Note Taking
Note Taking
CS231n 은 image classification 위주로 강의가 진행될 것
Data-Driven Approach ?
•
기존의 classification 은 edge detection + @ 의 방식을 사용
◦
물체를 바꿀 때마다 알고리즘을 재작성해야 함 (lack of robustness, brittle)
◦
Non-scalable approach
•
겁나 많은 데이터 + Machine Learning 을 사용한 classification approach
Nearest Neighbor ?
•
처음 등장한 classifier
•
train step 에 모든 training data 를 memorize
•
predict step 에 memorize 한 데이터와의 유사도로 classify
•
K-Nearest Neighbors
◦
K=1 → 가장 가까운 이웃의 class 로 classify
◦
K≥3 → 가장 가까운 K 개의 이웃 집합의 최대 빈도 class 로 classify
◦
빈 공간(white region) ? 최대 빈도 class 가 1개가 아닐 경우
데이터와의 유사도를 나타나는 metric ?
•
L1 Distance
◦
•
L2 Distance
◦
Hyperparameters ?
•
K-Nearest Neighbors 에서의 K 나 metric (L1, L2) 의 선택
•
해보고 가장 좋은 hyperparameters 를 선택하는 것이 일반적
Setting Hyperparameters ?
•
Training data 에서 가장 좋은 성능을 보인 Hyperparameter → X
•
Data 를 train/test 로 나눈 후 test data 에서 가장 좋은 성능을 보인 Hyperparameter → X
•
Data 를 train/validation/test 로 나눈 후 validation 에서 가장 좋은 성능을 보인 Hyperparameter 를 선택 후에 test 로 최종 성능 검증 → O
•
Cross-Validation ?
◦
Test data 를 정해둔 후, 나머지 데이터를 몇 개의 fold 로 나눔
◦
나눈 fold 중 validation set 으로 사용한 fold 를 바꾸어가면서 어떠한 fold 를 validation set 으로 사용해도 좋은 성능을 보이는 Hyperparameter 를 선택 (robust 한 hyperparameter 의 선택)
K-Nearest Neighbor on images never used !!
•
L1, L2 distance 가 실제로 이미지의 유사도를 나타내주지 않음

위 사진들 중 2, 3, 4번째 사진들은 실제로 original 과의 L2 distance 차이가 동일하나 이미적으로 굉장히 다름....
•
이미지에 적용하기엔 굉장히 느림 (이미지 픽셀을 다 돌아가면서 차이의 제곱을 하고 있어야 함...)
◦
3-Dimension 이기에... (RGB 까지!)
Parametric Approach - Linear Regression
•
image → → class scores
•
- simplest function
◦
dimension ?
Linear Classifier
•
특정 물체인지 아닌지 구별 with Linear Regression
•
특정 물체인지 아닌지 구별하는 선형 초평면의 합 형태로 최종 다중 classifier 구별
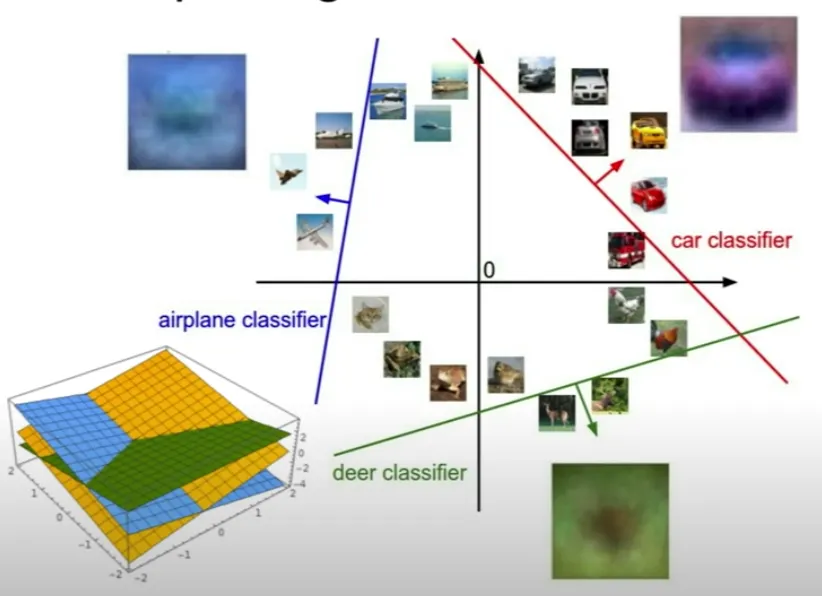
•
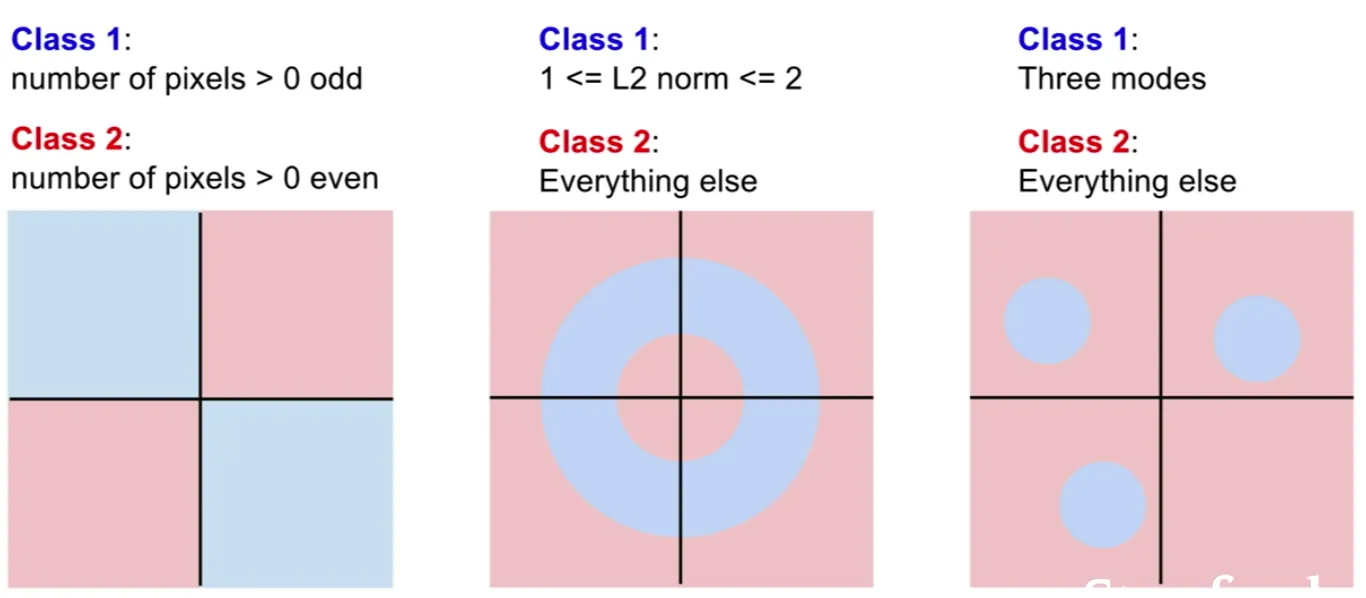
Linear Classification 이 어려워 하는 문제들 ?