본 포스트에서는 Text-Image Foundation Model 로 유명한 CLIP 이 visual image 와 wirtten image 를 이해하는 능력을 분리하려는 시도를 한 논문에 대해서 소개드리려고 합니다.
openaccess.thecvf.com
https://openaccess.thecvf.com/content/CVPR2022/papers/Materzynska_Disentangling_Visual_and_Written_Concepts_in_CLIP_CVPR_2022_paper.pdf
Disentanglinig Visual and Written Concepts in CLIP
논문을 직접 읽어보시고 싶으신 분들은 위 링크를 참고하시면 좋습니다.

Objective
Written Words (문자 이미지) 와 Visual Object (시각 이미지) 를 구별하는 것은 인간에게는 굉장히 쉽고, 당연한 작업입니다. 하지만, Goh et al. 에서 보인 것과 같이 일반적으로 neural network 가 해당 작업을 하는 것은 생각보다 쉬운 작업이 아니었습니다.

Classification Failure in the case of text in image, reference
일례로, “iPad” 라고 적혀 있는 사과가 그려진 이미지는 neural network 가 실제 해당 과일 (Apple) 을 인지하기 보다는 적혀져 있는 텍스트 (iPad) 에 기반한 예측을 하는 경우가 많았습니다. 논문에서는 이러한 현상이 나타나는 근본적인 이유를 Real-World Training Data Image 에 잦은 빈도로 등장하는 텍스트들에서 온다고 생각했습니다.

Written Text in Images (Top) & Generated Images (Bottom)
위 그림의 첫 번째 행에서처럼 많은 물체들은 그 포장지, 표식, 라벨의 텍스트들과 함께 표현되는 경우가 많았고, 논문에서는 이들이 neural network 가 이미지 속 텍스트의 의미와 실제 시각적 물체를 구별하는데 어려움을 겪게 하는 요인으로 보았습니다. 실제로, 선행연구 Goh et al. 에서 CLIP 의 특정 neuron 이 동일한 의미를 가지는 텍스트 이미지와 시각이미지 모두로부터 activate 된다는 사실을 통해 pretrained 된 CLIP 이 “multi-modal neuron” 을 가짐을 실험적으로 확인했고 위 그림의 두 번째 행에서처럼 Text-to-Image Generation 에서 그대로 conditional text 를 이미지 속에 표현하는 형태로 실패하는 사례들을 보였습니다.
이러한 상황에서 논문에서는 CLIP 의 Image Encoder 가 가진 Written Words 와 Visual Object 에 대한 이해 능력을 분리할 수 있는 방법론에 대해 연구하고 제안합니다.
Visual Comprehension
논문에서는 CLIP 의 Image Encoder 가 Image Text (텍스트가 그려진 이미지) 를 어떻게 이해하는지에 대해 알아보기 위해서 크게 두 가지 Visual Comprehension Task 를 설계하여 실험합니다.
Matching Natural Images with Image Text
Image Encoder 와 Text Encoder 를 모두 사용하여 Image 와 Text 의 유사도를 산출했던 기존의 CLIP 과는 다르게, 논문에서는 Text Encoder 를 사용하지 않고, Image Encoder 만을 사용해서 Classification Task 를 설계합니다.

Associating Natural Images with Word Class Label
위 그림의 좌측과 같이 Image Text (여기서는 Synthetic Image Text, 배경 속에 텍스트가 있는 이미지) 와 Natural Image (실제 해당 텍스트가 의미하는 바가 그려진 이미지) 가 얼마나 잘 matching 되는지를 각각을 Image Encoder 통과시켜 얻은 벡터의 유사도로 구해냅니다. 이 때, Classification Task 에서 예측할 수 있는 class 의 집합은 준비한 모든 Synthetic Image Text 에 적혀진 텍스트들이며, Natural Image 를 encoding 한 뒤, 가장 유사한 Synthetic Image Text 와 matching 시키는 형태로 Classification 을 진행합니다. (P.S 논문에 자세히 적혀있지는 않지만 유사도는 기존 CLIP 과 같이 cosine similarity 를 사용했을 것으로 보입니다.)
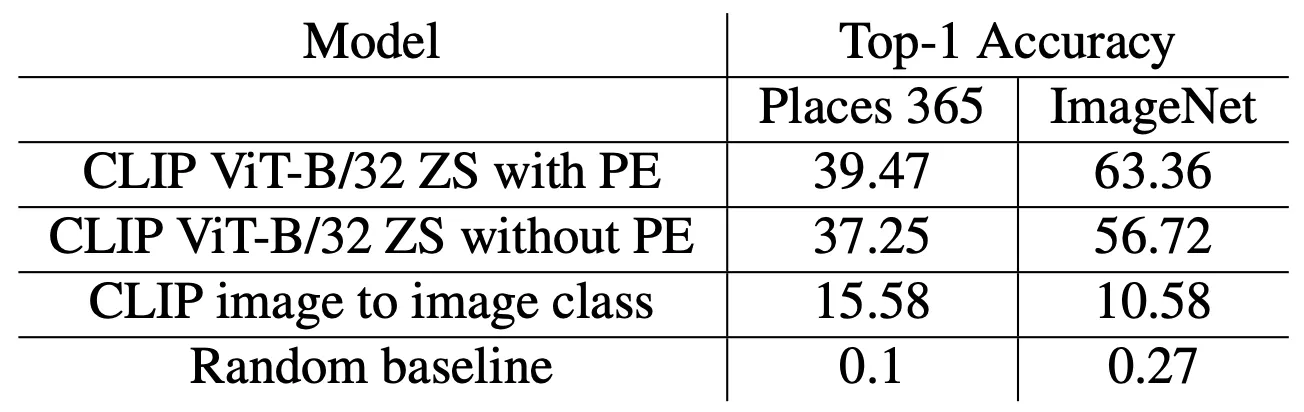
Image Classification Result
논문에서는 크게 Places 365, ImageNet 두 개의 데이터셋을 사용해 실험을 진행했는데, 그 결과는 위 표와 같습니다. Text Encoder 를 사용하여 가장 유사한 텍스트를 찾는 형태로 진행한 CLIP 의 Zero Shot Classification 방법론들과 비교하면 낮은 성능을, Random 하게 classification 하는 방법론과 비교하면 높은 성능을 나타냄을 확인할 수 있었습니다. 이 결과를 통해 논문에서는 매우 밀접하지는 않지만, CLIP Image Encoder 가 Written Words Image 와 Visual Object Image 를 어느정도 관계가 있도록 encoding 한다는 점을 살펴볼 수 있었다고 합니다. (Entanglement of Encoded Vector of Image Encoder)
Matching Image Text with Text String
앞서는 Image Encoder 가 Written Words Image 와 Visual Object Image 들이 entangle 된 형태로 encoding 을 진행한다는 것을 알아보았습니다. 논문에서는 Natural Image 가 아닌, Image Text 를 입력으로 넣었을 때도 CLIP 이 잘 동작하는지 확인하기 위해서 마찬가지로 Retrieval Task 를 설계합니다.
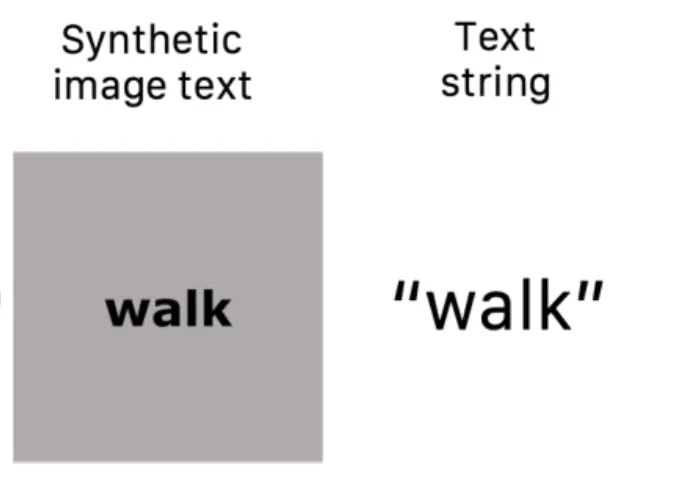
Word Image and Language Word Retrieval
위 그림의 좌측과 같은 Image Text 를 CLIP 의 Image Encoder 에 넣고 우측과 같은 Text String 을 Text Encoder 에 넣어서 각각의 벡터를 뽑아낸 뒤, 각 벡터들마다 서로 다른 encoder 에서 encoding 된 벡터 중에서 가장 높은 유사도를 가지는 벡터를 retrieval 해내는 방법으로 matching 을 진행합니다. (Text 에서 Image 방향으로, Image 에서 Text 방향으로 모두). 이 때 사용한 텍스트들은 실제 존재하는 영단어 (Real English Word) 와 3~8 의 길이를 가진 랜덤하게 sampling 된 알파벳의 조합으로 구성한 넌센스단어를 모두 포함하도록 설계합니다. 그렇게 matching 해낸 것들 중 옳은 matching 의 비중을 retrieval score 로 지칭하였고 다음과 같이 나타났다고 합니다.

Text-Image Retrieval Result
그 결과 CLIP 은 실제 영단어 뿐만이 아니라 의미가 없는 조합으로 구성된 (Training Data 에 없는) 넌센스단어 조차도 retrieval 에 성공하는 것을 볼 수 있었고 이 결과는 CLIP 의 Image Encoder 가 Image Text 속의 텍스트를 인지할 수 있는 능력이 있음을 시사했습니다. 그리고 이러한 결과는 CLIP 의 Image Encoder 가 가진 Visual Processing 능력과는 별개로 각각의 문자를 인식하는 능력을 가진 것인지, Natrual Images 에 포함되어 있는 텍스트들을 인지하는 능력과 관계가 있는 것인지에 대한 궁금증을 야기했고, 논문에서는 새로운 실험을 설계합니다.
Disentangling Text and Vision with Linear Projections
논문에서는 CLIP vector space 에서 visual space 와 written space 를 분리하려는 시도를 합니다. 논문의 아이디어는 이미 학습된 CLIP vector space 에서 각각의 목적 space 로의 orthogonal, lower-dimensional projection 을 진행하는 것입니다.
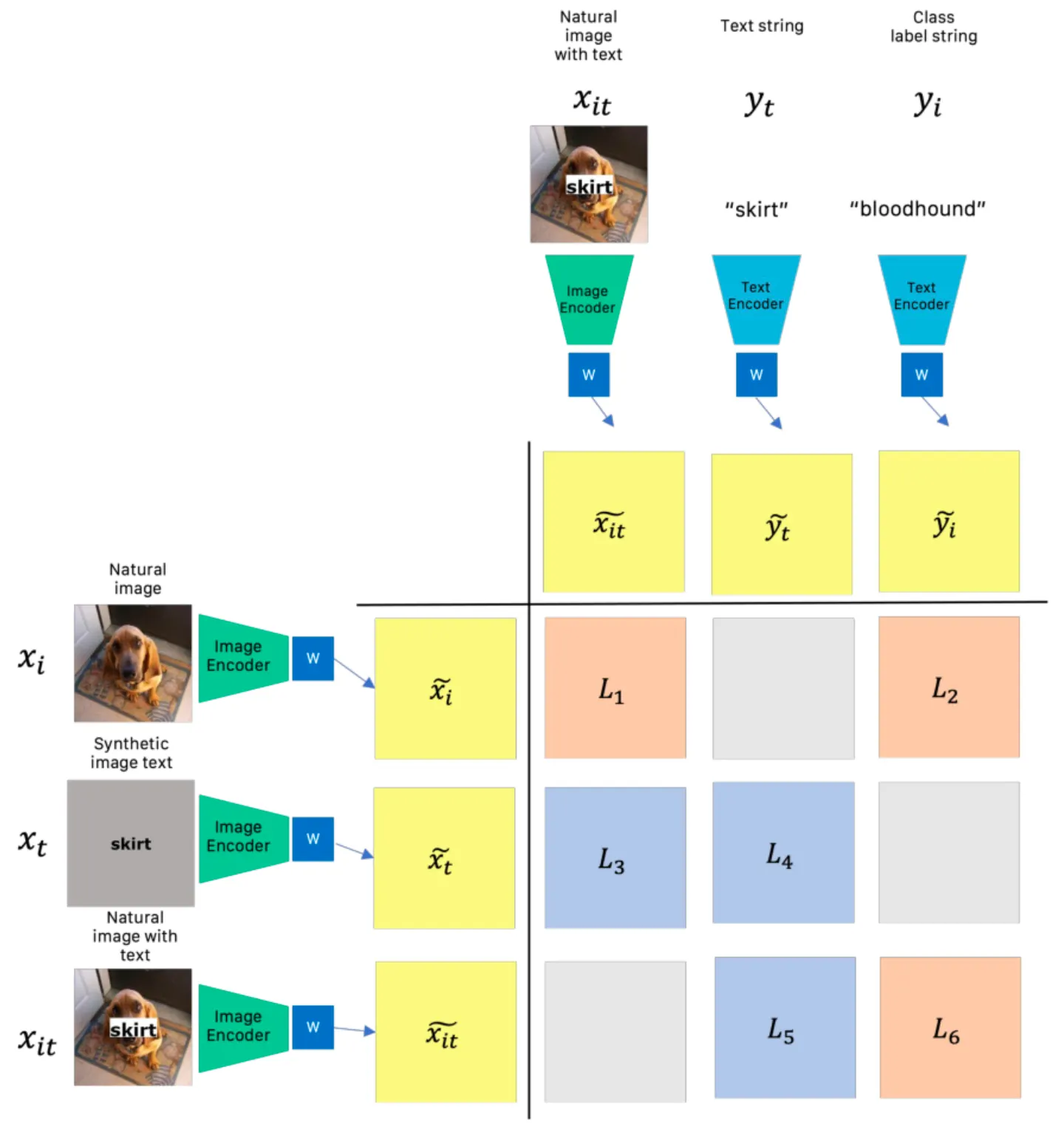
Orthogonal, Lower-Dimensional Projection Setting
이를 위해, 논문에서는 위의 그림과 같이 추가적인 작업을 위한 다섯 개의 요소로 구성된 dataset 을 준비합니다. 로 구성된 하나의 데이터는 세부적으로 Natural Image 와 그 Label Text String 인 , Image Text 와 그 Text String 인 , 그리고 안에 가 삽입된 형태의 이미지인 로 이루어져 있습니다.
여기서 기존의 학습된 CLIP 의 Image Encoder 와 Text Encoder 를 가져와서 추가적으로 Low-Dimensional Space 로의 mapping 을 추가해 학습을 진행합니다. 이는 encoding 된 벡터의 dimension 을 줄이면서 학습을 진행하는 것으로, 최종적인 정보의 손실을 가져와 특정 정보만을 남기려는 intuition 에서 비롯된 것으로 볼 수 있습니다.
위와 같이 를 열로, 를 행으로 두어 행의 요소들과 열의 요소들을 각각 CLIP space 로 mapping 하여 구해낸 유사도를 1. Spelling 만 할 수 있도록, 2. Spelling 을 할 수 없도록 추가적으로 학습합니다. (여기서 말하는 Spelling 이란 Image Text 를 이해하는 능력이라고 보시면 됩니다.)
Learn to Spell
Spelling 만 할 수 있도록 추가적으로 학습하기 위해서는 Image Text 와 Text String 의 유사도 개념을 포함하고 있는 쌍들은 유사도가 크도록 (loss 가 작도록), Natural Image 와 Text String 의 유사도 개념을 포함하고 있는 쌍들은 유사도가 작도록 (loss 가 크도록) 설계할 수 있습니다.
위 그림에서는 푸른색으로 표시된 가 Image Text 와 Text String 의 유사도 개념을 포함하고 있는 쌍들의 loss 이기 때문에 이들이 작아지도록하고 붉은색으로 표시된 가 Natural Image 와 Text String (혹은 Natrual Image 본인) 의 유사도 개념을 포함하고 있는 쌍들이기 때문에 이들을 커지도록 loss 를 아래와 같이 설계합니다.
여기서 는 regularization term 으로, encoding 된 벡터로 이루어진 의 orthogonality 를 보장하기 위해 설계한 항목으로 아래와 같이 표현됩니다. 더불어 는 상수입니다. 이를 통해서 서로 다른 것을 의미하는 이미지와 텍스트간의 유사도를 0 에 근접하게 만들 수 있습니다.
Forget to Spell
Spelling 을 할 수 없도록 추가적으로 학습하기 위해서는 Image Text 와 Text String 의 유사도 개념을 포함하고 있는 쌍들은 유사도가 작도록 (loss 가 크도록), Natural Image 와 Text String 의 유사도 개념을 포함하고 있는 쌍들은 유사도가 크도록 (loss 가 작도록) 설계할 수 있습니다.
위 그림에서는 붉은색으로 표시된 가 Natural Image 와 Text String (혹은 Natrual Image 본인) 의 유사도 개념을 포함하고 있는 쌍들의 loss 이기 때문에 이들이 작아지도록하고 푸른색으로 표시된 가 Image Text 와 Text String 의 유사도 개념을 포함하고 있는 쌍들이기 때문에 이들을 커지도록 loss 를 아래와 같이 설계합니다.
마찬가지로, 는 위에서 설명한 regularization term 과 동일하고 는 상수입니다.
Experiments
Projection Matrices 를 학습하는 과정에서 논문에서는 ImageNet 데이터셋을 활용했다고 합니다. 구체적인 학습의 세팅은 다음을 참고하시길 바랍니다.
Training Setting
Deciding Projection Dimension
해당 Training Setting 을 사용하여 논문에서는 먼저 Learn to Spell Task 에서는 projection 할 bottleneck dimension 에 따른 Retrival Score 에 대한 실험을 32 dimension 간격으로 진행합니다.
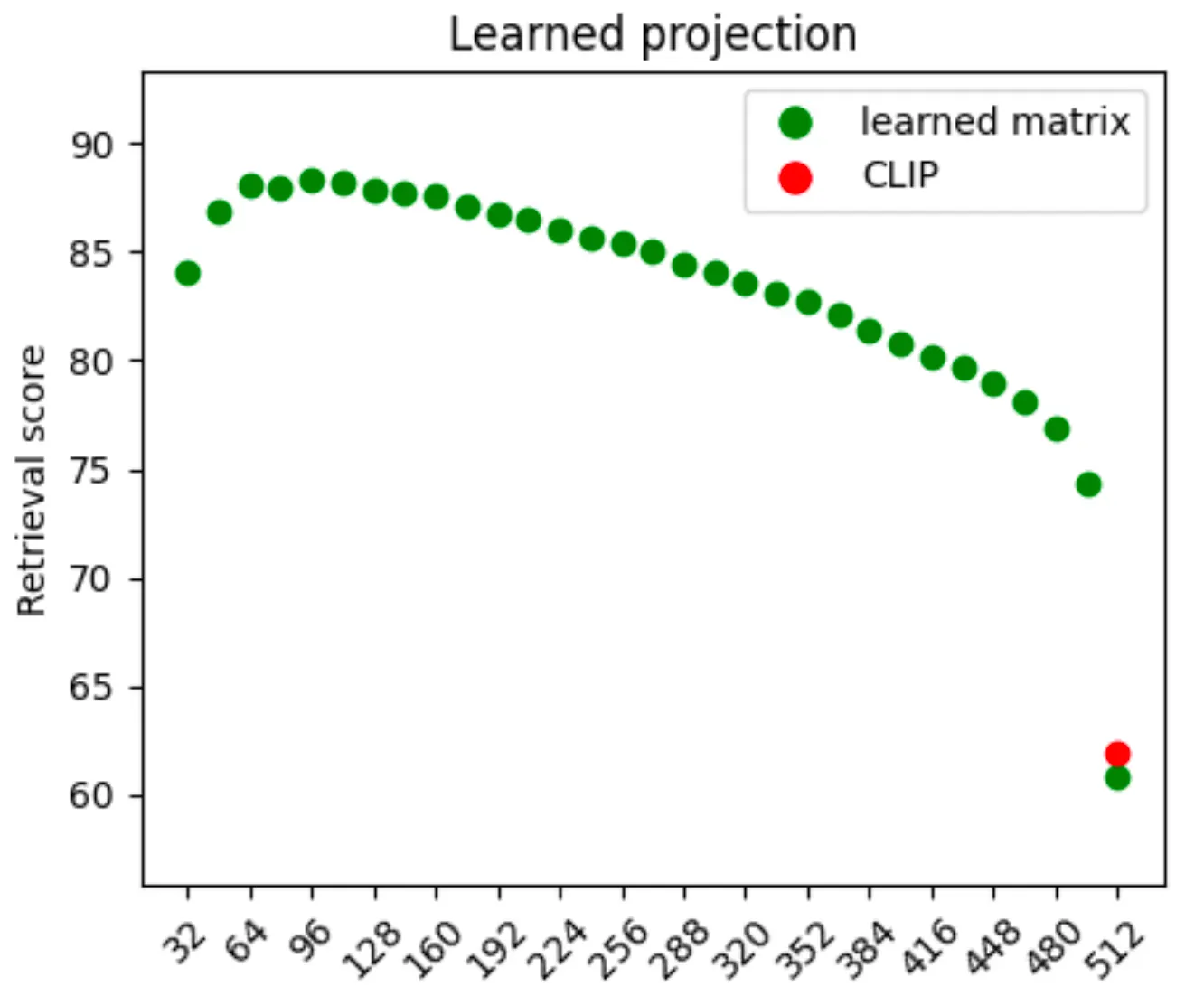
Varying Bottleneck Dimension
그 결과 Learn To Spell Model 의 경우 기존의 CLIP 이 가지고 있는 512 dimension 에서는 단순히 projection 이 rotation 만을 의미하기 때문에 CLIP 의 성능에서 크게 변하지 않은 것을 확인할 수 있었습니다. 가장 높은 score 를 얻은 것은 512 → 64 dimension 으로의 projection 이었고, 해당 dimension 이 Written Text 를 이해하는데 충분한 크기의 dimension 이라는 사실을 역으로 알 수 있었다고 합니다. Forget To Spell Model 의 경우에는 512 → 256 projection 이 가장 높은 성능을 보였고 해당 dimension 으로의 projection 을 활용했다고 합니다.
Ablating Different Loss Terms
이렇게 projection dimension 을 먼저 결정한 뒤, 논문에서는 앞서 설계한 loss 항목들에 대한 ablation study 를 제공합니다. 앞서 Visual Comprehension 에서 이야기한 두 가지 실험 1. Matching Natural Images with Image Text, 2. Matching Image Text with Text String 를 진행하여 Learn To Spell Model, Forget To Spell Model 각각에 대해 평가를 진행했습니다.
Learn To Spell Model
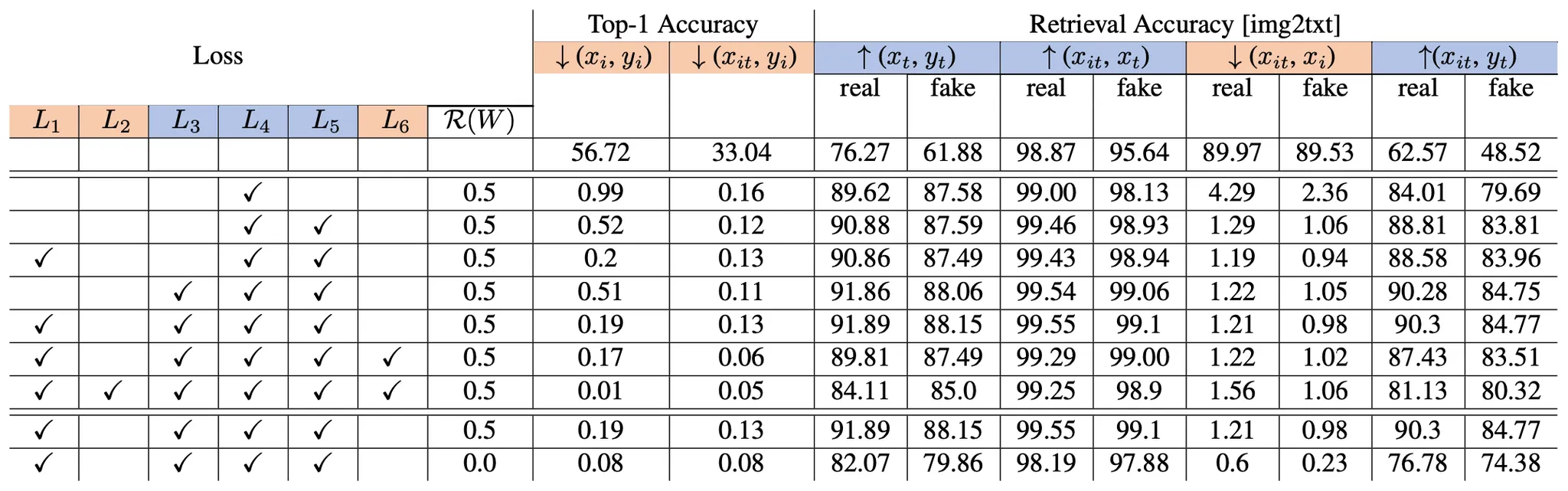
Ablation of the Effects of Different Loss Terms on “Learn to Spell” Model
논문에서 가장 먼저 언급한 내용은 푸른색으로 지정된, “Learn to Spell Task” 와 관련이 있는 loss 항목의 추가가 유의미하게 원하는 결과로의 이동을 나타냈다는 점입니다. 반면 붉은색으로 지정된 “Learn to Visual Task” 과 관련이 있는 loss 항목의 추가는 상대적으로 큰 변화를 나타내 주지는 못했고 최종적으로 논문에서는 제시한 모든 loss 항목을 사용하기보다 항목만 사용하는 것으로 결정합니다.
더불어 최종 선택한 세팅() 과 해당 세팅에서 regularization term 을 없앤 세팅 (표의 마지막 행) 을 비교하는데 regulariztaion 을 없앤 경우 10% 정도의 성능저하가 있음을 확인할 수 있었고, 해당 설계의 유의미함을 어느정도 입증했습니다.
Forget To Spell Model
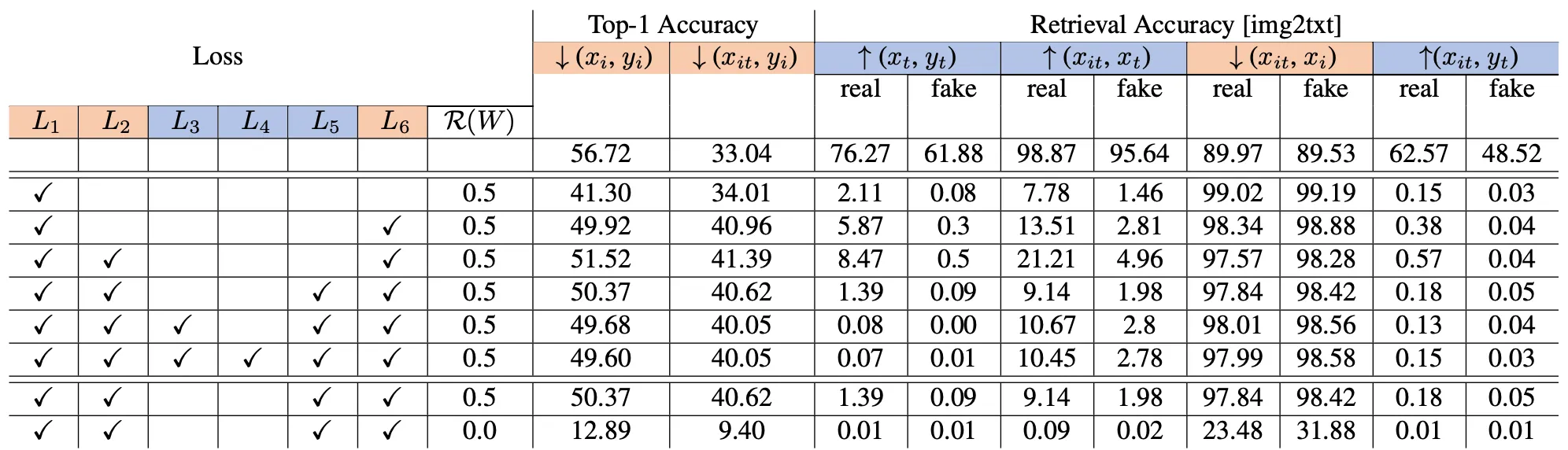
Ablation of the Effects of Different Loss Terms on “Forget to Spell” Model
Forget To Spell Model 에서도 각 loss term 별로 ablation study 를 진행했습니다. Learn To Spell Model 과는 달리 붉은색 평가 항목을 높도록, 푸른색 평가 항목이 낮도록 해야하기 때문에 최종적으로 을 선택했으며 마찬가지로 reguralization term 의 효과가 중요하게 나타남을 확인할 수 있었습니다.
Evaluation
Text Generation
Written Text 와 Visual Object 를 이해할 수 있는 능력이 새롭게 projection 한 vector space 위에서 disentangle 됨을 확인하기 위해서, 논문에서는 Text Prompt 기반으로 이미지를 생성하는 선행연구를 가져와서 시각화를 시도합니다. 논문에서 초점을 맞춘 것은 Novel Font Synthesis 나 Text-to-Image Generation 과 같은 특정 task 가 아니라 disentangle 방법론이기 때문에 논문에서 학습한 projection 을 선행연구에 적용했을 때 얼마나 잘 동작하는지만 확인했다고 합니다.
논문에서는 생성모델인 VQGAN + CLIP 의 구현체를 사용했고, 생성한 이미지의 CLIP embedding 과 Text Prompt 의 embedding 간의 cosine similarity 가 최대화되는 방향으로 학습을 진행했습니다.

Written Text in Images (Top) & Generated Images (Bottom)
위 그림은 리뷰 초반에서도 등장한 사진인데, 기존 CLIP 을 활용을 할 경우 위 그림의 두 번째 행과 같이 의미적으로도 유사하지만 텍스트 또한 직접적으로 이미지 속에 삽입된 형태의 그림들이 생성되는 이슈가 있었습니다.

Images generated with text-conditioning using CLIP
위 그림은 논문에서 학습한 Learn To Spell Model 과 Forget To Spell Model 을 VQGAN 과 함께 이용하여 생성한 이미지들입니다. 전반적으로 넌센스 단어에 대한 Learn To Spell Model 이 실제 영단어에 대한 Learn To Spell Model 에 비해서 텍스트가 잘 드러나는 모습을 보이는데 논문에서는 이러한 현상에 대해 넌센스 단어는 일반적으로 시각적 정보를 가지고 있지 않기 때문에 시각적으로 표현될 수 있는 여지가 없기 때문에 모델이 해당 단어를 텍스트 형태로만 표현할 수 있어서-로 보고 있습니다.
더불어 Forget To Spell Model 에서도 일부 텍스트 형태가 보이는데, 이러한 텍스트들은 표현하지 않고자 했던 Latin Alphabet 과 닮아 있지 않고 Asian Text 형태와 닮아 있는 것을 확인할 수 있었습니다.
이 뿐만 아니라, 논문a

위 그림과 같이 이미지 속에서 텍스트가 등장하는 상황에서 옳게 등장했는지를 판단할 때 정확한 단어의 등장이 아닌, 정성적으로 유사한 단어면 옳은 등장으로 취급하는 Qualitative Analysis 를 적용했다고 합니다. 위 그림의 2행 1열의 database 가 옳게 등장했다고 판단하지만 실제 텍스트 자체는 애매한 예시 중 하나입니다.
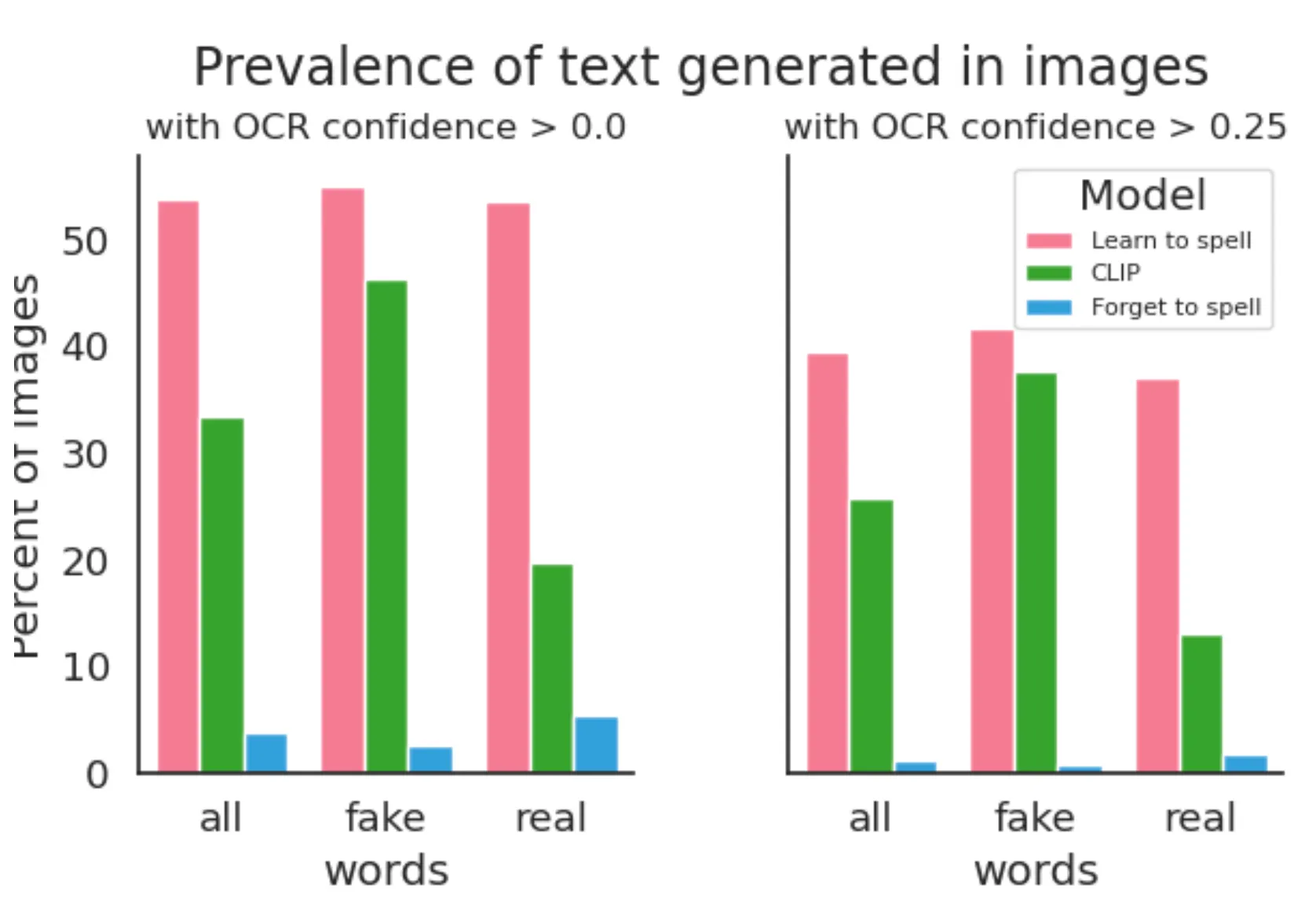
Text Detection Evaluation
위의 그림과 같이 모든 단어에 대해서 Learn To Spell Model 은 기존의 모델에 비해서 25.43% 높은, Forget To Spell Model 에 비해서 54.92% 높은 텍스트 등장 비율을 보였습니다. 이 차이는 실제 영단어의 경우만 추려서 보면 더욱 커지는 것을 확인할 수 있었습니다. 이는 논문에서 언급한 Qualitative Analysis 가 적용되었기 때문도 있지만, 넌센스 단어의 경우 기존 CLIP 모델이 표현할 형태가 텍스트 뿐이기 때문도 있는 것으로 보입니다. 그리고 이는 논문에서 언급한 대로 넌센스 단어에서 CLIP 모델의 텍스트 등장 비율이 높은 이유이기도 합니다.
더불어, 논문에서는 Orthogonal Constarint (앞서 설명드린 regularization term) 의 존재 여부에 따른 Text Detection 비율 또한 자료로 제시합니다.
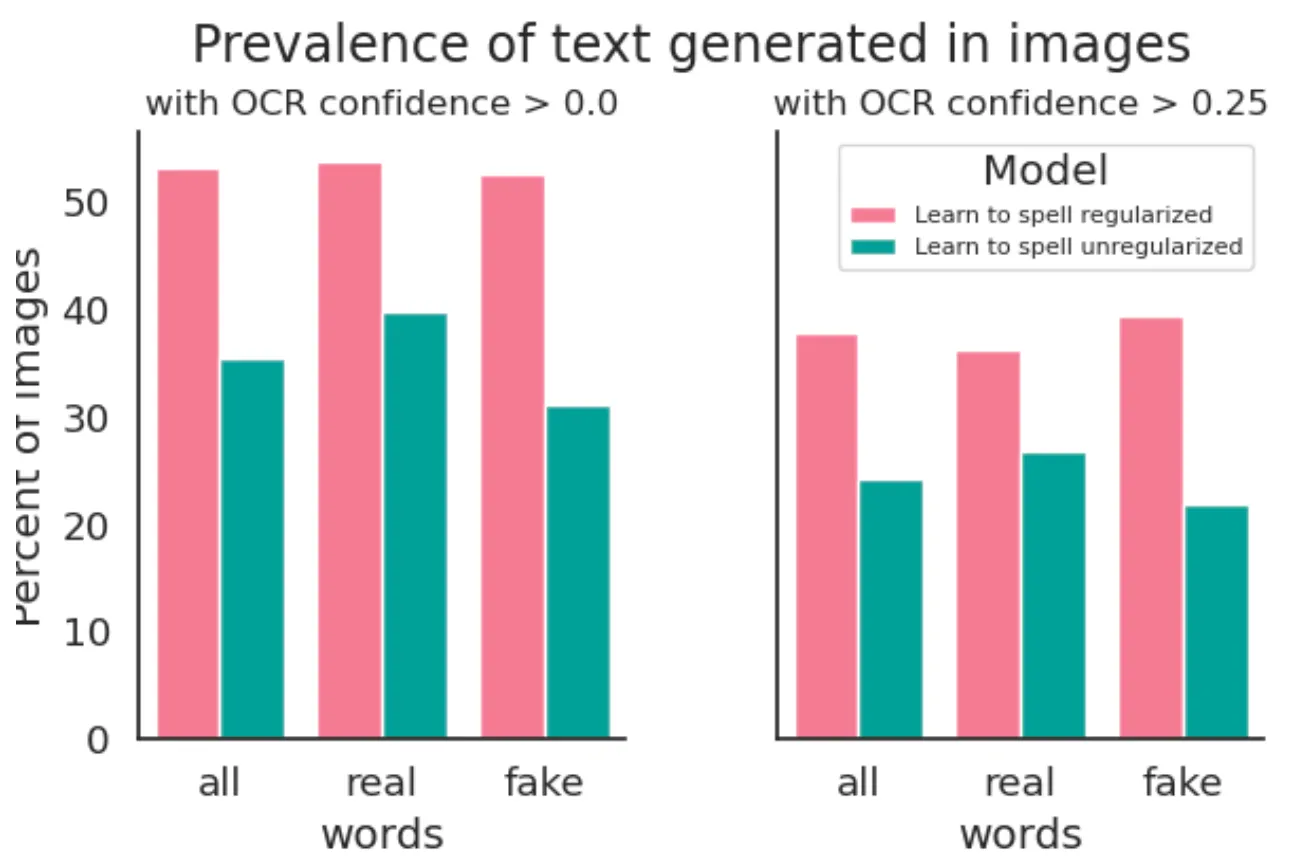
Effect of Orthogonal Constraints in terms of Detection
위 그림에서 보이는 바와 같이 전체 단어에 대해서 Orthogonal Learn To Spell Model 은 Non-Orthogonal Learn To Spell Model 에 비해서 17.5% 높은 텍스트 등장 비율을 보였습니다.

Failure on Non-Orthogonal Constraint on “Forget To Spell Model”
논문에서 특이하게 발견한 점은 Forget To Spell Model 에서 Non-Orthogonal 하게 projection 을 진행했을 때 Detection Rate 는 거의 0% 에 가까울 정도로 좋았지만 붉은 색 배경을 가진 패턴의 일관적인 결과를 나타내어 기존 CLIP 모델이 가지고 있던 유의미한 시각적인 정보마저도 잃어 실패하는 모습을 보여주었습니다.
Robustness
논문에서 사용한 두 번째 Evaluation Task 는 OCR 입니다. 단어를 포함한 Natural Image 로 구성된 IIIT5K dataset 을 사용하였고, 1000 개의 lexicon 에 대해서와 dataset 의 모든 단어들에 대해서 classification 을 진행하는 형태로 OCR 을 구현했고, retrieval score 를 계산하여 평가를 진행했습니다.
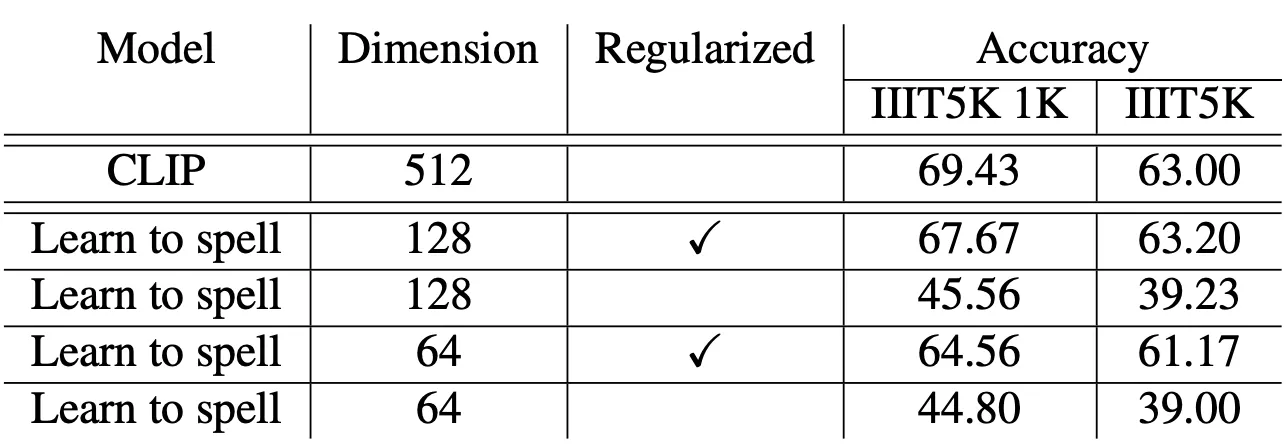
처음에 128 dimension 으로의 projection setting 을 활용해 진행한 실험 결과는 testing 할 때 전체 데이터셋을 retrieval 할 수 없어서 생긴 out-of-domain 이슈가 있음에도 불구하고 기존의 CLIP 모델에 비해서 1.76% 정도밖에 안낮은 retrieval score 를 얻을 수 있었습니다. 전체 데이터셋으로 실험을 한 결과 기존의 CLIP 모델보다 0.2% 정도 상향된 성능을 보였습니다.
더불어 128, 64 dmiension 의 projection setting 을 사용했을 때 모두 Non-Orthogonal Setting 에서 성능의 치명적인 감소가 있음을 확인할 수 있었습니다.
논문에서는 Typographic Attack Setting 에서 논문의 Forget To Spell Model 의 유용함을 제시합니다.

Typographic Attack 이란?
이미지에 해당하는 텍스트가 올바르지 못하게 주어진 상황 등으로 네트워크를 공격하는 (오작동을 유발) 행위로 볼 수 있습니다. 단순한 Classification 모델이라면 큰 문제가 되지 않을지도 모르지만, 네트워크의 결과로 판단을 하는 자율주행과 같은 이슈 등에서는 민감한 주제입니다.
20 개의 물체에 대한 180 개의 이미지 속에서 8 개의 Typographic Attack 이 존재하는 데이터셋에 대해서 평가를 진행했고, 기존 CLIP 모델의 경우 49.4% 의 accuracy 를 보인 반면 논문의 Forget To Spell Model 은 77.2% 의 accuracy 를 보였습니다.
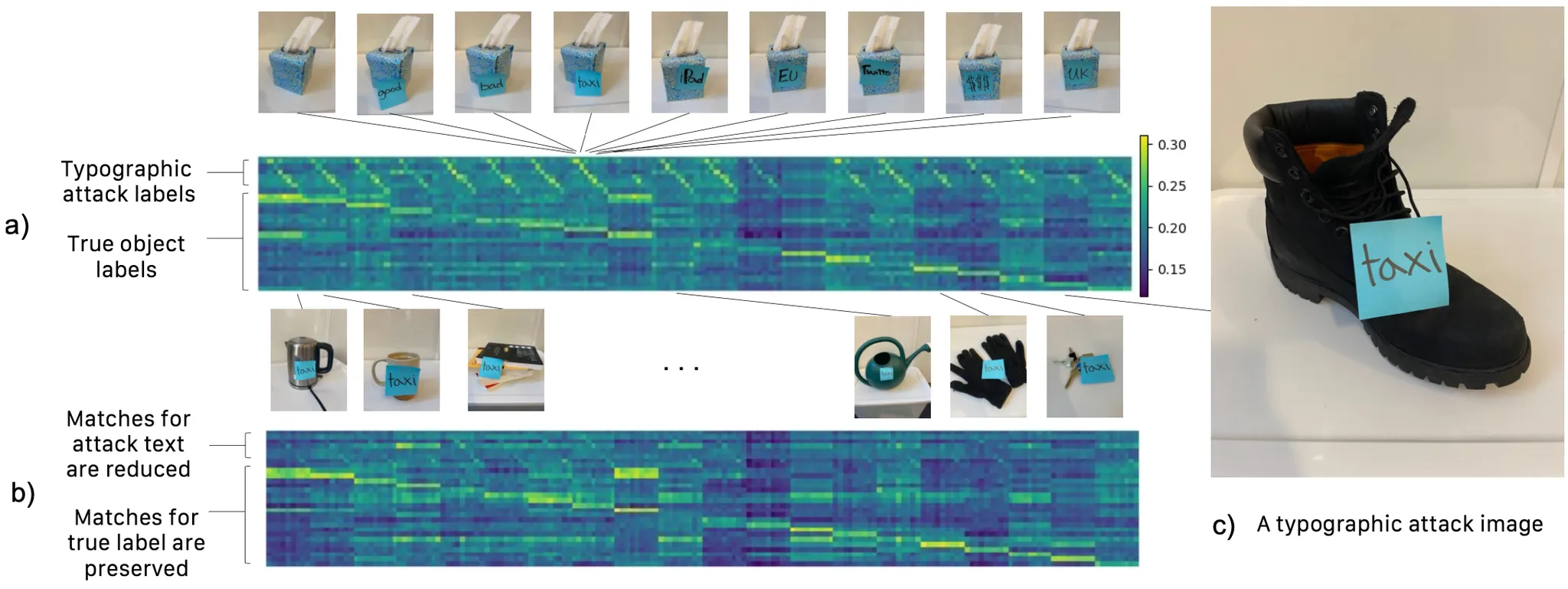
위의 Similarity Matrix 에서도 이러한 경향을 확인할 수 있습니다. 에서 표현된 대각선 항목이 강조된 모습을 통해 기존의 CLIP 모델은 텍스트에 크게 영향을 받는 모습을 보여주었지만, 의 경우에는 텍스트에 대한 민감도가 확실히 줄어든 채 True Label 에 대한 민감도 (직선) 는 유지한 것을 볼 수 있었습니다. 더욱이 이 결과는 논문의 Forget To Spell Model 이 Synthetic Image Text 에 대해서만 학습이 이루어진 점을 감안하면 out-of-domain eneralization 을 진행했을 때 훨씬 좋은 결과를 보일 수 있음을 예상해볼 수 있다고 주장합니다.
Limitations
논문의 방법론은 CLIP 의 orthogonal supspace 로의 projection 을 통해 이미지 속 visual words 의 비율을 조절할 수 있었습니다. 다만, Forget To Spell Model 을 사용하더라도 모든 텍스트를 지울 수는 없었고 반대로 Learn To Spell Model 을 사용하더라도 일부의 단어만 등장한다던지의 형태 등으로 완벽한 Written Text 를 얻을 수는 없었습니다.
Conclusion
이것으로 논문 “Disentangling Visual and Written Concepts in CLIP” 의 내용을 간단하게 요약해보았습니다.
개인적으로 CLIP 을 사용한 프로젝트를 진행하면서 겪었던 이슈 중 하나가 학습된 이미지가 Text Prompt 를 semantic 한 의미가 드러나는 visual object 의 형태가 아닌 텍스트 그대로 출력하는 현상이 잦게 발생한다는 점이었습니다. 이러한 이유 때문에 CVPR 2022 를 살펴보다가 이 논문을 보았을 때 제가 고민하던 이슈를 다루던 논문이어서 흥미롭게 읽을 수 있을 것 같다고 생각했습니다.
논문의 Novelty 있는 방법론 자체는 굉장히 간단해서 놀랐던 것 같고, 그에 비해서 실험과 평가가 생각보다 구체적이고 세세하게 이루어져 있어서 “아 이게 CVPR oral…?” 이라고 생각했던 것 같습니다. CLIP 을 사용해보신 분들은 누구나 흥미롭게 읽을 수 있으실 것 같아 추천할만한 논문인 것 같습니다.