본 포스트에서는 기존의 2D Image 에서 진행되었던 Diffusion Process 를 Latent Space 로 변경하여 효율적으로 다양한 가이던스에 기반하여 고해상도 이미지의 생성에 성공해낸 논문에 대해서 소개드리려고 합니다.
논문을 직접 읽어보시고 싶으신 분들은 위 링크를 참고하시면 좋습니다.

Objective
Denoising Autoencoder 를 사용한 Diffusion Models 들은 Image Synthesis 분야에서 SOTA 를 달성한 것은 물론 Guiding Mechanism (Conditional Guide 를 제공하는 방법론) 부가적인 학습 (e.g. fine-tuning) 없이도 이미지 생성을 조절할 수 있었습니다. 하지만, 이들의 동작은 이미지의 픽셀 단에서 이루어지기 때문에 성능이 좋은 것으로 알려진 Diffusion Model 들은 학습에 100+ 시간이 소요되기도 했습니다.

FID ans PSNR Score of Reconstruction Task
논문에서는 제한된 리소스를 활용하더라도 기존의 Diffusion Model 들이 가지고 있던 성능과 유연함을 유지하도록 하기 위해 Pretrained Autoecncoder 를 사용하여 Latent Space 단에서 Diffusion Pipeline 을 설계합니다.더불어, Cross-Attention Layer 를 해당 pipeline 에 넣음으로써 text 나 bounding box 같은 conditional guidance 를 바탕으로 고해상도 이미지를 생성했다고 합니다.
논문에서는 이러한 그들의 모델을 Latent Diffusion Model (LDM) 이라고 부르고, Text2Image Synthesis, Unconditional Image Generation, Super Resolution 등의 분야에서 pixel-based Diffusion Model 들의 성능과 견줄만한 SOTA score 를 얻어냈다고 주장합니다.
Method
논문에서 제시한 Latent Diffusion Model 의 전체적인 파이프라인은 아래의 그림과 같습니다.
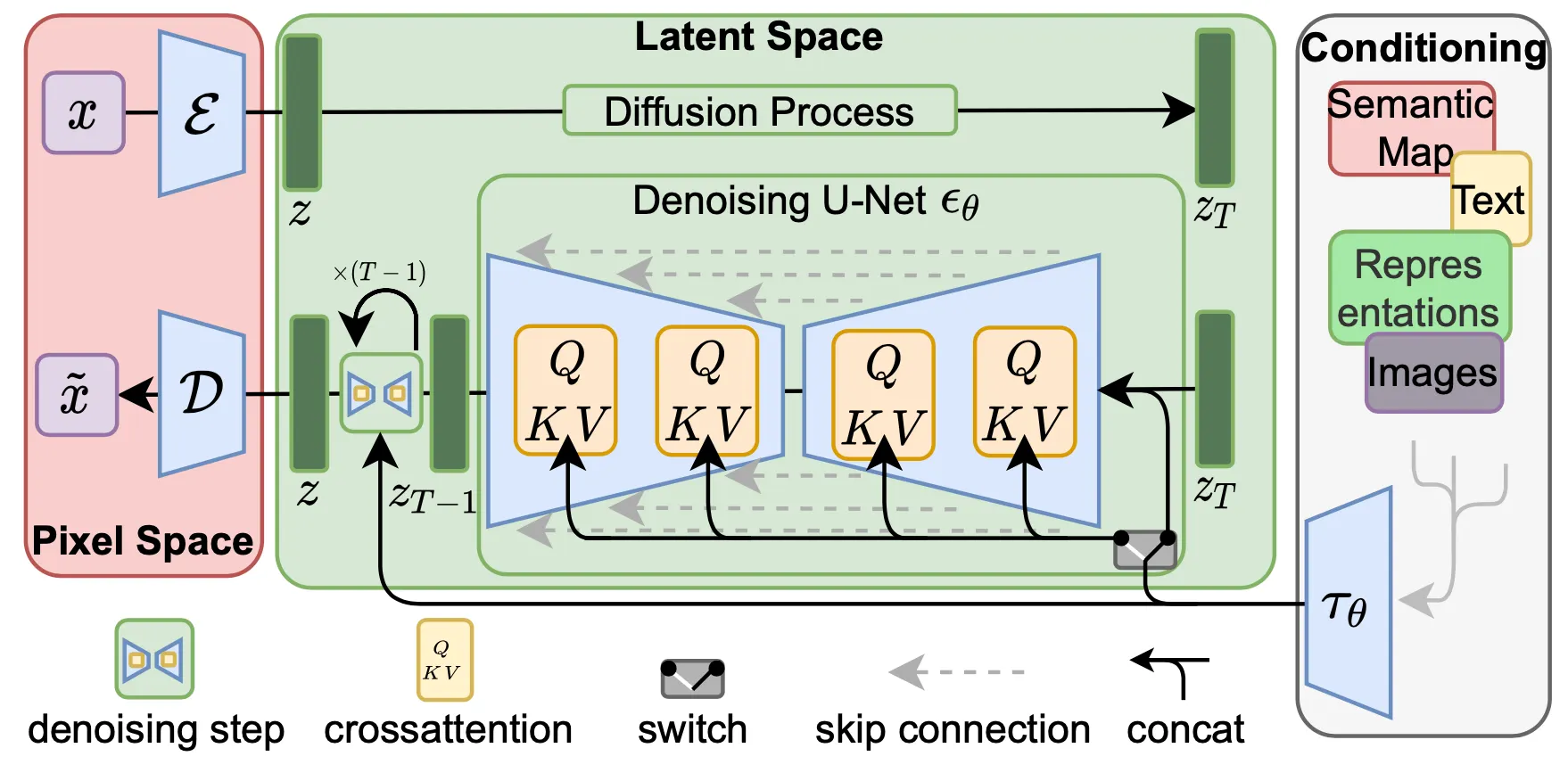
Overall Structure of Latent Diffusion Model
위 그림에서 표현된 논문의 방법론은 크게 세 가지로 나눌 수 있습니다.
1.
Perceptual Image Compression 단계에서 이미지 를 low dimensional latent space 로 mapping 합니다.
2.
Latent space 에서 Diffusion Model 을 선언하여 Forward Process 를 진행합니다.
3.
Cross-Attention 기반의 Conditioning Mechanism 을 설계하여 Reverse Process 를 진행하고 이미지를 복원합니다.
각각의 과정에 대한 구체적인 설명은 이어서 설명드리겠습니다.
Perceptual Image Compression

Compression Model
DDPM 과 같은 기존의 Diffusion Model 들도 지각적으로 불필요한 정보를 무시하기 위해서 Loss Term 에서 undersampling 을 행하지만, 여전히 Cost Function 자체가 이미지의 픽셀단에서 정의되어 있기 때문에 연산에 리소스가 많이 필요합니다.
논문에서는 이를 해결하기 위해 Autoencoding Model 을 사용하여 기존 이미지단과 지각적으로 동일하면서도 (충분한 정보를 보유하여 복원 가능한- 정도의 의미로 보입니다.) 차원이 낮은 공간을 학습하게 됩니다. 논문에서는 이러한 Compression Model 이 다음과 같은 의미가 있다고 주장합니다.
1.
차원이 낮은 공간에서 Diffusion Model 의 Sampling 이 이루어지기 때문에 효과적임.
2.
U-Net 구조로부터 Diffusion Model 의 Inductive Bias 를 추출해내어 Aggressive, Quality-Reducing Compresion Level 의 필요성을 완화할 수 있음.
3.
Single Image CLIP-guided Synthesis 와 같이 다른 downstream application 들에도 사용될 수 있는 범용적인 Compression Model 을 얻음.
논문에서는 encoder 를 두어 주어진 input image 을 를 통해 latent space 로 mapping 합니다. 이 때 downsampling rate 는 의 형태를 지니며 이 때문에 latent vector z 또한 2-dimensional vector 의 형태가 됩니다. 이러한 설계는 1-dimensional latent space 를 사용한 선행연구들에 비해서 상대적으로 mild compression 을 사용한다고 볼 수 있고, 좋은 reconstruction 을 달성할 수 있었다고 합니다.
이 latent space 가 높은 분산을 가지지 않도록 하기 위해서 논문에서는 크게 KL-reg 와 VQ-reg 을 도입하는데, KL-reg 는 분포가 standard normal 과 비슷하도록 하는 regularizor 이며 VQ-reg 는 decoder 에 vector quantization layer 를 추가한 형태의 regularizor 입니다.
Latent Diffusion Models
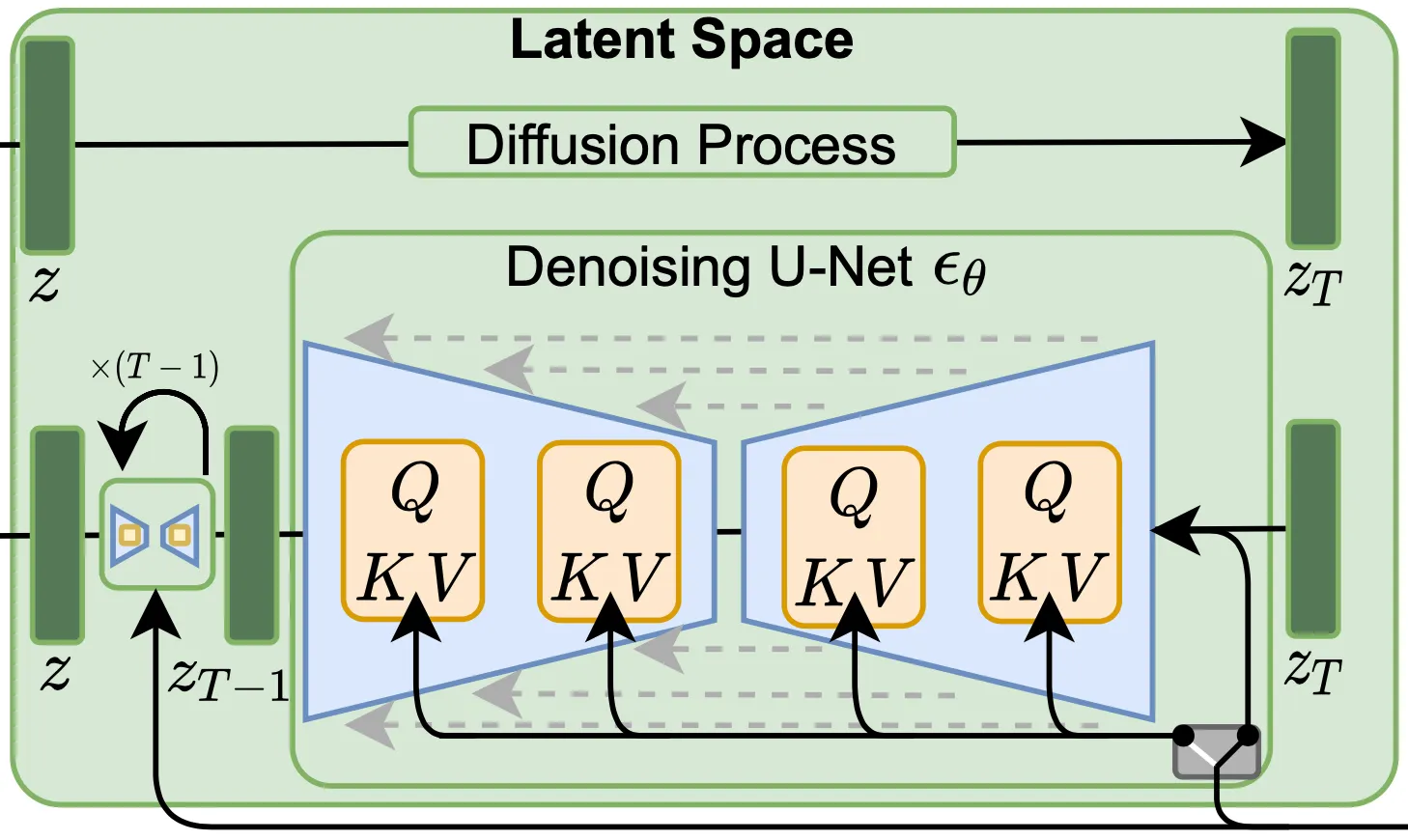
Latent Diffusion Model
논문에서 제시하는 Latent Diffusion Model 에 대한 이해를 위해서는 Diffusion Model 에 대한 이해가 필요합니다. Diffusion Model 은 Markov Noise Process 의 역과정인 Denoising process 를 학습하는 확률 모델입니다. Denoising Autoencoder 에 대해서 objective 는 다음과 같이 정의됩니다.
위 식에서 은 noise variant 입니다. 이는 초기 입력 값에 어떤 noise 를 추가할지를 결정하는 요소입니다. 위 식에서 적혀있는 것처럼 standard normal distribution 에서 sampling 하여 각 학습 iteration 별로 사용하게 됩니다. 즉, 위의 cost function 은 Denoising Autoencoder 가 noise 된 입력과 그 timestep 이 입력으로 들어왔을 때 해당 iteration 의 Markov Noise Process 에 어떤 noise 가 추가되었는지를 예측해내도록 네트워크를 학습합니다. 논문에 자세히 적혀있지는 않지만, 이렇게 각 가 어떤 noise 가 추가되었는지를 예측해내면, 이를 이용해서 noise 가 한 단계 제거된 값과 예측 원본 모두 단순 연산으로 계산해낼 수 있습니다. 이렇게 noise 가 한 단계 제거된 값은 다음 Denoising Autoencoder 에 들어가 동일한 과정을 반복합니다.
논문에서는 앞선 Perceptual Image Compression 부분에서 언급된 것과 같이 low dimensional latent space 로 mapping 하는 과정이 처음에 존재하기 때문에 이미지 단이 아니라 latent space 단에서 Diffusion Model 을 수행합니다. 논문의 이러한 설계는 모델이 데이터의 중요하고 의미 있는 부분에 초점을 맞추는 것을 용이하게 하고, 계산의 비용이 저렴한 장점이 있다고 합니다. Latent Space 상에서 Diffusion Model 을 적용하고자 한 시도를 반영하면 다음과 같은 objective 가 정의됩니다.
Conditioning Mechanisms
Text, Semantic Maps 와 같은 condition 을 기반으로 conditional distribution 를 모델링하는 것은 Conditional Autoencoder 를 사용함으로써 구현할 수 있다는 것을 선행연구에서 보여주었습니다. 하지만, class-label 과 blurred variants of the input image 를 condition 으로 하여 이미지를 생성하는 것은 선행연구들에서 다루지 못했던 영역이었습니다.
논문에서는 기존의 Diffusion Model 을 조금 더 flexible 한 Conditional Image Generator 로 개선하기 위해서 U-Net backbone 구조에 Cross-Attention 를 적용하여 변경합니다. 다양한 modality y 의 정보를 pre-processing 하기 위해 논문에서는 를 를 통해 새로운 representation 으로 mapping 합니다. 이렇게 mapping 된 representation 을 기반으로 논문에서는 Cross-Attention 개념을 적용합니다.
위 식에서 는 Denoising Process 에서 등장하는 intermediate representation (U-Net 내부에 중간단계에서 나타나는 representation) 이며, 는 학습 가능한 parameter 들입니다. 최종적으로는, Cross-Attention 을 반영한 형태의 conditional LDM loss 를 다음과 같이 정의하게 됩니다. 여기서, 각 attention 을 계산하는 transformer layer 는 공유하지 않습니다.
정성적으로 해석해보자면, 기존 noise 에 대한 이미지 정보 와 step 정보 뿐만 아니라 condition 에 대한 정보를 embedding 한 벡터에 대한 가중합을 Cross-Attention 으로 정의하여 새로운 representation 을 사용했고, 이를 기반으로 Markovian Reverse Process 의 분포를 예측하게 함으로써 condition 을 반영한 분포가 condition 과 함께 주어진 이미지를 최종적으로 생성하도록 유도함으로써 conditional 한 synthesis 를 달성했다고 볼 수 있습니다.
Experiments
On Perceptual Compression Tradeoffs
논문에서는 그들의 Perceptual Compression 방법론의 효과를 검증하기 위해서 downsampling factors 를 조정해가며 Reconstruction Task 에 대한 실험을 진행합니다. 각각의 모델을 factor 의 값에 따라 다르게 라 칭하며 이에 따라 인 경우가 기존의 Pixel-based Diffusion Model 인 경우가 됩니다.
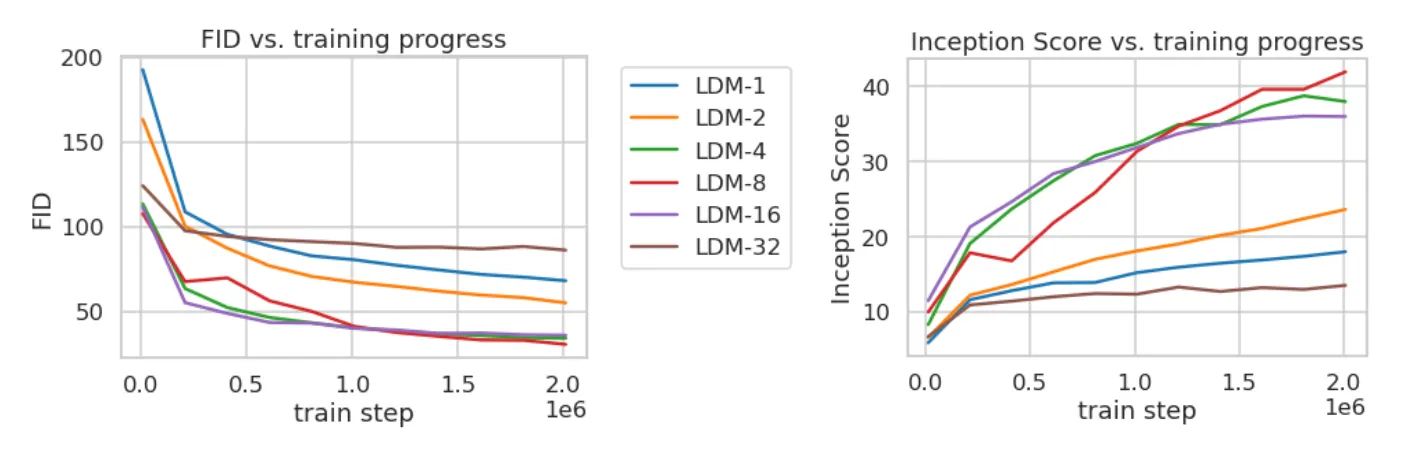
Training Time and FID of Reconstruction
위 표는 Class-Conditional LDM 의 학습을 분석한 그래프입니다. 와 같이 downsampling rate 가 작은 경우에는 전반적으로 training 이 느린것을, 와 같이 downsampling rate 가 매우 큰 경우에는 얼마 지나지 않아 학습의 정체가 오는 것을 확인할 수 있었습니다.
논문에서는 첫 번째 현상을 거의 대부분의 Perceptual Compression 에 대한 역할을 Diffusion Model 에 이관하기 때문으로, 두 번째 현상을 선행적으로 진행되는 매우 큰 Perceptual Compression 이 정보의 손실을 유발했기 때문으로 보고 있습니다. 가장 적절한 의 선택은 까지라고 합니다.
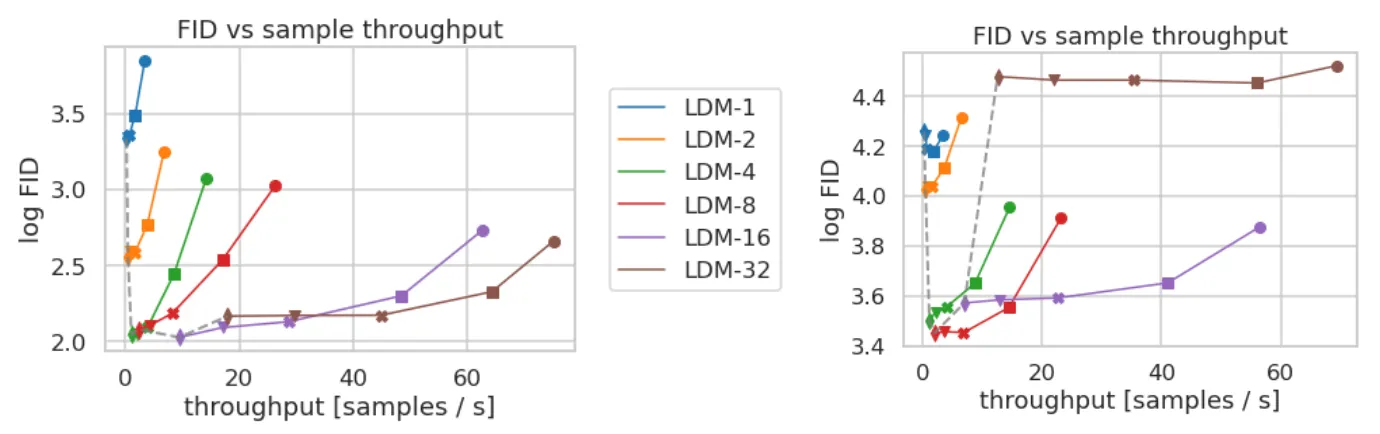
Comparing LDMs with varying Compressions on CelelA-HQ and ImageNet
위 표는 Sampling Speed 와 FID 관점에서 CelebA-HQ 데이터셋과 ImageNet 데이터셋에서의 LDM 을 값에 따라 비교한 결과를 나타낸 그래프입니다. Sampling Speed 는 클수록, FID 는 작을수록 좋은데, 논문에서는 정도의 세팅들이 적절한 수준으로 보았고, 특히 과 비교했을 때 유의미하게 낮은 FID 와 Sampling Speed 를 보여줌을 확인할 수 있었습니다. 특이하게 발견할 수 있는 점은 조금 더 복잡한 장면들이 많이 존재하는 ImageNet 데이터의 경우에는 quality 를 위해 너무 큰 downsampling factor (e.g. 32) 를 사용하면 안된다는 것을 확인할 수 있었다고 합니다.
Image Generation with Latent Diffusion
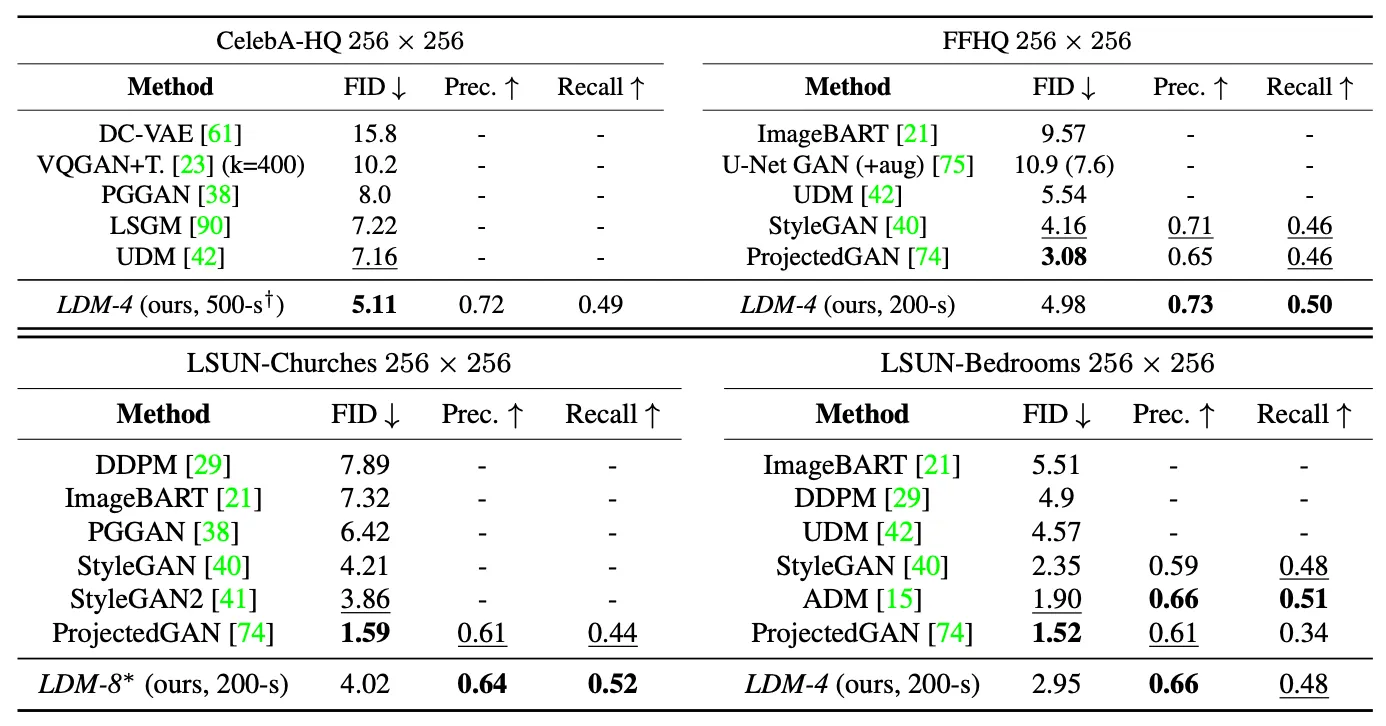
Evaluation on Unconditional Image Generation
위 표는 크기의 CelebA-HQ, FFHQ, LSUN-Churches, LSUN-Bedrooms 데이터셋을 사용하여 unconditional 모델을 학습한 결과를 평가한 표입니다.
CelebA-HQ 데이터셋에 대해서는 FID 5.11 의 수치로 기존의 likelihood-based model 들과 GAN 류, LSGM 을 이기고 새로운 SOTA 를 달성했습니다.
LSUN-Bedrooms 데이터셋에 대해서는 앞선 diffusion based 방법론들에 비해 낮은 FID 수치를 얻었고, ADM 에 비해서는 높은 FID 수치였지만 그것보다 절반의 parameters 로, 4배 빠르게 학습을 했다는 점에서 방법론의 이점을 강조합니다.

Qualitative Results on Reconstruction
위 그림은 논문에서 제시한 qualitative result (reconstruction) 입니다. 논문에서는 이에 대한 세부적인 설명은 해주지 않고 있습니다.
Conditional Latent Diffusion
Transformer Encoders for LDMs
논문에서는 Cross-Attention 기반의 conditioning 방법론을 도입하여 앞선 선행연구에서 사용하지 못했던 다양한 conditioning modalities 들을 사용한 생성을 진행해볼 수 있었습니다. Text-to-Image Model 의 경우, 논문에서는 τθ 로 BERT-tokenizer 를 사용했고, LAION-400M 의 language prompt 를 사용했습니다.

Qualitative Results on Text to Image Generation
위 그림은 논문의 방법론으로 학습한 Text-to-Image Generation 모델의 결과물입니다. 논문에서는 위 결과를 바탕으로 Language Representation 을 잘 학습한 BERT tokenizer 와 LDM 기반의 Visual Synthesis 가 합쳐진 Pipeline 이 복잡한 유저 입력 prompt 에도 일반적으로 잘 동작하는 강력한 모델을 생성할 수 있었다고 주장합니다.

Quantitative Comparison on Text to Image Generation (MS COCO)
위 표는 MS COCO 데이터셋으로 Text to Image Generation task 에 대해 qualitative comparison 을 진행한 결과입니다. 그 결과 classifier-free diffusion guidance 를 도입한 것이 성능에 유의미한 결과가 있음을 밝혀냈고, 이를 도입한 논문의 구현체는 SOTA 로 불리던 AR 기반의 Make-A-Scene, Diffusion 기반의 GLIDE 와 비슷하게 낮은 FID 를 얻어냈습니다.

Quantitative Comparison on Image Generation (Class-Conditional ImageNet)
MS COCO 데이터셋 뿐만 아니라, 논문에서는 class-conditional ImageNet 모델에 대한 평가를 진행하고, 이는 위 표에 나타나 있습니다. 논문에서는 이 분야의 SOTA 인 ADM (Guided DIffusion) 보다 성능도 좋음과 동시에 유의미하게 연산 및 필요한 parameters 들을 줄였다고 주장합니다.

Layout to Image Synthesis Results
논문에서는 더불어 Cross-Attention with Conditioning Mechanism 방법론의 flexibility 를 보여주기 위해 OpenImages 의 Semantic Layout 을 사용하여 Layout-to-Image Synthesis 결과를 보여줍니다.
Convolutional Sampling Beyond
논문에서 spatially aligned conditioning 정보를 에 concatenate 하는 과정을 통해 LDM 은 일반적인 Image-to-Image Translation task 를 다룰 수 있다고 합니다. 논문에서는 이 방법을 통해 Semantic Synthesis, Super Resolution, Inpainting 과 같은 task 를 수행할 수 있었다고 합니다.
일례로, Semantic Synthesis 와 같은 경우에는 landscape 이미지와 쌍을 이루는 semantic map 을 준비하고, 두 이미지를 모두 latent space 로 mapping 한 뒤에 이 둘을 concatenate 하는 방식을 사용했다고 합니다.

Semantic Synthesis Result
Super-Resolution with Latent Diffusion
앞선 Semantic Synthesis 와 마찬가지로 LDM 은 저해상도 이미지의 latent vector 를 concatenate 하는 과정을 거쳐서 Super Resolution task 를 타겟할 수 있습니다. 다만 특이하게 이 경우에는 를 identity 로 사용합니다.


Qualitative & Quantitative Results of Super Resolution
논문에서는 SR3 의 pipeline 을 따라서 ImageNet 을 활용해 image degradation 을 bicubic interpolation 으로 설정하여 학습을 진행합니다. 전체적으로 논문의 방법론을 활용한 것과 SR3 의 것은 비슷한 수준의 평가 결과를 보여주었는데 LDM-SR 은 SR3 보다 FID 가 낮고, SR3 는 LDM-SR 보다 IS 가 높았습니다. 특이한 점은 제일 간단한 Image Regression 방법론이 가장 높은 PSNR 과 SSIM 을 보였는데 논문에서는 이 metric 은 Human Perception 과 일치하지 않는 경우들이 존재함을 시사합니다.

User Study on Results of Super Resolution
더 나아가 논문에서는 Pixel-based Diffusion Model 과 논문의 방법론으로 진행한 Super Resolution 결과에 대한 User Study 를 제시합니다. 첫 번째 task 의 결과로 적혀져 있는 것은 ground truth 와 생성된 이미지 중 더 품질이 좋은 것을 선택하라는 질문에서 생성된 이미지가 선택된 비율이고, 두 번째 task 의 결과로 적혀져 있는 것은 두 개의 생성된 이미지 중 더 품질이 좋은 것을 선택하라는 질문에서 각 이미지가 선택된 비율입니다. 논문에서는 이 결과를 통해 기존 Pixel-based Diffusion Model 에 비해서 유의미하게 Super Resolution task 의 결과가 좋음을 시사했습니다.
Inpainting with Latent Diffusion
논문에서는 최근 inpainting 모델인 LaMa 의 프로토콜을 따라서 평가를 진행합니다.
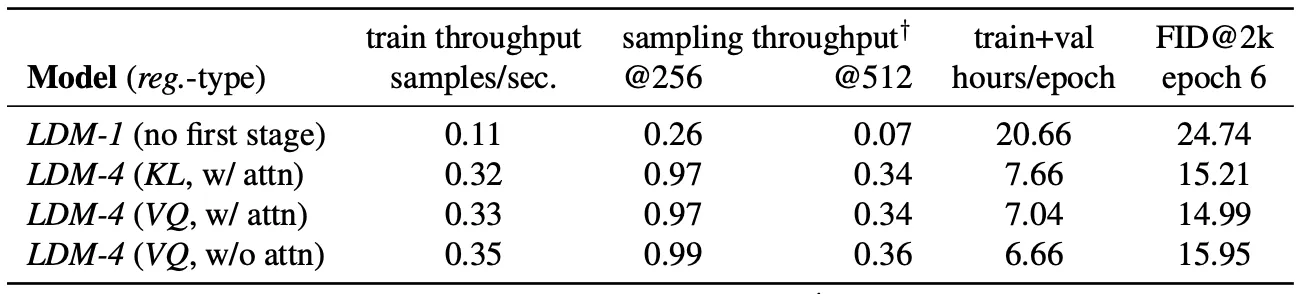
Comparison of Inpainting Efficiency
가장 먼저 논문에서 제시한 것은 LDM 의 downsampling factor 에 따른 Inpainting task 의 efficiency 에 관한 표입니다. 최종적으로 Pixel-based Diffusion 에 비해서 약 2.7 배 가량의 speed up 및 1.6 배의 FID 점수의 감소를 얻어낸 것을 확인할 수 있습니다.
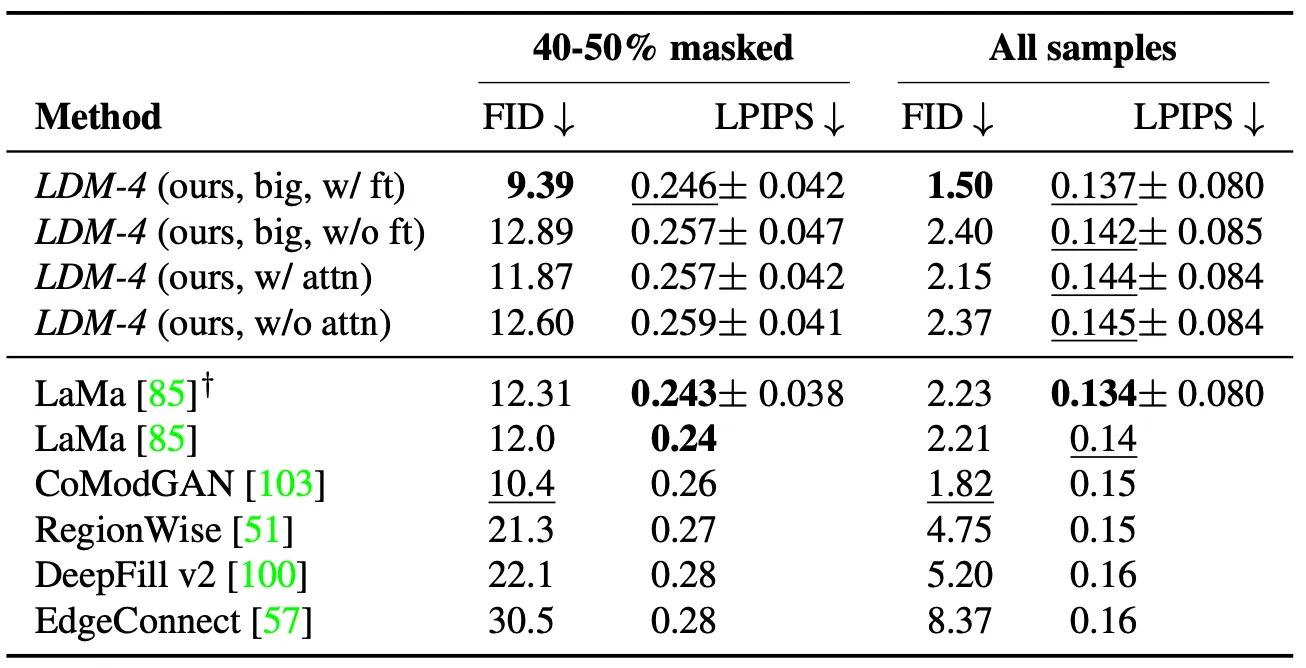
Comparison with Other Inpainting Approaches
위 표는 논문의 방법론과 다른 Inpainting 방법론을 비교한 것입니다. 표에서 볼 수 있듯이 논문의 방법론이 LaMa 보다 낮은 FID 를 얻을 수 있었고 unmasked 된 ground truth 기반으로 계산한 LPIPS 는 살짝 낮았습니다. 논문에서는 이러한 결과를 LaMa 의 방법론이 다양한 결과를 산출하는 LDM 과는 달리 단일 결과만을 산출하는 특성상 발생한 결과로 해석하고 있습니다.
또한, 위 표에는 big 이라고 적혀져 있는 실험 결과가 존재하는데, 이는 Guided Diffusion 논문에서 제시한 세팅 (Attention Layers on Three Levels of its feature hierarchy, BigGAN residual block for up- and downsampling) 으로 구성한 모델이며, 유의미한 성능 향상이 있었다고 합니다. 논문에서는 이를 부가적인 attention module 의 효과로 예상하고 있다고 합니다.
Conclusion
이것으로 논문 “High-Resolution Image Synthesis with Latent Diffusion Models” 의 내용을 간단하게 요약해보았습니다.
확실히 확률론 기반의 논문이 이해하기 어렵다는 사실을 다시금 깨닫게 해준 논문이었던 것 같습니다. 이전에 Diffusion Model 관련한 논문을 읽어놔서 그나마 편하게 읽을 수 있었던 것 같으며, VAE 와 함께 제가 읽었던 논문 중 투탑으로 어려웠지 않나… 라는 생각을 했습니다. 생성모델에서 큰 파장을 일으켰던 만큼, 엄청난 양의 실험을 포함해 논문의 퀄리티 자체도 높은 것 같았지만, 개인적으로는 논문만 보고 이해하기엔 난해한 부분이 많았던 것 같습니다. 때문에 부가적인 코드를 많이 찾아보았고 이해에 많은 도움을 주었던 코드들은 다음과 같습니다.



생성모델 쪽에 관심이 있으신 분은 한 번 읽어보시는 것도 추천드립니다. 하지만, 이 논문만으로 diffusion 을 다 알아야겠다는 접근은 별로 좋지 못한 것 같습니다. 이 논문만으로 이해가 어려운 부분들도 많고 실험 관련 부분은 살짝 잡다하게 많이 들어가 있는 느낌도 있어서, 관련 자료나 정리본, 코드 등을 통해 해당 도메인에 대한 지식을 어느정도 습득한 다음에 살펴보시는게 나은 것 같습니다.