Visual Recognition
•
Verification
◦
ex. 이 사인이 진짜로 내 사인인지, 이것이 진짜 자동차인지
•
Classification
◦
분류 문제로, 정해진 label 중 어느 것에 속하는지
◦
Multi-label 을 가지는 문제도 있음.
•
Detection
◦
관심있는 물체 종류를 정해두고, 이미지가 해당 물체들을 포함하고 있는지, 있다면 어느 부분에 있는지
•
Pose Estimation
◦
자세를 예측하는 문제
•
Activity Recognition
◦
사람의 동작을 기반으로 한 Classification (사람이 무엇을 행하고 있는지 분류)
•
Object Categorization
◦
이미지 상의 관심있는 물체들을 label 하는 과정
•
(Semantic) Segmentation
◦
Pixel-level 의 classification 문제
Object Recognition - Is it Really so Hard?
•
의자를 찾는 문제에서 Template Matching 을 사용할 수 있음.
◦
NCC 가 가장 큰 지점을 뽑으면 됨.
•
일반적인 상황 (일상적인 사진) 에서는 랜덤한 사진에서 의자를 찾는 문제가 될 것임.
◦
Template Matching 을 그대로 진행하면 수 많은 False Positive 가 생김.
Challenges 1 (Why Object Recognition is Hard): View Point Variation
•
실제 물체는 3차원인데, 보이는 이미지는 해당 3차원 물체를 2차원으로 projection 한 것임.
•
어디에서 보느냐에 따라서 얼굴 모양이 생각보다 많이 달라보임.
•
Viewpoint 에도 robust 한 물체인식을 행하는 것은 쉬운 문제가 아님.
Challenges 2 (Why Object Recognition is Hard): Illumniation
•
같은 사람이라고 할지라도 조명조건을 달리하면 매우 달리 보임.
•
표정 인식과 같은 task 에서 조명조건에 따라서 인식이 달라질 수 있음.
Challenges 3 (Why Object Recognition is Hard): Occlusion
•
Camera Center 와 공간 상의 점을 잇는 직선 위에 있는 물체들이 동일한 픽셀로 mapping 이 되는데, 그 중 가장 가까운 물체의 point 만이 보이고 나머지는 occluded 됨.
•
Ex. 사람이나 자동차가 빽빽하게 많은 곳에서 모든 사람 및 자동차를 인식하기 어려움. → 고차원적인 reasoning 으로 일부의 시각정보만으로도 인식이 가능하긴 한데 기계한테는 어려운 일임.
Challenges 4 (Why Object Recognition is Hard): Scale
•
같은 물체라도 어떤 사진에서는 크게 보이고 어떤 사진에서는 작게 보임.
•
Object Detection 도 큰 물체에 대해서는 잘 동작하는데, 작은 물체에 대해서는 잘 동작하지 않음.
◦
주변 여러가지 Context 정보를 활용하여 인식을 시도할 수 있음.
Challenges 5 (Why Object Recognition is Hard): Deformation
•
말과 같은 생명체는 겉이 물렁하기 때문에 deformable 하고, 생명체이기 때문에 골격이 말마다 다르고, 관절을 움직임으로써 자세를 바꿀 수 있음.
•
모양이 다른 다양한 말들에 대해서 안정적으로 모두 말이라고 인식하는 것은 쉬운 일이 아님.
Challenges 6 (Why Object Recognition is Hard): Background Clutter
•
일반적인 상황에서는 아마존의 상품처럼 배경이 깔끔한 이미지만 주어지는 것이 아님.
•
배경이 매우 다양한 배경 물체 (잡동사니) 들 사이에서 관심있는 물체에만 집중하여 원하는 물체를 인식해 내는 것은 쉬운 일이 아님.
Challenges 7 (Why Object Recognition is Hard): Object Intra-Class Variation
•
같은 의자 카테고리더라도, 모든 의자가 동일하게 생기지는 않음.
•
의자처럼 생긴 물체를 인식하는 것보다, “앉을 수 있는 구조” 로 생긴 것을 인식할 수 있는 능력이 필요하여 어려움.
Categorization
•
알고 있는 label (object) 로 분류하는 task
◦
영역 안에 있는 물체가 향후에 어떤 행위를 하게될지 등을 예측할 수 있음.
◦
영역 안 물체에 대한 다양한 질문들에 대한 답변을 할 수 있음 (ex. 위험한가? 살아있는가? 등) → 엄청나게 많은 정보를 얻을 수 있음.
Why do We Care about Categories?
•
Categorization 을 함으로써 이미지 속의 다양한 물체들이 어떠한 관계를 맺고 미래에는 어떤 행위를 할 지 예측이 가능함.
•
Categorization 은 다른 말로는 이미지 영역 내에 이름 붙이기로도 볼 수 있음.
◦
영역에 이름을 붙임으로써 알고 있는 사전 지식으로의 Pointer 역할을 하여 연결할 수 있음.
•
Communication 을 더 잘 할 수 있음.
◦
“털 달린 짐승을 봤어” 보다 “고양이를 봤어” 에 대한 이해가 높고 의사소통이 편함.
Theory of Categorization
1.
Definitional Approach
•
Plato & Aristotle 에 의해서 제안된 카테고리에 대한 개념.
•
카테고리는 카테고리에 속하는 모든 요소들이 공유하고 있는 특성의 리스트임.
◦
어떤 객체의 membership 은 binary (속하거나 안속하거나)
◦
카테고리에 속하는 모든 member 는 동일하게 취급함.
•
컴퓨터비전의 Attribute (색, 털의 유무, 줄무늬 유무) 을 통한 물체 인식에서 많이 활용됨.
2.
Prototype Approach
•
수많은 개들로부터 개들의 정수만을 뽑아 가장 이상적인 개를 상상하고 Prototype 이라고 정의함.
•
해당 Prototype 을 바탕으로 물체를 인식함.
◦
Prototype 은 특정 개를 지칭하는 것이 아니라, 일반적인 특성만을 가짐.
3.
Exemplar Approach
•
수많은 개들 중에서 Clustering 등의 방법을 통해 몇 개의 대표적인 개들 (Exemplars) 를 저장해둠.
•
저장해둔 Exemplar 들을 기반으로 물체를 인식함.
Levels of Categorization

•
모든 물체를 Taxonomy 를 기준으로 배치할 수 있음.
◦
동물 밑에 사족보행, 이족보행 등 …
◦
사족보행 및에 개, 고양이, 소 등 …
•
일반적으로 수행하는 Categorization 은 Basic Level 에서 이루어짐.
◦
개, 고양이, 소 간의 Categorization (엄밀한 정의를 내리긴 어려움)
▪
굳이 내리면, Similar Shape 와 Common Attributes 를 기준으로 Basic Level 을 정의함.
◦
Hierarchy 상에서 Basic Level 위를 Superordinate Level
◦
Hierarchy 상에서 Basic Level 아래를 Subordinate Level → FIne-Grained Recognition (ex. 다양한 새 종류를 구별, 다양한 꽃 종류를 구별 등)
Categorization in Vision
•
Object Categorization (Classification)
◦
ImageNet 이 나오기 전에 자주 쓰였던 Caltech 101 데이터셋이 있음.
•
Part (Beak) Categorization
◦
새의 부리의 타입을 분류하는 작업
•
Place, Image Style, Visual Font 에 대해서도 Categorization 이 가능함.
•
Region Categorization

◦
사진 상 각 영역에 대해서 방향 (Normal Orientation) 을 구하는 것만으로도 물체 인식에 큰 도움을 줌.
◦
이미지 픽셀별로 depth 를 classification 할 수도 있음.
◦
RGBD 이미지로부터 Semantic Segmenation 을 진행할 수도 있음.
Suprevised Learning
•
기본적으로 Image Classification 은 Supervised Learning 관점에서 접근함. (label 이 주어짐)
1.
개 이미지와 개가 아닌 이미지들을 많이 준비함
2.
이미지 자체는 픽셀 수가 너무 많아서 Classification 목적에 맞는 형태로 이미지를 표현하도록 특성을 추출함. (LAB Histogram, Textons, HOG 등의 feature 를 추출함.)
3.
Feature Space 상에 각 이미지는 point 로 표현이 되기 때문에 해당 공간에서 정의되는 Classifier 를 학습함으로써 이미지 분류를 구현할 수 있음.
Analogy to Documents
•
대통령의 연설문만 보고도 어느 대통령의 연설인지 맞추는 문제는 각 대통령이 자주 사용하는 단어들, 해당 시대의 이슈 등에 기반하기 때문에 이를 바탕으로 분류할 수 있음.
•
Bag-of-Words 는 각 documents 를 (순서를 무시하고 빈도만 남긴) 단어들의 집합으로 봄.
◦
먼저 Dictionary (Vocabulary) 를 정의함.
◦
DIctionary 밖의 단어는 OOV (Out of Vocabulary) 로 하나의 단어처럼 취급함.
◦
각 document 들을 각 단어의 빈도를 나타내는 벡터로 변환할 수 있음.
Bag of Words Model
•
이미지를 일종의 documents 로 취급할 수 있음.
•
자연어에서는 단어의 빈도를 셀 수 있는데, 이미지에서는 단어라고 할 수 있는 게 없기 때문에 엄청 많은 이미지 속에서 작은 feature 들을 뽑고 이들을 clustering 하고 clustering center 를 단어와 같은 개념인 visual words 로 취급함.
•
이미지를 해당 visual words 의 histogram 으로 표현할 수 있고 이를 이용해 classifier 를 학습할 수 있음.
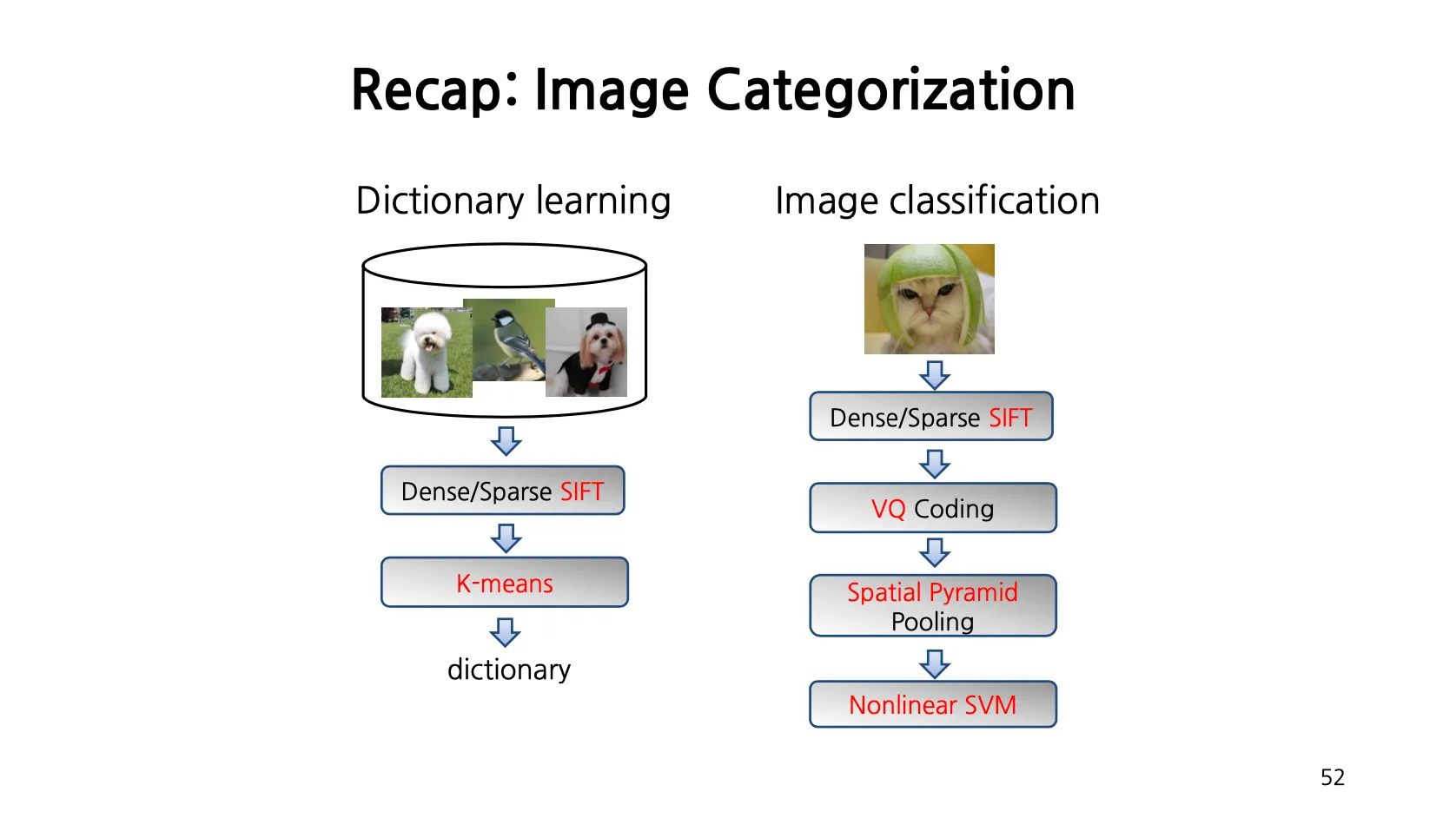
Outline: Bag of Words
1.
Extract Features (ex. SIFT descriptor)
2.
Learn Visual Vocabulary (Code Words)
•
K-Means Clustering 을 사용해 Clustering Center 를 구하고 VIsual Words 로 활용함.
3.
Quantize Features using Visual Vocabulary
•
각 이미지의 SIFT descriptor 마다 가장 가까운 cluster center 를 찾음.
4.
Represent Images by Frequencies of “Visual Words”
•
이미지 내 모든 SIFT descriptor 에 대해서 3번을 진행한 뒤 찾은 cluster center 들의 histogram 의 frequency 에 +1 을 해줌으로써 representation 을 찾아냄.
5.
Image Classifier 학습
1. Feature Extraction
•
크게 두 가지 approach 가 있음.
1.
Dense Regular Grid: 등간격으로 interesting point 를 찾고 SIFT descriptor 를 계산함.
•
보통 이 방법을 Image Classification 에서 많이 사용함.
•
Key Point Detection 까지 이미지에서 수행하면, 이미지별로 정해지는 SIFT descriptor 의 숫자가 크게 달라짐.
2.
Sparse Interest Regions: Interesting point detector 를 돌려서 찾은 후 SIFT descriptor 를 찾음.
•
이미지를 여러 descriptor 의 집합으로 표현이 가능함. (ex. SIFT descriptor)
2. Learning the Visual Vocabulary
•
이미지가 1000 장이고 각 이미지별로 500 개의 SIFT descriptor 를 뽑으면 총 500,000 개의 SIFT descriptor 를 얻을 수 있음. (이 떄 Vocabulary 를 만드는 과정에서는 Training Dataset 에서 만들지 않아도 됨. Training Dataset 은 classifier 를 학습하는 과정에서 사용함.)
•
해당 SIFT descriptor 에서 으로 설정하여 K-means Clustering 을 수행하여 각 cluster center 를 Visual Words 로 사용하면 Dictionary 를 500 개의 단어로 구성할 수 있음.
•
Clustering and Vector Quantization
◦
Clustering 이 visual vocabulary (codebook) 을 배우는 가장 일반적인 방법임.
▪
Clustering 방법론으로 K-means Clustering 이 가장 많이 활용되고 Cluster Center 가 codevector 가 됨.
▪
Codebook 은 Training Dataset 외의 데이터셋으로부터 배워도 무방함.
◦
Codebook 은 feature 를 qunatize 하는데 사용됨.
▪
이미지에서 특성을 추출하고 Dictionary 에 있는 단어 중 해당 특성과 가장 가까운 것과 mapping 하는 형태로 quantize 할 수 있음.
•
Visual Vocabularies: Issues
◦
Vocabulary Size 를 어떻게 골라야 할까?
▪
작은 : 굉장히 많은 feature 들이 같은 codevector 에 대응되기 때문에 분류 성능이 떨어짐.
▪
큰 : 매우 비슷한 두 feature 랑 어느정도 다른 feature 가 동일하게 서로 다른 codevector 에 대응되기 때문에 quantization artifact 가 생길 수 있음. (Overfitting)
•
Vocabulary 를 구성하는 과정, Vector Quantization 을 하는 과정을 빠르게 진행하는 알고리즘들이 발달해 옴. (ex. Vocabulary Trees)
3. Recap: BOW Classification
•
이미지를 고정된 크기 (Dictionary 크기 ) 의 represntation 으로 변경하면, 이후에 classification 을 적용할 수 있음. (ex. SVM)
But What about Spatial Layout?
•
BoW 는 Spatial Layout 을 제거해버림.
◦
두 눈, 한 코, 한 입이 랜덤하게 배치된 모든 사진을 BOW representation 상으로 동일하게 취급해버림.
◦
Color Histogram 이 같은 이미지들을 BOW approach 에서 구별할 수 없음.
Spatial Pyramid
•
기존 BOW 는 전체 이미지에 대한 BOW representation 을 만드는데, Binning 을 통해서 나눈 격자별로 각각 histogram 을 만들고 이들을 concatenate 하는 형태로 정의할 수 있음.
◦
Level 0 → 전체 이미지를 사용
◦
Level 1 → 가로 1번 세로 1번으로 나누어 4 갸의 bin 이 생김
◦
Level 2 → 한 번 더 반복해 16 개의 bin 이 생김.
•
Level 1 까지 고려하면 기존 벡터에서 로 벡터로 나타낼 수 있음.
•
이 정도까지만 Spatial Layout 을 고려해도 성능이 많이 좋아짐.