
Objective
Human-Object Interaction 를 학습하는 이전 연구에서 간과했던 정보들이 HOI 를 이해하는데 도움이 된다는 intuition 에서 시작하여 Human, Object, 그리고 Reference Image 가 주어졌을 때 End2End 로 Human 과 Object 위의 Contact, Spatial Relation 을 simultaneously 하게 뽑아내는 것이 목적이다.
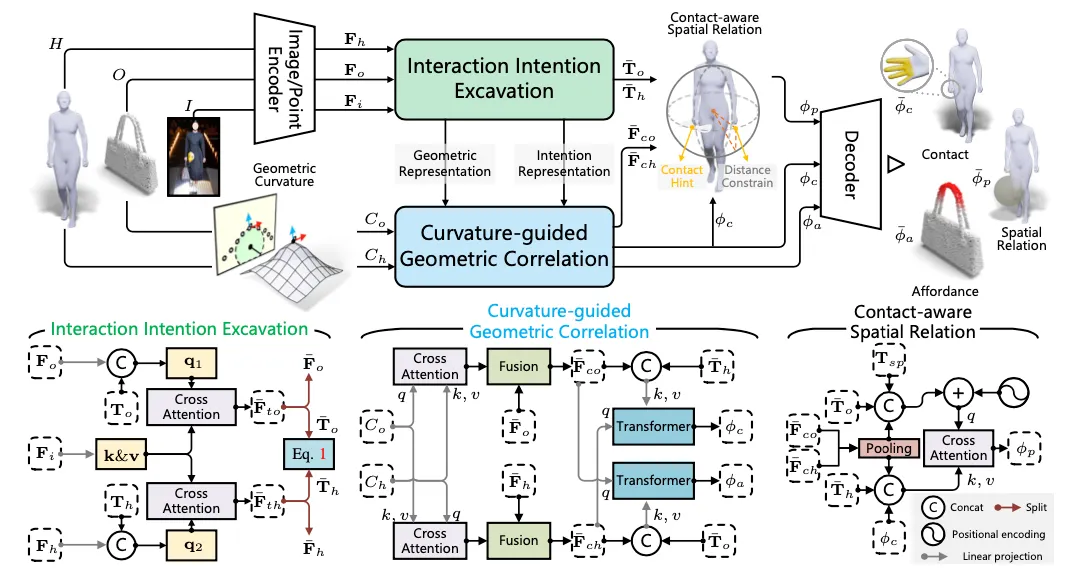
Method
Intention 과 Geometric Correlation 이 HOI 를 이해하는데 큰 도움이 되는 요소라고 판단한 논문에서는, 해당 정보를 사용하여 End2End 로 파이프라인을 구성하고 학습을 진행한다.
이미지가 가지고 있는 Semantic 한 정보를 포함하는 형태의 geometric representation 을 뽑아내면서 같이 intention representation 을 산출하고, 각 human, object 로부터 산출한 intention 의 semantic 이 유사하도록 contrastive learning 을 진행한다.
Human 과 Object 각각의 vertex curvature 를 입력으로 받아 이 정보를 기반으로 HOI 를 뽑을 수 있도록 transformer 구조를 사용하여 affordance vector 들을 산출한다.