
Face Detection vs. Recognition
•
Face Detection: 이미지 속에 존재하는 모든 물체에 bounding box 를 만드는 것
•
Recognition: 이미지의 고유 class 를 알아내는 것
◦
Recognition 의 pre-processing 으로 detection 을 많이 사용하기도 함
•
번외) Keypoint detection 은 2D keypoint 를 찾는 task 로 이 또한 detection 을 pre-processing 으로 많이 사용함
Challenges of Face Detection
•
이미지 속에서 맞는 영역은 0~50 개인데, 맞지 않는 영역은 ~1M 에 가까움
•
Goal 은 face 와 non-face 를 구별해내는 classifier 를 만드는 것 → False positive rate 를 1e-6 보다 작게 만들고 싶음!
•
고려해야할 것들?
◦
Features: 어떤 feature 가 얼굴을 가장 잘 표현하는지
◦
Classifier: 어떻게 face/non-face 를 효과적으로 구별할 수 있는 모델을 만들 것인지
◦
Efficient inference (real-time): 어떻게 빠르게 inference 할 것인지
Viola-Jones Face Detector [CVPR 2001]
•
Input Image → Haar Feature Selection → Integral Image → AdaBoost Training → Cascading Classifiers
•
Strengths?
◦
Real-time processing
◦
High correct detection rate
◦
Low false positive rate
Haar-like Feature
•
Haar wavelet 에 기반하여 설계된 2D filter 들
◦
특정 사이즈의 이미지 내에서 계산할 위치까지 정해져 있는 filter
◦
Edge Feature: 좌에 +1 우에 -1 이 있는 filter
◦
Line Feature: +, -, + 순서로 있는 filter
◦
Diagonal Feature: 좌상단, 우상단, 좌하단, 우하단 순서로 -, +, -, + 가 있는 filter
→ face structure 에 맞는 다양한 feature 들을 뽑을 수 있음!
•
이러한 다양한 Haar-like feature 중에 face 에 잘 적용되고 다른 이미지에 잘 적용되지 않는 feature 들을 찾을 수 있음!
Computing a Haar Feature
•
Haar-like Feature 의 영역의 픽셀을 다 retrieve 해야 하기 때문에 느림!
◦
특정 영역 사이의 확률을 구하려면 Culmulative Distribution 의 양 끝 값을 빼기만 하면 됨!
•
Cumulative Distribution 과 같은 Integral Image 를 설계함!
◦
좌부터 우, 상부터 하로 픽셀값의 누적을 가지고 있는 이미지
◦
이미지를 순회하면서 Integral Image 를 완성해가는데, 지금까지 완성한 Integral Image 의 자신 위 값 + 자신 왼 값 - 자신 왼, 위 값을 한게 현재 본인의 값이 됨!
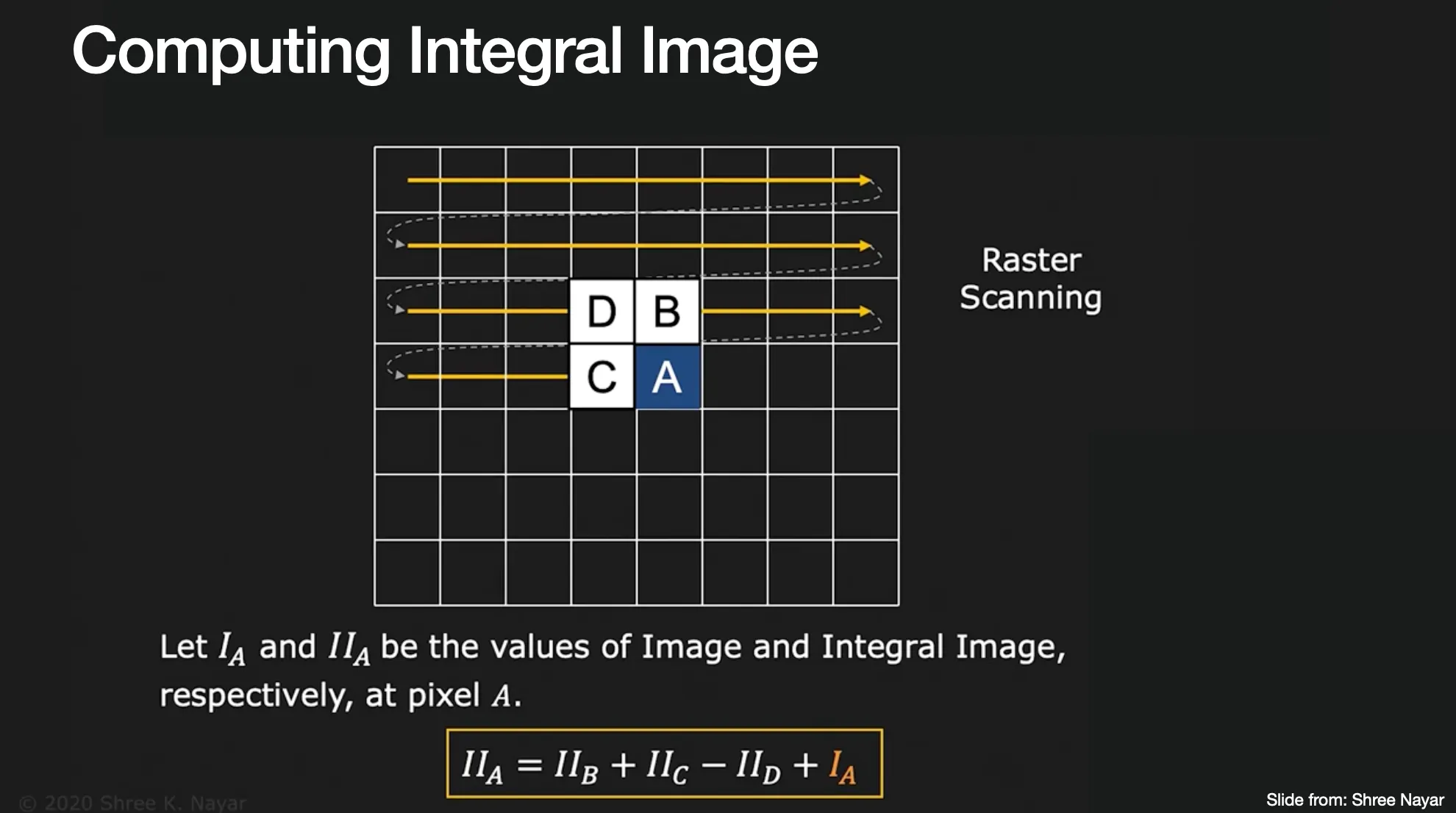
◦
Integral Image 의 지점을 읽으면 이는 원래 이미지의 까지의 사각형 영역의 합이 됨
•
특정 영역의 픽셀 합을 구하고 싶다면, 단순히 3 additions 로 구해낼 수 있음

◦
좌에 +, 우에 - 가 있는 Haar-like Feature 를 계산하려면 7 additions 만으로 구해낼 수 있음…!
A Weak Classifier
•
하지만, 이렇게 계산해낸 Haar-like Feature 가 항상 좋은 feature 는 아닐 수 있음
•
좋은 feature 를 찾기 위해서는 strong classifier (face 를 detect 하는데 큰 영향을 주는)가 필요함
•
Weak classifier 는 Haar filter 를 적용했을 때, 나온 값의 threshold 로 face 여부를 구별함
◦
로, 단순히 inequality 의 방향을 바꾸기 위한 용도로 사용할 수 있음!
◦
는 threshold
AdaBoost (Adaptive Boosting)
•
Weak classifier 를 모아서 strong classifier 를 만듬 (ensemble)
◦
여러 weak classifier 의 결과 중 가장 좋았던 걸 선택 후 선택한 classifier 가 실패했던 이미지들에 대한 weight 를 높여서 다시 반복하면서 좋은 classifier 들을 선택해가면서 완성하는 과정
1.
각 classifier 의 weight 는 동일하게 초기화함
•
이미지는 으로 개이고, 로 label 임
•
: number of negatives
•
: number of positives
2.
각 weight 를 normalize 하여 초기화함
3.
각각의 feature 에 대해서 해당 feature 를 이용한 classifier 하나만 이용해서 분류를 한다고 가정하고 학습을 진행한 뒤에 나온 error 를 계산함
4.
가장 작은 error 를 뽑아낸 classifier 를 좋은 feature 및 classifier 로 선택하고, 해당 classifier 가 실패한 sample 에 대한 weight 를 높임
•
•
: 특정 sample 를 제대로 classify 했을 경우
•
: 특정 sample 를 제대로 classify 못 했을 경우 즉,
•
최종적인 AdaBoost 의 strong classifier 는 다음과 같음
◦
◦
즉, 단일로써 error 가 컸던 classifier 는 최종 classifier 에 가중치를 작게 주는 것임
Cascade Classifier
•
200 개의 feature classifier 의 조합은 95% 의 correct detection rate (true positive) 와 14084 개 중 1개의 false positive 을 산출했음!
•
하지만, 200 개의 feature classifier 를 다 적용하는 것은 시간적으로 좋은 효율을 가지지 못하기 때문에, Viola Jones 는 early rejection 하는 방법론인 Cascade Classifier 에 대해서 제시함
•
첫 classifier 에서 non-face 로 감지되었다면 reject (첫 classifier 는 가장 좋은 친구이므로…), 2, 3 번째에도 반복…
◦
이런 설계에서는 False Positive Rate 는 커도 크게 상관은 없지만, False Negative 가 많으면 위험함 (non-face 로 탈락해버리면 다시는 기회가 없기 때문!)
◦
각각의 classifier 는 100% 의 detection rate 와 점점 작아지는 False Positive Rate 를 목표로 설계가 됨
◦
Detection Rate 는 combination 버전과 동일하게 가져가면서, False Positive Rate 를 줄이고 10 배정도 빠르게 실행시킬 수 있었음!
Measuring Classification Performance
•
True Positive Rate (Recall)
◦
진짜 맞은 것중에 내가 맞았다고 얘기한 것의 비율
•
False Positive Rate
◦
실제 틀린 것 중에 내가 맞았다고 얘기한 것의 비율
•
Precisiion
◦
내가 맞았다고 얘기한 것 중 진짜 맞은 것의 비율
•
Accuracy
◦
전체 중 내가 정확히 짚은 것의 비율
•
F-measure
•
ROC curve
◦
True Positive Rate 가 y 축, False Positive Rate 가 x 축인 curve
◦
좌 상단에 가까울 수록 좋은 그래프!
Failure Modes
•
Rotations, side views, light changes, occlusion 에 대해서는 성공하지 못함…