



Recap: Supervised Learning: Classification
•
Binary classification 은 input 와 label ()에 대해서 decision boundary 를 찾는 문제였음!
•
Linear Regression 과 같은 model 을 사용하는 것은 output 이 0 과 1 뿐인 binary classification 에는 적합하지 않음.
•
Sigmoid Function 은 output 을 0 ~ 1 사이로 압축해주기 때문에 0 과 1 로만 예측해야 하는 binary classification 에서 유용하게 사용될 수 있음.
◦
Linear Regression + Sigmoid 를 거친 값이 0.5 보다 크면 1로, 0.5 보다 작으면 0 으로 예측!
◦
Linear Regression 의 결과는 0 에서 판단의 경계를 가짐
Recap: Summary for Linear Classification
•
Logistic Regression
◦
◦
(Binary) Cross Entropy Loss
▪
Square Error 에 비해서 Cross Entropy 가 더 빠름! ( 까지가 굉장히 절댓값이 크기 때문)
▪
True value 가 1 이면 0 근처 value 를 크게 penalize 하고, true value 가 0 이면 1 근처 value 를 크게 penalize 함!
◦
Testing (예측)
▪
▪
•
Softmax Regression
◦
Softmax → Softmax 의 결과값 항목을 다 더하면 1
◦
Cross Entropy Loss
◦
Testing (예측)
가장 큰 Softmax 값을 산출한 카테고리를 선택!
Logistic Regression: Probabilistic Perspective
•
Odds → 특정한 outcome 이 나올 likelihood 의 측정 (gambling 에서 자주 사용)
◦
이길 확률 / 질 확률
◦
()이면 내가 이길 확률이 높다는 것이므로 참여해야 함.
•
Log Odds (Logit)
◦
이 0 보다 크면 내가 이길 확률이 높다는 것이므로 참여해야 함.
Relation Between Logit (Log Odds) vs. Sigmoid Function
•
Sigmoid function 은 Logit 의 inverse
◦
Sigmoid function 이 logistic regression 에서 뜬금없이 등장한 것이 아니라 logit 컨셉에서부터 나온 것
Revisiting Logistic Regression
•
Logit function 을 hyperplane 에 fitting 하는 경우
•
는 다음과 같이 나타내어짐
◦
이는 곧 logistic regression 에서의 결과값 () 이며, 이것이 probability of positive sample 임!
◦
,
•
정리하자면, , 로 정의하고, 에 대한 logit 을 hyperplane () 을 통해 fitting 을 하게 되면, 결과로 나오는 가 sigmoid of hyperplane 임!
◦
일 때 positive 으로 예측 ( 일 때 positive 으로 예측)
Recall: Probabilities vs. Likelihoods
•
Continous 한 probability distribution function 을 가지는 행위에 대해서 특정 행위가 나타날 확률은 0 임
•
Probability 는 고정된 distribution 의 아랫 영역
•
Likelihood 는 특정 데이터가 어떤 분포에서 가지는 등장 확률 값
◦
데이터들을 가지고 있을 때, 실제 분포가 어떤 분포일지 예측하기 위해서는 Likelihood 를 최대로 가지는 분포를 실제 분포로 예측할 수 있음!
Recall: MLE with Gaussian Distribution
•
Likelihood
◦
가진 데이터들의 likelihood 들의 총합
•
Log-likelihood
Cost Function for Logistic Regression
•
•
•
위 두 개의 식을 묶어 간결하게 로 나타낼 수 있음! ()
◦
인 input
◦
인 target value (label)
•
조절 가능한 parameter 인 에 대한 데이터의 likelihood 는 다음과 같음
•
조절 가능한 parameter 인 에 대한 데이터의 log-likelihood 의 maximize 는 cross entropy 를 minimize 하는 것과 같음!
Optimizing Logistic Regression
•
Prelimiary: Derivative of sigmoid function
•
Computing gradient considering the likelihood of one sample
◦
◦
Label 과 예측 값의 차이에 입력 값의 번째 값을 곱한 값이 likelihood 의 에 대한 gradient!
•
Gradient Ascent (likelihood 를 maximize 하기 위해) 를 적용하면 다음과 같음!
Support Vector Machine
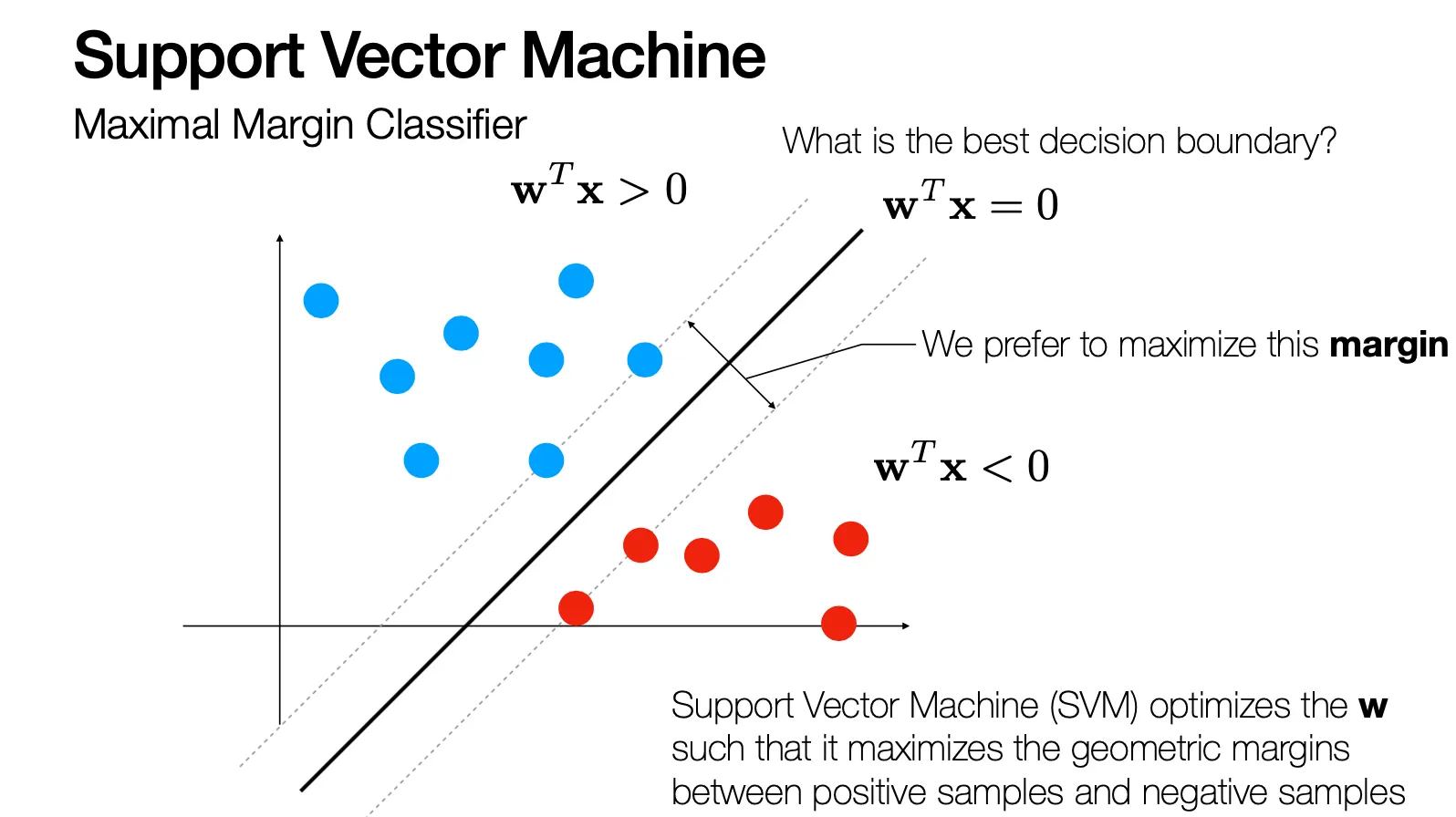
•
Positive samples 와 negative samples 로 나눌 수 있는 boundary 를 찾는 문제
•
무엇이 가장 좋은 decision boundary 인가? → Margin 을 최대화 하는 decision boundary
•
Input: where
•
Label: where
•
Decision boundary equation: → 는 perpendicular vector!
◦
and →
◦
Unit perpendicular vector 는
•
특정 점 에서 hyperplane 에 내린 수선의 발 점이 라고 할 때, 두 점 사이의 관계는 다음과 같음!
◦
해당 는 hyperplane 위에 있으므로 다음이 성립함!
◦
로부터 hyperplane 까지의 거리 은 다음과 같음!
◦
positive 와 negative 모두를 고려한 식은 에 대해 다음과 같음!
◦
가장 가까운 거리를 가지는 에 대한 거리는
◦
가장 가까운 거리를 가장 길게 만드는 를 구해야함!
•
SVM 의 최종 목표는 가장 가까운 거리의 점간의 거리가 최대가 되는 를 구하는 것!
◦
여기서 모든 경우에서 해당 와 에 scalar 를 곱해서 이 되도록 변경할 수 있고 이 과정이 와 로 결정되는 hyperplane 에 영향을 주지 않기 때문에 이러한 constraint 를 줄 수 있음!
◦
이는 더불어 minimizing problem 으로 바꿀 수도 있음! (Linear 하게 두 영역을 separate 가능할 때만 이러한 변경이 가능)
◦
Linearly separable 하지 않은 경우에 대한 대응은 다음과 같음.
▪
slack variables , violator point 에 대해서만 non-zero 값을 가짐
▪
으로 된 점들에 대해서는 margin 안쪽에 있음! (다만, margin 안쪽에 있는 경우가 식을 최대로 만들어야 함)
▪
▪
높은 는 margin violation 을 크게 penalize 함 (Hard Margin)
▪
낮은 는 margin violation 을 어느정도는 허용함 (Soft Margin)