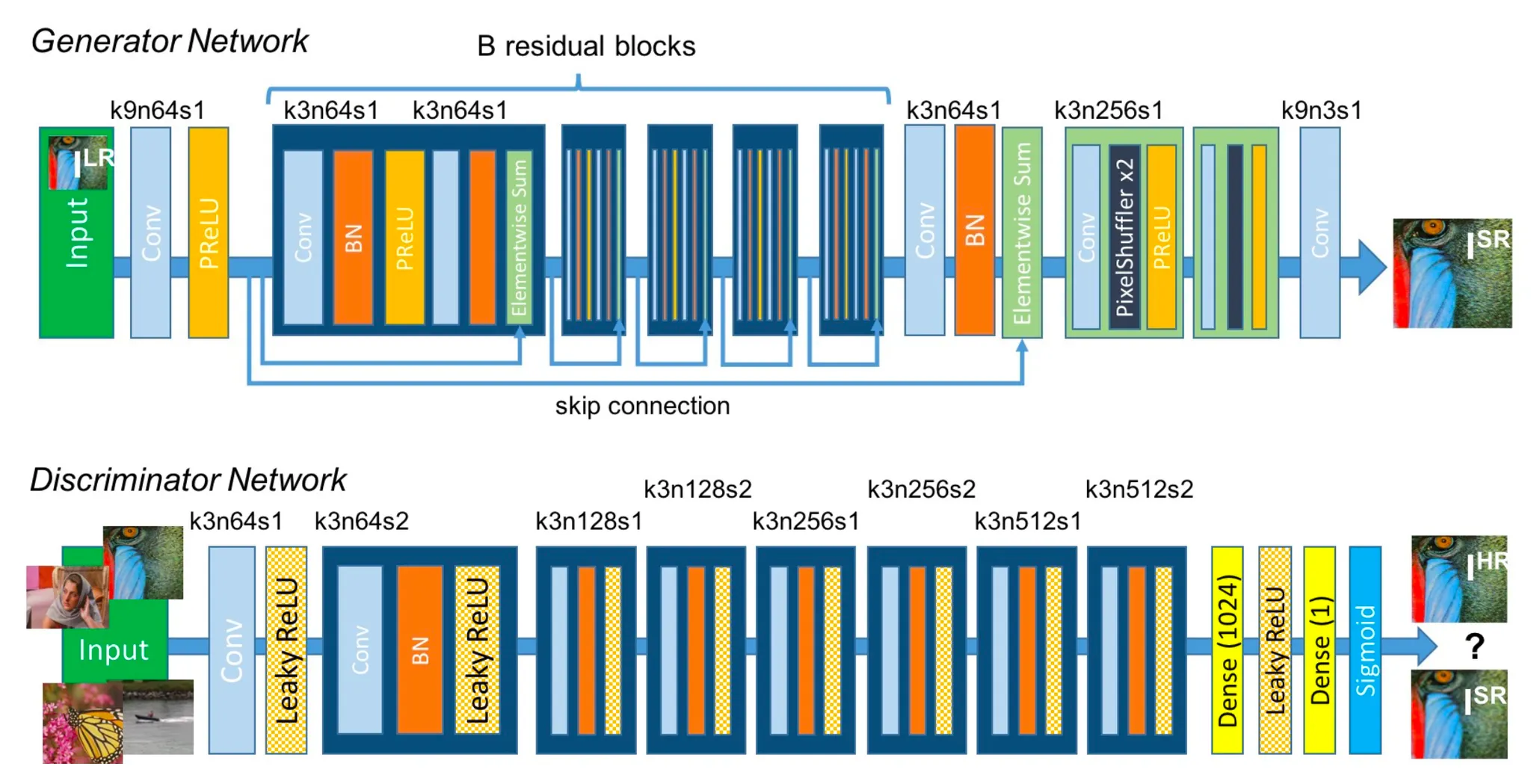
최종적으로 논문에서 위의 식을 바탕으로 위와 같은 Generator 및 Discriminator 구조를 설계합니다. 세부 사항은 다음과 같습니다.
Generator
1.
Conv - Batch Norm - ParametricReLU 로 반복되는 B개의 residual blocks 존재
2.
residual blocks 뒤의 2개의 Conv - PixelShuffle - ParametricReLU 로 2 배씩 2 번 resolution 증가
3.
마지막 Conv 를 지나고 최종 이미지 산출
Discriminator
1.
Radford et al. 의 구조를 따름
2.
8 개의 Conv - Batch Norm - Leaky ReLU 의 구조를 따르고, 첫 번째만 Batch Norm 이 없음
a.
점진적으로 Channel 수가 2 배가 되는 구조
b.
Stride 2 인 Conv 를 지날 때마다 feature map 의 크기는 줄어듬
3.
Dense Layer 2 개를 지나고 최종 판정 결과 산출
Perceptual Loss Function
논문에서는 앞서 언급한 이미지의 지각적 유사도의 측면을 반영하기 위해서 기존의 MSE 가 기반이 된 다른 논문들과는 차별적으로 Peceptual Loss Function 을 제시합니다.
위처럼 Content Loss 인 과 Adversarial Loss 인 의 weighted sum 형태로 최종적인 Perceptual Loss 를 정의합니다. 이는 Generator 의 학습에만 사용되는 Loss 입니다.
Content Loss
Content Loss 는 기존의 MSE 기반의 loss 와 비슷합니다. 하지만, 앞서 논문에서는 MSE loss 가 peceptual similarity 를 capturing 하지 못하는 단점이 있다는 것을 제시했습니다. 때문에 이런 이미지의 perceptual similarity 에 가까운 context 를 사용해 MSE loss 를 정의하려고 했고, 그러한 시도로 진행한 것이 VGGNet 의 feature extractor 부분을 사용하여 feature 단에서 MSE loss 를 비교한 것입니다.
위 식에서 는 VGG19 Network 의 번쨰 maxpooling layer 이전의 번째 convolution 연산 이후로 나오는 feature map 결과라고 보면 됩니다. 즉, ground truth 인 과 생성한 이미지인 을 각각 VGG19 Network 의 특정 지점까지 통과시킨 후 나온 feature map 단에서 MSE loss 를 구했다고 보시면 됩니다. 이에 대한 구체적인 이유는 표기되어 있지는 않지만 Upsampling 이전의 압축된 특성으로 loss 를 정의하는 쪽이 조금 더 이미지의 세부 디테일 유사도에 도움이 되지 않았나- 하는 간단한 생각이 있습니다.
Adversarial Loss
Adversarial Loss 는 GAN 에서 제시한 loss 와 비슷합니다. 다만 한 가지 차이점은 1 에서 뺀 값을 사용하지 않았습니다. 논문에서는 이를 better gradient behavior 를 위했다- 라고 표현하고 있습니다.
논문에서는 따로 Discriminator 의 Loss 에 대해서는 언급하고 있지는 않은데 실제 구현체를 본 결과 기본적인 GAN Loss 와 동일하게 가져가는 것으로 보입니다. 논문에서 novelty 를 주장하고자하는 loss function 에 대한 언급만 한 것으로 보입니다.
Experiments
논문에서는 제시한 방법론이 유의미하다는 것을 보이기 위해 다음과 같은 실험을 진행했습니다.
Mean Opinion Score (MOS) testing
Mean Opinion Score 는 지정된 rater 가 각각의 네트워크가 reconstruct 한 이미지가 얼마나 지각적으로 설득력이 있는지 (고해상도처럼 보이는지) 에 대한 값을 매긴 것의 평균이라고 보시면 됩니다. 각각의 rater 들은 서로 다른 네트워크들이 산출한 이미지에 대해서 1 (Bad Quality) 부터 5 (Excellent Quality) 까지의 값을 매기게 됩니다.
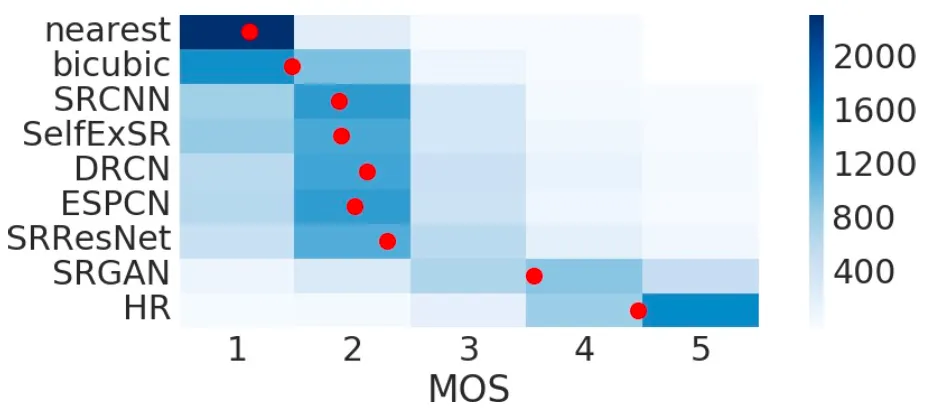
위의 결과는 BSD100 데이터셋으로 학습한 네트워크에 대한 실험 결과입니다. Ground Truth 인 HR 이 제일 고해상도로 그럴듯하다고 평가받았고, 그 다음에 이어서 논문의 SRGAN 의 결과물이 순위를 차지했습니다. NN, Bicubic 등의 고전 interpolation 방법론이 가장 별로라고 평가되었고 그 사이를 기존의 MSE 기반의 방법론들이 차지했습니다.
Investigation of Content Loss
다음으로 논문에서는 Content Loss 에서 선택할 수 있는 요소들에 대한 실험을 진행합니다. 앞서 로 명시된 부분의 선택에 따른 결과의 변화를 분석한 것이라고 보시면 됩니다.
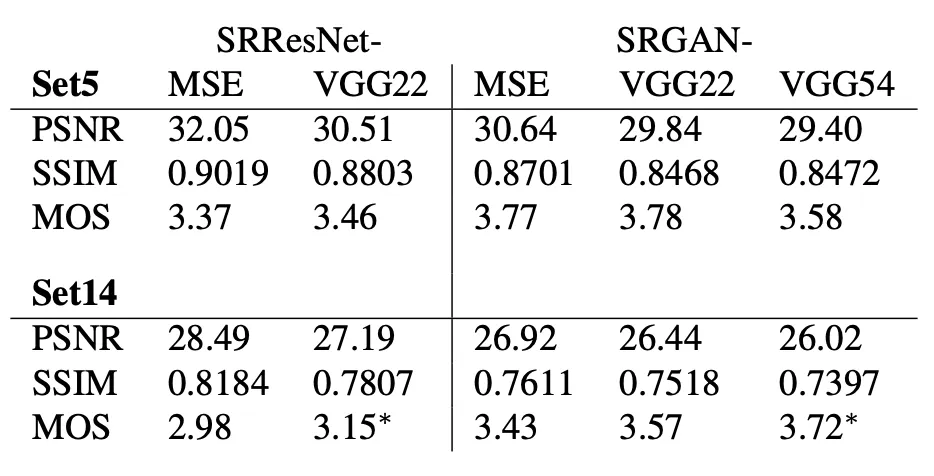
SRGAN-MSE, SRResNet-MSE 에서 보이는 PSNR 과 SSIM 값이 높은 것으로부터 VGG 를 사용하지 않은 버전들이 확실히 MSE based loss 에서 우위를 점하는 것을 확인할 수 있었습니다. 이 부분에 대한 구체적인 설명이 논문에 나와 있지는 않지만 이는 학습의 Loss 와 Evaluation Metric 이 동일시 되었기 때문이 큰 요소가 아닐까 생각하고 있습니다.
더불어 MOS metric 에 대해서는 Content Loss 에 VGG 를 적용한 버전이 높은 경향을 보였습니다. 특히 Set 14 dataset 의 VGG54 네트워크는 MOS 관점에서 다른 네트워크에 비해 압도적인 성능을 보였고 해당 관점으로 볼 때 high level 에서 진행한 feature extraction 이 texture detail 을 챙기는데 도움이 되었다는 사실을 알아낼 수 있었다고 합니다.

위의 사진은 논문에서 제시한 정성적인 분석 사진입니다. 확실히 SRResNet 보다는 GAN 을 도입하여 MSE Loss 만으로 capturing 할 수 없었던 이미지의 지각적 특성을 얻어내고자 한 SRGAN-MSE 가 더 선명한 형태를 보였고, SRGAN-MSE 보다는 VGG 를 활용해 이미지의 압축된 정보를 가지고 MSE Loss 를 설계한 SRGAN-VGG22, SRGAN-VGG54 가 디테일에서 우세한 것을 볼 수 있습니다. 더불어 high level 에서 feature extraction 을 하는 것이 조금 더 섬세한 디테일을 뽑아낼 수 있다는 것을 눈으로 볼 수 있었다고 합니다.
Performance of the Final Networks
마지막으로 논문에서 모든 Set5, Set14, BSD100 dataset 에 대해 모든 metric 으로 SRResNet, SRGAN, 그리고 interpolation 방법론과 다른 4 개의 SOTA Network 를 평가한 지표를 제공합니다.
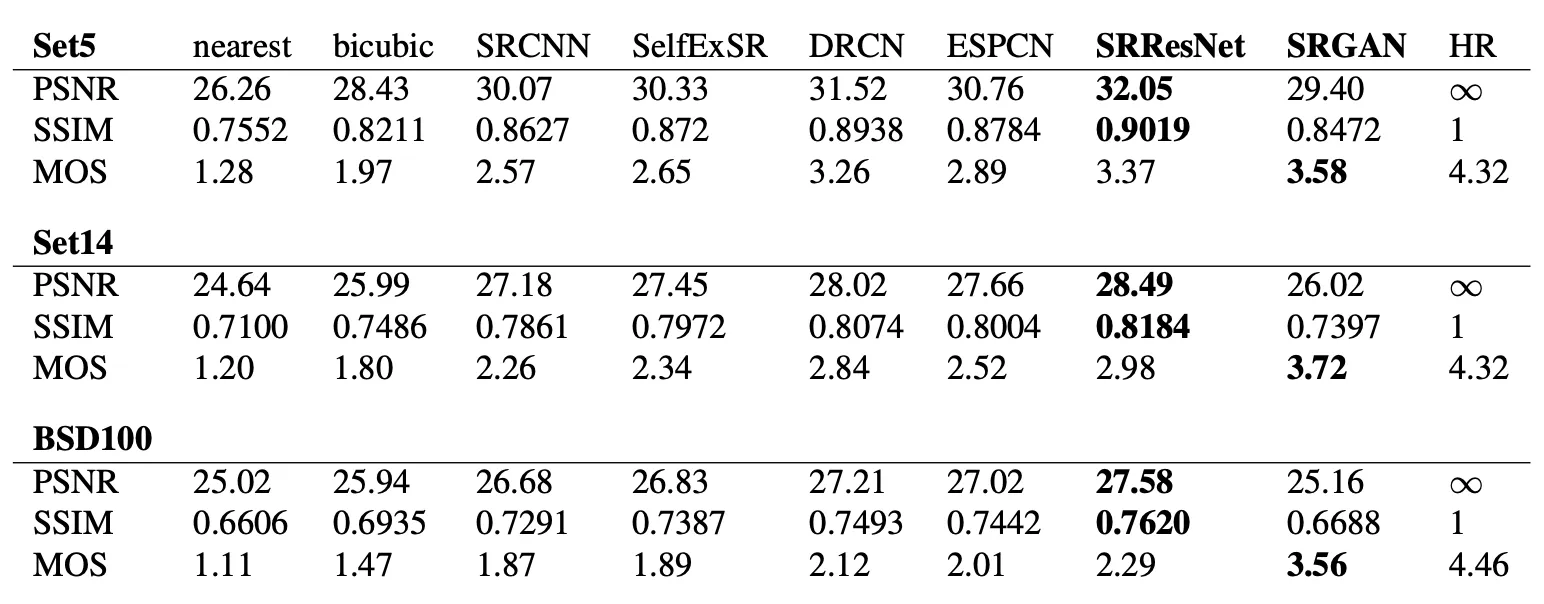
논문에서는 SRResNet 은 PSNR, SSIM 의 metric 에서 SOTA 를 달성했고, SRGAN 은 MOS metric 에서 SOTA 를 달성했다는 것을 알려줍니다. 특히나 BSD100 dataset 에서의 SRGAN 의 MOS 는 압도적인 차이를 가지고 SOTA 를 달성했습니다.
Conclusion
이것으로 논문 “Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network” 의 내용을 간단하게 요약해보았습니다.
Super Resolution 관련 분야에 대해 아는 것이 별로 없어서 최근에 조사를 하다가 MSE based 방법론이 주된 시점에서 GAN based 방법론을 제시한 첫 논문이라고 해서 관심있게 읽었던 논문이었던 것 같습니다. 요번 논문은 디테일까지 포함해서 읽지는 않았고, 내용 자체도 어렵지 않아서 쉽게 읽혔던 것 같습니다.
하지만 PSNR 로만 치면 현재 SOTA 는 SRResNet 보다도 훨씬 많은 네트워크가 나온 현재 시점(2022년 3월) 이기에 해당 논문들도 나중에 한 번 살펴봐야 할 것 같습니다.