



How to Represemt Humans in 3D
•
Voxels (Volume Elements)
◦
Pixel 의 3D version
◦
각 volxel grid 부분이 occupied 되었는지, 아닌지로 3D 를 표현함. 다만, application 에 따라 각 voxel grid 에 floating point 를 assign 할 수도 있음.
◦
장점은 Shape, Volume, Occupancy 를 표현할 수 있고, 쉽게 구현이 가능하다는 것임.
◦
단점은 Semantic 을 표현할 수 없다는 것임.
▪
하나의 인간 volume 과 다른 인간 volume 간의 공통된 correspondence 를 정의하기 어려움.
▪
No correspondences between frames
•
Dense Trajectory
◦
각 점이 그리는 trajectory 를 트래킹하여 3D 를 표현할 수 있음.
◦
장점은 한 점이 어떻게 움직이는지 tracking 할 수 있다는 것임.
◦
단점은 손, 얼굴 등 semantic 에 대한 정보가 없다는 것임.
•
3D Skeleton
◦
Joint 와 그들의 연결관계를 통해 3D 를 표현할 수 있음.
◦
Multiview Images 들에 대해 keypoint 를 찾고 triangulation 을 함으로써 완성할 수 있음.
◦
장점은 Spatial, Temporal Correspondence 를 나타낼 수 있다는 것임.
◦
단점은 Shape, Volume, Occupancy 를 표현할 수 없다는 것임.
Single View 3D Human Pose and Shape Reconstruction
•
Multi view 기반으로 3D 를 재구성하는 것은 Triangulation 기반으로 진행할 수 있기 때문에 어려운 내용은 아니고, 보통은 Single view 기반으로 재구성하는 것을 목표로 함.
•
2D Representation → 3D representation
◦
2D Representation 은 RGB images, 2D Keypoints, 2D DensePose 등이 있음.
◦
3D Representation 은 3D Keypoints, 3D Volue, 3D Parameteric Model 등이 있음.
Input: 2D Keypoints → Output: 3D Keypoints
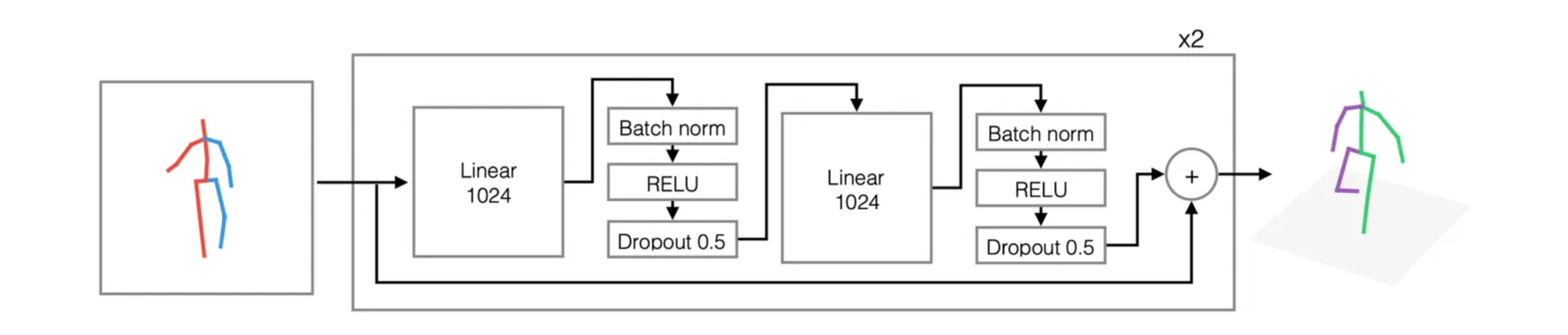
•
단순한 regression 문제
•
이 문제의 고전적인 어려움은 ground truth 로 사용할 수 있는 1. 3D dataset 의 부재 + 2. 존재하는 3D dataset 조차 캡처가 필요한 작업이라 Indoor Studio 에서 생성된 경우가 많다는 것임.
◦
Indoor paired 2D Image -3D Keypoint 데이터로 train 을 하게 되면 outdoor 에 적용했을 때 배경이 많이 다르기 때문에 잘 되지 않을 가능성이 높음.
◦
때문에 2D Keypoint 만을 뽑아서 input 으로 formulation 하면 이러한 문제를 해결할 수 있음.
•
두 가지 문제점은 다음과 같음.
1.
Origin 에 따라 joint 의 위치가 달라지기 때문에 normalization 이 중요함.
2.
Input 은 2D Keypoint 이기 때문에 기존 이미지에서 가지고 있던 양질의 정보가 다 삭제됨.
Input: 2D Keypoints → Output: 3D Parameteric Face Model
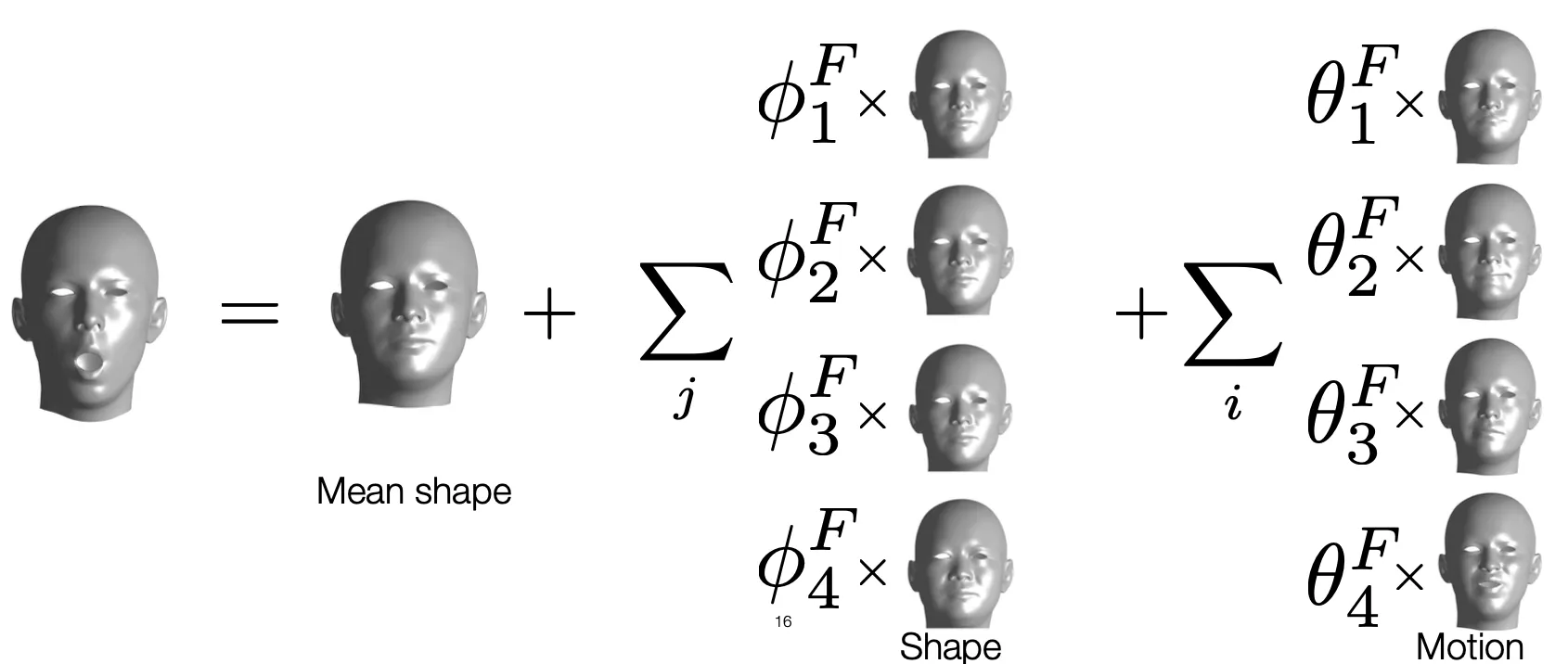
•
얼굴을 표현하기 위한 DoF 는 실제로 구성하는 vertices 의 position 개수 기반으로 () 표현되지는 않음. 그 이유는, 얼굴의 각 점들이 서로 연결되어 있기 때문임.
•
그렇다면 DoF 를 줄일 수 있을까?
◦
DoF 를 줄이기 위한 시도를 하기 위해서 모든 사람의 얼굴의 평균에 variation 을 더하는 방식을 채용함.
◦
특정 수 (reasonable number) 의 basis 를 두고 앞에 coefficient 를 두어 이들의 선형결합으로 구조적인 변화를 표현할 수 있음. (Shape)
◦
마찬가지로 특정 수 (reasonable number) 의 basis 를 두고 앞에 coefficient 를 두어 이들의 선형결합으로 표정의 변화를 표현할 수 있음. (Motion)
•
앞선 reasonable number 는 SVD 를 통해서 가장 중요한 방향의 변화의 수 몇 개를 뽑을 수 있음. (PCA Approach 라고 볼 수 있음.)
•
사람들을 모아 특정한 표정을 지으라고 요청을 하여 데이터를 구하고, 이들 데이터들 중에서 중요한 성분만 남겨서 basis 를 구성할 수 있음.
◦
사람을 바꾸면, Face Identity (Shape) 를 바꾸는 벡터를 얻을 수 있고, 이들 중 몇 개를 추림.
◦
다른 표정을 지으면 표정 (Motion) 을 바꾸는 벡터를 얻을 수 있고, 이들 중 몇개를 추림.
•
여기에 전체적인 (모든 점들이 동일한 방향) Translation 까지 더해 최종적인 Vertices 를 구성할 수 있음.
•
실제로는 Identity 와 Motion 이 완벽하게 independent 하지 않을 수도 있어 표현력이 부족할 수 있음.
Input: 2D Keypoints → Output: 3D Parameteric Body Model
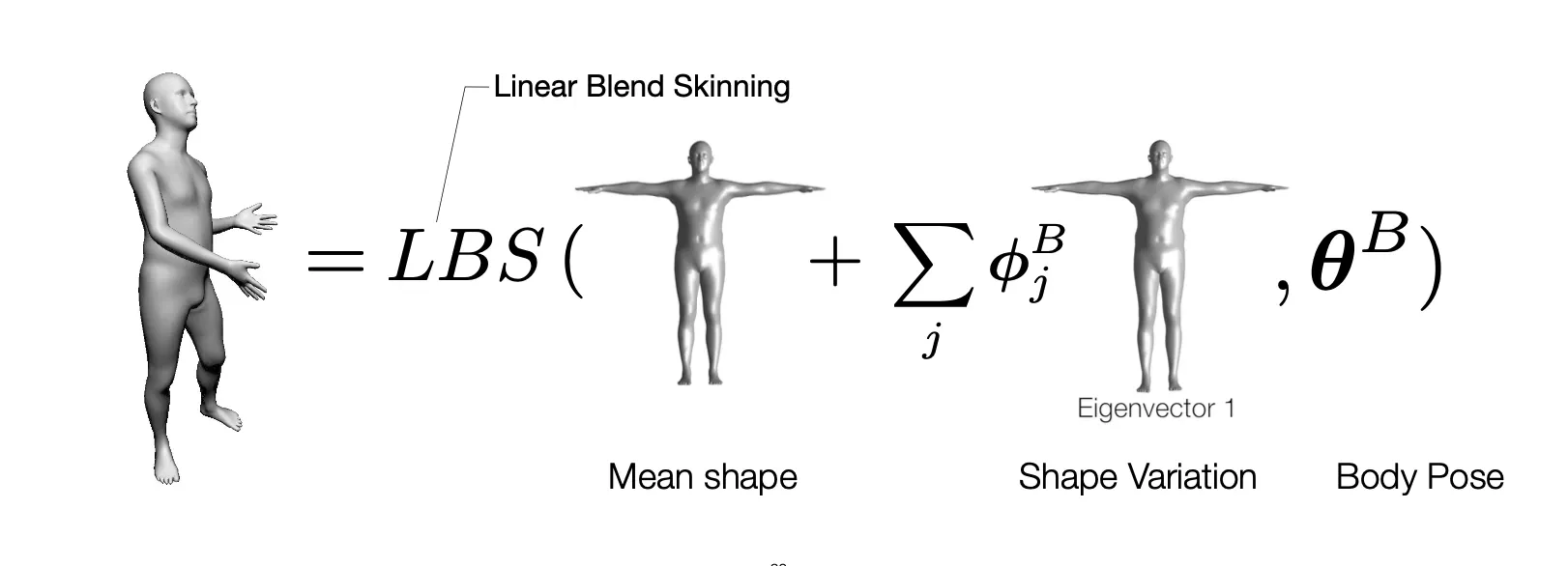
•
앞선 3D Parameteric Face Model 과 유사하게 Mean Shape 과 Shape Variation 을 나타내는 basis 및 coefficient 로 나타낼 수 있음.
•
여기에 각 Joint 마다의 3D angle 항목도 추가로 들어감. → 3D Skeleton 을 조절하는 역할을 함.
•
여기에 추가적으로 3D Skeleton 의 조절과 vertices 의 변화를 대응시키기 위한 Linear Blend Skinning 과정이 추가로 필요함.
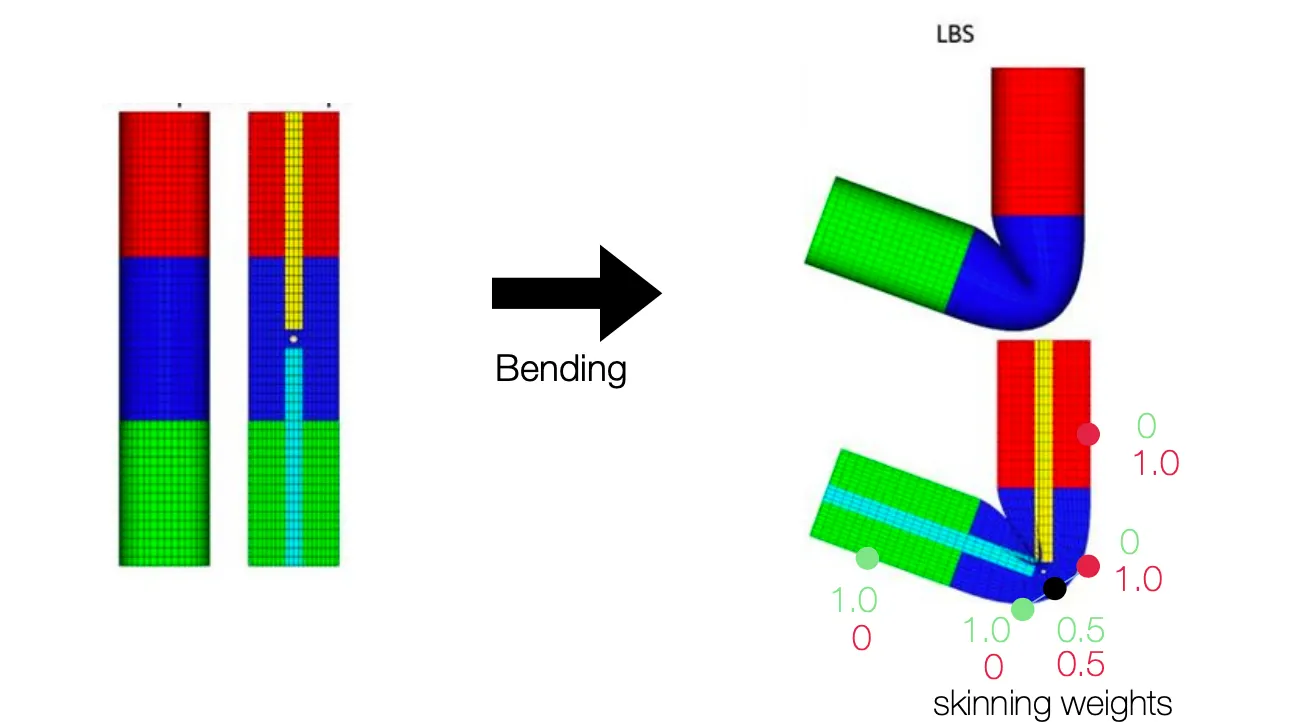
◦
Skeleton 이 움직일 때, vertices 의 변화를 구하는 방법
◦
Rigid 한 영역은 skeleton 을 그대로 따라가기 때문에 큰 문제가 없음.
◦
구부러지는 영역은 pre-defined parameters (vertices 마다 지정, Skinning Weight) 를 이용하여 skeleton 의 angle 에 따른 위치를 해당 parameters 의 비율로 interpolate 하여 새로운 vertex 를 찾아냄.
•
마찬가지로 여기에 전체적인 (모든 점들이 동일한 방향) Translation 까지 더해 최종적인 vertices 를 구성할 수 있음.
3D Parameteric Body Models: SMPL
•
일반적인 경우에는 vertices 와 joint 가 둘다 주어지고 joint 의 pose 만을 변형함.
•
하지만, 다양한 사람들을 표현하기 위해서 shape 를 변경해야 하고 다음과 같이 진행함.
1.
Deformed Mesh 에 Shape Parameters 를 도입함.
2.
Joint Regression (Linera Regression) 를 이용해 Joint Location 을 찾음.
3.
Body Pose Parameters 를 이용해 Skeleton Angle 을 적용함.
4.
Linear Blending Skinning 을 통해 vertices 를 변경함.
•
사람에 따라 다른 종류의 Body Model 을 사용하지 않아도 되게 해줌.
•
SMPL 은 추가적인 parameter 를 사용하여 pose 에 따른 shape 을 보정하여 더 자연스러운 pose 를 표현할 수 있도록 함. (pose-dependent blend-shape)
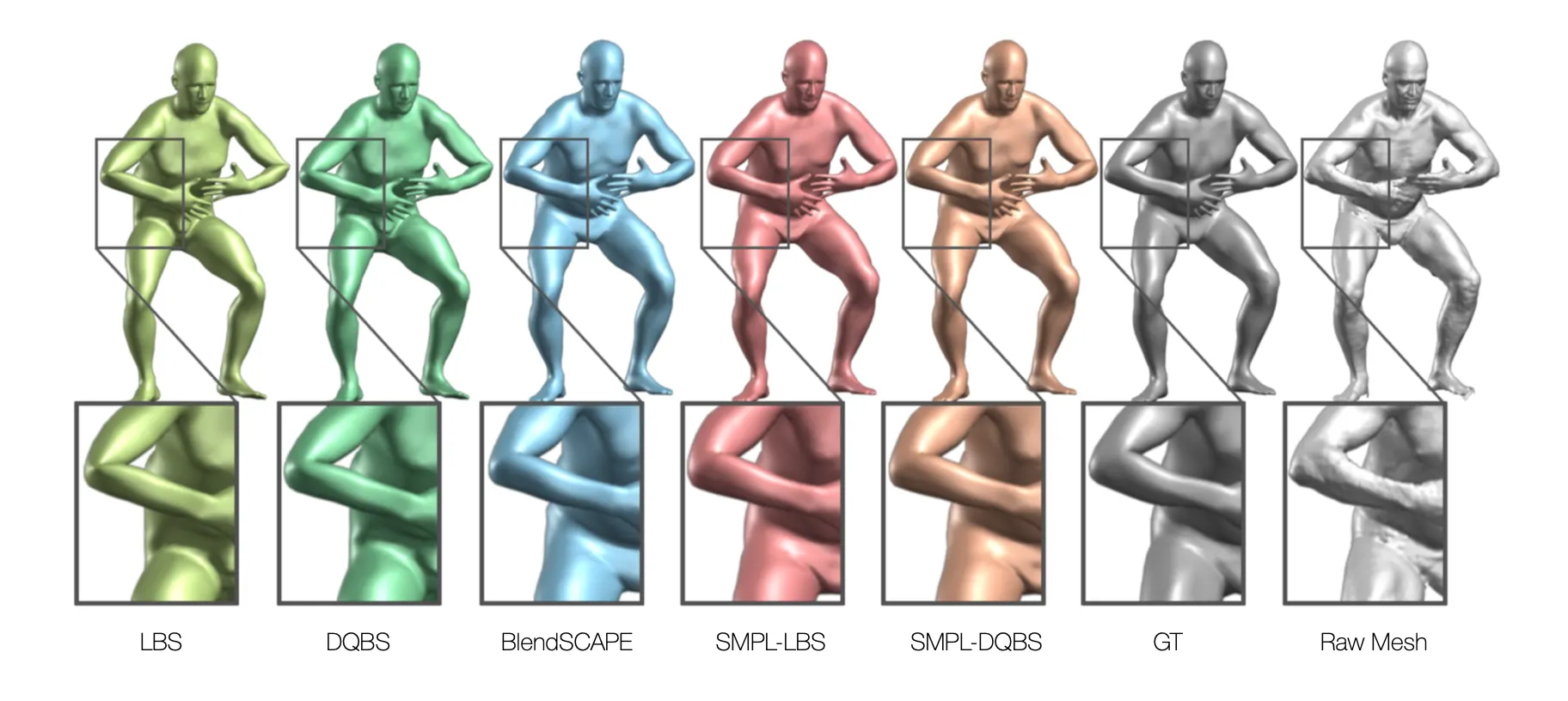
How to Fit a Parameteric Model on 2D Keypoints

•
가장 간단한 방법은 3D Parameteric Body Model 의 parameter 를 조정하여 projection 했을 떄 matching 이 잘 되는 값을 찾으려고 할 수 있음.
◦
다만 이러한 방법은, 2D 에 matching 이 잘되더라도 이상한 자세들이 나올 수 있음.

◦
이를 보정하기 위해 Prior 항목 를 추가한 것임.
•
장점은 Optimization 기반의 방법론이라 일반화가 잘되고 쉽다는 점임.
•
단점은 여전히 ambiguity 가 존재하며, 느리고, 좋은 initialization 이 필요하며 데이터와 Prior 항목의 밸런스에 대한 미세한 조정이 필요할 수도 있으며, Multi-Stage (Body First, Shape Later) Optimization 이 필요할 수도 있다는 점임.
Input: 2D RGB → Output: 3D Parameteric Model
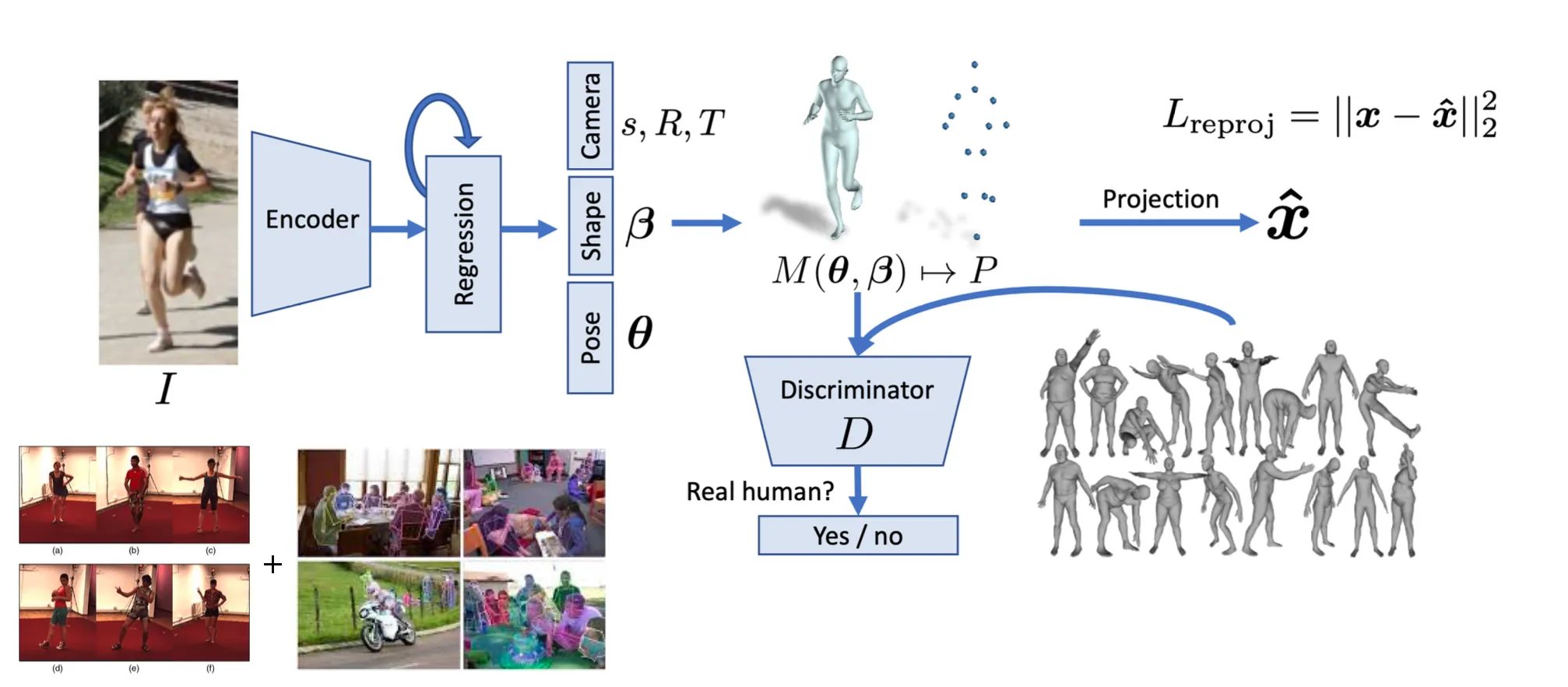
•
Image 를 입력으로 넣어 SMPL parameter parameter 를 regression 함.
•
Regression 한 SMPL 을 가지고 reproejction error 및 discriminator loss 로 optimize 할 수 있음.
•
얼굴이나, 손 등에도 동일한 approach 를 사용할 수 있음.
Input: 2D Dense Corres. Map → Output: 3D Parameteric Model
•
Image 는 domain issue 를 가지고 있고, 2D Keypoint 는 sparse 하기 때문에 2D DensePose 를 사용해볼 수 있음.
•
Pretrained DensePose-RCNN 을 거쳐 dense 한 keypoints 를 찾은 이후에 동일하게 SMPL parameter 를 regression 하는 방향으로 동일하게 진행이 가능함.
Input: Videos → Output: 3D Parameteric Model Sequences

•
Per-frame 방법론 보다 좀 더 smooth 한 결과를 얻을 수 있음.
◦
이전의 데이터도 가지고 inference 를 할 수 있기 때문임.
•
Severe occlusion 이 있는 경우에도 이전보다 robust 하다는 장점도 있음.
Adam: A Total Body Model
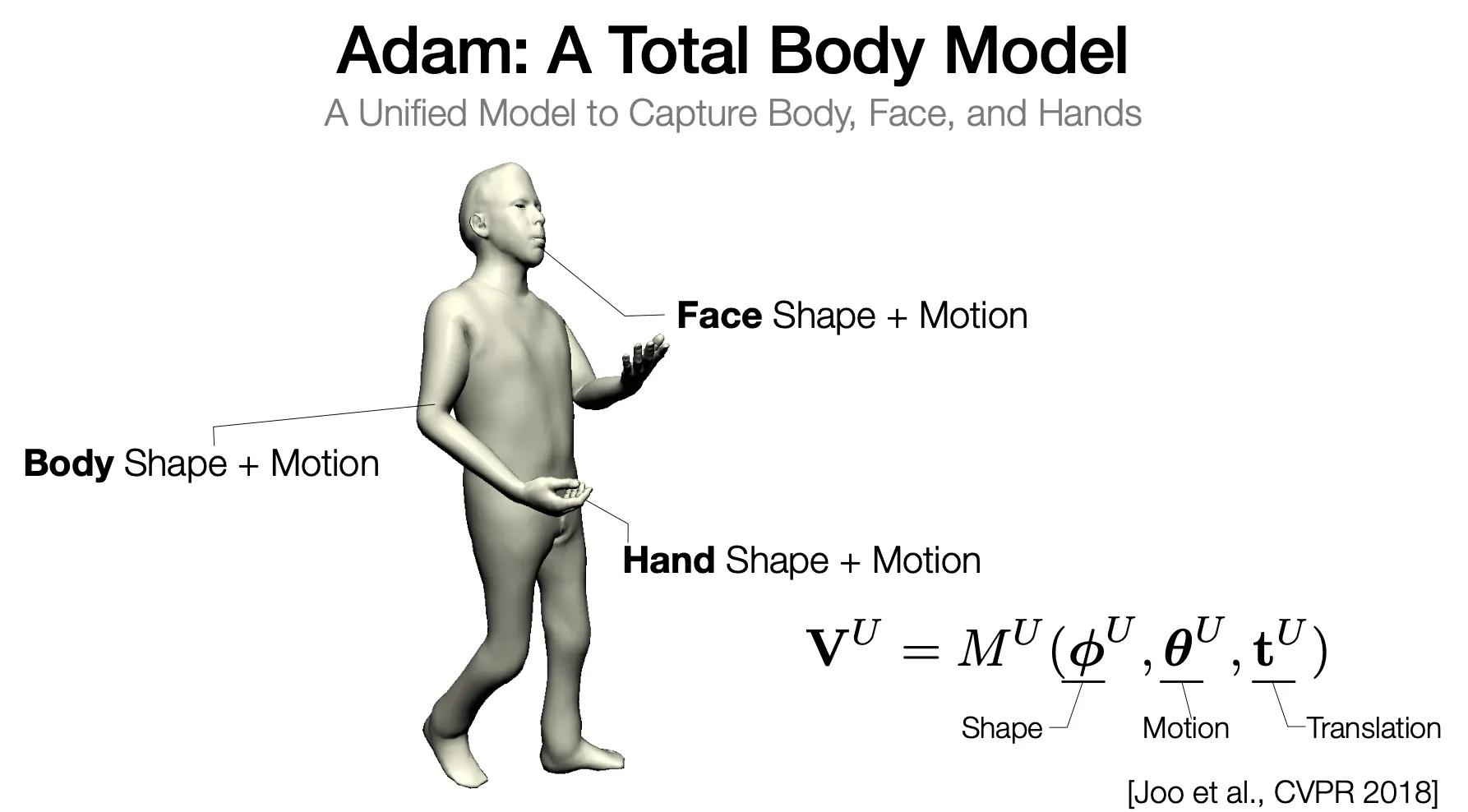
•
단일 모델로 Body, Face, Hands 를 모두 커버하여 Single Image to 3D Human Pose Estimation 을 할 수 있음.
•
교수님의 연구 MTC 와 FrakMocap 등도 있음.
◦
FrakMocap 은 Hand, Body Module 을 분리하여 진행해서 따로 학습하여 나중에 좋은게 나오면 갈아 끼기 용이함.