
본 포스트에서는 Latent Diffusion Model 을 사용하여 고해상도 비디오를 생성해낸 논문에 대해서 소개드리려고 합니다.
Project Page 및 논문을 직접 읽어보시고 싶으신 분들은 위 링크를 참고하시면 좋습니다.

Objective
Generative Models 영역에서 Diffusion Model 은 기존에 트렌드였던 GAN 을 넘어(…) 많은 computation 을 필요로 하지 않으면서도 높은 퀄리티의 이미지 생성에 성공했습니다. 하지만, 이미지의 생성에 성공적인 것과는 사뭇 다르게 비디오의 생성에 있어서는 큰 진전을 보여주지는 못했고 이는 비디오 데이터를 처리하는데 필요한 computational cost 가 이미지의 처리에 필요한 양보다 압도적으로 많았고, 방대한 오픈소스 데이터셋이 존재하지 않았기 때문이었습니다.
그럼에도 불구하고, Diffusion Model 을 사용하여 비디오를 생성하려는 시도들은 존재했는데, 이들은 저해상도의 짧은 비디오만을 생성하는데 그쳤습니다. 논문에서는 고해상도의 긴 비디오를 생성하는 것이 크게 (1) Real World 고해상도 주행 데이터의 생성과 (2) Creative Content Generation 을 위한 텍스트 기반의 비디오 생성 이라는 측면에서 실생활의 문제를 해결하는데 사용될 수 있다고 이야기 합니다.
Generated Video “Milk Dripping into a Cup of Coffee”
이러한 목적을 가지고, 논문에서는 기존의 2D Latent Diffusion Model 에서 부가적인 학습을 하는 방법으로 위와 같이 텍스트를 입력받아 고해상도의, 높은 퀄리티를 가진 비디오를 생성할 수 있는 방법론인 Video LDM 을 제시합니다.
Method
논문에서는 Image LDM 을 fine-tune 하기 위해 다음과 같은 형태의 데이터셋의 사용을 가정합니다.
이는 height , width 를 가지는 이미지가 개 sequential 하게 존재하는 데이터 구조입니다. 그리고 논문에서 준비한 이러한 형태의 데이터셋의 분포를 라고 명명합니다.
Turning Latent Image into Video Generators
기존 Image LDM 은 각각의 이미지를 높은 퀄리티로 생성해주지만, 해당 모델은 temporal awareness 가 없기 때문에 이를 이용해 개의 연속적인 frame 을 생성하면, 연속적인 이미지로 구성된 비디오를 생성할 수 없습니다. 논문에서는 이를 해결하기 위해 기존의 spatial layers 에 추가적인 Temporal Layers 을 추가하여 temporal awareness 를 부여하려는 시도를 합니다.
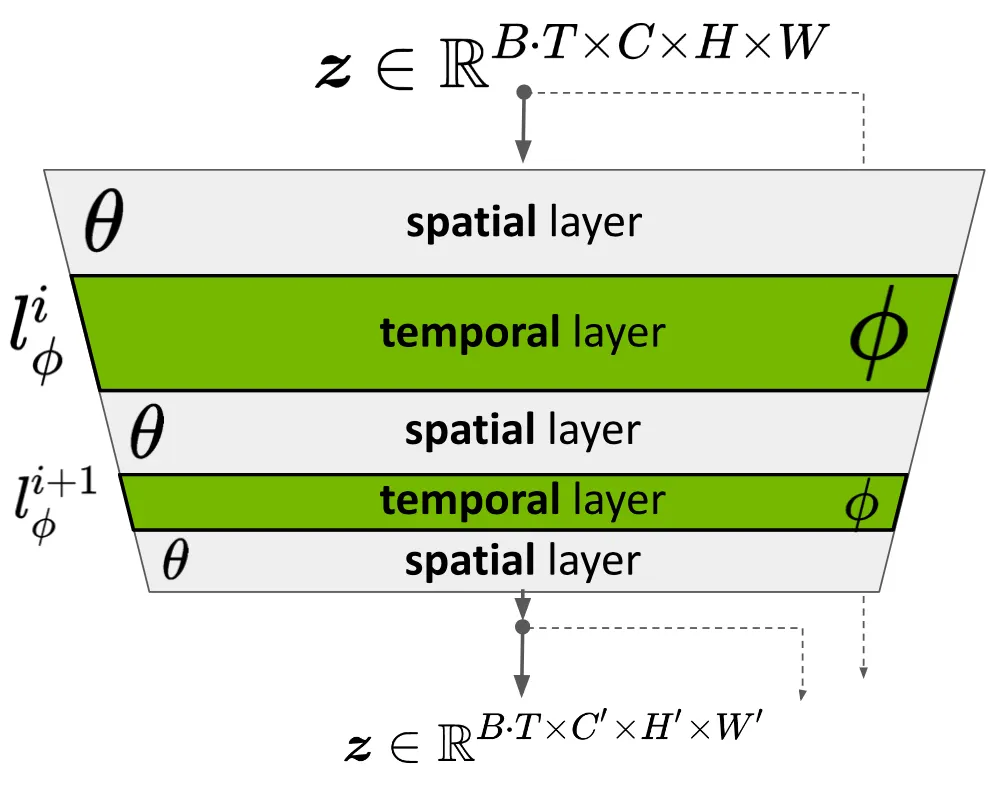
Turn Pre-Trained LDM into a Video Generator
위의 그림은 기존 LDM 의 denoising network 를 구성하는 하나의 U-Net encoder block 입니다. 논문에서는 기존의 U-Net encoder block 을 구성하고 있는 Spatial Layer 사이에 Temporal Layers 를 넣고, Spatial Layer 의 parameters 는 고정하고 Temporal Layers 의 parameters 만 학습하는 형태로 네트워크를 변경합니다.
입력으로는 LDM 의 vae encoder 를 거친, batch size , sequence length 의 세팅에서 의 형태의 latent vector 가 들어오게 되며, 출력으로는 같은 batch size 와 sequence length 를 가지면서 다른 channel, height, width 를 가진 vector 가 출력되고, U-Net 의 구조 상 decoder 에서 크기가 다시 복원됩니다.
이 때 중요한 점은 Temporal Layer 가 단순한 U-Net 의 layer 가 아니라, 전 후로 다음과 같은 dimension reshaping 과정을 동반한 layer 라는 점입니다.
위 식에서 주요하게 살펴볼 수 있는 점은 sequence 를 나타내는 dimension 과 channel 을 나타내는 dimension 의 위치가 바뀌어서 Temporal Layer 의 입력으로 들어가고, 나온 출력을 다시 Spatial Layer 에 넣기 전에 다시 형태를 복원한다는 점입니다. 즉, 기존에는 입력 이미지의 spatial 정보를 가지고 있는, 의 latent vector 를 하나의 데이터로 하여 이 데이터가 sequential 하게 개, 그리고 이런 sequential 데이터가 batch size 만큼 존재한다고 생각할 수 있었던 반면, rearrange 된 벡터에서는 라는 sequential 한 정보를 담고 있는 latent vector 를 하나의 데이터로 하여 이 데이터가 개, 그리고 이런 데이터 집합이 batch size 만큼 존재한다고 생각할 수 있습니다.
이러한 세팅은 기존 Spatial Layers 만 존재했던 Image LDM 에 sequential 하게 데이터를 넣어도 이 데이터들 간의 정보 교환이 일절 없어 독립적인 이미지가 생성되었던 반면, dimension 의 위치를 바꾸어 하나의 데이터에 본인과 channel 이 같고 sequential 한 입력의 정보를 섞어 넣음으로써 하나의 이미지를 생성할 때 sequential 데이터의 정보도 사용하게 하고, 궁극적으로는 네트워크가 생성된 이미지간의 관계를 표현할 수 있는 표현력을 가질 수 있는 세팅이라고 볼 수 있습니다.
표현력을 가진다는 세팅에 걸맞게 논문에서는 learnable parameter 를 두어 기존 Spatial Layer 의 output 과 추가적으로 Temporal Layer 를 거친 것의 output 을 적절한 비율로 섞는 과정을 진행합니다. 이는 다음과 같습니다.
위 식에서 는 한 Spatial Layer 의 출력이고, 는 해당 Spatial Layer 다음에 오는 Temporal Layer 의 출력입니다. 마치 ResNet 에서 사용한 것과 같은 skip connection summation 을 weight 를 가지고 수행한다고 볼 수 있습니다. Inference 단에서 로 하면 기존 Image LDM 의 기능을 동일하게 표현할 수 있습니다.
이런 식의 세팅에서 학습은 기존 Image LDM 에서와 동일하되, 앞서 언급한 것과 같이 Spatial Layer 는 고정하고 Temporal Layer 의 weight 만 변경하는 형태로 다음과 같이 진행합니다.
위 식의 로, denoising network 의 U-Net block 의 입력 항목입니다. 각 입력은 일반적인 LDM 처럼 gaussian-sampling 된 noise 과 uniform-sampling 된 time step 에 의해서 계산되며 는 sampling 된 noise 값 혹은, scheduler 에 따라서 로 정의되는 값입니다. 는 conditioning information 이며, text prompt embedding 을 생각하시면 됩니다.
Temporal Autoencoder Finetuning
논문의 Video LDM 은 pre-trained Image LDM 에 기반을 두고 있지만, Image LDM 의 autoencoder 를 그대로 사용하여 Video 를 생성하게 되면 flickering artifacts 가 나타났다고 합니다.
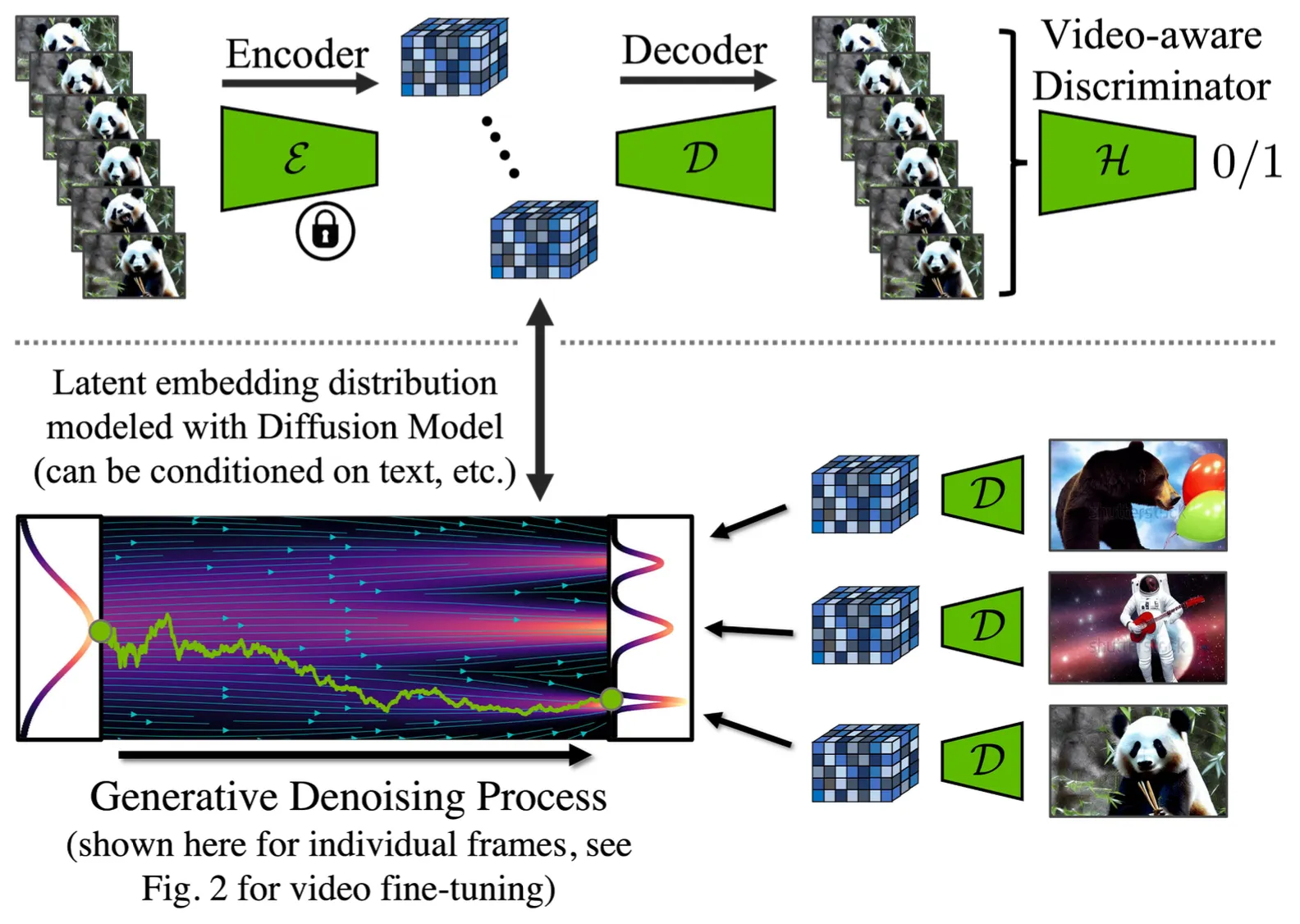
Temporal Decoder Fine-Tuning
이를 해결하기 위해서 논문에서는 encoder 를 고정한 채 decoder 에 temporal layers 를 추가하고, 3D convolutions 으로 구성된 video-aware discriminator 를 이용해 autoencoder 를 fine tuning 합니다. 논문에서 구체적으로 언급하진 않지만 pre-trained video-aware discriminator 를 사용하여 decoder 의 Temporal Layer 가 temporal consistency 를 유지하는 방향으로 학습되도록 한 것으로 보입니다. 여기서 encoder 를 고정하는 이유는 이미지에서 잘 동작하는 좋은 representation 을 추출하는 encoder 를 video 의 각 프레임에 재사용해도 되기 때문이라고 이야기하고 있습니다.
Prediction Models for Long-Term Generation
앞에서 언급한 방법론을 사용하면 짧은 길이의 비디오를 생성해낼 수 있지만, 긴 영상에 대해서는 불가능했습니다. 모델에서 한 번의 inference 과정에서 허용되는 GPU 만큼의 이미지 수만큼의 frame 을 가지는 비디오만큼의 길이가 최대였기 때문입니다.
논문에서는 긴 길이의 비디오 생성을 위해서 논문의 Video LDM 이 이전 context images 를 condition 으로 받아 다음 image 들을 생성할 수 있는 구조를 학습합니다. 이를 반복적으로 사용하게 되면 길이를 늘릴 수 있을 것이라고 생각한 것입니다.

Network Design for Long-Term Generation
논문에서는 학습할 때 입력 Sequence 의 길이가 일 경우 앞의 개의 context frame 만을 가지고 나머지 개의 frame 을 예측하도록 설계합니다. 이를 구현하기 위해서 conditioning 을 위한 변수 를 다음과 같이 선언합니다.
여기서 는 VAE 의 encoder 를 통과하여 생성된 latent 이며, 는 temporal mask 입니다. Temporal mask 는 앞서 설명한 frame 을 가리는 역할을 하며, 이 경우에는 개의 frame 을 mask out 하는 역할을 하여 개의 frame 만 conditioning 에 사용하도록 합니다. 이 과정이 위의 식에서 로 표시된 부분입니다. 이 값과 를 concatenate 한 값이 최종적인 conditioning vector 입니다. 이 conditioning vector 를 다시 learned downsampling operation 을 통해 변환하여 Temporal Layer 에 넣어 LDM 에서의 conditioning 을 진행하는 것입니다. 논문에서는 구체적으로 어떻게 conditioning information 을 넣는지에 대해서 언급해주고 있지는 않습니다. 이를 식으로 표현하면 다음과 같습니다.
앞선 식에서 text conditioning term 뿐만이 아니라 temporal conditioning term 이 하나 더 추가 된 형태입니다. 논문에서는 inference 시에 이러한 conditioning 의 효과를 크게 보기 위해서 classifier-free guidance 를 사용하는 것이 좋았다고 말하며 이는 일반적인 text conditioning 과 동일하게 다음과 같이 동작한다고 밝혔습니다.
더불어, 실제 세팅에서는 context frame 의 개수 로는 만 사용하는데 처음 text 기반으로 이미지를 생성하고, 다음으로 생성한 하나의 이미지를 context 로 sequence 를 생성하고, 그 이후부터는 마지막 두 개의 이미지를 이용해 sequence 를 생성하는 과정을 진행합니다.
Temporal Interpolation for High Frame Rates
High-Resolution Video 는 비단 spatial resolution 이 높아야 하는 것 뿐만 아니라 temporal resolution 이 높아야 합니다. 논문에서는 temporal resolution 을 높이기 위한 방법론의 일환으로, 비디오를 생성하는 과정을 두 개의 부분으로 나눕니다.
첫 번째 부분은 앞서 설명드렸던, 텍스트로부터 이미지, 이미지로부터 다음 이미지들을 생성하는 과정을 거쳐서 key frames 가 되는 이미지들을 생성하는 과정이고, 두 번째 부분은 생성한 key frames 사이를 interpolation 하는 이미지들을 생성하는 과정입니다. 두 번째 과정은 첫 번째 과정의 prediction model 과 동일하게 주어진 데이터를 masking 하여 예측하는 형태로 학습이 진행되며, 논문에서는 두 프레임 사이에 세 개의 프레임을 masking 하여 최종적으로 의 interpolation 을 진행하는 추가적인 모델을 학습하게 됩니다. 이 때, 전반적인 학습 방법론은 이전의 방법과 완벽하게 동일하게 사용했습니다.
Temporal Fine-tuning of SR Models
Image LDM 자체가 괜찮은 resolution 을 보여주긴 했지만, 논문에서는 megapixel 단위로 결과물을 뽑아내고 싶었기 때문에, diffusion 기반의 super resolution 모듈을 붙이려는 노력을 합니다. 다만, 각각의 비디오 프레임에 독립적으로 super resolution 모듈을 통과시키게 되면, 애써 앞에서 맞추어놓은 temporal consistency 가 무너지기 때문에, 논문에서는 마찬가지로 video-aware 한 SR Diffusion Model 을 만들고자 합니다.
이러한 SR Model 도 앞선 논문의 방법론과 Temporal Layer 를 추가하는 방법으로 동일하게 위와 같은 objective 으로 fine-tuning 하게 됩니다. 위 식에서 는 학습하고자 하는 SR model 이라고 보면 됩니다. Resolution 을 올리는 작업만을 담당하기 때문에 앞선 모델과는 다르게 prediction 과 interpolation 을 위한 masking 조치가 필요없습니다.
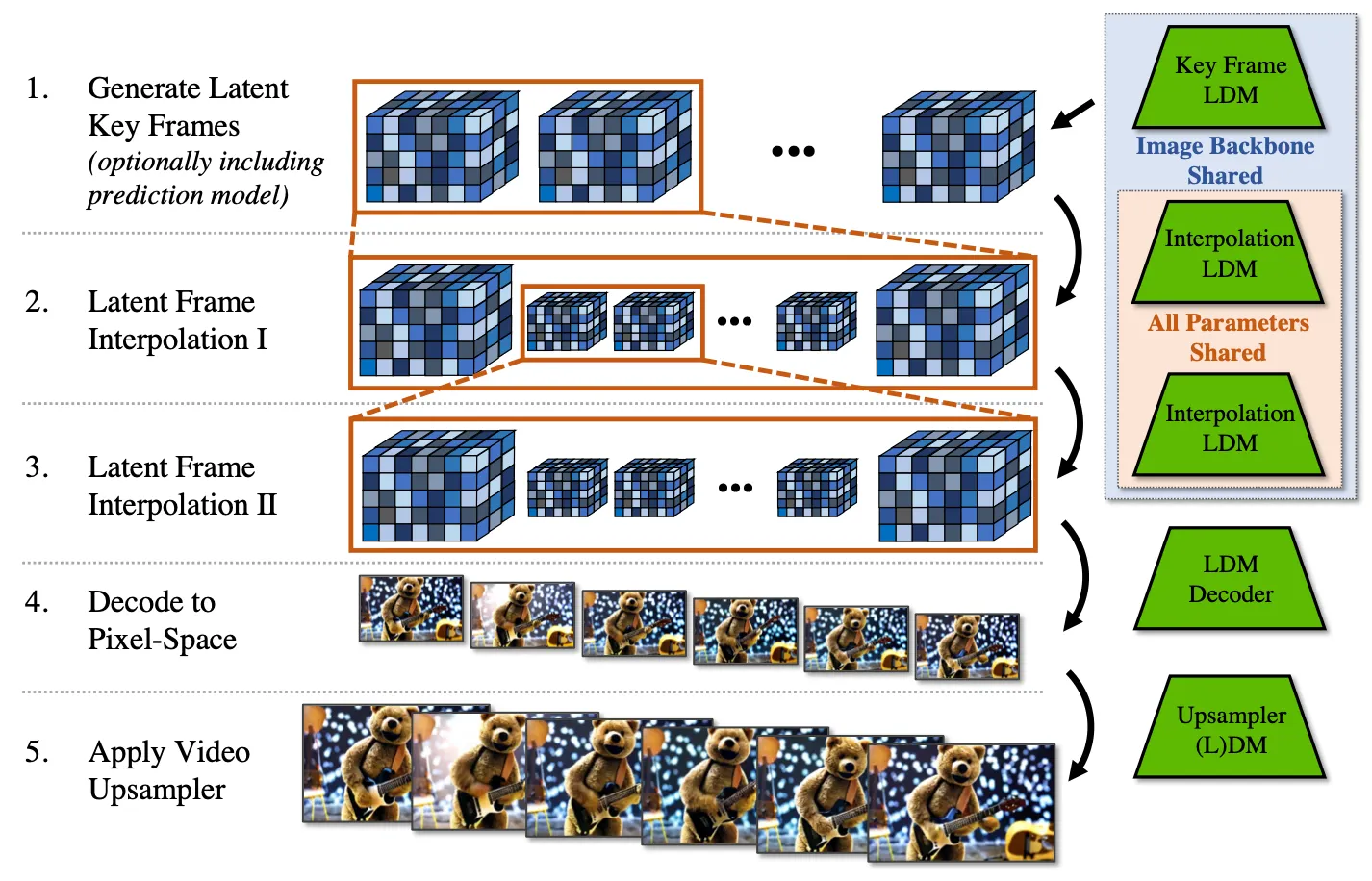
Overall Pipeline of Video LDM
정리하자면, Video LDM 의 inference 는 위의 그림과 같은 파이프라인을 가집니다. 가장 먼저 Key Frame LDM 을 사용하여 key frames 들을 생성해내고, Interpolate LDM 을 두 번 적용하여 만큼의 temporal resolution 을 확보합니다. 이후 LDM decoder 를 통과하여 pixel space 로 변환한 뒤 (Video-Aware) Upsampler LDM 을 통과하여 최종적인 비디오를 생성하게 됩니다.
Experiments
Datasets
논문에서는 크게 두 가지 데이터셋을 사용하여 그들의 방법론에 대한 평가를 위한 실험을 진행합니다. 첫 번째 데이터셋은 Real Driving Scene (RDS) video 의 in-house dataset 을 사용했고, 이는 8 초동안 지속되는 개의 비디오로 구성된 해상도의 데이터셋입니다. 이 데이터셋은 낮 / 밤에 대한 라벨, scene 에 등장하는 자동차의 수 (crowdedness) 와 그에 대한 bounding box 또한 포함되어 있습니다. 두 번째 데이터셋은 WebVid-10M 데이터셋으로, video-caption 쌍으로 이루어진 개의 데이터셋으로, 논문에서는 크기로 resize 하여 사용했다고 제시하고 있습니다.
Evaluation Metrics
평가 지표로는 일반적인 이미지의 도메인 거리를 나타내는 FID score 와 이의 비디오 버전인 FVD score, human evaluation, CLIP similarity, 그리고 IS score 를 사용합니다. 생성모델 관련 논문에서 자주 등장하는 지표를 논문에서도 동일하게 사용한 모습입니다.
Model Architecture and Sampling
논문에서 fine tuning 에 사용한 Image LDM 은 Latent Diffusion Model 을 처음 제시한 논문인 [Rombach et al.] 의 구조를 그대로 가져왔고, U-Net 의 구조는 Diffusion Model 을 처음 제시한 논문인 [Dhariwal et al.] 의 구조를 사용했다고 합니다. Super Resolution 을 위한 Pixel Space Diffusion Model 에서도 동일하게 [Dhariwal et al.] 의 U-Net 구조를 사용했으며, scheduler 는 DDIM 을 사용합니다.
High-Resolution Driving Video Synthesis
논문에서는 piexl-space Video Upsampler 를 사용한 Video LDM 파이프라인을 RDS 데이터셋으로 학습합니다. 이 때 낮 / 밤 라벨과 crowdedness 에 conditional 하게 학습을 진행했고, 학습 과정에서 classifier-free guidance 와 unconditional synthesis 를 위해서 이러한condition 정보를 drop 하여 학습했습니다.

Comparison with LVG on RDS
위 표의 좌측은 선행연구인 Long Video GAN () 와의 성능 비교를 보여줍니다. 전반적으로 논문의 방법론이 FVD 및 FID score 가 낮은 것을 보여주었고, 특히 condition 을 추가로 준 경우 FVD score 를 더욱 낮출 수 있음을 보여주었습니다.

User Study on Driving Video Synthesis on RDS
위 표는 RDS 데이터셋의 결과에 대한 User Study 입니다. 는 비교항목의 좌측이 realistic 한 결과인 것 같다고 이야기 한 비율, 는 비교항목의 우측이 더 realistic 결과인 것 같다고 이야기한 비율입니다. 논문의 방법론이 에 비해서, 그리고 condition 을 줄 때가 그렇지 않을 때보다 realism 측면에서 선호도가 높은 것을 확인할 수 있었습니다.

Evaluation of Temporal Fine Tuning
위 표는 Upsampler 를 video-aware 하게 fine tuning 한 논문의 세팅에 대한 영향을 평가한 것입니다. 논문의 Video Upsampler 를 사용한 결과 FVD score 가 유의미하게 낮아진 것을 확인할 수 있었고 이는 각각의 프레임을 Image Upsampler 로 upsampling 한 것에 비해 temporal consistency 를 잘 유지할 수 있었기 떄문이라고 보고 있습니다. 다만 Temporal Layer 를 추가하고 학습했기 떄문에 이미지 단에서는 거의 영향이 없는 모습을 살펴볼 수 있습니다.
Ablation Studies
논문에서는 제시한 세부적인 방법론의 유의미함을 보이기 위해서 ablation study 를 진행합니다. 그 대상이 되는 것은 논문의 네트워크 구조이며 각각 (1) Pixel DM 으로 교체한 경우, (2) End-to-End LDM 으로 처음부터 RDS 데이터셋으로 학습한 경우, (3) Temporal Layer 에 3D convolutions 을 사용하지 않고 attention 만 사용한 경우, 그리고 (4) context-guidance 를 사용하지 않은 경우가 비교 대상입니다.
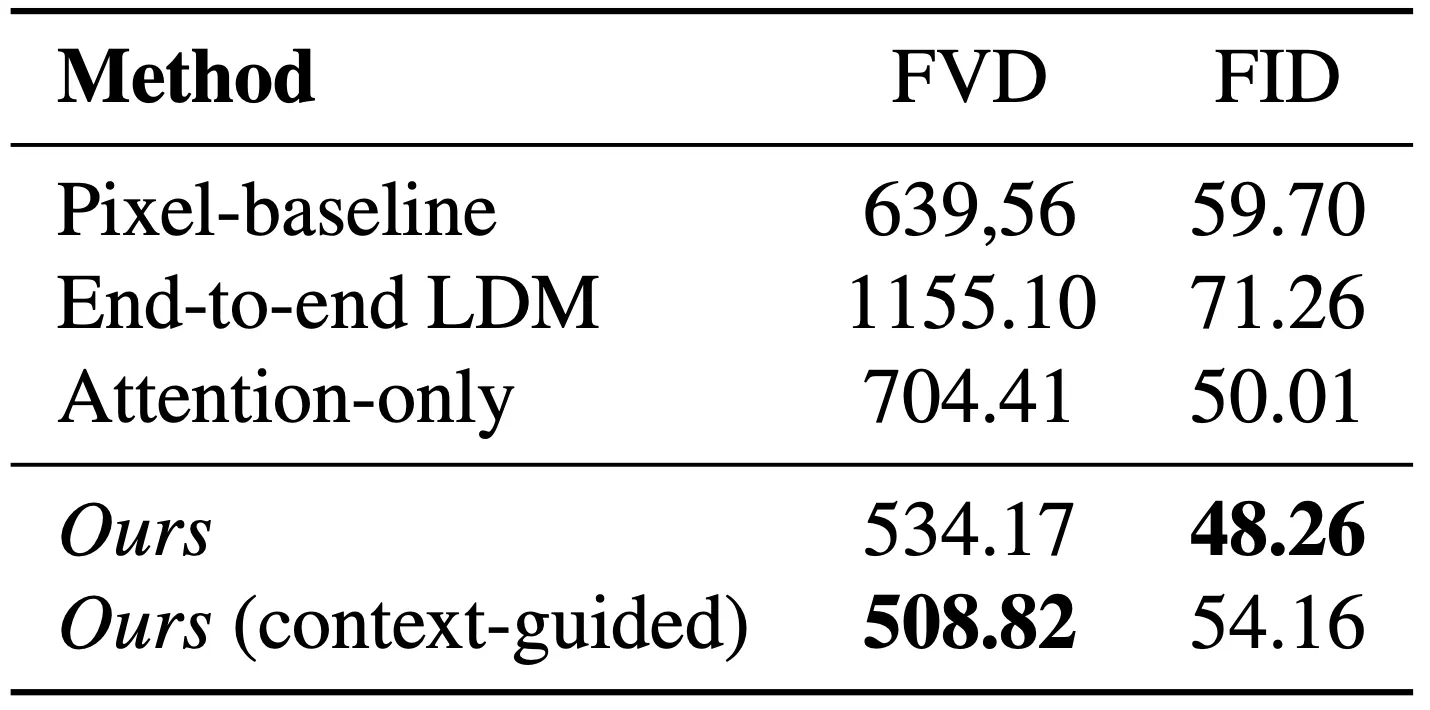
Ablation on Network Setting
그 결과, Pixel DM 과 처음부터 LDM 으로 학습한 경우는 현저하게 지표가 높아진 것을 볼 수 있으며, 3D convolutions 를 사용하지 않고 attention 으로 두 Temporal Layer 를 쌓는 경우 또한 지표가 높아진 것을 확인할 수 있었습니다. 더불어 context guidance 를 사용할 수 있도록 condition, uncondition 을 동시에 학습하여 inference 에 사용하는 것이 성능의 미세한 향상이 있었습니다.

Ablation on Decoder Fine Tuning
논문에서는 decoder 의 fine tuning 또한 ablation study 로 제공합니다. 이는 video-aware discriminator 로 fine tuning 하는 과정의 유무이며, fine tuning 한 경우가 FVD score 를 유의미하게 낮춤을 확인할 수 있었습니다.
Driving Scenario Simulation
논문에서는 RDS 데이터셋으로 학습한 모델이 생성해낸 결과물에 대한 정성적인 자료를 제시합니다.

Qualitative Results on Driving Scenario Simulation
이 때, 위의 그림의 붉은색 박스 이미지로부터 두 갈래의 서로 다른 시나리오의 예측 결과를 만들어내는 결과를 통해 논문의 방법론이 그럴듯한 다양한 시나리오를 생성해낼 수 있음을 보여줍니다.
Text-to-Video with Stable Diffusion
논문에서는 Image LDM 을 WebVid-10M 데이터셋으로 fine tuning 한 뒤에 text conditioning 이 가능한 Temporal Layer 를 추가하여 재 학습합니다. 더불어 Super Resolution 을 위한 Upsampler 도 학습하여 최종적으로 해상도의 비디오를 생성해냅니다.

Qualitative Results of Text-to-Video
논문에서는 먼저 위와 같은 정성적인 생성 결과를 제시합니다. 위 그림에서 첫 번째 행은 “An astronaut flying in space, 4K, high resolution” 이고, 두 번째 행은 “Milk dripping into a cup of coffee, high definition, 4k” 의 prompt 를 가지고 생성되었다고 합니다. Web-Vid-10M 데이터셋이 일반적인 실생활의 비디오 수준의 이미지 퀄리티만 가지고 있었지만 위와 같이 높은 표현력이 나타날 수 있는 이유로 논문에서는 Image LDM 의 생성 능력을 비디오단으로 잘 옮겼기 떄문이라고 이야기하고 있습니다.

UCF-101 Text-to-Video Generation

MSR-VTT Text-to-Video Generation
논문에서는 zero-shot text-to-video generation task 에 대해서 다른 선행연구들과 비교한 결과를 제시합니다. 위 표의 좌측은 UCF-101 데이터셋 (action 을 text 로 쓴 듯 합니다), 우측은 MSR-VTT 데이터셋으로 평가한 결과이며, Make-A-Video 를 제외하고는 다른 선행연구들에 비해서 지표 상으로 우월한 결과를 얻었습니다. 논문에서는 Make-A-Video 가 text-to-video 에만 초점을 맞춘 연구이며, 또 다른 데이터셋으로도 학습이 되었다는 것을 언급하여 지표에서 진 이유를 설명하려고 합니다.
Personalized Text-to-Video with Dreambooth
논문에서는 그들의 방법론을 사용하면 Video LDM 을 fine tuning 하여 만들 수 있다는 것 이상으로 응용 가능성을 제시합니다. 한 번 학습된 Temporal Layers 를 다른 Stable Diffusion Model 에 붙여도 동일하게 비디오를 생성할 수 있음을 보인 것입니다.

Application in DreamBooth
위 그림은 DreamBooth 로 학습한 Diffusion Model 에 pre-trained 된 Temporal Layer 를 추가하여 비디오를 생성한 결과입니다. 놀랍게도, DreamBooth 를 통해 개인화가 이루어진 토큰을 사용하여 Temporal Coherent 한 비디오를 생성할 수 있음을 확인할 수 있었습니다.
Conclusion
이것으로 논문 “Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models” 의 내용을 간단하게 요약해보았습니다.
이 논문은 프로젝트 페이지에서 temporal resolution 과 spatial resolution 이 모두 높으면서도 temporal coherency 까지 챙긴 비디오가 생성되는 것이 놀라워서 읽게 되었는데, 확실히 Key Frame Generation, Frame Interpolation, Upsampler 등등을 덕지덕지 달고 있어서 읽기에 편하지만은 않았던 논문이었습니다.
특히 저는 diffusion 및 diffusion 의 fine tuning 에 대한 이해가 어느 정도 있었음에도 어느정도 난해한 설명들 (context conditioning 이 구체적으로 어떻게 구현되는지…) 에 이해가 어려웠고, 코드도 공개되어 있지 않아서 많이 답답했는데 diffusion 에 대한 이해가 부족하면 정말 어렵게 느껴질 수 있을 것 같습니다.
총평은, 아이디어나 개괄적인 내용만 이해하기에는 괜찮은 논문이지만, 깊게 읽기에는 디테일을 다 담겨 있진 않아서 어려운 논문이었던 것 같습니다. 다만, Text-to-Video 분야에서는 qualitative 한 결과가 현재로써는 가장 좋아보이기 때문에 이 분야에 관심이 있다면 Make-A-Video 와 함께 읽어보시는 것도 괜찮을 것 같습니다.