Note Taking
Note Taking
Lecture 13 요약
•
Unsupervised Learning
◦
학습 데이터는 있지만 그에 해당하는 label 이 존재하지 않는 학습
◦
ex) Clusterinf, Dimension Reduction
•
PixelRNN, PixelCNN
◦
Sequential 하게 다음 픽셀을 생성하는 네트워크를 학습
◦
학습 속도가 굉장히 느림
•
Variational Auto Encoder (VAE)
◦
Intractable density function
◦
density function 을 근사하기 위해 variational inference 도입
◦
encoder 를 붙여 를 학습 (mean, variance)
◦
encoder 를 통해 학습한 분포에서 reparametrization trick 을 사용해 sampling
◦
sampling 한 를 사용해 loss 계산 후 back propagation
•
Generative Adversarial Network (GAN)
◦
Generator: noise vector로 부터 학습 데이터의 분포와 유사한 이미지를 생성하여 discriminator 를 속이는 것이 목적
◦
Discriminator: Generator 가 생성한 이미지를 fake 로, 실제 이미지를 real 로 정확하게 판단하는 것이 목적
◦
Minimax Loss Function
Reinforcement Learning
•
Reward 를 제공하는 environment, 그리고 그와 상호작용하는 agent 를 포함하는 문제에서 Reward 를 maximize 하는 목적을 가지는 학습
•
State : Environment → Agent
Action : Agent → Environment
Reward : Environment → Agent
Environment 가 ternminal state 에 도착하기 전까지 가 증가하며 루프 반복
•
Example 1. Cart-Pole Problem
Objective: 움직이는 카트에서 pole 을 수직으로 세우는 것
State: pole 의 각도, pole 의 각속도, 카트의 수평 속도 등
Action: 카트에 가하는 수평 힘
Reward: pole 이 수직인 time step 마다 1
•
Example 2. Robot Locomotion
Objective: 로봇이 수평으로 걷게 하는 것
State: 모든 관절의 각도와 위치
Action: 관절에 가해지는 토크
Reward: 로봇이 똑바로 서 있으면서 앞으로 걷는 time step 마다 1
•
Example 3. Atari Game
Objective: 최대한 높은 점수로 게임을 끝마치는 것
State: 게임 화면의 raw pixel 들
Action: 컨트롤러의 4 개 커맨드 컨트롤 중 하나
Reward: 각 time step 마다 1
Markov Decision Process
•
Reinforcement Learning 문제를 수학적으로 형성하는 방법
•
Markov Property
◦
현재의 state 가 다음 state 를 전적으로 결정하는 성질
•
5 가지의 요소로 정의
◦
◦
: 가능한 state 들의 종류
◦
: 가능한 action 들의 종류
◦
: (state, action) pair 마다의 reward
◦
: (state, action) pair 마다의 다음 state 로의 전이 확률
◦
: state 변화 시 reward 에 곱해지는 값
•
다음 순서로 process 가 진행
1.
일 때, initial sate 를 sampling
2.
끝날 때 (Terminal State)까지 다음을 반복
a.
Agent 가 action 를 선택
b.
Environment 가 reward 를 sampling
c.
Environment 가 다음 state 를 sampling
d.
Agent 가 reward 를 받고 다음 state 로 진입
•
Policy 는 state → action 인 함수
•
목적은 를 최대화하는 를 찾는 것
•
Example. Grid World
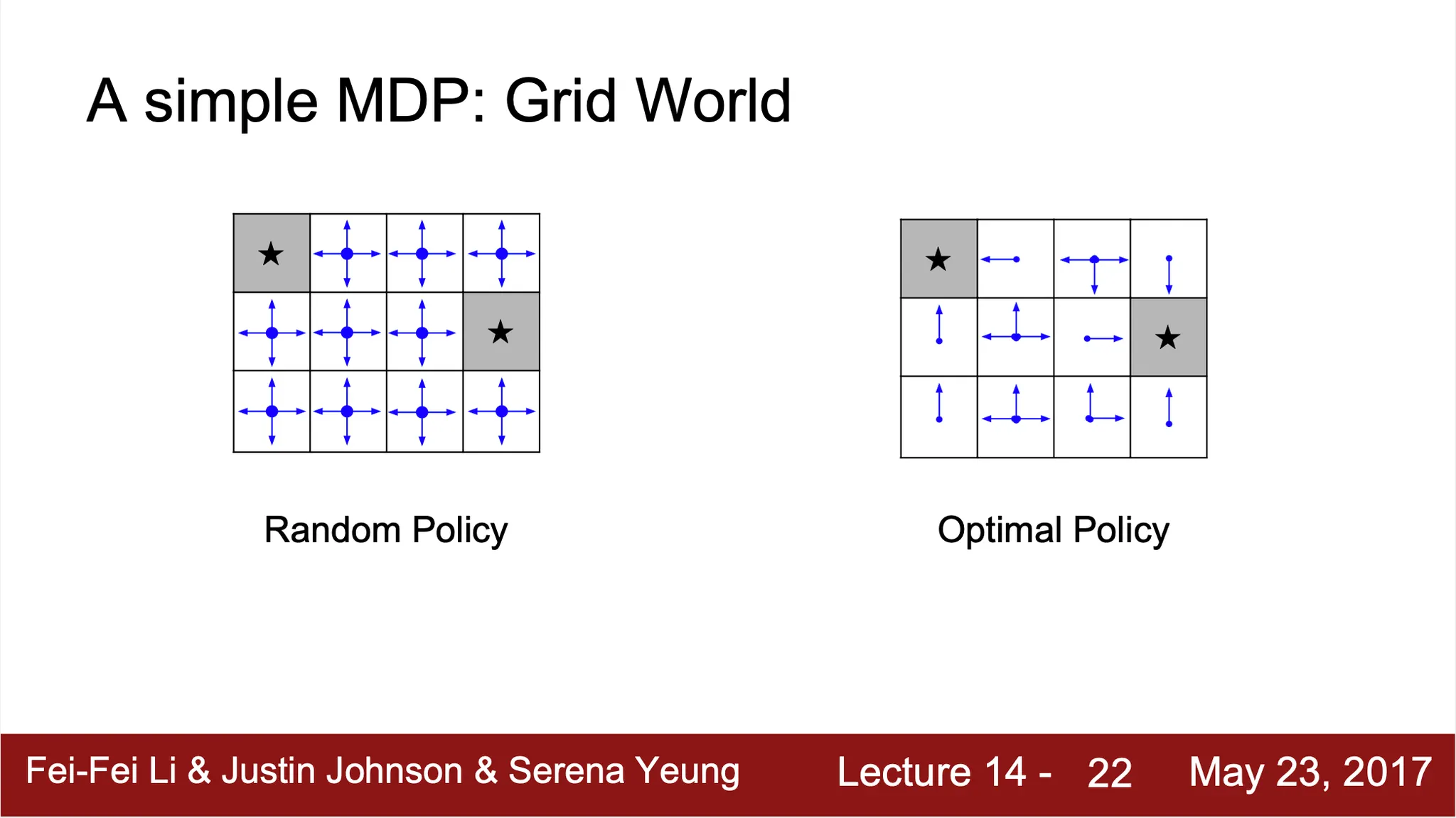
•
를 찾는 방법 → expected sum of rewards 를 maximize
•
How good is a state: Value Function
◦
•
How good is a state-action pair: Q-value Function
◦
◦
Optimal 한
◦
이 때, 은 Bellman Equation 을 만족
▪
▪
다음 스텝 이후의 Q-value Function 의 최댓값이 로 주어진다면, 현재 스텝에서는 의 기댓값을 최대로 만드는 action 을 취하는 직관에서 시작
◦
Bellman Equation 을 풀어 를 얻어내자!
▪
가장 기본적인 방법: Value Iteration algorithm
▪
▪
가 일 때
▪
하지만, state 가 굉장히 많은 경우에 현실적으로 불가능... → Neural Network 로 찾자!
Q-Learning
•
Q-Value Function 을 예측하기 위한 function approximator 를 사용하는 방법
•
Function approximator 로 deep neural network 를 사용하면 Deep Q-Learning
•
Loss function
◦
•
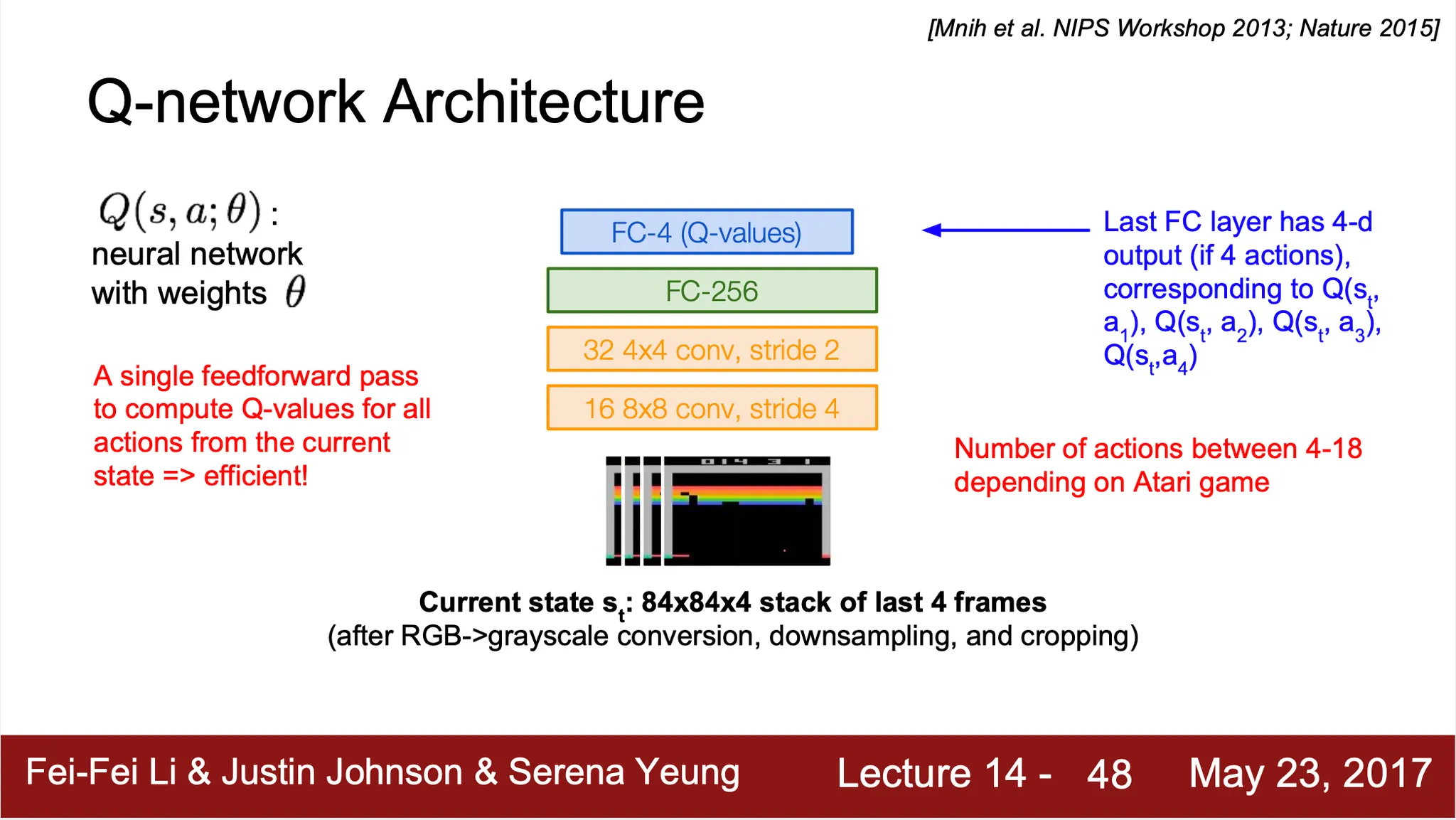
Example. Atari Game
◦
Input: 현재 상태
◦
Output: 각 action 을 선택했을 때 해당하는 Q-value
◦
단일 forward pass 만으로 현재 상태에서 모든 action 에 대한 Q-value 를 구해낼 수 있음!
Training the Q-Network: Experience Replay
•
기존 Q-Network 학습의 문제점
◦
현재 상태의 Q-Network 가 다음 training sample 을 결정하는 형태의 학습
▪
input sample 들이 서로 관계가 있어 학습 효율이 떨어짐
▪
잘못된 피드백 루프에 빠질 수 있음
•
Experience Replay
◦
각 time step 별로 얻은 다음 sample 을 tuple 형태로 data set 에 저장해두고, 해당 data set 에서 random 하게 뽑아서 mini batch 를 구성하고, 학습 데이터로 사용
Policy Gradients
•
로봇이 물체를 집는 행위는 관절 위치, 속도 등 다양한 상태가 존재하는 문제에 대해서 Q-Learning 은 매우 복잡함
•
대략적으로 optimal policy 를 알고 있을 때, policy 들 중에서 가장 좋은 policy 를 얻어낼 수 없을까-
•
State 에 따른 Action (Policy) 를 직접 output 으로 내는 네트워크의 학습
•
Policy 에 대한 평가 - Value of policy
를 만족하는 를 찾자!
•
REINFORCE algorithm
◦
Policy 로 부터 sampling 한 trajenctory 에 대해,
◦
해당 Value of Policy 의 미분 값? (for gradient ascent)
Expectiation 의 gradient 를 gradient 의 expectation 으로 치환할 수 있음!
◦
Transition probabilites 는 Value of Policy 의 gradient 를 계산하는 데 불필요!
◦
위 식 전개 덕분에, 하나의 sampling 된 trajectory 에 대한 gradient 는 다음과 같이 구해냄 (expectation 말고 expectation 내부에 있는 term 만!)
◦
위 항목을 Gradient Estimator 라 칭함 (하나의 input trajectory 에 대한 gradient)
◦
이 때, 가 높다면, 속에서 관찰된 state 속에서의 action 의 확률을 높이고 낮다면 확률을 낮추는 직관을 사용 (ex. Atari Game 에서 고득점 받은 플레이어의 상황에 따른 이동들[trajectory] 에 reward 가 부여되었을 것이므로 해당 상황 속 이동들이 나올 확률을 높이는 것)
◦
하지만, 위 직관은 또 high variance problem 을 야기함. 굉장히 많은 sample 이 존재해야 진짜 정답에 가까워지고, 적당히 많아서는 그냥 지금까지 많았던 데이터의 경향성 쪽으로 해당 state 에서의 해당 action 의 좋고 나쁨을 판단해버릴 수 있음.
◦
때문에 variation reduction 에 대한 시도를 진행함!
1.
Trajectory 내 어떤 state, action 에 대한 push up probability 정도를 결정하기 위한 reward 부분을 trajectory 전체의 reward 가 아닌, 해당 state 이후의 reward 만으로 계산. 이는 해당 state 에서의 action 이 얼마나 좋고 나쁜지 판단할 때, future reward 만을 계산해야 한다는 직관에서 유래함.
2.
1 번의 방법에 reward 에 대한 discount factor 를 추가하여 계산. 현재 상태를 기준으로 future reward 만 계산하되 아주 먼 미래의 reward 는 현재 state action 이 영향을 주었다고 보기 힘들기 때문에 점점 감소되는 reward 를 주는 직관에서 유래 (실제로 a → b → c 경로 뿐 아니라 a → d → c 등 같은 결과가 나오더라도 b, d 등 중간단계는 다를 수 있기 때문)
3.
Reward 가 높냐 낮냐 얼마냐가 중요한 것이 아니라, reward 가 생각한 것보다 높냐, 낮냐가 중요. 생각한 것보다- 의 기준이 baseline.
◦
3 번의 baseline 으로 사용하는 것이 Q-Value Function 과 Value Function 의 차이 (State 에서 선택할 수 있는 수 많은 선택지들에 비해서 해당 선택지가 얼마나 더 좋냐!)
◦
하지만, 위의 Q, V 는 Policy Gradient 를 위한 REINFORCE algorithm 에서 구해낼 수 없었음. 이를 위해 새로운 Actor-Critic Algorithm 을 도입
•
Actor-Critic Algorithm
◦
Policy Gradient 에 Q-Learning 을 섞어 actor (the Policy) 와 critic (Q-Value Function) 를 동시에 학습하는 방법론

•
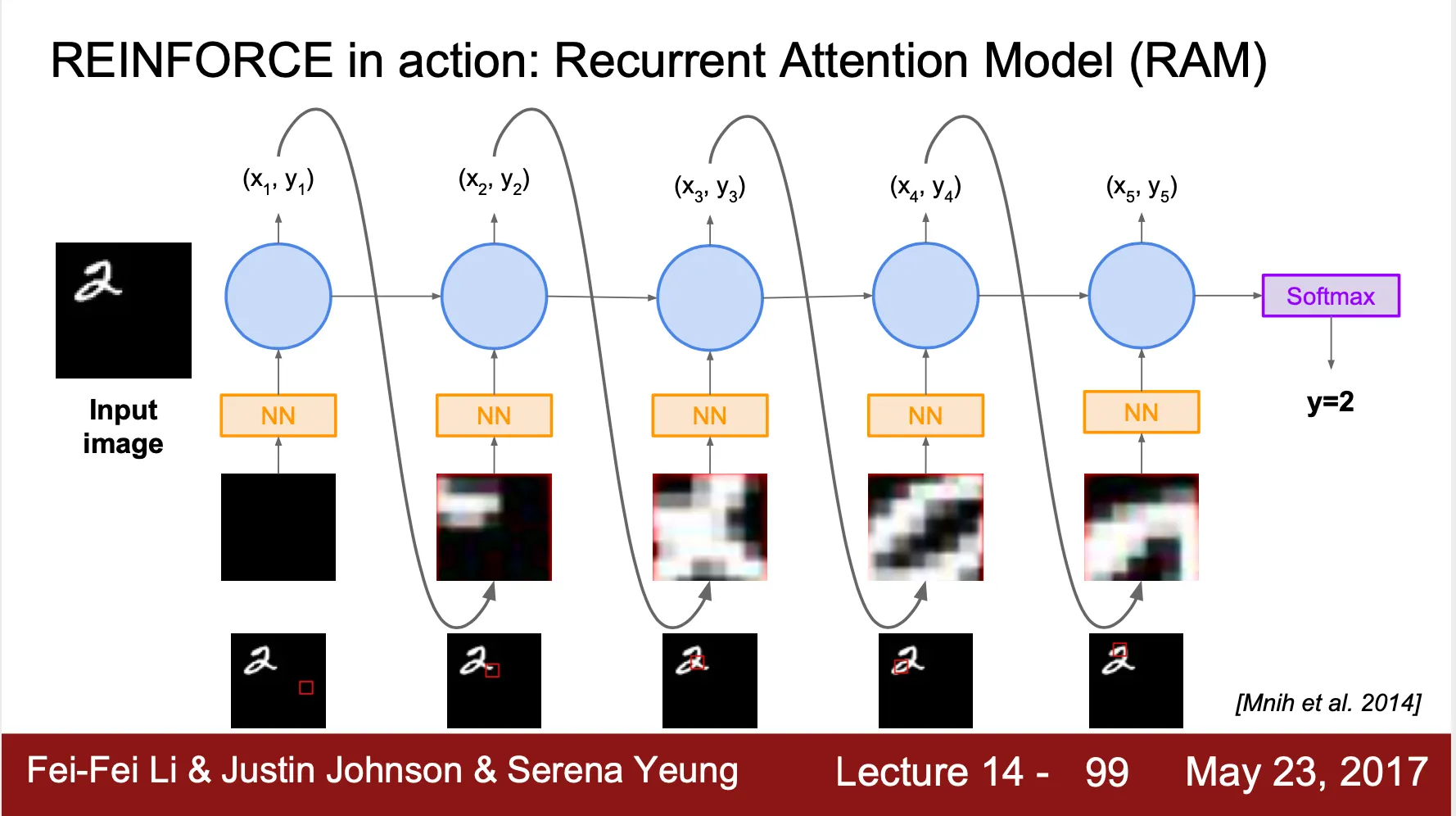
REINFORCE in action: Recurrent Attention Model (RAM)
◦
State: 현재까지 관찰한 glimpses 들의 모음
◦
Action: 다음 볼 glimpse 의 coordinate
◦
Reward: final timestamp 에서 image 가 정확하게 classified 되었으면 1, 아니면 0