본 포스트에서는 Text to Mesh 분야에서 새로운 방법론을 제시한 논문에 대해서 소개드리려고 합니다. 리뷰하려는 논문의 제목은 다음과 같습니다.
“Text to Mesh Without 3D Supervision Using Limit Subdivision”

Objective
게이밍, 가상현실, 영화 등의 많은 멀티미디어 경험은 3D 모델에 의존합니다. 이러한 3D 모델을 표현하는 방법에는 여러가지가 있지만, 많은 게임과 모델링 소프트웨어들은 Polygonal Mesh + Texture Map + Normal Map 의 조합인 3D assets 로 표현하는 방법을 사용하고 있습니다. 하지만, 3D 모델을 표현하기 위한 3D asset 을 직접 생성하는 것은 간혹 특수 소프트웨어를 동반하는 등 time-consuming, expensive 한 작업이기 때문에 이에 대한 연구들이 많이 이루어졌습니다.

Stanford Bunny: Polygonal(Triangular) Mesh
선행연구들에서 Point Cloud, Voxel Grids, Implicit Function 등을 산출하여 3D 모델을 생성하는 방법들이 연구되었으나, 이러한 방법들은 추가적인 소프트웨어의 사용이 필요했고 이는 의도치 않은 3D 모델의 생성을 불러왔습니다. 더불어 3D Mesh 로 표현되지 않는 3D 모델의 생성은 현존하는 다양한 어플리케이션과의 호환성도 상당히 떨어집니다.
논문에서는 이러한 상황 속에서 naive 하게 생각할 수 있는 가장 이상적인 방법론인 Text Description 으로부터 그에 해당하는 3D 모델을 생성하는 방법으로 접근합니다. 이 때 생성되는 3D 모델의 표현 방법으로 기존의 선행연구들과는 다른 3D Polygonal Mesh 와 Texture Map, 그리고 Normal Map 을 활용하게 됩니다.
Optimization Pipeline
논문에서는 3D 모델을 생성하기 위한 방대한 데이터셋이 존재하지 않음을 시사합니다. 물론 ShapeNet 과 CO3D 데이터셋이 있지만, 각각 51개와 50개의 물체 카테고리만 제공할 뿐이었습니다. 반면 2D 이미지 같은 경우에는 ImageNet-21K 가 21,000 개의 물체 카테고리를 제공했기 때문에 논문에서는 이를 활용하여 3D Mesh Optimization 을 진행할 아이디어를 모색합니다.
CLIP Image & Text Encoder
CLIP 은 400만개 이상의 image - text pair 로 학습된 visual & textural alignment 를 수치화할 수 있는 모델입니다. 간단히 부연설명을 하자면, inference 단계에서 고양이가 찍힌 사진과 고양이 라는 텍스트의 유사도를 산출해줄 수 있는 모델입니다. 논문에서는 이 pretrained CLIP 의 Image Encoder 와 Text Encoder 부분을 때 내어 특정 Text Prompt 와 3D 모델의 특정 카메라각에서의 이미지 간의 유사도를 산출하고, 이 유사도를 기반으로 Loss 로 정의하여 Loss 를 줄여 유사도를 최대화하는 방향으로 Input 3D Mesh 를 변형해나가는 형태의 네트워크 구조를 제안합니다.
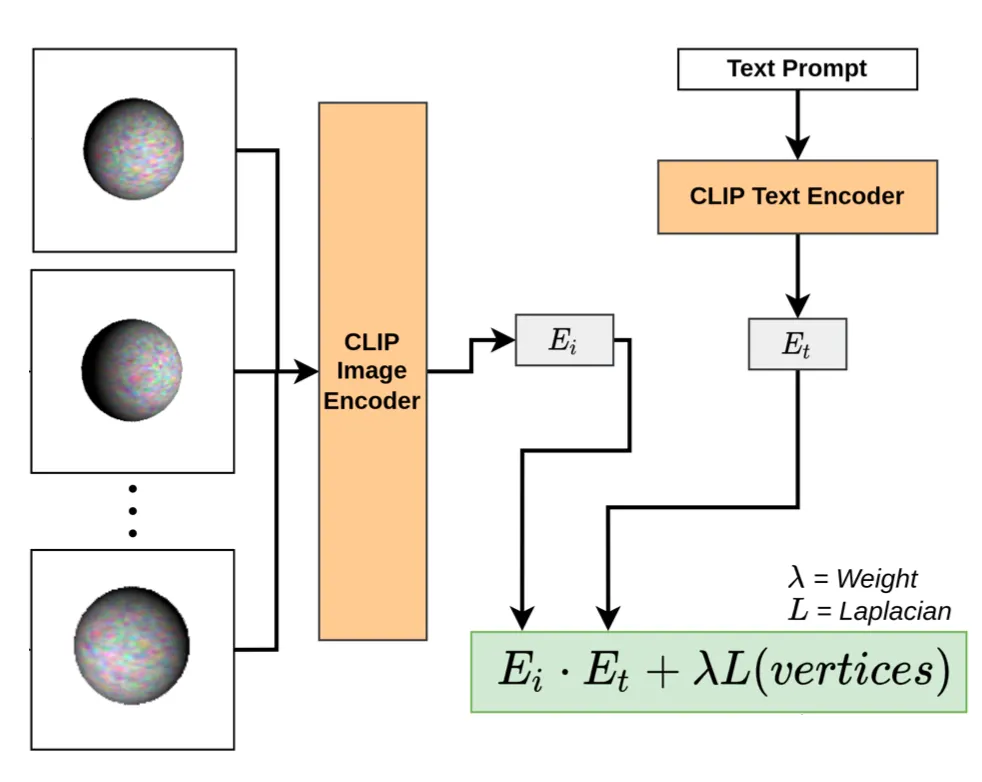
Pretrained CLIP Application
위 그림과 같이 Image 를 CLIP Image Encoder 에, Text Prompt 를 CLIP Text Encoder 에 넣어 각각의 image embedding 와 text embedding 를 산출해낸뒤, dot product 를 수행하여 CLIP Loss 를 정의하게 됩니다.

CLIP Loss 의 각 parameter 에 대한 간략한 설명은 다음과 같습니다.
: 3D mesh 의 vertex
: Texture Map
: Normal Map
: Text Prompt
: CLIP Image Encoder 를 통과한 Image 의 embedding
: CLIP Text Encoder 를 통과한 Text Prompt 의 embedding
논문에서는 CLIP Loss 뿐만 아니라 Appearance-driven automatic 3d model simplification. In Eurographics Symposium on Rendering 에서도 사용한 것처럼 생성한 mesh 의 geometry 를 유지하기 위한다는 이유로 Laplacian Regularizer 를 추가합니다. 이는 다음과 같이 정의됩니다.
각각의 vertex 에 대해서 위와 같이 Laplacian operator 를 정의합니다. 이는 특정 vertex 와 그의 one-ring neighbours 의 평균적인 좌표 차이를 의미하며, 극단적으로 vertex 가 튀는 현상을 방지하는 목적으로 사용한 것으로 보입니다.
최종적인 Laplacian Regularizer 는 위와 모든 vertex 에서의 Laplacian operator 값의 평균으로 정의됩니다. 위와 같은 regularization 을 포함한 최종적인 CLIP Loss optimization 은 다음과 같이 나타낼 수 있습니다.
Differentiable Renderer & Limit Subdivision
앞에서는 pretrained CLIP 를 이용한 논문의 핵심 아이디어를 알아보았습니다. 하지만 3D Mesh 로부터 CLIP 의 input 으로 들어간 이미지들을 렌더링하는 방법에 대해서 설명드리지 않았습니다. 더불어, CLIP Loss 에서부터 Back propagation 을 통해 3D Mesh 를 구성하는 parameter 들을 업데이트 하여 optimize 하려면 해당 렌더링 과정이 differentiable 하다- 는 전제가 필요합니다.
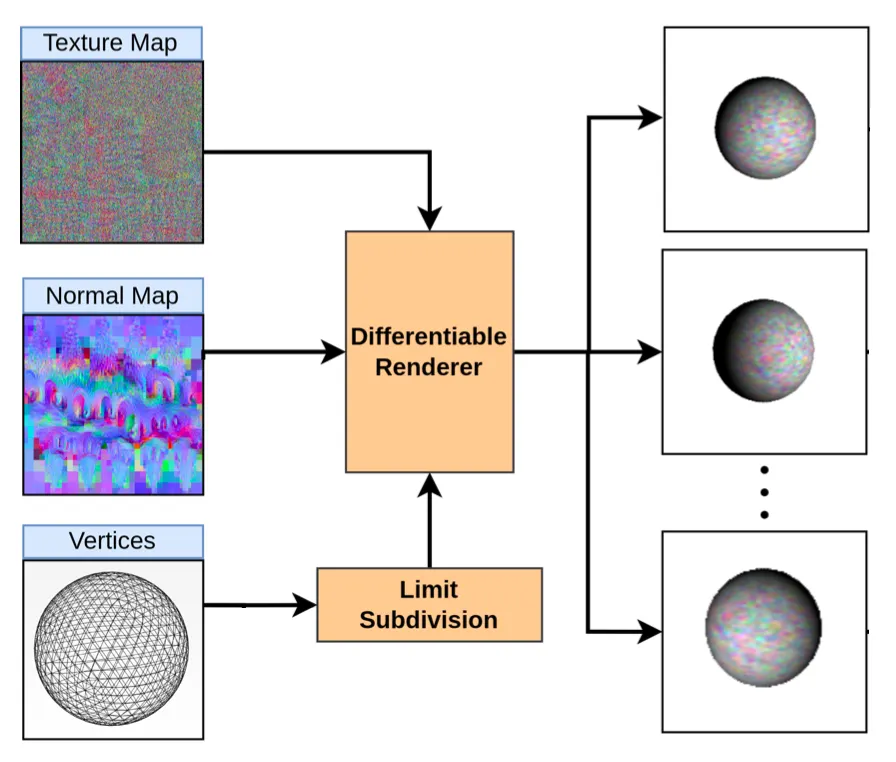
Differentiable Renderer + Limit Subdivision
논문에서는 Modular primitives for high-performance differentiable rendering 논문을 인용하여 해당 논문에서 제시한 Differntiable Render 를 사용했다고 합니다. 일반적으로 3D Mesh 데이터에서 특정 카메라 각에서의 뷰를 2D plane 에 투영하는 것 자체는 differentiable 하지만, 이를 pixel 기반의 2D image 로 만드는 과정 속에서 sampling 이 필요하여 이에 대한 연구가 이루어졌습니다. 이 과정을 Rasterization 이라고 하는데, 이에 관련한 논문들이 따로 있을 정도로 방대하여 이 부분은 추후에 한 번 읽어보도록 하겠습니다.
논문에서는 위에서 설명드린 인용한 논문의 Differentiable Renderer 를 사용하여 CLIP Loss 를 계산할 때 필요한 이미지들을 산출합니다. Differntiable Renderer 을 이용한 input image 생성은 다음과 같습니다.
이 때 는 camera position 을 의미하며, 는 에서 의 uniform distribution 에서 sampling 을, 는 , 의 에서 범위의 beta distribution 에서 sampling 을 했다고 합니다.
이렇게 다양한 camera position 에 따른 다양한 input image 를 생성해낸 뒤에 해당 이미지들을 앞에서 설명드린 CLIP image encoder 에 넣어 Loss 를 구한다- 라고 보시면 됩니다. 그리고 구한 Loss 를 기반으로 differentiable 가능한 back propagation path 를 따라서 3D Mesh 를 업데이트하게 됩니다.
추가적으로 논문에서는 initial control mesh 에 Limit Subdivision 이라는 과정 진행하는데, 이는 Loop Subdivision 을 반복하여 3D Mesh 상의 face 를 점차 작은 크기로 만드는 과정입니다. 이를 반복하여 만들어진 smooth 한 3D mesh 를 limit surface 라고 칭하고, 이는 실제로 결과 3D mesh 의 smoothness 를 증가시켜 퀄리티 높은 3D 모델의 형성에 도움을 주었다고 합니다.
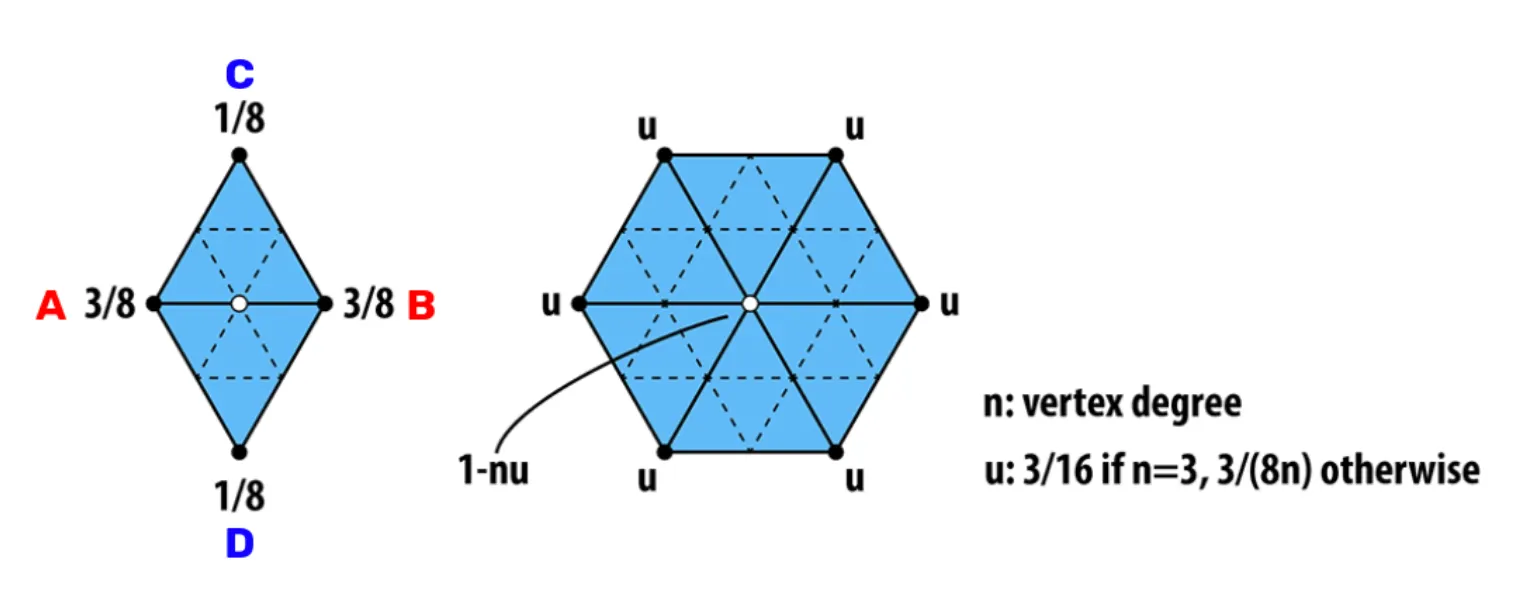
Loop Subdivision
Loop Subdivision 은 새로운 vertex 의 생성과 기존 vertex 의 위치 수정이 동반됩니다. Triangular Mesh 각각의 과정은 다음과 같은 식에 의해서 진행됩니다.
New Vertex Creation
3D Mesh 상의 각 edge 에 대해서 위 그림의 vertex 를 정의할 수 있습니다. 이 때, 새로운 vertex 의 위치는 다음과 같이 정의합니다.
Old Vertex Update
3D Mesh 상의 각 vertex 에 대해서 one-ring neighbors 가 개 있을 때, 기존 vertex 의 업데이트된 위치는 다음과 같이 정의합니다.
이 때, 는 다음과 같습니다.
이러한 방법론을 적용하면 다음과 같이 smooth 한 3D Mesh 를 얻어낼 수 있습니다.

Stanford Bunny: Loop Subdivision
Implementation Details
논문에서는 그들의 구현체에 대한 부가 설명을 진행합니다.
첫 번째로, CLIP Loss 의 weight 를 Appearance-driven automatic 3d model simplification. In Eurographics Symposium on Rendering 논문을 따라서 시간이 지남에 따라 decay 되는 형태를 사용했다고 합니다. 구체적으로는 다음과 같습니다.
이 때 이며, 은 의 2% 정도로 설정했으며, hyperparameter 인 는 10 ~ 50 정도로 설정했다고 합니다.
두 번째로, 카메라는 origin 을 보도록, up-vector 는 y-axis 로 설정했다고 합니다. 더불어 카메라와 물체 사이의 거리는 5.0 으로 선언했는데, CLIP 과 같은 visual recognition model 에서 잘 알려진 texture bias 문제를 해결하기 위해서 카메라의 시야각을 에서 사이에서 랜덤하게 sampling 하는 방법을 사용했다고 합니다. 이는 zoom in/out effect 를 불러와 vertex position 과 texture 의 변화를 통해 다양한 학습 데이터를 확보할 수 있는 관점인 것 같습니다. 더불어 Differentiable Rendering 과정에서 랜덤한 배경 및 offset 을 두어 Data Augmentation 을 진행했다고 합니다.
마지막으로, inital control mesh 의 경우에 basic primitive 인 horizontal or vertical cuboid 와 sphere 에서 선택을 했다고 하는데, 처음에 모든 initial control mesh 를 사용해 보다가 가장 낮은 loss 를 가진 control mesh 를 initial 로 사용하도록 설정했다고 합니다. 이렇게 진행할 경우에 필요한 deformation 의 수치가 적은 mesh 를 선택할 수 있어 빠르고 좋은 결과를 얻을 수 있었다고 합니다. 더불어 Texture Map, Normal Map 그리고 image background 의 경우에는 따로 특별한 커스텀 없이 Random Value 로 initialize 했다고 합니다.
Results
논문에서는 생성한 3D Model 의 호환성을 강조하기 위해 Text Prompt 로 생성해낸 3D Mesh 를 Blender 로 바로 import 하여 scene 에 위치시킨 그림을 보여줍니다. 아래의 그림이 그 예시이며, 다양한 특성을 정의한 다양한 종류의 물체들을 생성해낼 수 있다는 것을 볼 수 있었다고 합니다.

A 3D scene composed of objects generated using only text prompts

Additional Experiment Results
논문에서는 추가로 위의 그림을 제공했습니다.
의 경우 다양한 카테고리의 3D 모델을 생성할 수 있음을 보여주었습니다. 각각 a ufo thors hammer a red and blue fire hydrant with flowers round it a cowboy hat 의 Text Prompt 를 입력받아 생성한 3D Mesh 라고 합니다.
의 경우 Texture Map 및 Normal Map 의 역할, 그리고 Limit Subdivision 의 영향을 보여주었습니다. 는 a matte painting of a bonsai tree; trending on artstation 라는 Text Prompt 를 받아 생성된 이미지이고, 는 같은 모델에 Normal Map 을 Texture 로 입힌 버전, 는 같은 모델에 Texture 를 입히지 않은 버전, 그리고 는 Limit Subdivision 을 사용하지 않고 Texture 를 입히지 않은 버전입니다.
의 경우 논문의 방법론과 Jain et al. 의 방법론에서 같은 Text Prompt 인 red chair 를 받았을 때의 결과 차이를 나타낸 것입니다. 정성적으로 바라본 결과도 논문의 방법론으로 생성한 가 더 좋지만, 그 외에도 논문의 방법론은 Jain et al. 의 것과 달리 게임이나 모델링 어플리케이션에 바로 적용될 수 있는 3D Modeling assets (아마도 3D Mesh + Texture Map + Normal Map 형태인듯 합니다) 을 가지고 있다고 합니다. 동시에 같은 GPU: NVIDIA Titan XP with 12GB 를 썼을 때 Jain et al. 의 방법론은 1시간이 소요되는 반면 논문의 방법론은 17 minutes 이 소요되어 훨씬 효율적이라고 합니다.
은 논문에서 구현에 사용한 여러 방법들에 대한 ablation study 를 진행한 결과입니다. 는 물체에 대한 random translation 을 제거한 버전이고, 은 randomized background 를 사용하지 않은 버전입니다. 은 카메라의 시야각 변화를 주지 않은 버전이고 이 최종적인 결과라고 합니다. 정성적인 관찰 결과로 보았을 때 논문의 방법이 해당 케이스에서는 유의미한 결과를 불러왔다고 보입니다.
Conclusion
이것으로 논문 “Text to Mesh Without 3D Supervision Using Limit Subdivision” 의 내용을 간단하게 요약해보았습니다.
Text Description 만으로 다양한 3D 모델을, 여러 다양한 게임과 소프트웨어에 applicable 한 형태로 적용할 수 있다는 사실이 흥미로웠던 것 같습니다. 큰 골자 자체는 읽기에 크게 어려움이 없었지만 CLIP, Differentiable Renderer 에 대한 깊은 이해와 카메라 설정에 대한 디테일 부분은 아직 조금 모자란 것 같습니다.
이러한 부족한 부분들을 컴퓨터 그래픽스를 비롯해서 최신 논문들을 리뷰하여 좀 더 채워나가야겠다는 생각이 들은 논문이었습니다.