
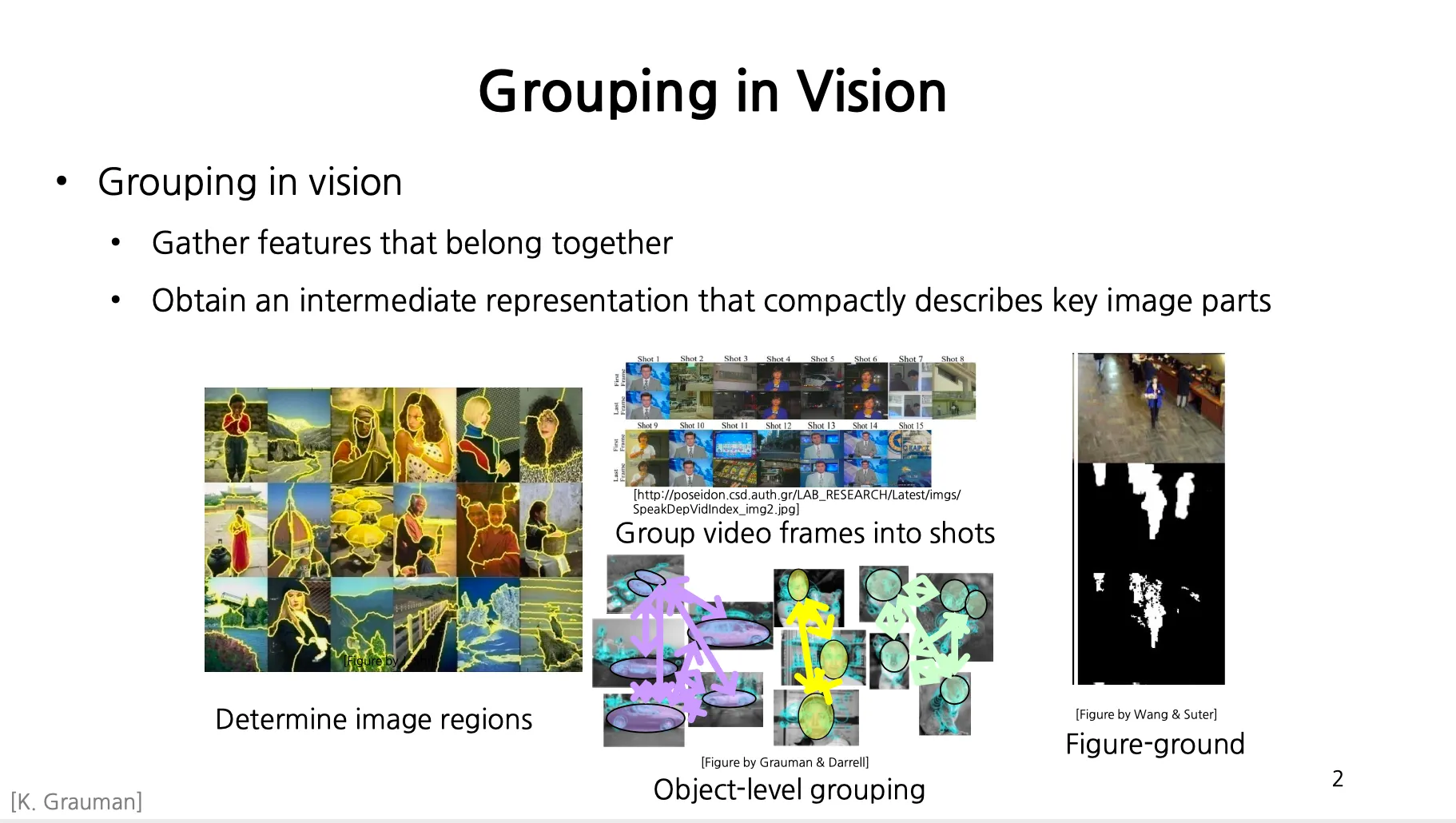
Grouping in Vision
•
관련 있는 feature 들을 서로 모으는 경우
•
Low level vision task 와 high level vision task 사이의 중간단계 표현을 얻기 위한 경우
•
예시
◦
균일한 영역별로 나누기 (Determine image regions)
◦
영상을 비슷한 여러 장의 shot 으로 나누기 (Group video frames into shots)
◦
많은 이미지 속에서 동일한 object 를 묶기 (Object-level grouping)
◦
영상에서 관심있는 부분과 없는 부분을 나누기 (Figure-ground)
Gestalt Psychology or Gestaltism
•
Gestalt: “form” or “whole” in German
◦
20세기 베를린 연구 학파에서 제시
◦
사람이 어떻게 시각정보를 이해하는지에 대한 규칙을 제시
◦
View of Brain
▪
전체는 부분의 합보다 큼.
▪
인간은 전체를 보고 파악하며 그것을 바탕으로 grouping 을 함. (Holistic)
▪
평행한 정보, 유사성 등을 많이 봄. (Parallel, Analogy)
▪
시각 정보의 빈 부분들을 채워가면서 구조화함. (Self-organizing tendencies)
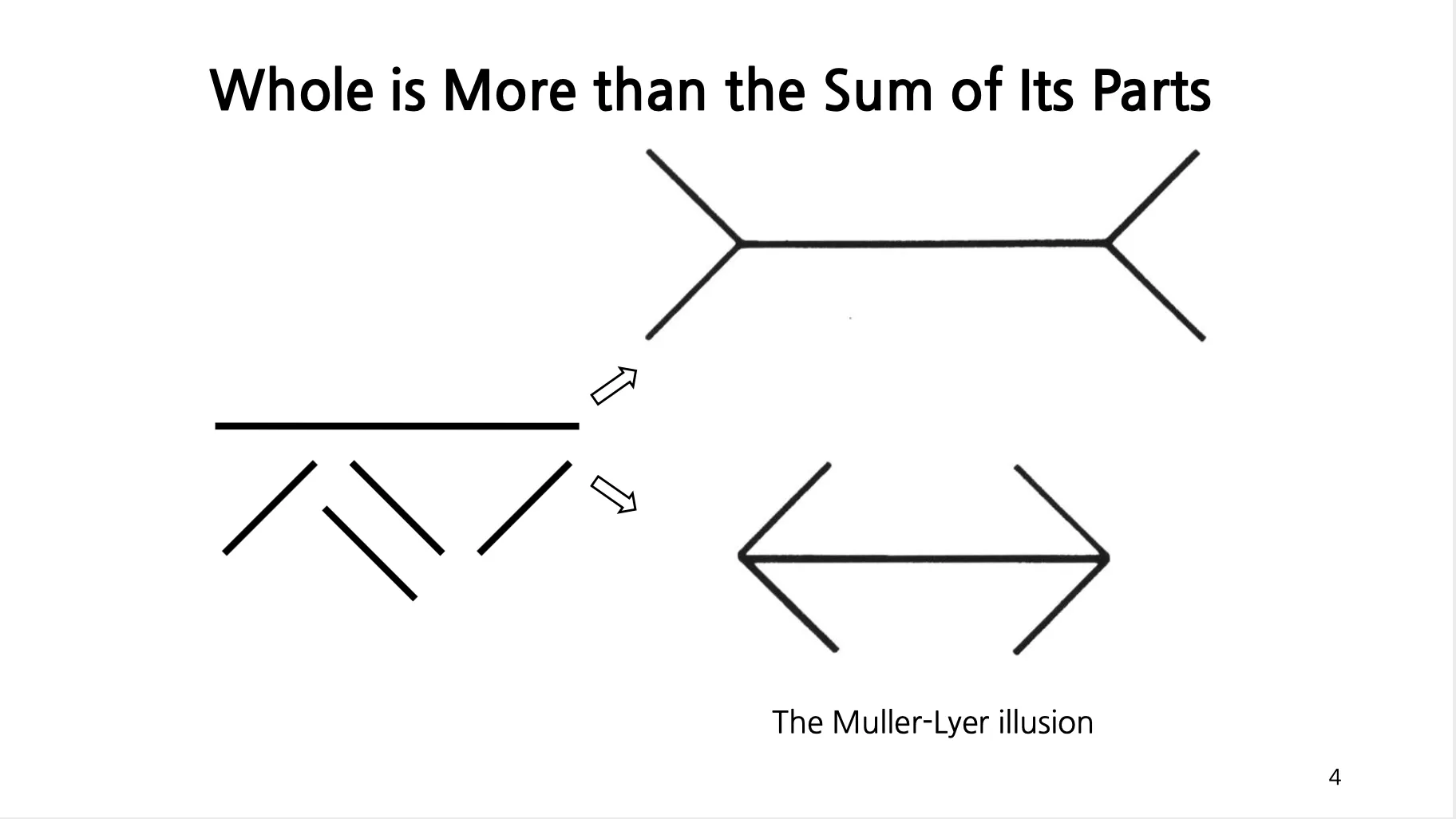
Whole is More than the Sum of Its Parts
•
The Muller-Lyer illusion
◦
위 그림의 직선이 더 길다고 느낌.
◦
각각의 part 가 어떻게 구성이 되는지에 따라 인지하는 것이 달라짐.
◦
2차원을 볼때 3차원을 고려하는, Perspective Projection 을 고려한 인지를 수행하기 때문임.
▪
같은 Line 이라도 더 멀게 느껴지고, 실제론 더 길지 않을까? 생각을 하는 원리
Principles of Perceptual Organization
•
어떤 점들을 묶는가에 대한 기준들이 존재함
1.
Proximity: 얼마나 가까운가
2.
Similarity: 얼마나 생김새가 유사한가
3.
Common Fate: 같은 미래(움직임) 을 보이는 것끼리
4.
Common Region: 같은 영역에 있는가 → 인간은 두 점이 멀리 있음에도 하나의 region 에 있으면 묶인다고 생각함
5.
Parallelism: 평행한 선들끼리
6.
Symmetry: 대칭인 선들끼리
7.
Continuity: 동일 선 상의 점들끼리
8.
Closure: 닫힌 공간 각각끼리
•
인간이 시각 정보를 grouping 하는 근거는 매우 다양하고 그때그때 다름
Reification - Grouping by Invisible Completion

•
여러 도형의 관계를 설정함에 있어서 보이지 않는 부분을 활용함.
•
삼각형, 봉을 감싸는 뱀, 뿔난 구, 물에 걸친 뱀 등으로 위 그림을 해석함.
◦
이런 정보들을 기계한테 알려주기는 어려움.
Gestaltists do Not Believe in Coincidence

•
순으로 정육면체라고 생각할 확률이 높음.
•
우연에 의해 처럼 보일 확률은 매우 낮기 때문임.
Emergence

•
흑백 이미지 속에서 물체를 찾아낼 수 있음.
•
왜 그렇게 찾을 수 있는지를 기계한테 설명하는 것은 어려움.
Gestalt Cues
•
사람이 어떻게 grouping 을 하는지에 대한 직관이 됨.
•
현실에서 해당 직관을 구현하기는 어려움.
◦
이럴 때는 이렇게 grouping 하고 저럴 때는 저렇게 grouping 하는데, 이렇게 결정을 내리려면 전체를 이해해야 하고 기준이 있어야 하는데 기계한테 이를 이야기해주기 모호함.
•
Occlusion Reasoning 을 할 때 사용되기도 함.
Image Segmentation
•
사진이 주어졌을 때, 여러 개의 관련 있는 영역으로 나누는 과정
◦
breaking up the image into meaningful or perceptually similar regions
◦
어떤 점들을 같은 지점으로 볼 지는 주관적인 요소임.
Interactive Segmentation
•
Foreground 에 해당하는 부분을 bounding box 로 주면, foreground 와 background 를 segmentation 할 수 있음.
•
Background 가 균일하면 깨끗한 segmentation 을 얻을 수 있음.
•
정보를 준 scribe 에 해당하는 부분은 해당 정보를 만족하도록 하는 방법도 있음. (이 부분은 background 여야 함- 과 같은 정보)
Segmentation for Efficiency - Super Pixels
•
이미지 같은 경우에는 의 pixel 이 존재함.
•
심각하게 oversegmentation 된 경우, 각 균일한 segment 하나를 pixel 로 취급할 수 있음.
•
이후에 할 작업을 효율적으로 하기 위해서 pixel 수를 줄이는 과정으로 segmentation 을 활용할 수 있음.
Types of Sementations
•
Oversegmentations: 너무 작은 영역으로 segmentation
•
Undersegmentations: 너무 큰 영역으로 segmentation
•
Oversegmentation 은 합쳐질 여지가 있다는 점에서 undersegmentation 에 비해서는 좋음.
•
Segmentation 이 항상 정확하지 않다는 것을 알기 때문에, 하나의 segmentation 에 의존하기 보다는 여러 segmentation 버전을 구하고, 적절한 patch 를 찾는 방법을 활용함.
Major Processes for Segmentation
•
Segmentation 의 두 가지 과정
◦
Bottom-up: 이미지 픽셀마다 feature 를 뽑고, 비슷한 feature 를 grouping
◦
Top-down: High level resoning 부터 하여 동일한 의미를 가지는 영역들은 하나가 되도록 grouping
Segmentation: Caveats
•
일반적으로 사용하는 segmentation 은 bottom-up 과정임.
•
하지만, segmentation 을 완벽히 해결하려면 top-down (recognition) 문제를 무시할 수 없음.
•
Segmentation 이 어려운 점은 결과가 주관적이라는 점임.
Clustering
•
여러 개의 data point 들을 대표하는 하나의 token 으로 표현하는 방법
•
Key Challenges
◦
Similairty Metric 을 어떻게 정하는 것이 좋을까 (비슷함의 정량적 정의)
◦
Clustering Objective (목적함수)를 어떻게 정의해야 할까
Why do We Cluster?
•
Clustering 을 사용하는 이유?
◦
Summarizing Data
▪
데이터가 너무 많아서 요약하기 위해서 clustering 을 사용함.
▪
Patch-based compreesion/denoising 이 필요한 경우 사용함.
◦
Counting
▪
이미지를 histogram 의 형태로 나타낼 때가 있는데, 이를 위해서 필요함.
◦
Segmentation & Prediction
▪
이미지를 다른 영역으로 분리하기 위해서 사용함. + 같은 영역이 같은 label 값으로 예측할 수 있음.
Image Segmentation: Toy Example
•
이미지 픽셀 값으로 clustering 가능
•
3 개의 명확한 histogram 의 bar 가 나타나고 명확하게 구별할 수 있음.

•
Noise 가 추가된 경우 Intensity 값에서 3 개의 group 을 찾아내야 함.
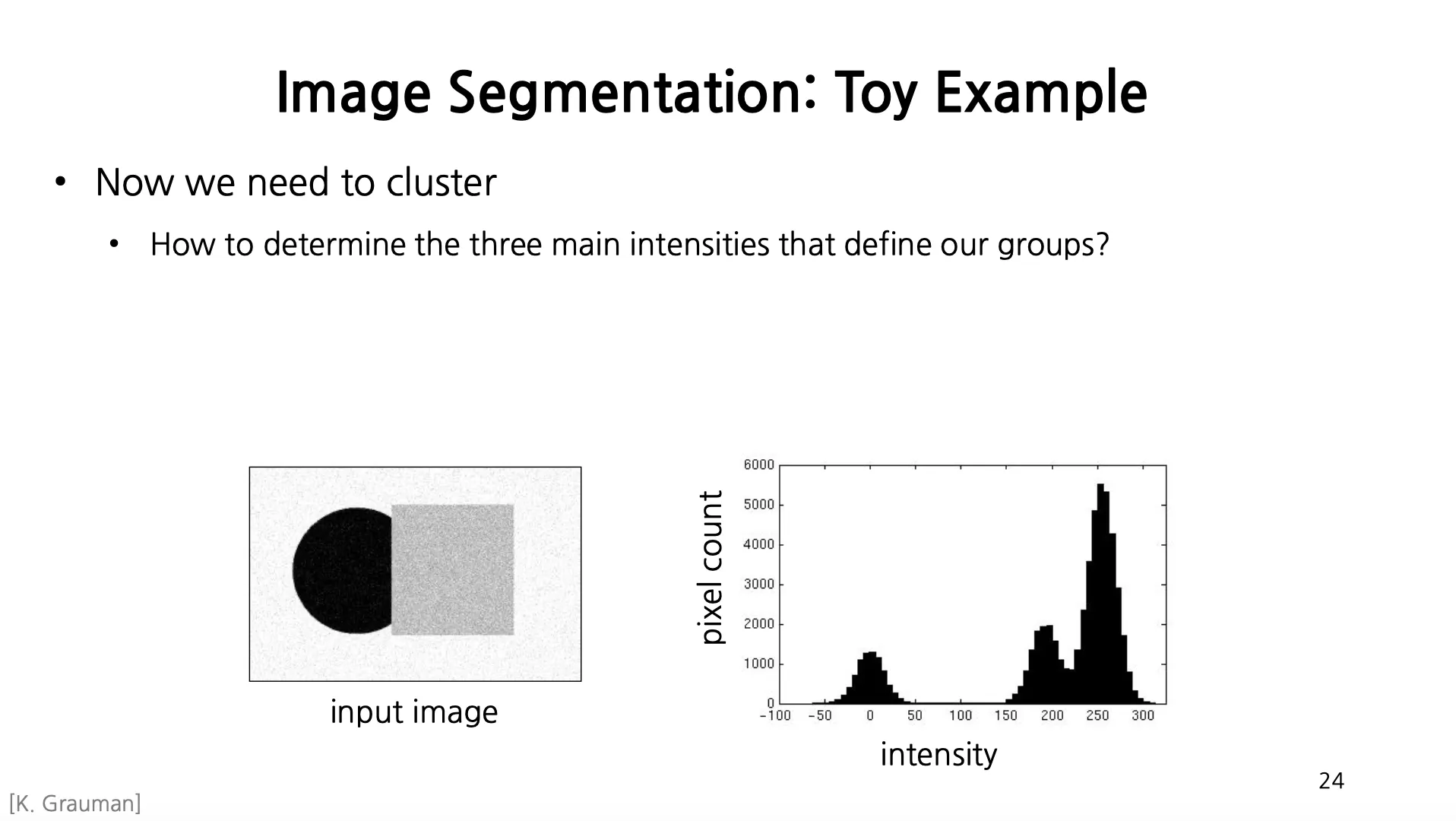
Image Segmentation: Toy Exmaple
•
이미지 픽셀 값이 noise 를 가진 채 3 개의 group 으로 나누어지는 경우를 생각할 수 있음.
•
각각의 대표가 되는 cluster center 를 찾고, 각각의 값들은 그들 중 가장 가까운 쪽으로 assign 하는 것으로 생각해볼 수 있음.
◦
Data point 와 cluster center 사이의 L2 norm (SSD)을 최소화하도록 설정
◦
하지만 위 목표는 “Chicken and Egg” 문제가 됨
▪
Cluster Center 를 알면, 각 데이터가 어느 Cluster 에 속할지 정할 수 있음.
▪
각 데이터가 어느 Cluster 에 속할지 알면, Cluster Center 를 각 Cluster 에 속하는 데이터들의 중심으로 정할 수 있음.
▪
하나가 주어지면 다른 하나를 알아내는 것은 쉽지만, 동시에 알아내는 것은 어려움.
Segmentation as Clustering
•
각각의 pixel 에 대해서 feature vector 를 뽑고, 해당 vector 에 대해 clustering 을 함.
•
가장 쉬운 방법은 intensity 값을 feature 로 뽑고 clustering 을 하는 것임.
•
Color Image 의 경우에는 각 픽셀에서 3차원의 intensity feature vector 를 얻어낼 수 있고, 여기서 K-means Clustring 을 돌릴 수 있음.
•
Filter Bank 를 사용해서 feature vector 를 뽑을 수도 있음.
•
Intensity 뿐만이 아니라 position 정보 또한 clustering 에 넣어줄 수 있음. → coherent 한 clustering 을 얻을 수 있음.
Image Segmentation
•
Segmentation → 의미있는 영역으로 이미지를 나눈 작업 (무엇이 의미인지에 따라서 주관적임)
◦
Clustering 을 활용한 segmentation
◦
Graph 를 활용한 segmentation
◦
Edge & Boundary 를 활용한 segmentation
•
Clustering → 데이터에 대한 grouping
How do We Cluster
•
K-means
◦
일반적으로 가장 많이 쓰이는 clustering algorithm
◦
Clustering 을 해야하는 task 가 있으면 K-means 부터 고려함.
◦
Summarization, Dictionaries of Patches …
•
Agglomerative Clustering
◦
Segment 나 Cluster 의 hierarchy 를 만들고 싶은 경우에 사용
•
Spectral Clustering
◦
Graph 를 자름으로써 얻게되는 Clustering
◦
데이터 사이의 연결관계를 고려한 segmentation 을 얻고 싶은 경우에 사용