
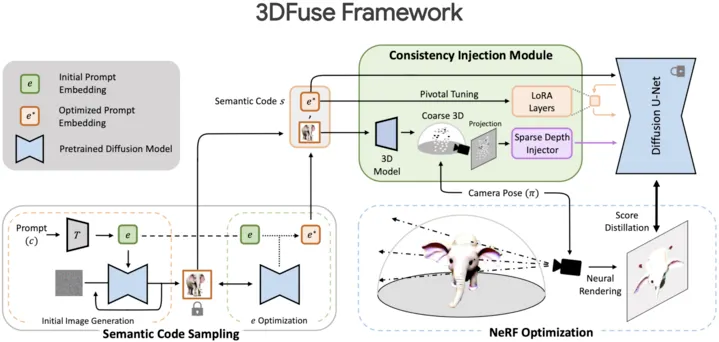
They mainly focused on injecting 3D-awareness ability into diffusion model. The main method is using previous method which construct point cloud from single rgb image, rendering it from same view point and use it as a depth prior of diffusion model.The full process is as below.
1.
To avoid text ambiguity, they use semantic code optimization (prompt token optimization) using two diffusion model. First they generate image with one, and second they optimize semantic code with another
2.
Using image generated from 1, they construct point cloud and render it as specific view point and use it as a depth prior of diffusion model. Also they use semantic code as text prior
3.
Use SDS to optimize NeRF