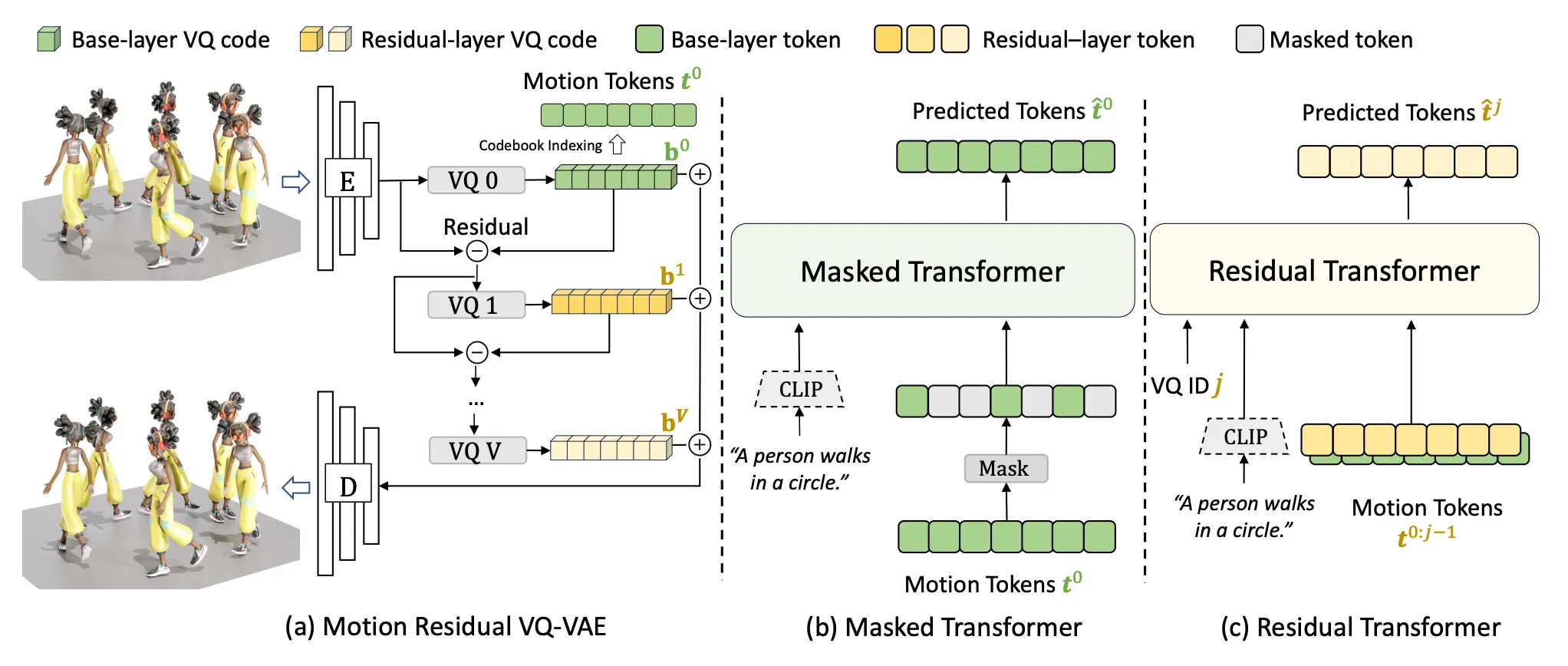
Model Architecture
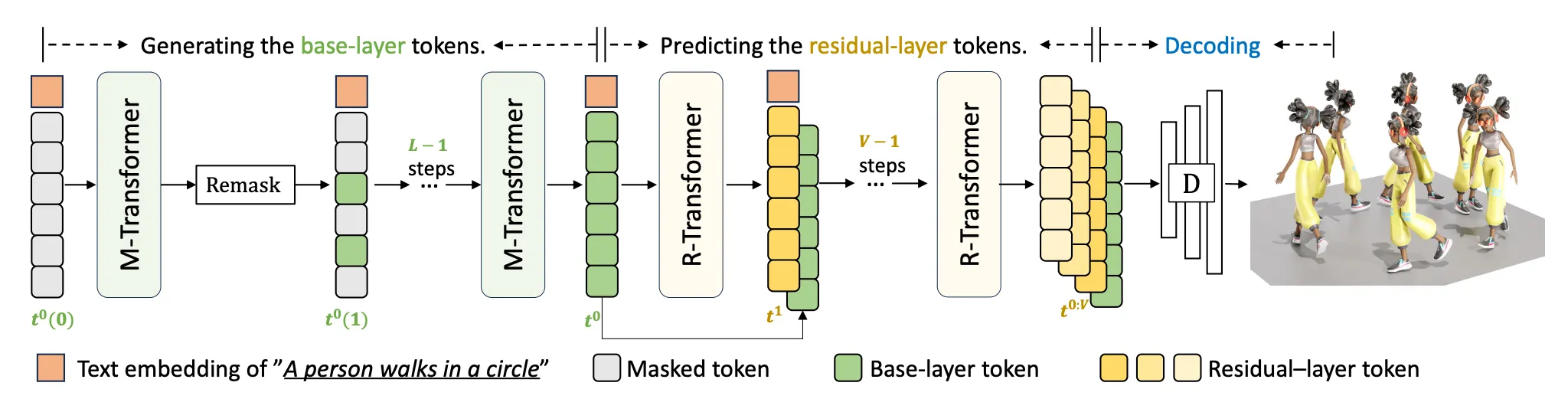
Inference Pipeline
Objective
Text-to-3D Human Motion Generation
Method
•
Motion Residual VQ-VAE
◦
Motion 을 입력하여 복원하는 encoder 와 decoder 를 학습하는 단계
◦
Residual VQ (RVQ) 구조를 사용하여, encoding 하고 vector quantization 을 하고, 남은 차이를 또 vector quantization 하는 것을 반복하며 최종 벡터는 residual 들의 합으로 정의하고 decoding 하게 됨
◦
Inference 단에서는 생성한 토큰들을 기반으로 decoding 하는 용도로 motion 을 generate 할 때 사용됨.
•
Masked Transformer
◦
Motion Token 은 vector quantize 된 벡터에 codebook indexing 을 거친 값
◦
Masked Transformer 는 Masked 된 Motion Token 을 입력 받아서 plausible 한 predicted motion token 을 만드는 능력을 학습함.
◦
나중에 inference 단에서 text 가 주어졌을 때 base level 의 token 을 만드는 용도로 사용됨.
•
Residual Transformer
◦
Residual Transformer 는 앞선 토큰들과 text 를 입력으로 받아서 다음 토큰을 예측하는 능력을 학습함.
◦
Inference 단에서는 Masked Transformer 가 base level token 을 만들었다면, 그 후의 residual 한 토큰들도 만들 때 사용됨.