
본 포스트에서는 ViT Features 에 대한 고찰을 바탕으로 Semantic Appearance Transfer 를 구현해낸 논문에 대해서 소개드리려고 합니다.
“Splicing ViT Features for Semantic Appearance Transfer”

Objective
Visual Appearance Transfer 는 Semantic Relation (의미적 유사도) 이 있는 두 개의 이미지 (source, target) 를 입력으로 받아 source image 의 구조 (structure, content) 를 유지한채 target image 의 visual appearance (texture, style) 를 가지는 이미지를 생성하는 task 입니다.

Visual Appearance Transfer
위 그림은 Visual Appearance Transfer 의 다양한 결과물들입니다. 한 예시로 좌측 상단의 그림을 보시면 강아지의 얼굴에 해당하는 의미를 가지는 부분에 대해서는 하얗고 갈색을 띄는 외관이, 배경 부분에 대해서는 가로 줄이 있는 흰색 외관 정보가 잘 전이되면서도 전체적인 강아지의 구조 자체는 유지한 형태의 결과물이 나타남을 알 수 있습니다.
이와 비슷한 선행연구로 Neural Style Transfer 가 있었고 이는 VGGNet 과 같은 pre-trained 된 모델의 feature extractor 를 prior 로 사용하여 style 을 추출하고 전이하는 방법론을 사용했습니다. 하지만 이러한 방법론은 이미지 전체의 global artistic style 만을 전이할 수 있었고 이미지 상에서 의미적 유사도가 있는 부분들에 대한 구별 및 로컬 영역에 대한 세부적인 전이가 가능하지는 않았습니다.
논문에서는 이러한 상황에서 Image Retrieval, Object Segmentation, Copy Detection 등 다양한 downstream task 에 활용되어 인상적인 결과를 남긴 강력한 prior 인 DINO-ViT 의 Encoder 를 활용하여 Appearance 와 Structure 에 대한 정보를 추출하려는 시도를 통해 이를 극복하고자 합니다.
Method
논문에서는 Source Structure Image 인 와 Target Appearance Image 인 가 입력으로 들어 올 때 의 구조를 가지면서 의 외관을 가진 최종적인 Output Image 를 생성하는 것을 목적으로 합니다. 이를 위해 앞서 잠깐 언급했던 DINO-ViT 의 encoder 를 prior 로 사용했고, encoder 의 특정 feature 를 추출하는 형태로 loss 를 선언하여 generator 를 학습하게 됩니다.
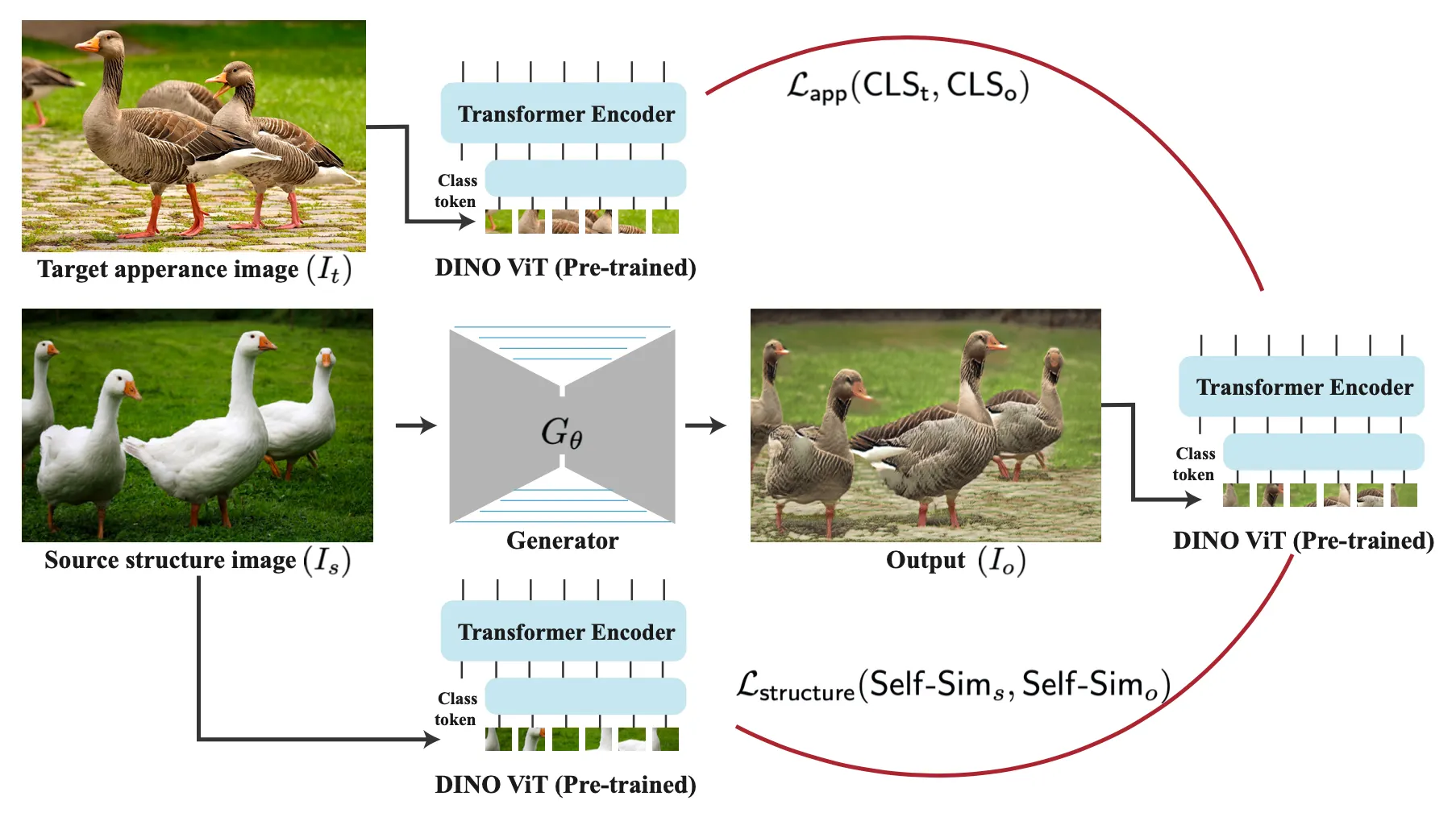
Method Pipeline
입력으로 받은 와 각각에서 DINO-ViT 의 encoder 를 거쳐서 뽑아낸 feature 와, generator 를 지나 생성된 이미지를 동일하게 DINO-ViT 의 encoder 를 거쳐서 뽑아낸 feature 와의 similarity 를 계산하고 이를 최대화하는 형태로 generator 를 학습하게 되는 형태입니다. 사실 여기까지만 이해하더라도 전체적인 논문의 방법론은 이해하셨다고 보셔도 됩니다.
Vision Transformers: Overview
논문에서는 그들의 방법론에 대한 세부적인 이해를 돕기 위해서 기본적인 Vision Transformer (이하 ViT) 의 원리에 대해서 간략하게 설명합니다. 본래 Transformer 는 문장과 같은 sequential data 에 사용되는 방법론으로 이러한 데이터들의 선후 관계를 반영한 효과적인 embedding 방법으로 주목받고 있었습니다. ViT 는 이러한 아이디어를 이미지에도 적용한 방법론입니다.
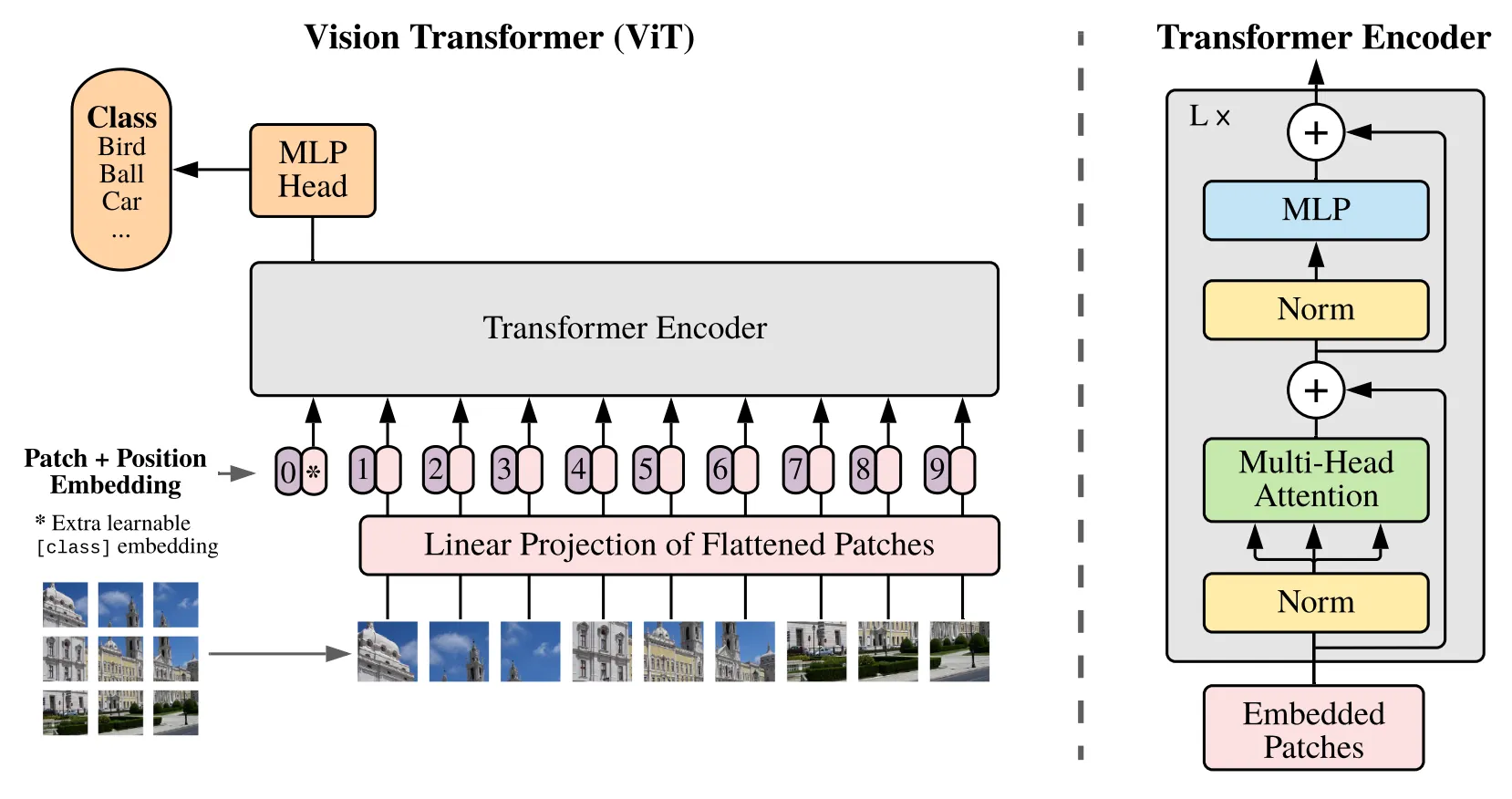
ViT Model Overview
ViT 논문에서 가정한 상황은 의 입력 이미지와 의 patch 크기입니다. 입력 이미지를 겹치지 않게 해당 크기의 patch 로 나누게 되면 , 총 196 개의 patch 가 생겨납니다. 이 patch 이미지 각각을 flatten 하면 인 768 의 크기를 가지는 1D vector 가 생겨나고, 총 196 개의 patch 가 있었기 때문에 최종적으로는 크기의 embedding 이 1차적으로 생깁니다.
이렇게 생겨난 embedding 을 linear projection (Linear or Conv + Rearrange) 하여 세팅에 관계없이 동일한 크기 를 가지도록 변경합니다. 여기서 동일하게 을 활용하게 되면, 크기 변화 없이 크기의 embedding 이 2차적으로 생깁니다.
여기에 BERT 에서 사용한 것과 같은 [CLS] token 을 넣어주게 되는데, BERT 에서 이를 class 에 대한 정보를 예측하는 학습 가능한 parameter 로 사용한 것과 같이 ViT 에서는 이미지의 global 표현에 대한 정보를 담고 있는 학습 가능한 parameter 로 취급합니다. 이는 patch 하나로 취급하는 위치에 따로 놓이게 되며 최종적으로 의 크기를 가지게 변경됩니다.
마지막으로 각 patch 의 위치에 대한 정보를 담고 있는 학습 가능한 parameter 인 positional embedding 을 추가하게 됩니다. 이는 앞선 embedding 과 동일한 크기의 의 벡터이며 각 embedding 에 추가적으로 positional 정보가 같은 크기로 붙은 형태라고 보실 수 있습니다. 이렇게 최종적으로는 2 개의 크기의 벡터를 transformer encoder 에 입력으로 넣게 됩니다.
이후의 과정은 Normalization Layers (LN) 과 Muli-head Self-Attention (MSA) modules 및 MLP block 으로 구성된 Transformer Encoder 를 L 번 통과하는 것인데, 다음과 같은 식으로 나타내어지게 됩니다.
위 식의 는 이미지 하나에 대한 번째 Transformer Encoder 의 output token 이라고 보면 되며 아래와 같이 나타내어 집니다. 위에 예시로 설명드린 formulation 에 따르면 아래 식의 이 됩니다.
더불어 MSA 같은 경우에는 Self-Attention 에 대한 이해가 필요하지만, 간략히 언급하자면 각 나눠진 patch 별로 얻어낸 벡터에 학습 가능한 parameter 인 query weight, key weight, value weight 를 matrix multiplication 하여 query, key, value 를 얻어내고, 최종적인 embedding 을 본인의 query 와 다른 patch 들의 key 에 대한 matrix multiplication 에 key vector size 의 제곱근만큼을 나누어준 뒤 softmax 한 것에 value 를 matrix multiplication 한 값으로 정의하는 방법론이라고 보시면 됩니다.
논문에서 사용하는 DINO-ViT 는 self-distillation 방법론을 이용해 학습한 ViT 라고 볼 수 있는데, 이는 같은 이미지의 다른 augmentation 인 두 이미지를 입력으로 넣어 같은 분포로 매핑되게끔 학습한다고 합니다. 일반적으로 supervised ViT 에 비해서 noisy 한 정도가 적고 더 semantic 하게 의미있는 visual representation 을 학습할 수 있다고 알려져 있습니다.
Structure & Appearance in ViT’s Feature Space
논문의 방법론의 핵심은 DINO-ViT 의 feature space 로부터 유의미한 외관 (이하 Appearance) 와 구조 (이하 Structure) 에 대한 정보를 추출하는 것입니다.
특히나, Appearance 같은 경우에는 정확한 물체의 위치 및 방향이나 장면의 구조적 레이아웃과 같은 요소들을 포함하고 있지 않으면서도 전체적인 style 정보를 포함하고 있어야 했습니다. 이를 위해서 논문에서는 앞선 ViT 구조에서 사용한 [CLS] token 을 통과시켜 얻은 벡터를 Appearance 를 나타내는 벡터로 사용하게 됩니다.
Structure 같은 경우에는 반대로 로컬 영역의 texture pattern 등에 영향을 받지 않고 전체적인 레이아웃, 형태, 인식된 물체와 배경의 의미 등을 해치지 않고 보존해야 했습니다. 이를 위해서 논문에서는 DINO-ViT 의 각 patch 에서 추출한 key 를 기반으로 cosine similarity 정의하여 Structure 를 나타내는 벡터로 사용하게 됩니다. 이 항목을 Self-Similarity 라고 합니다.
위 항목 는 번째 patch 와 번째 patch 의 key 간의 cosine similarity 를 row , column 번째 행렬의 값으로 가지는 벡터입니다. 때문에 의 크기를 가지게 됩니다. 이렇게 Self-Similarity 를 사용하여 structure 정보를 얻어내는 것은 고전적인 방법론 및 딥러닝을 활용하는 Neural Style Transfer 에서도 사용된 테크닉이며, 이를 구성하기 위해 ViT 의 구성요소 중 유독 key 를 사용한 것은 Amir et al. 의 연구결과를 차용했다고 합니다.
Understanding and visualizing DINO-ViT’s features
논문에서는 실제로 DINO-ViT 의 feature 로부터 얻어낸 정보에 대한 이해를 위해 Feature Inversion 접근방법을 사용합니다. 이는 특정 이미지를 DINO-ViT 의 encoder 를 통과시켜 특정 layer 에서 얻어낸 feature 를 기준으로 이 정보만을 prior 로 하여 새롭게 이미지를 재구성하려는 시도를 한 것입니다.
하지만, 기존 CNN 에서 진행했던 비슷한 사례들은 이미지 픽셀 자체를 optimizing 하는 것은 의미있는 결과물로 수렴하기 어렵다는 사실을 알려주었고, 논문에서는 random noise 를 입력으로 주었을 때 이미지를 재구성하는 CNN 인 를 구성하였고, 이 결과로 생성된 이미지인 를 DINO-ViT 를 통과시켜 얻은 Feature 가 앞서 얻어낸 prior feature 와 비슷해지도록 학습을 진행합니다.
위 식에서 는 DINO-ViT 의 앞부분부터 특정 layer 까지를 잘라낸 feature extractor 라고 보시면 됩니다.
실제로 논문에서는 Appearance 를 정보를 나태내는 벡터로 사용하기로 한 [CLS] token 과 key vector 에 대한 Feature Inversion 결과를 제시합니다.
Feature Inversion of [CLS] Token
먼저 논문에서는 Appearance 를 정보를 나태내는 벡터로 사용하기로 한 [CLS] token 에 대한 Feature Inversion 결과를 제시합니다.

[CLS] token Inversion Results
위 그림의 첫 번째 행은 입력으로 넣은 이미지를, 아래 행은 Feature Inversion 을 통해 얻어낸 이미지를 나타냅니다. 얕은 layer 들은 로컬 영역의 texture pattern 정보를 가지고 있는데 그친 반면, 깊은 layer 는 global information 을 가지고 있었습니다. 논문에서는 이를 통해 깊은 layer 로 갈 수록 [CLS] token 이 점진적으로 Appearance 에 대한 올바른 정보를 가지게 됨을 보여주었습니다.

[CLS] token Inversion over Multiple Runs
더불어 같은 이미지를 입력으로 하되 입력 noise 를 달리했을 때의 결과를 제시합니다. 그 결과, Appearance 정보가 유지된 채 Structure 가 달라보이는 다양한 이미지가 생성되었고, 이를 통해 [CLS] token 이 구조적 자유도를 배제한 Appearance 정보를 가지고 있음을 보여주었습니다.
Feature Inversion of Key Vector
다음으로 논문에서는 Structure 정보를 나태내는 벡터로 사용하기로 한 Key Vector 에 대한 Feature Inversion 결과를 제시합니다.

Visualization of DINO-ViT Keys
위 그림의 첫 번째 행은 마지막 (11 번째) layer 의 결과로 나온 key vector 를 Structure 를 나타내는 벡터로 취급하여 로 구성하여 얻어낸 이미지입니다. 놀랍게도 이 key vector 만으로 논문에서는 기존 이미지를 완벽하게 복원해낼 수 있음을 확인할 수 있었습니다.
다만, 논문에서는 Appearance 정보를 포함하지 않는, Strucuture 정보만을 순수하게 가진 벡터 표현을 원했고, 이를 위해서 앞선 Self-Similarity 를 구성하게 됩니다. 그 결과 위 그림의 두 번째 행과 같이 Appearance 정보가 소실된 채 물체 및 다른 의미를 가지는 요소들에 대한 구조 정보를 복원해낼 수 있음을 확인할 수 있었습니다. 이 결과를 통해 Self-Similarity 가 Appearance 를 배제한 Structure 정보를 가지고 있음을 보여주었습니다.
Splicing ViT Features
앞선 실험을 통해 밝혀낸 Dino-ViT 의 feature space 에 대한 이해를 바탕으로 논문에서는 처음에 나왔던 파이프라인에서의 generator 를 학습하기 위한 objective function 을 다음과 같이 구성합니다.
여기서 각 항목 , , 는 각각 appearance, structure, identity 에 대한 항목을 나타내며, , 는 가중치를 조절하는 hyperparameter 입니다. 각 손실함수 항목은 구체적으로 다음과 같이 설계됩니다.
Appearance Loss
항목은 output image 가 target image 의 Appearance 와 동일하도록 유도하는 손실함수 항목입니다. 앞선 실험에서 가장 마지막 layer 의 출력 [CLS] token 이 Appearance 정보를 가장 잘 반영할 수 있는 벡터로 밝혀짐에 따라 이를 활용하여 다음과 같이 정의하게 됩니다.
여기서 는 matrix 에 대한 Frobenius Norm 으로 볼 수 있는데, matrix 에 대한 L2 norm 과 동일하다고 보시면 됩니다.
Structure Loss
항목은 output image 가 source image 의 Structure 와 동일하도록 유도하는 손실함수 항목입니다. 앞선 실험에서 가장 마지막 layer 의 출력 key vector 를 활용한 Self-Similarity 이 Structure 정보를 가장 잘 반영할 수 있는 벡터로 밝혀짐에 따라 이를 활용하여 다음과 같이 정의하게 됩니다.
Identity Loss
항목은 논문에서 regularization 목적으로 추가한 항목입니다. 구체적으로는 target image 를 source image 로도 활용하여 generator 에 통과시켜 얻은 의 key vector 가 통과시키기 전의 key vector 와 동일하도록 유도하는 손실함수 항목입니다. 이는 GAN-based 방법론들에서 많이 사용하는 방법론으로 이미 특정 domain 에 있는 것을 input 으로 주었을 때 네트워크가 identity 의 기능을 하도록 유도하는 항목으로 보시면 됩니다.
Data augmentations and training
논문의 방법론에서는 source image 와 target image 를 한 쌍의 입력 로 받습니다. 하지만 논문에서는 optimization problem 을 푸는 것이 아닌, generator 를 학습하는 것이기 때문에 cropping 과 color jittering 을 포함한 augmentation 을 통해서 좋은 mapping function 을 찾도록 유도했다고 합니다.
Results
논문에서는 Animal Faces HQ (AFHQ) 데이터셋과 Flickr Mountain 에서 크롤링한 것, 그리고 Pixabay 에서 가져온 25 개의 고해상도 이미지 셋으로 논문에서 직접 구성한 Wild-Pairs 데이터셋을 사용하여 테스트합니다.

Sample Results on in-the-wild Image Pairs
위 그림은 테스트에 사용한 샘플 결과들입니다. Visual Appearance 가 물체의 위치 및 방향, 물체의 개수 등에 관계없이 의미적으로 관계가 있는 물체들에 대해서 잘 전이된 모습을 확인할 수 있습니다. 한 물체 내에서도 그 물체가 가지고 있는 지점지점들마다의 다른 Appearance 를 잘 반영하고 있는 형태로 전이가 된 모습을 볼 수 있습니다. 위 그림의 첫 번째 행에서 오리의 세부적인 Appearance 패턴이 백조 떼에 잘 반영된 모습을 확인할 수 있습니다.
Comparisons to Prior Work
논문에서는 선행연구 중 동일한 문제인 (Semantic) Visual Appearance Transfer 를 다룬 방법론이 없기 때문에, 문제 상황이 최대한 비슷한 두 선행연구를 가져와 비교를 합니다.
첫 번째로 가져온 것이 Swapping Autoencoders () 로, domain 한정으로 texture 와 structure 를 swap 할 수 있는 방법론이고, 두 번째로 가져온 것이 로, pretrained 된 CNN feature 에 Self-Similarity 를 사용하여 Neural Style Transfer 를 진행한 방법론입니다. 마지막으로는 라고 불리는 photorealistic Neural Style Trasnfer 방법론을 가져옵니다.
Qualitative Comparison
논문에서는 와 , 그리고 의 방법론으로 얻어낸 이미지들을 정성적으로 비교합니다.

Comparisons with Style Transfer and Swapping Autoencoder
위 그림은 논문에서 제시한 각 방법론 별 생성 이미지를 통한 정성적인 비교입니다. 먼저 논문의 방법론인 는 모든 경우에 대해서 의미적으로 관계가 있는 부분들을 잘 매칭한 것은 물론 해당 부분들에 맞게 Visual Appearance 를 잘 전이한 모습을 볼 수 있었습니다.
의 경우에는 첫 3 개의 열의 산 사진들에 대해서는 잘 동작했지만 4 번째 열의 고양이 사진 등에서 Appearance 를 제대로 전이하는데 실패한 모습을 볼 수 있습니다. 이처럼 에서는 Source Image 와 거의 동일한 형태의 이미지를 생성하기도 하는 모습을 보여주었는데 이는 training 데이터에 의해서 위와 같이 swapping 된 결과도 realistic 하다고 판별한 GAN 기반의 loss 에서 발생한 오류라고 보고 있습니다.
와 와 같은 Neural Style Transfer 기반의 방법론들은 Source Image 의 Structure 를 잘 유지하는 모습을 보였지만, 간혹 결점을 보이는 것을 확인할 수 있습니다. 는 색상이 번지는 현상 (Color Bleeding) 이 나타나고 는 전체적인 색상에서 결점들이 보이는 것을 확인할 수 있습니다.
더불어, 마지막으로 논문에서는 최근 등장한 GAN-based Image Translation 방법론인 과도 정성적으로 결과를 비교합니다.

Comparison to SinCUT
위 그림에서 볼 수 있듯이 은 풍경을 기반으로 한 이미지에 대해서는 잘 동작하지만 백조의 구조를 가지는 이미지를 흑조로 바꾸는 경우에서 볼 수 있듯이 고차원의 시각적 정보를 전이할 수 있는 능력은 부족함을 확인할 수 있습니다. 반면 논문의 방법론은 의미적으로 관계를 가지는 영역들에 대한 정확한 매치를 통한 전이를 성공한 모습을 볼 수 있습니다.
Quantitative Comparison
앞서 논문에서는 선행연구들 중 (Semantic) Visual Appearance Transfer 를 다룬 것들이 없다고 언급했고, 이에따라 마찬가지로 evaluation metric 도 마땅한 것이 없었다고 합니다. 때문에 Style/Appearance Transfer 에서 많이 사용되는 인간이 평가를 매기는 형태들을 가져와 Amazon Mechanical Turk 에서 User Study 를 진행했다고 합니다.
논문에서는 두 개의 입력 이미지 (Source, Target) 및 논문의 방법론으로 생성한 이미지 와 비교 대상의 방법론으로 생성한 이미지 , 이렇게 총 4 개의 이미지를 유저들에게 보여주고 와 중 어느 것이 Source Image 의 Structure 를 가지면서 Target Image 의 Appearance 를 더 잘 나타내는지에 대한 Two-Alternative Forced Choice (2AFC) 문제를 냈다고 합니다.

AMT Perceptual Evaluation
총 65 쌍의 이미지에 대해서 설문조사를 진행했고, 그 결과는 위와 같습니다. 위 표의 값은 각 방법론과 비교했을 때 논문의 방법론이 더 좋은 결과를 산출했다고 응답한 유저의 비율입니다. 모든 비교 대상 및 데이터셋에 대해서 논문의 방법론이 좋다고 평가한 인원이 더 많았으며 특히 Wild-Pairs 데이터셋에 대한 비중은 압도적이었습니다. 더불어 는 mountain 데이터셋으로 학습되었음에도 불구하고, 논문의 방법론이 해당 데이터셋에 대해서도 더 성능이 좋다고 평가를 받았습니다.
번외로, 논문의 방법론의 핵심적인 내용 중 하나가 Semantic 한 레이아웃을 유지한 채 Appearance 를 전이할 수 있다는 것이기 때문에, 논문에서는 MaskRCNN 을 통해서 semantic segmentation 을 진행하여 기존 Source Image 의 segmentation region 과 Output Image 의 segmentation region 의 IoU (합집합가 얼마나 높은지를 정량적으로 평가합니다.

Mean IoU of Output Images with respect to the Input Structure Image
논문의 방법론은 , 보다는 높은 수치의 IoU 를 보여주었고, 정성적인 결과에서 색상 결점이 보였던 에 준하거나 약간 낮은 수치의 IoU 를 보여주었습니다. 논문은 이 결과를 바탕으로 Segmentation IoU 를 metric 으로 했을 때 높은 수준의 Structure Preservation 을 보여주었음을 주장합니다.
Ablation
논문에서는 최종적인 손실함수를 정의할 때 사용한 세 가지 항목에 대한 Ablation Study 를 통해 해당 설계 각각의 중요성을 입증합니다.

위 그림은 Appearance Loss, Structure Loss, Identity Loss 각각에 대한 Ablation Study 결과입니다.
먼저, Appearance Loss 없이는 Appearance 가 거의 전이되지 못하는 모습을 보였고 Identity Loss 에 의해서 Target Image 를 입력으로 넣었을 때 본인 자체가 나오도록 학습된 부분의 영향으로 전체적인 옅은 초록빛 색상으로만 전이된 모습을 확인할 수 있습니다.다음으로, Structure Loss 없이는 기존 물체의 온전한 모습을 유지하는데 실패한 모습을 보였습니다. 그림에서 배의 일부분이 왜곡된 모습을 볼 수 있습니다. 마지막으로, Identity Loss 는 Appearance 및 Structure 두 측면 모두에서 물체의 구체적인 디테일을 확보하는데 도움이 되는 것을 확인할 수 있습니다.
Conclusion
이것으로 논문 “Splicing ViT Features for Semantic Appearance Transfer” 의 내용을 간단하게 요약해보았습니다.
이 논문에서 신선하게 다가왔던 부분은 Feature Inversion 으로, 보통 어떤 feature 가 표현하는 바나 담고 있는 정보를 실험 및 경험적으로 찾았다- 정도만 언급하지 보여주진 않는데 직접 실험을 통해서 보여주니 논문의 방법론을 구현한 것에 대한 자연스러운 이해가 되었던 것 같습니다.
더불어 NLP 쪽의 최신 동향에 대해서 약해서 Self-Attention 에 대해서 간단히만 알고 있었는데 ViT 에 대한 배경지식을 필요로 하는 논문이어서 해당 분야에 대한 공부를 하면서 자연스럽게 많은 도움이 되었던 것 같습니다.
전체적인 파이프라인은 크게 이해하기 어려운 부분은 없었고 분야가 아직은 작아서 평가가 얕은 수준으로 이루어진 부분은 아쉽지만 정성적인 결과가 매력적인 논문임에는 틀림없어 보였습니다.