본 포스트에서는 Mobile Application 에서 효율적으로 Computer Vision Task 를 수행할 수 있는 네트워크를 설계한 논문에 대해서 소개드리려고 합니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“MobileNets: Efficient Convolutional Neural Networks for Mobile Applications”

Objective
AlexNet 이 ILSVRC 2012 를 우승하고 나타난 Computer Vision 분야의 트렌드는 더 깊고, 더 복잡한 네트워크를 구성하여 높은 accuracy 를 얻어내는 것이었습니다. 하지만, AlexNet 이 공개된 직후의 연구들은 네트워크의 높은 accuracy 를 얻어내는 것에만 치중하였고, 그 accuracy 를 얻어내는 필요한 resource 를 고려하지 않은 경우가 많았습니다. 하지만, 로보틱스, 자율주행, 증강현실과 같이 real world application 에서는 resource 가 한정되어 있기 마련이고 이런 application 에 필요한 vision task 들은 필연적으로 제한된 자원에서 결과를 내야만 했습니다.
이와 관련해 실제로 많은 연구들이 작고, 효율적인 네트워크 설계에 뛰어들었고 이러한 기존 연구들은
1.
처음부터 작은 네트워크를 학습하기
2.
학습된 규모가 큰 네트워크를 압축하기
의 두 가지 방법을 필두로 진행되었습니다. 하지만 이러한 방법들은 대부분 size 가 작은 네트워크를 만드는 것에만 집중하고 inference time 의 latency 를 최적화하지는 않았습니다. 논문에서는 이 두 가지 요소, latency 와 size 모두를 가지고 resource-wise 한 네트워크를 설계하는 방법이 없을까에 대해 고민하기 시작했고, 가지고 있는 resource 에 따라서 선택적으로 네트워크를 결정할 수 있는 방법론을 제시하게 됩니다.
MobileNet
논문에서는 MobileNet 을 구성하는 코어 및 전체적인 네트워크 구조, 그리고 resource-wise 한 네트워크 설계를 위한 두 가지 특별한 parameter 를 소개합니다.
Depthwise Seperable Convolution
Depthwise Seperable Convolution 은 factorized convolution 의 하나의 형태로 볼 수 있습니다. 이전 논문리뷰에서 VGGNet 이 Conv 를 하나 사용하는 것보다 Conv 를 3 개 사용하는 것이 receptive field 관점에서는 동일한 반면 computation 및 paramter 수를 줄일 수 있기 때문에 학습에 유리하다는 사실을 알 수 있었습니다.
이와 비슷한 맥락으로 Depthwise Seperable Convolution 에서는 기존의 Standard Convolution 에 비해서 computation 이 적은 새로운 convolution layer 의 형태를 제시합니다. Standard Convolution 의 경우에는 feature 를 filtering 하는 연산과 feature 를 combining 하는 연산이 합쳐져 있는 형태입니다. Input 의 depth 까지 한 번에 dot product 를 한 결과를 하나의 output channel 로 압축하여 산출하기 때문입니다. 반면, Depthwise Seperable Convolution 은 이 연산을 두 개로 나눕니다.
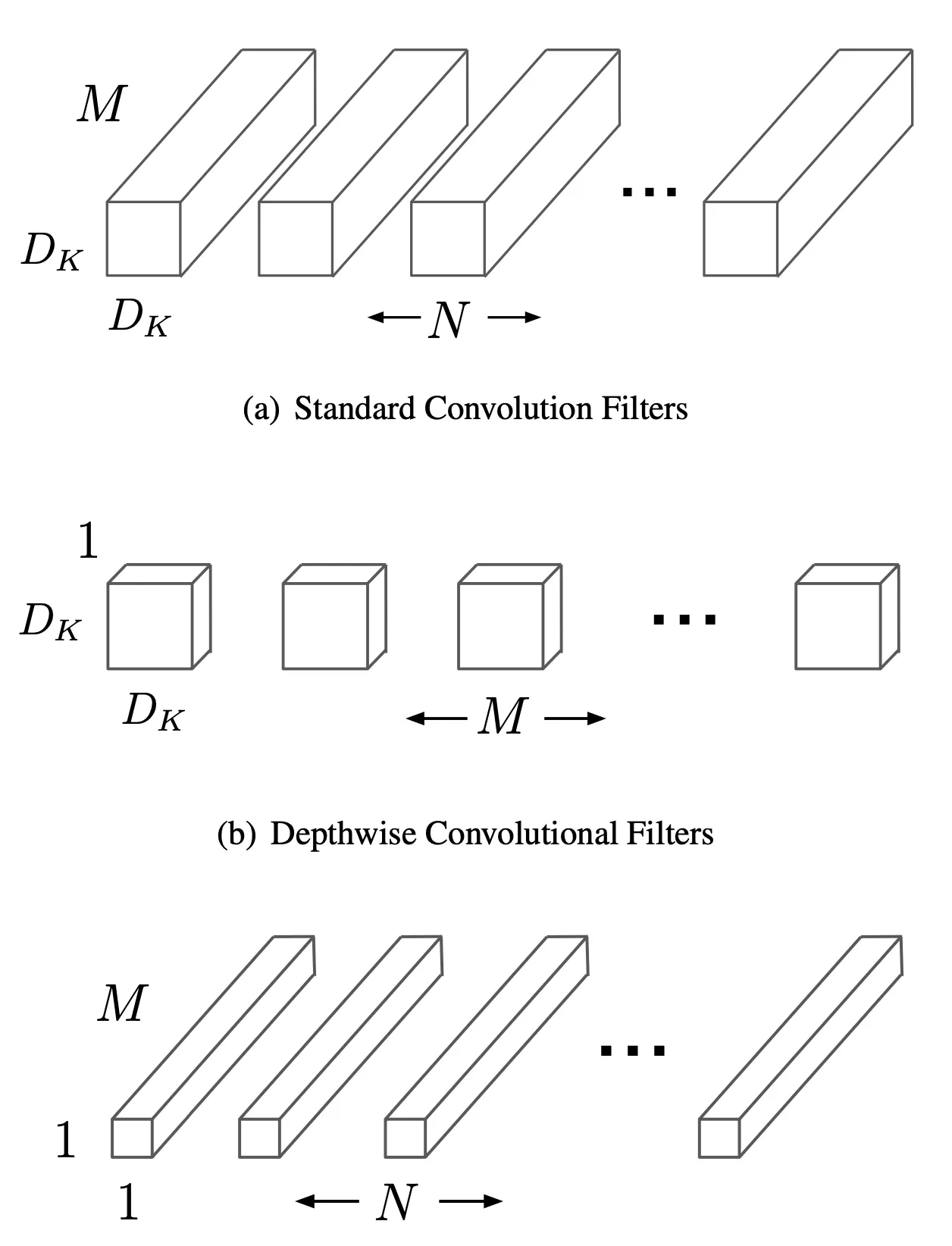
Depthwise Seperable Convolution 의 첫 번째 과정은 depth convolution 입니다. 이 과정은 feature 를 filtering 만 하는 과정으로 보시면 됩니다. Depth convolution 의 kernel 은 Standard Convolution 에서 kernel 이 가지는 depth (즉, output vector 의 depth) 가 1 인 것과 동일하게 해석할 수 있습니다. 더불어 연산이 Standard Convolution 에서 나타나는, depth 를 포함한 전체 범위에서의 dot product 가 아니라 depthwise product 입니다. 즉, kernel 의 channel 이 input 의 channel 하고만 dot product 연산을 하여 output 의 channel 을 구성하는 것입니다.
Depthwise Seperable Convolution 의 두 번째 과정은 pointwise convolution 입니다. 이 과정은 filtering 한 feature 를 combining 하는 과정으로 보시면 됩니다. Pointwise convolution 은 Standard Convolution 과 완전히 동일한 연산에 Conv 를 사용한 과정입니다. Depthwise 연산이었던 기존의 depth convolution 의 depth 들을 각 channel 에 합치는 과정이 여기서 일어난다고 보시면 됩니다.
세부적으로 들어가서, 이러한 Depthwise Seperable Convolution 이 어떻게 computation 의 수를 줄여주는지 살펴보도록 합시다. 먼저 동일한 Input, output, kernel spatial dimension 환경을 정의해줍니다.
위와 같은 환경에서 Standard Convolution 의 연산은 다음과 같습니다.

혹시나, 위 식을 정량적으로 이해하고 싶으신 분들을 위해 !!
고정된 에 대해서 에 영향을 줄 수 있는 input 의 영역의 좌상단 좌표가 의 좌표에서 (padding 이 1 이기 때문에 1을 뺀 값부터 시작) 최대 kernel 의 variation 만큼 이동할 수 있는 영역 () 만큼 더한 지점입니다. 이것이 의 의미이며 kernel 의 channel 수와 input 의 channel 수는 동일하며 동일한 채널끼리 dot product 이기 때문에 와 에 같은 번째가 적혀져 있는 것을 볼 수 있습니다.
그렇게 input 의 좌상단부터 kernel 의 범위만큼, 그리고 같은channel 끼리 dot product 를 하면, 이 계산이 되고 은 kernel 의 개수로 번째 output channel 은 번째 kernel 의 연산에 의해서만 나타나는 것입니다.
이 때, computational cost 는 다음과 같습니다.
이는 단순히 의 범위를 영역만큼 쓸고 지나가면서 dot product 를 하는데, 그 depth 가 이고 이 전체 과정을 반복한 kernel 의 개수가 이므로 이를 모두 곱한 값이 되는 것입니다.
하지만, 위와 같은 환경에서 Depthwise Convolution 의 연산은 다음과 같습니다.
Standard Convolution 과 비교해서 확연히 달라진 것은 iteration 을 돌며 sum 을 진행할 때 depth 요소였던 을 변수로 하여 진행하지 않는다는 점입니다. 더불어, Standard Convolution 에서 kernel 의 개수 번째로 output 의 channel 번째가 결정되었다면, Depthwise Convolution 에서는 kernel 과 input 의 channel 번째로 결정되게 됩니다.
이 때, computational cost 는 다음과 같습니다.
유일한 변화는 항목이 빠진 것입니다. 당연하게도, kernel 의 개수가 1 개이기 때문입니다. 기존에 kernel 개수로 output 의 channel 이 결정된 것이 지금은 input 및 kernel 의 channel 로 output 의 channel 이 결정되는 것으로 바뀌어 output 의 dimension 자체는 유지할 수 있는 것입니다.
여기에 Pointwise Convolution 을 진행하게 되면, 앞서 언급했듯이 기존의 Standard Convolution 에서 인 computation 값이 추가되게 됩니다.
위 식을 보시면 아시겠지만, 앞선 feature filtering 에서 배가 빠지면서 그 역할을 뒤에서 분리된 네트워크로 따로 진행해주어 더해주기 때문에 곱셈 연산을 덧셈 연산으로 바꾼 듯한 변화를 이끌어 내어 전체적으로 computation 이 적어짐을 알 수 있습니다.
결과적으로 Standard Convolution 에 비해서 Depthwise Seperable Convolution 을 사용했을 때 얻는 computation 의 변화 비율은 다음과 같습니다.
위 계산 식에 따라, 네트워크에서 Conv 를 사용한다는 가정하에 약 8~9 배 정도의 computation 을 절감할 수 있다고 합니다.
Network Structure and Training
앞서는 MobileNet 의 코어 네트워크 구조에 대해서 알아보았습니다. 논문에서는 코어 네트워크인 Depthwise Seperable Convolution 를 이용해 전체 네트워크를 구성합니다. 그 구성에 대한 표는 다음과 같습니다.
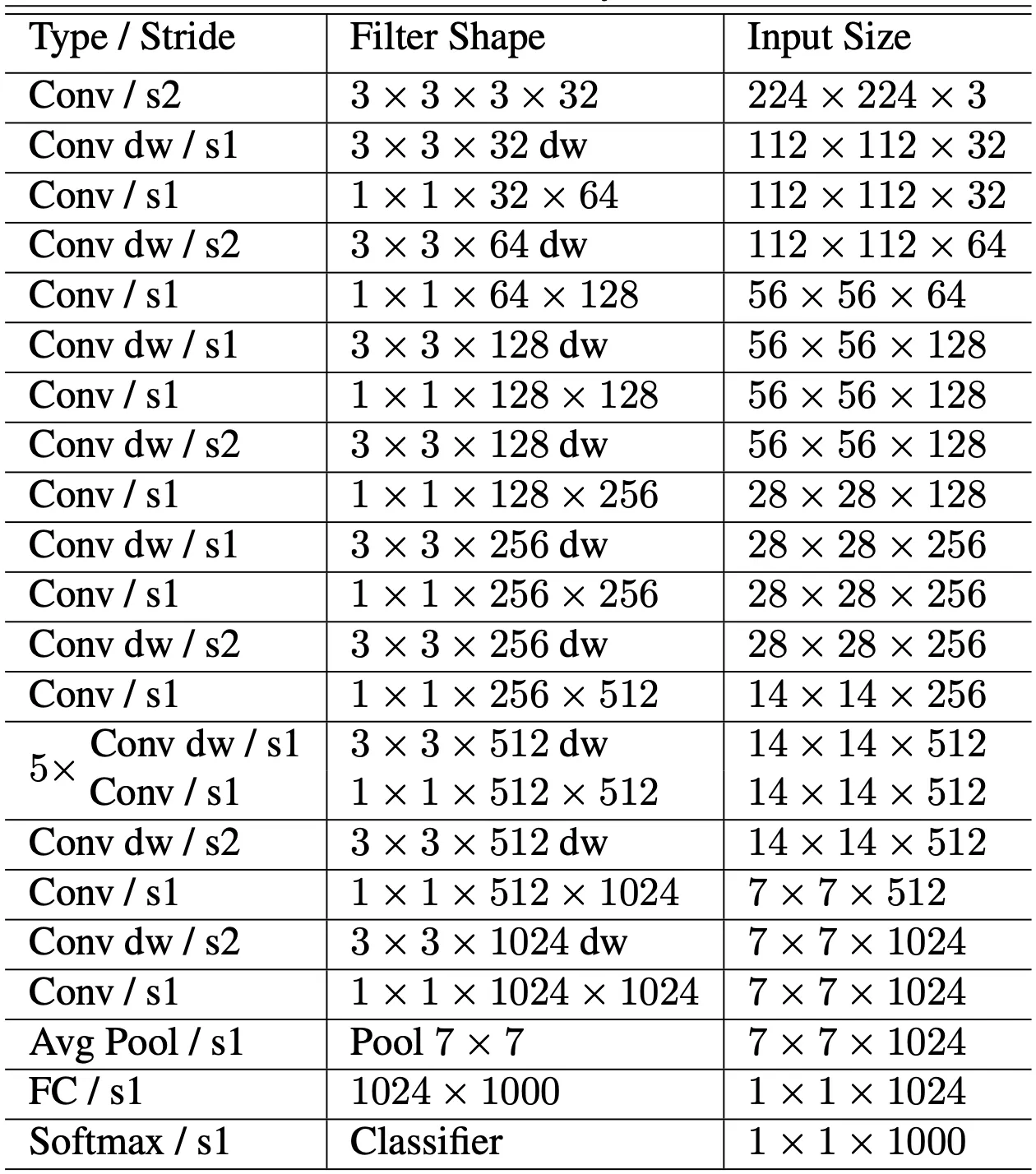
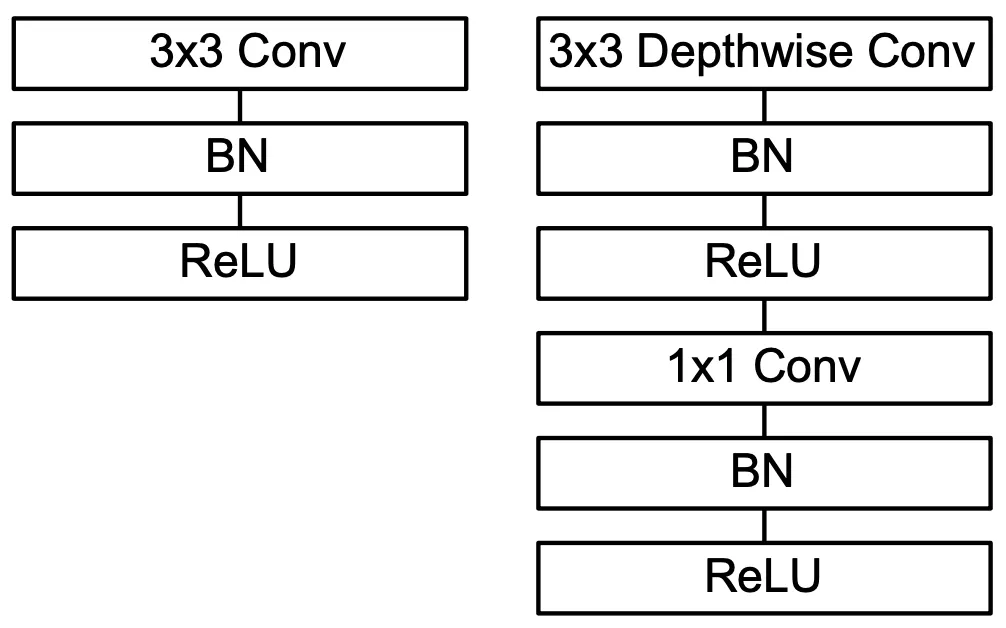
위 구성에 대한 설명이 논문에서 장황하게 적혀 있는데, 이를 간결하게 전달하기 위해 논문의 설명을 나열식으로 전달드리려고 합니다.
1.
MobileNet 에서 사용한 Conv 는 첫 번째 Conv 를 제외하고는 모두 다 Depthwise Seperable Convolution 입니다. 위 그림 좌측의 Conv dw 뒤에 항상 Conv 가 오는 구조가 이전에 살펴본 Depthwise Convolution + Pointwise Convolution 의 구조로 보시면 됩니다.
2.
마지막 Fully Connected Layer 를 제외하고는 모든 layer 뒤에 batch normalization layer 와 ReLU activation 이 함께 하는 구조입니다. 위 그림의 우측에 이를 포함한 Standard Convolution 과 Depthwise Seperable Convolution 의 구조가 그려져 있습니다.
3.
Strided Depthwise Convolution 에서 downsampling 이 함께 행해집니다. 이는 위 표의 Conv dw / s2 뒤에 항상 Input 의 spatial dimension 이 작아지는 것으로도 확인할 수 있습니다.
4.
마지막 average pooling 에서 spatial dimension 이 으로 줄어든 뒤에 Fully Connected Layer 로 들어갑니다.
5.
Depthwise Convolution 과 Pointwise Convolution 를 개별 layer 로 취급하여 총 28 개의 layer 가 존재하는 구조입니다.
아래는 학습에 관련된 요소의 설명입니다.
1.
TensorFlow 로 학습을 진행했습니다.
2.
Optimization algorithm 으로 RMSProp + asynchronous gradient descent 를 사용헀습니다.
3.
큰 네트워크를 학습할 때와 달리, MobileNet 은 작은 네트워크이기 때문에 overfitting 의 위험이 적고, 적은 regularization 과 data augmentation 을 사용했습니다.
4.
Side head, label smoothing 을 사용하지 않았습니다.
(Head 는 feature extraction layer 이후에 붙는 layer 를 일컫는 단어입니다. Label smoothing 은 라벨을 0, 1 등으로 확실하게 부여하지 않고 0~1 사이의 수로 유연하게 부여해 라벨링의 실수 등을 커버하는 방법론입니다.)
5.
Depthwise Convolution 에는 굉장히 적은 parameter 가 존재하여 L2 regularization 을 두지 않거나, 적게 두는 것이 효과적이었다고 합니다.
6.
이미지의 crop size 를 작게 줄임으로서 distortion 을 가진 이미지의 수를 줄이는 효과를 얻었습니다.
MobileNet 이 그 코어 네트워크 구조를 사용해 computation 의 수(mult-adds)를 줄이는 설계를 하더라도 실제로 그 computation 하드웨어 상에서 효율적이지 못하다면 성능이 좋지 못할 수 있습니다. 실제로 sparsity 가 과도하게 높지 않다면, 패턴이 없이 unstructured sparse 한 matrix 의 multiplication 은 dense 한 matrix 보다 computation 이 느린 경우가 그 예시입니다.
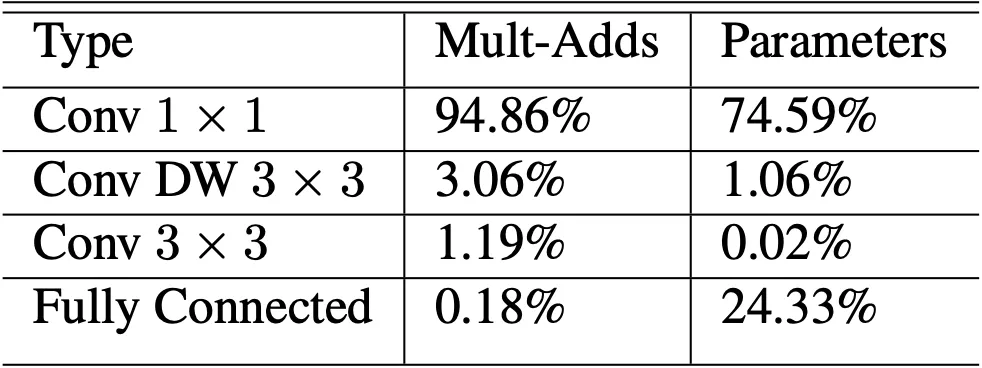
하지만, Conv 라는 quite dense 한 연산은 highly optimized general matrix multiply function 인 GEMM 을 사용하기에 적합하며 일반적인 Conv 와는 다르게 Conv 에서는 GEMM 을 적용하기 위한 초기 데이터의 재배열 과정이 필요 없습니다.
논문에서는 제시한 네트워크가 이러한 Conv 연산에 95% 의 연산 시간을 사용하고 있고, 75% 의 parameter 를 할당하고 있기 때문에 단순히 연산 수만이 적은 것이 아니라 실제 computation 에서도 효율적이라고 주장합니다.
Width Multiplier: Thinner Models
MobileNet 은 Depthwise Seperable Convolution 구조로 이미 작은 size 와 적은 latency 를 확보할 수 있었지만, 특별하게 작거나 빠른 네트워크가 필요한 경우가 존재할 수 있는 경우를 고려하여 width multiplier 라고 불리는 간단한 parameter 인 를 도입합니다.
Width multiplier 는 네트워크의 width 를 얇게 만드는 역할을 합니다. 정확히 말씀드리자면, input 의 channel 수가 에서 으로, output 의 channel 수가 에서 으로 바뀌면서 전체적인 computation 과 parameter 의 수를 줄이게 됩니다. Depthwise Seperable Convolution 에 이러한 설계를 적용했을 때 나타나는 computational cost 는 다음과 같습니다.
이 때, 이며, 전형적으로 1, 0.75, 0.5, 0.25 등의 값을 가집니다. 대략적으로 이러한 설계는computational cost 및 parameter 가 배 정도 적어지게끔 합니다.
Resolution Multiplier: Reduced Representation
Width multiplier 에 이어 computational cost 를 줄이는 두 번째 hyperparameter 는 resolution multiplier 입니다. 앞서 input 및 output 의 depth 를 조절하는 hyperparameter 를 설정했다면, 여기서는 input 및 output 의 spatial dimension 을 조절하는 hyperparameter 를 설정합니다.
Resolution multiplier 는 네트워크의 resolution 을 줄이는 역할을 합니다. 정확히 말씀드리자면, input 과 output 의 spatial dimension 이 에서 로 바뀌면서 전체적인 computation 수를 줄이게 됩니다. Depthwise Seperable Convolution 에 이러한 설계를 적용했을 때 나타나는 computational cost 는 다음과 같습니다.
이 때, 이며, 전형적으로 input, output 의 dimension 이 224, 192, 160, 128 등의 값을 가지도록 설정합니다. 대략적으로 이러한 설계는 computational cost 가 배 정도 적어지게끔 합니다.
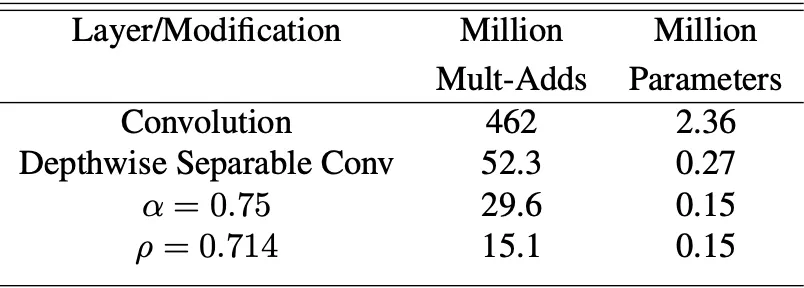
위 표는 Input 으로는 이미지를, kernel 로는 를 사용하여 측정한 computational cost 와 parameter 수입니다. Depthwise Seperable Convolution, width multiplier , resolution multiplier 를 실제 적용했을 때 computational cost 와 parameter 의 수를 얼마나 줄여주는지를 살펴볼 수 있습니다.
Experiment
먼저, 논문에서는 MobileNet 을 구성하는 코어 네트워크였던 Depthwise Seperable Convolution 의 효과를 입증합니다.
Model Choices
가장 먼저 제시한 것은 ImageNet 을 통해 학습시킨 Standard Convolution 과 Depthwise Seperable Convolution 의 결과입니다.
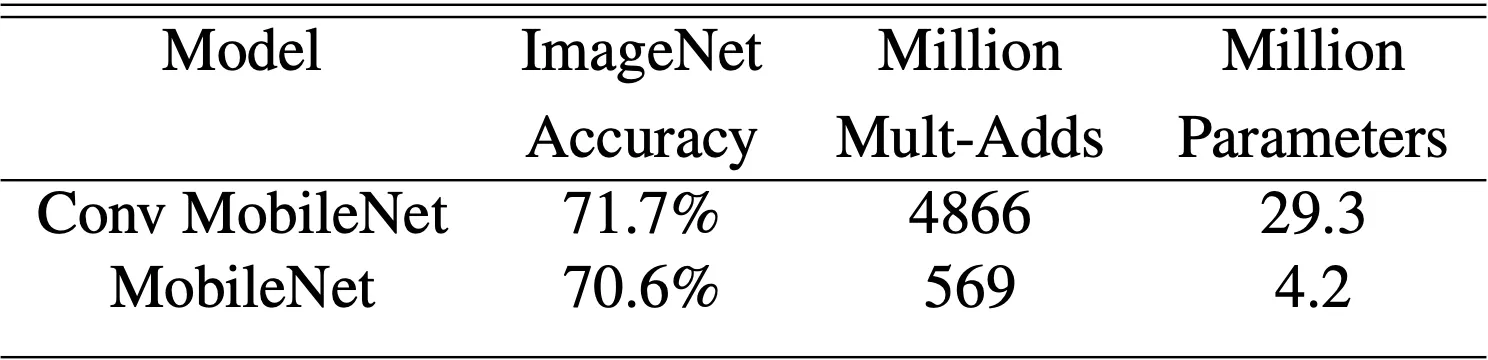
그 결과 accuracy 는 약 1% 정도 낮지만, 이를 비슷하게 유지하면서 computational cost 와 parameter 수를 극단적으로 줄일 수 있다는 것을 확인할 수 있었습니다.
다음으로는, 일반적으로 computational cost 나 parameter 수를 줄이기 위해서 네트워크의 깊이를 줄인 shallow network 방법과 논문의 width multiplier 를 사용한 thinner network 를 비교합니다. 이 때 사용한 Shallow MobileNet 네트워크는 기존 MobileNet 에서 input size 가 인 Depthwise Convolution 5 개를 제거한 네트워크입니다.

그 결과 width multiplier 를 사용한 방법이 비슷한 computational cost 와 parameter 를 보유하고 있음에도 약 3% 가량 더 높은 accuracy 를 얻은 것을 확인할 수 있었습니다. 논문에서는 이 결과로 네트워크의 width 를 줄이는 행위가 기존의 방법론에 비해 비슷한 네트워크 size 대비 정확도를 높게 가져갈 수 있는 방법론임을 보여주었습니다.
Model Shrinking Hyperparameters
다음으로 논문에서 제시한 것은, width multiplier, resolution multiplier 에 따른 accuracy - size trade-off 에 대한 표입니다.


두 표의 결과를 통해 논문이 제시하는 바는 size 가 극단적으로 작아짐에도 불구하고 급격하게 accuracy 가 떨어지지 않고 smooth 하게 떨어진다는 점입니다. (사실 smooth 의 기준이 나와있지 않아서 애매한 표현입니다만, 논문에서는 이런 식의 표현을 사용했습니다.)
다음으로 논문에서 제시한 것은 computational cost(mult-adds), parameter 와 accuracy 간의 관계에 대한 plot 입니다. 아래 분포는 , 의 선택지를 사용해 총 16 개의 점을 나타낸 것입니다. 좌측은 mult-adds 에 대한 log-scale vs accuracy 위에 나타낸 것이며, 우측은 parameters 에 대한 log-scale vs accuracy 위에 나타낸 것입니다.
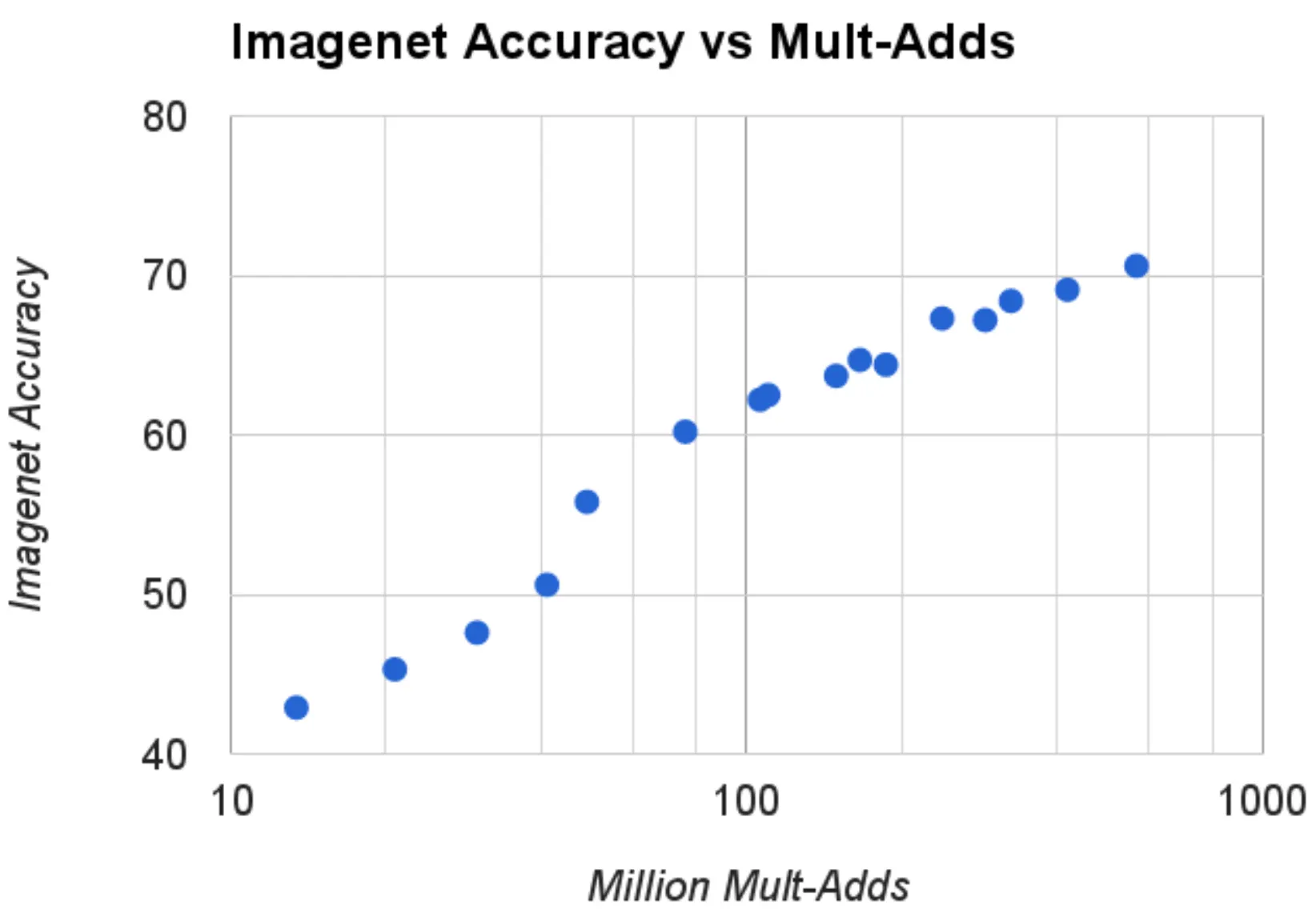
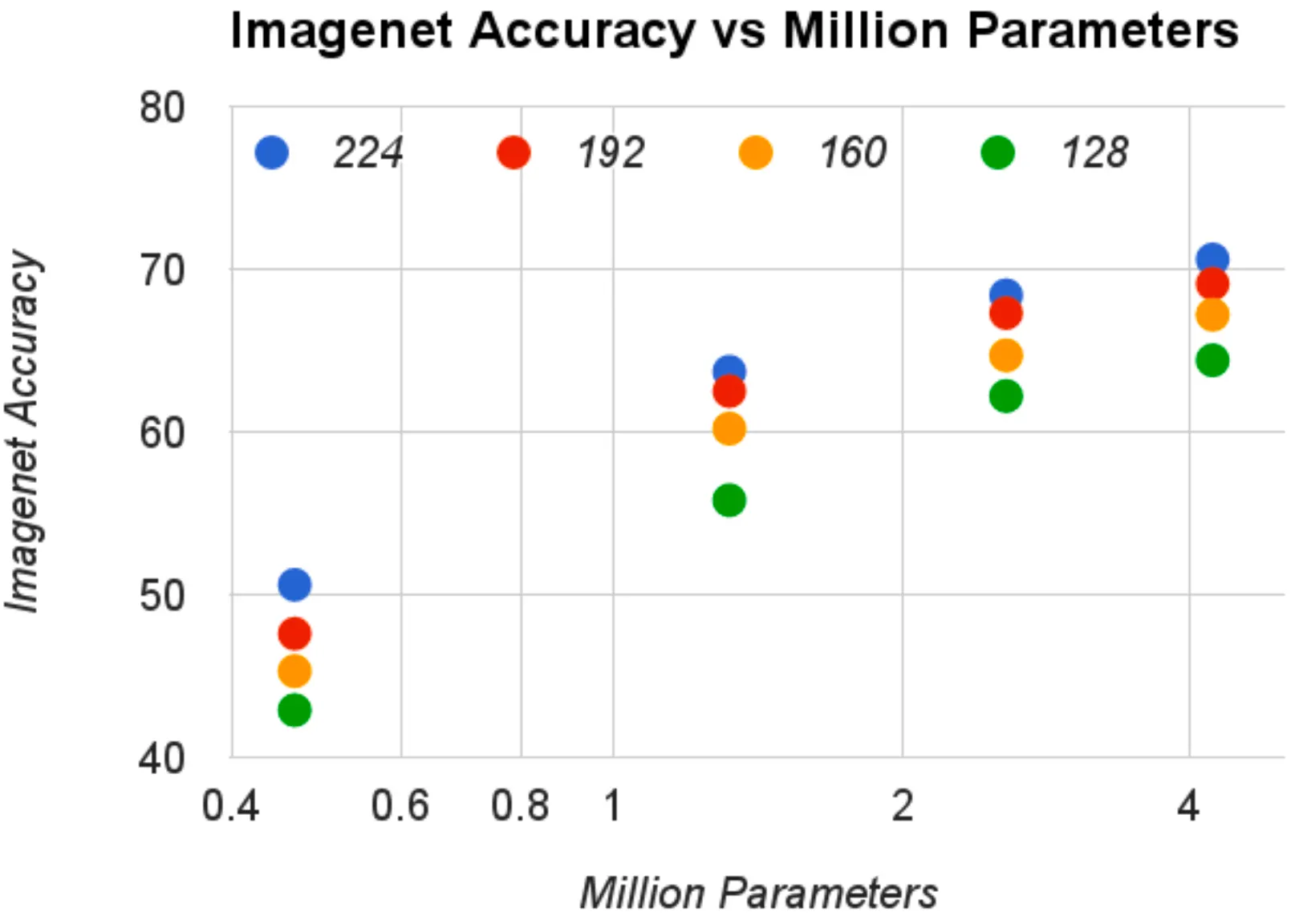
그 결과, multi-adds vs accuracy plot 에서는 를 벗어나는 시점에서 accuracy 의 큰 변화가 나타났고, 전체적으로는 log-linear 한 양상을 보였습니다. 이와 비슷하게 parameters vs accuracy plot 에서도 가장 작은 resolution 에서 다음 resolution 으로의 gap 이 큰 것을 확인할 수 있었습니다. 이 관계에 대한 자료는 논문의 width multiplier, resolution multiplier 가 smooth 한 accuracy 의 감소를 가져오는 것을 가시적으로 보여줍니다.
다음으로 논문에서는 기존의 유명한 네트워크와 MobileNet 을 비교하는 작업을 진행합니다.

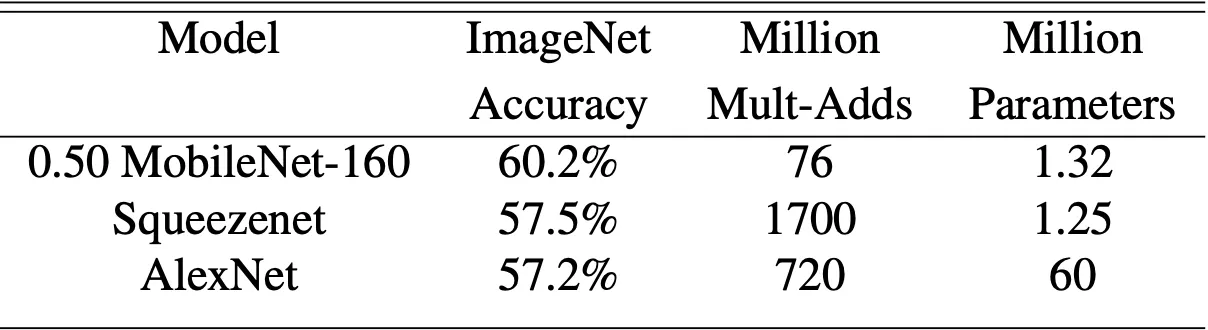
먼저, 좌측의 기본 MobileNet 은 VGG16 에 비견될만큼의 accuracy 를 보였는데, 네트워크 size 는 32 배 작고, computational cost 는 27 배 적었습니다. 더불어 GoogLeNet 보다 2.5 배 정도 size 및 computational cost 가 작은데도 불구하고 accuracy 가 높았습니다.
다음으로 우측의 인 MobileNet 과 accuracy 가 비슷했던 이전의 네트워크들과의 비교를 진행합니다. 가 적용된 MobileNet 은 AlexNet 보다 45 배 size rk wkrrh 9.4 배 적은 computational cost 를 가졌지만 4% 높은 accuracy 를 보여주었습니다. 더불어 SqueezeNet 보다는 22 배 정도 작은 size 와 computational cost 를 가짐에도 마찬가지로 4% 높은 accuracy 를 보여주었습니다.
Fine Grained Recognition
논문에서는 MobileNet 에 Fine Grained Recognition task 를 적용하여 state of the art network 인 Inception V3 와의 성능비교를 진행합니다. 상당히 크고 noisy 한 web data 를 모아 pretrain 한 뒤 Stanford Dogs dataset 으로 fine tuning 하는 형태로 학습을 진행했습니다.
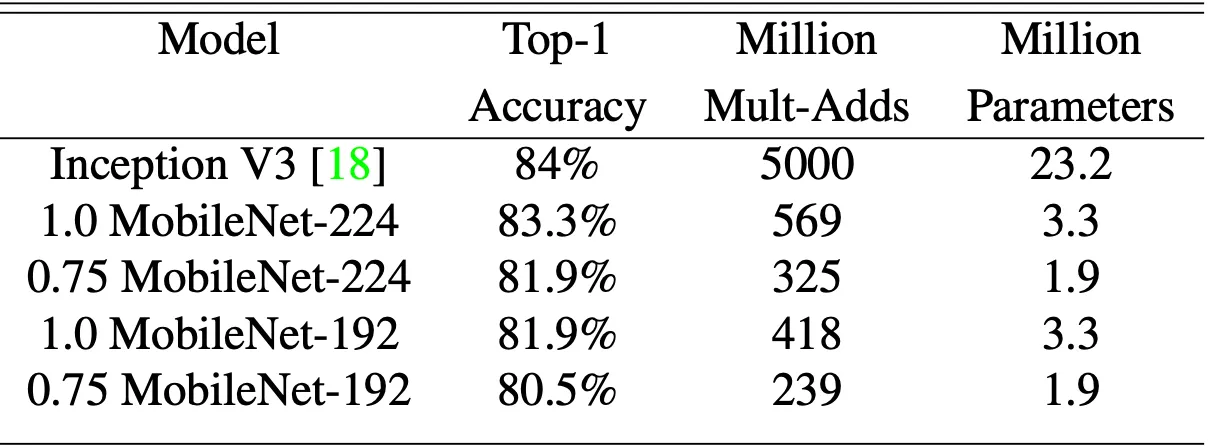
그 결과 위 표에 보이는 바와 같이 상대적으로 굉장히 적은 parameter 와 computational cost 로 Inception V3 에 거의 근접한 성능을 낼 수 있었습니다.
Large Scale Geolocalization
논문에서는 상당히 독특한 실험을 진행합니다. 지구의 사진을 geographic cell 로 classification 하는 task 에 MobileNet 을 학습시켜 본 것입니다. 이러한 task 를 Large Scale Geolocalization 이라고 합니다.
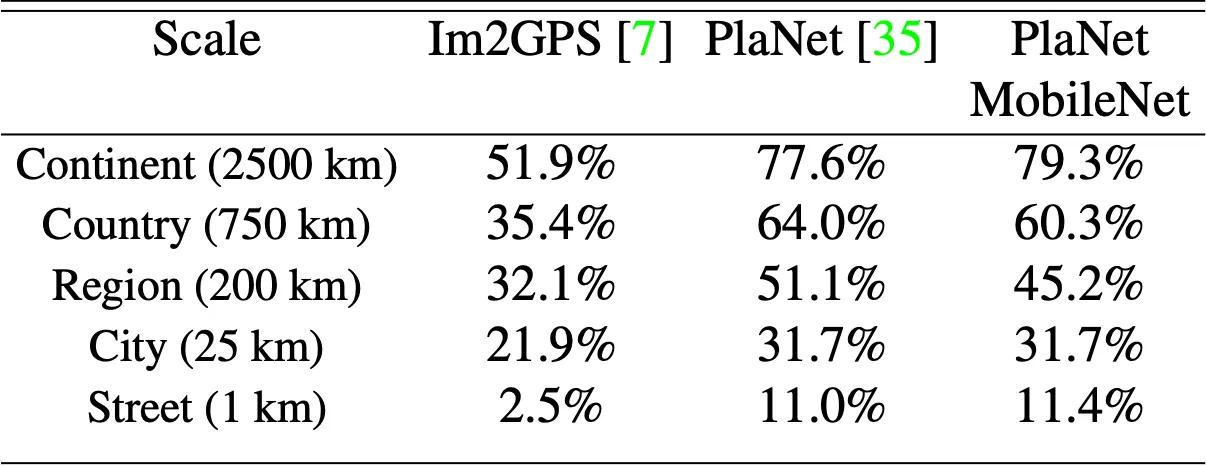
Large Scale Geolocalization 으로 유명한 네트워크는 PlaNet 과 Im2GPS 가 있었는데, 예상하셨겠지만 MobileNet 은 Im2GPS 를 뛰어넘고, PlaNet 과 비견될 정도의 성능을 보여주었습니다. 특히 Inception V3 를 기반으로 한 PlaNet 은 520 만개의 parameter 와 57.4 억번의 multi-adds 연산이 필요했던 반면, MobileNet 은 130 만개의 parameter 와 5.8 억번의 multi-adds 연산만을 사용했습니다.
Face Attributes
다음으로, 논문에서는 knowledge distillation 과 MobileNet 을 접목시켜 face attribute classification task 를 진행합니다. 750 만개의 parameter 와 16억번의 연산을 가진 classifier 를 MobileNet 으로 reduce 하는 시도를 했고, 이를 위해 ground truth 대신에 해당 classifier 의 output 을 label 로 사용하여 학습을 진행했습니다.
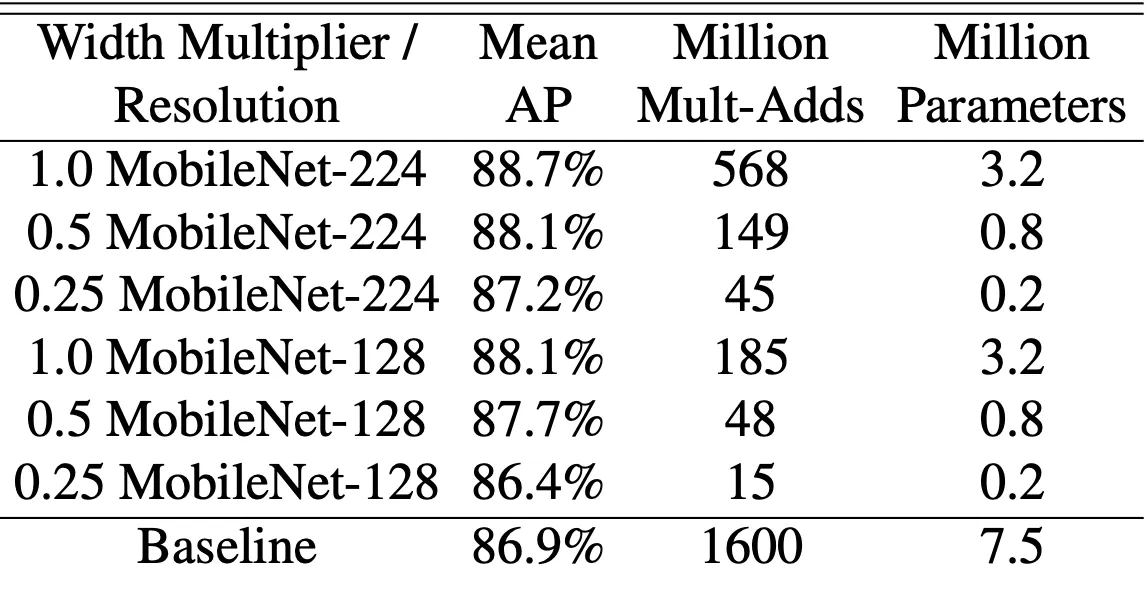
Knowledge distillation 의 확장성과 MobileNet 의 적은 parameter 로 인해서 학습 과정에서의 regularization 이 필요 없고 오히려 기존 baseline 보다 높은 MAP 를 가져오는 결과를 이끌어낼 수 있었습니다. 더불어 기존보다 약 1% 정도의 multi-adds 만 사용하고도 1% 정도밖에 떨어지지 않는 성능을 도달할 수 있었습니다.
Object Detection
논문에서는 MobileNet 은 object detection 분야에서도 효과적인 base network 가 될 수 있음을 보여줍니다. COCO dataset 을 기반으로, 학습한 MobileNet 은 SSD 300, Faster-RCNN 300, Faster-RCNN 600 의 framework & resolution 에서 다른 모델과 함께 평가됩니다.

SSD 와 Faster-RCNN 모두에서 MobileNet 은 매우 적은 multi-adds 와 parameter 를 가지고 VGG 와 Inception 에 도전할만한 성능을 보여주었습니다.
Face Embeddings
마지막으로, 논문에서는 face recognition 에 특징점이 될 지점들을 추출해 내는 face embedding task 를 MobileNet 에 적용시켜봅니다. Face Attribute 때와 마찬가지로 face embedding 분야의 state of the art 네트워크인 FaceNet 을 기반으로 knowledge distillation 을 진행하였고, 두 네트워크의 output 의 squared error 를 줄이는 방향으로 학습을 진행했습니다.
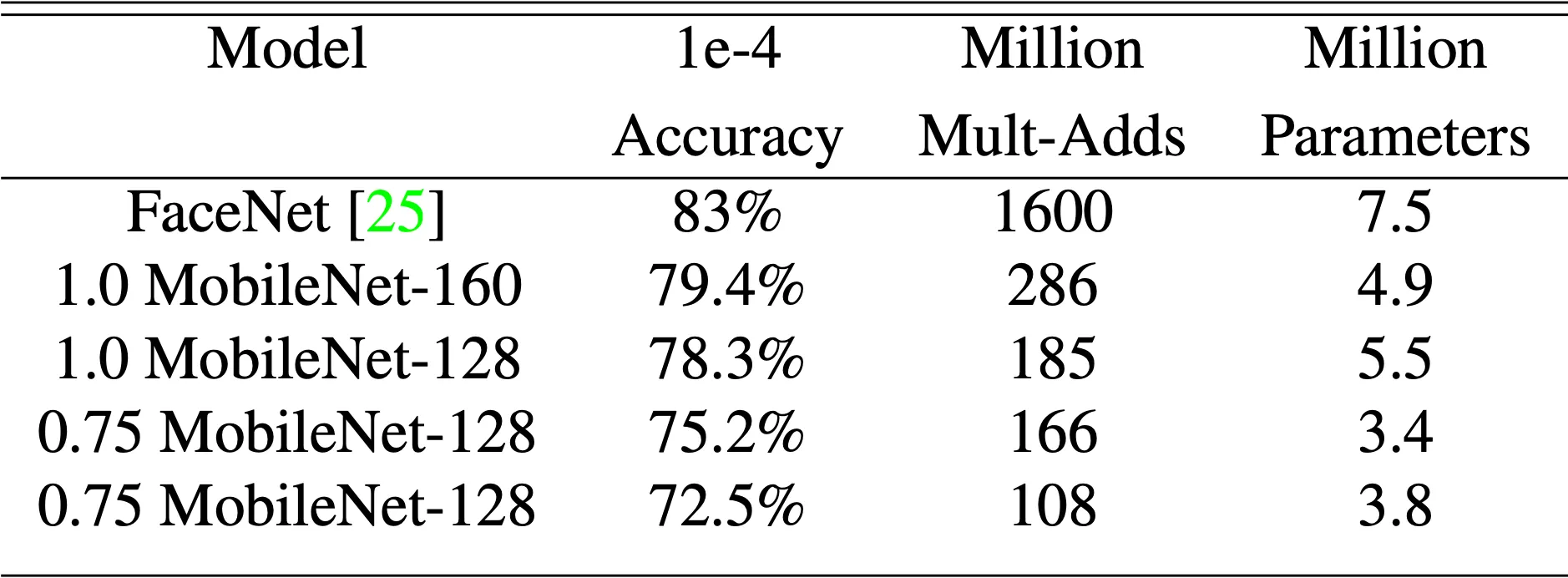
그 결과 지금까지와 마찬가지로, 작은 네트워크로도 기존에 비견될 만큼 좋은 성능을 뽑아낼 수 있음을 보일 수 있었습니다.
Conclusion
이것으로 논문 “MobileNets: Efficient Convolutional Neural Networks for Mobile Applications” 의 내용을 간단하게 요약해보았습니다.
EfficientNet 을 읽으면서 중간에 등장한 네트워크라 관심을 가지고 있었는데 이번 기회에 한 번 읽어보았습니다. 전반적으로 논문에서 이야기하고자 하는 바는 굉장히 간단한 것에 비해서 실험적으로 검증한 것이 굉장히 많은 느낌이었습니다. 때문인지, 논문에서 얻어가는 것이 많이는 없는 것 같다는 느낌도 들었던 것 같습니다. 개인적으로는 관심 있으신 분들은 한 번 읽어보시고, 그렇지 않으시다면 간단하게만 훑어보는 느낌으로 공부하셔도 좋을 것 같습니다.
