

본 세션에서는, Artificial Neural Network(ANN) 의 가장 기본이 되는 단위인 Perceptron(P) 에 대해서 알아보려고 합니다.
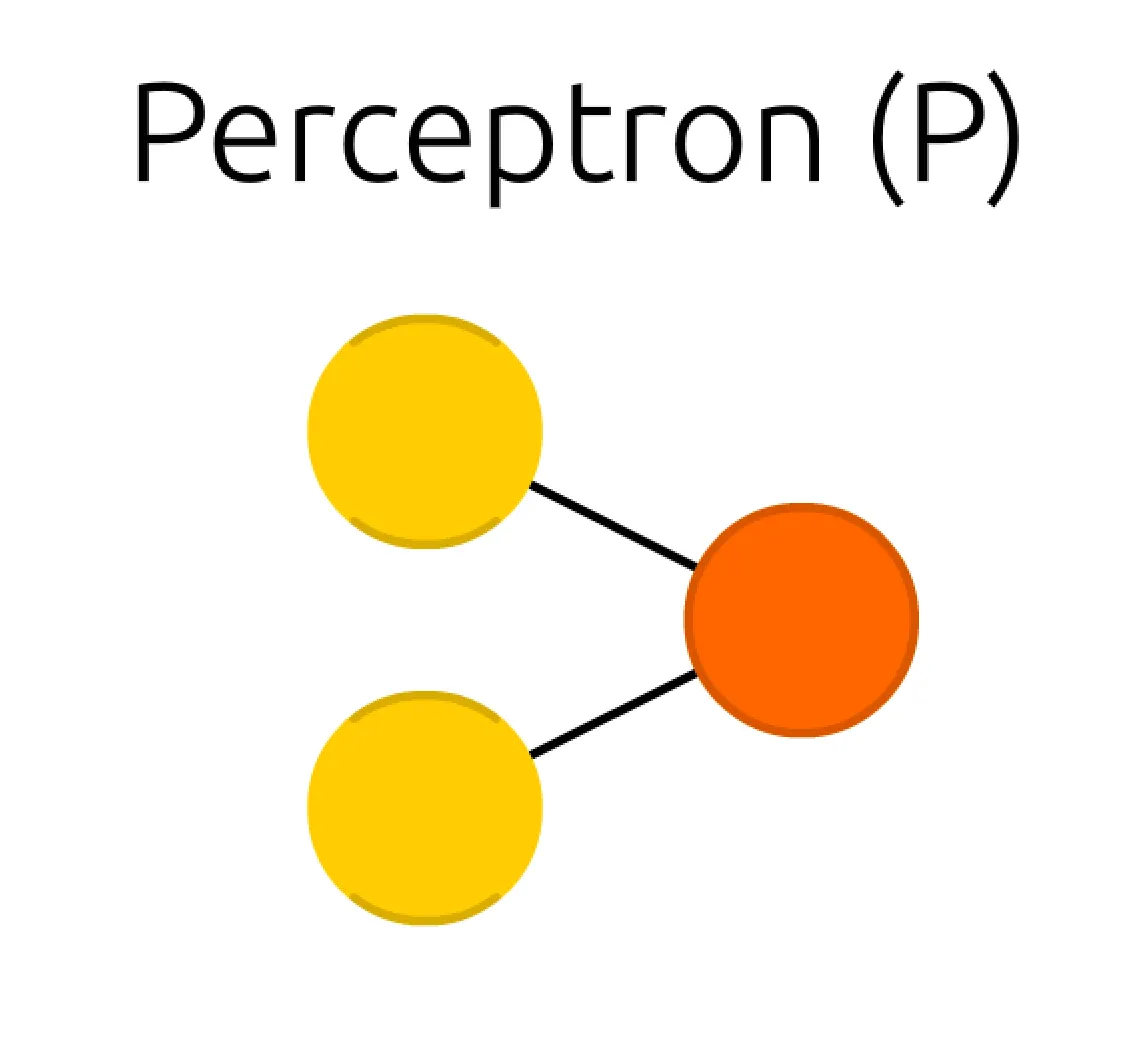
흔히, ANN(인공 신경망) 이 인간의 신경망을 기반으로 한 모델이라는 말을 들어보셨을 것입니다. 이러한 말이 나오게 된 이유는 perceptron 의 설계가 신경망의 기본 단위인 뉴런과 비슷하기 때문입니다.
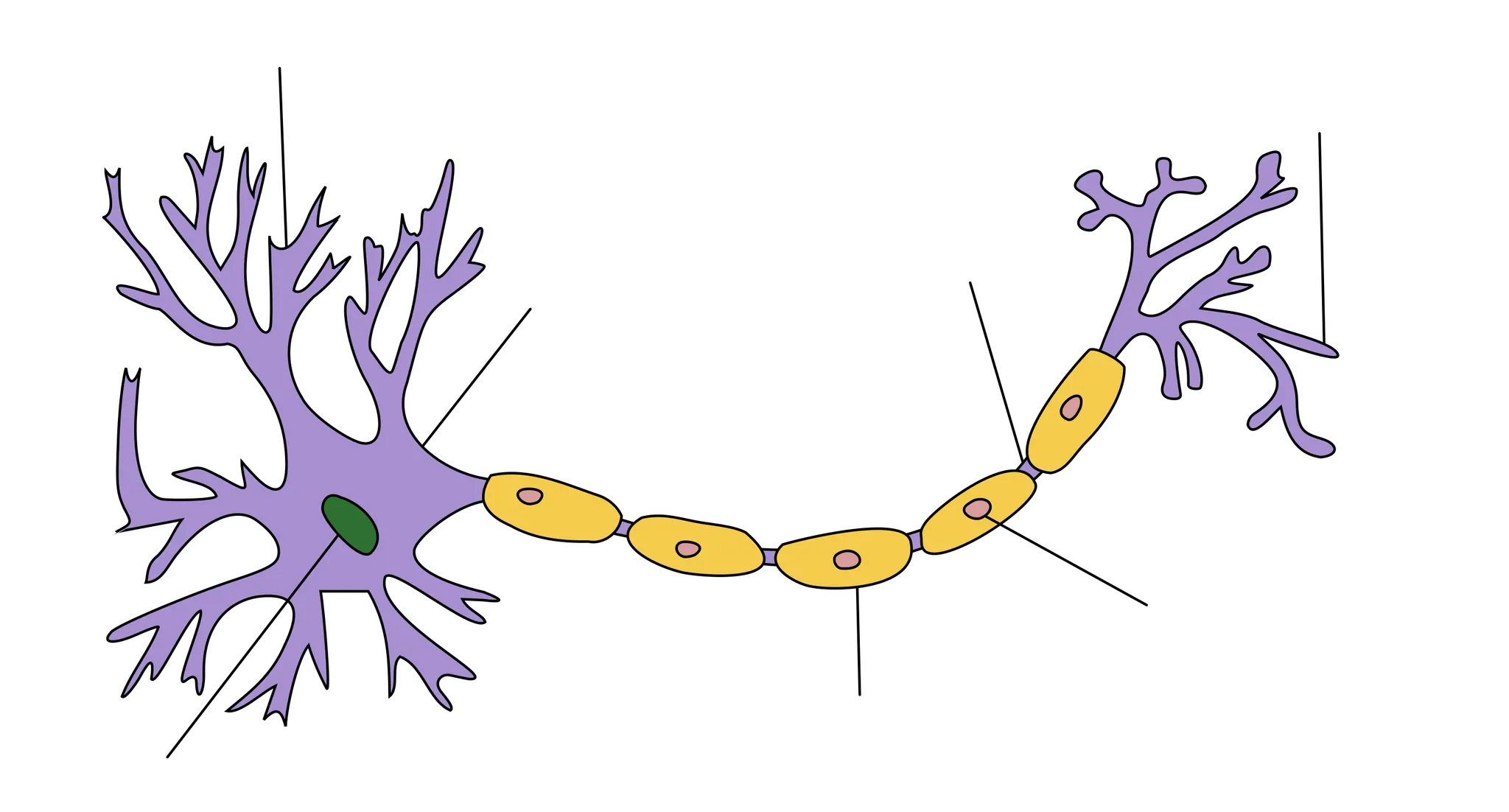
위 그림은 뉴런의 모습입니다. 중, 고등학교 생물에서도 배우지만, 뉴런은 dendrite(수상돌기) 와 axon(축삭돌기) 로 구성되어 dendrite 로부터 얻은 모든 자극이 임계치를 넘어가면 axon 을 통해서 다음 뉴런으로 전달됩니다.
Perceptron (퍼셉트론)은 코넬 항공 연구소의 프랑크 로젠블라트(Frank Rosenblatt) 가 1957년에 제안한 초기 형태의 인공 신경망으로, 다수의 입력(input) 으로부터 하나의 결과(output) 을 내는 알고리즘입니다. 아까 이야기 했던 뉴런도 dendrite 로부터 얻은 모든 자극을 하나의 axon 을 통해 보냈었습니다.
자, 이제 좀 위의 perceptron 의 모습과 비슷해보이시나요?
뉴런이 신경망의 기본 단위가 되듯이, perceptron 이 인공 신경망의 기본 단위가 됩니다. 자연스럽게 perceptron 이 어떻게 인공 신경망의 기본 단위가 될 수 있는지에 대해서 궁금해하실 수 있습니다.
답은 상당히 간단합니다.
놀랍게도, perceptron 을 가지고 원하는 간단한 모델을 학습시킬 수 있기 때문입니다. 가장 유명한 예시들로는 AND Gate, OR Gate, NAND Gate 를 perceptron 을 가지고 구현하는 것입니다.
본 세션에서는 AND Gate 를 학습을 통해서 구현하는 것을 예시로 보여드리려고 합니다.
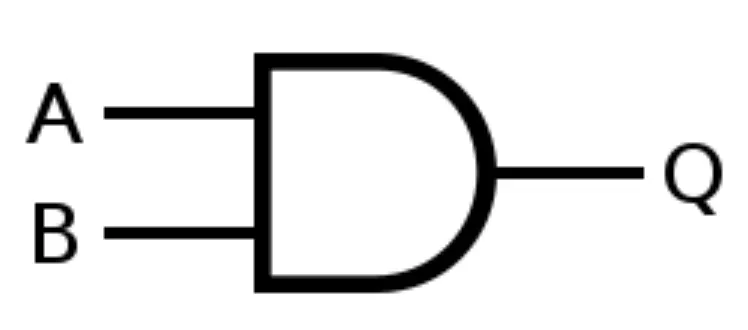
학습의 목적은 AND Gate 를 구현하는 것입니다.
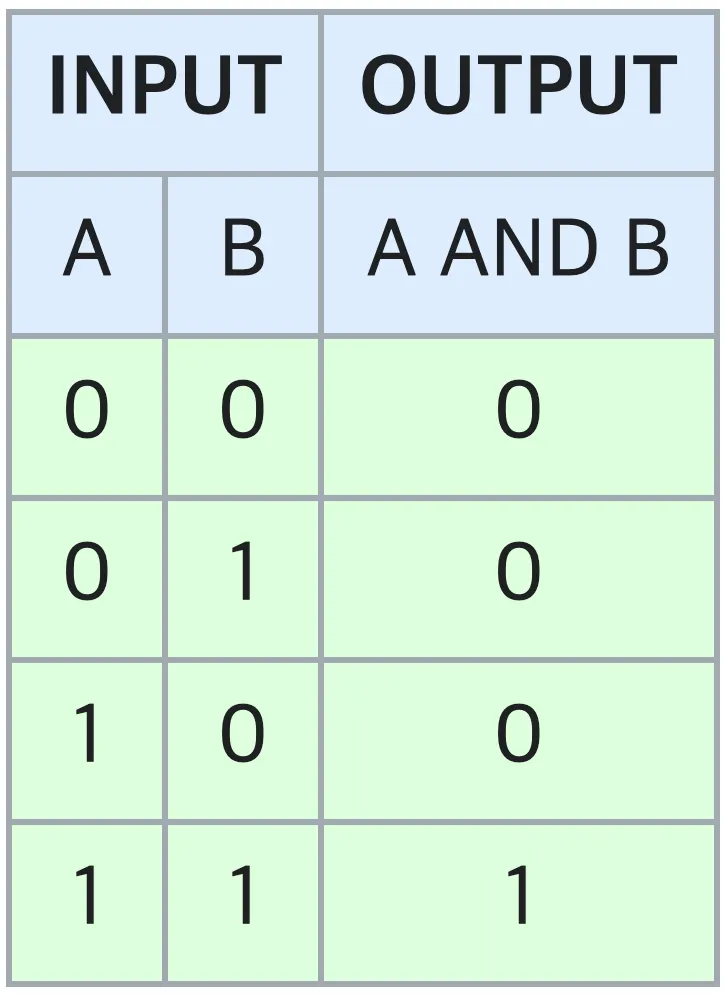
AND Gate 는 흔히 아는 논리곱 연산과 같습니다. 논리 타입 입력이 2개일 때, 두 입력 모두가 True(참, 1) 일 때만 결과를 True(참, 1) 으로 내며, 나머지 입력 조합에 대해서는 False(거짓, 0) 을 냅니다. 도표로 표현하면 다음과 같습니다.
학습의 목적을 달성하기 위해서는 일반적으로 cost function 을 설정하고, back propagation 을 합니다. 이 경우에는 binary classification 에 자주 사용되는 Binary Cross Entropy loss (BCE loss) 를 사용합니다.
BCE loss 는 위와 같은 식으로 나타낼 수 있습니다. 는 입력의 조합 (여기서는 (0, 0), (1, 0), (0, 1), (1, 1) 중 하나) 이며, 는 출력(여기서는 0, 1 중 하나) 입니다. 는 forward propagation 연산이라고 보시면 됩니다. 입력의 조합 를 넣어 나온 결과인 것입니다. 한 가지 언급드릴 사항이 있다면, activation function 까지 통과하여 나온 결과를 로 칭하고 있습니다.
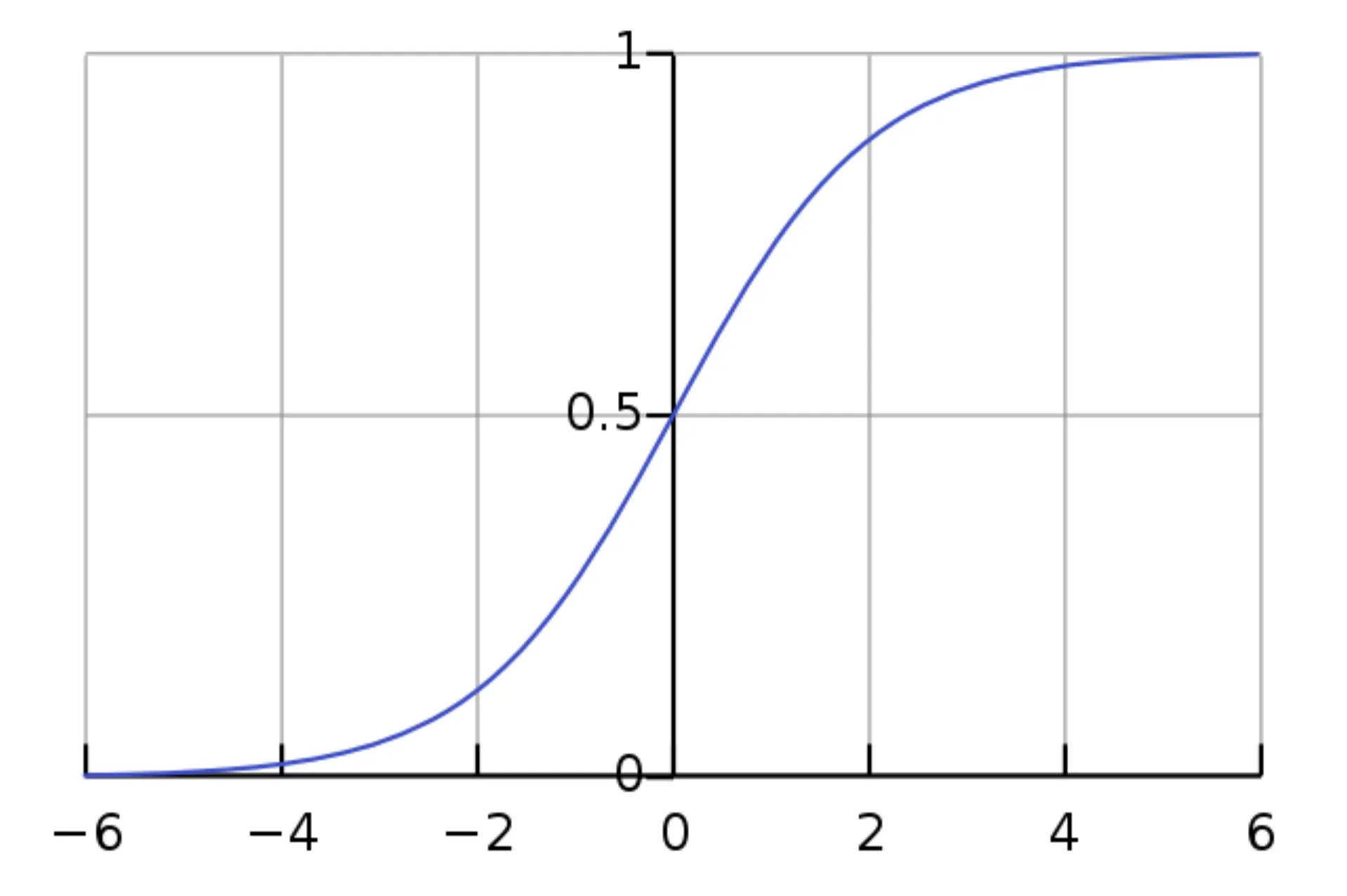
특히, BCE loss 는 sigmoid 라는 activation function 과 자주 쓰이는 경향이 있습니다. Sigmoid 는 아래와 같은 식으로 정의됩니다.
Sigmoid 의 그래프 형태는 다음과 같습니다. 가로 축이 이며, 세로 축이 입니다.
Activation function 을 포함한 결과를 로 칭한다는 것은 layer 의 뒤에 activation function 을 붙여준다는 말이며, 지금의 경우에는 perceptron(단층) 이기 때문에 perceptron 이 정의하는 연산 뒤에 마지막 연산으로 sigmoid 를 붙여준다고 보시면 됩니다.
이렇게 해서 원하는 것이 무엇일까요?
답은 BCE loss 를 최소화 하는 것입니다. Gradient descent 를 이용해서 cost function 을 최소화하는 방향으로 parameter 를 update 한다는 것은 들어보셨을 것입니다. 여기서는 BCE loss 가 cost function 이기 때문에 이를 최소화하는 것이 목적입니다.
자, 지금까지 학습의 목적성과 관련된 이야기를 해왔습니다. 어느정도 눈치채신 분들이 있으시겠지만 지금까지 학습이 될 parameter 에 대한 언급을 하지 않았었습니다. 그 이유는 "학습을 통해서 AND Gate 를 구현한다" 는 취지에 맞게 학습의 목적부터 언급을 드림으로서 지금부터 말씀드릴 학습을 위한 parameter 를 단순히 설정해 버리는 것과는 다른 개념임을 알려드리고 싶어서였습니다.
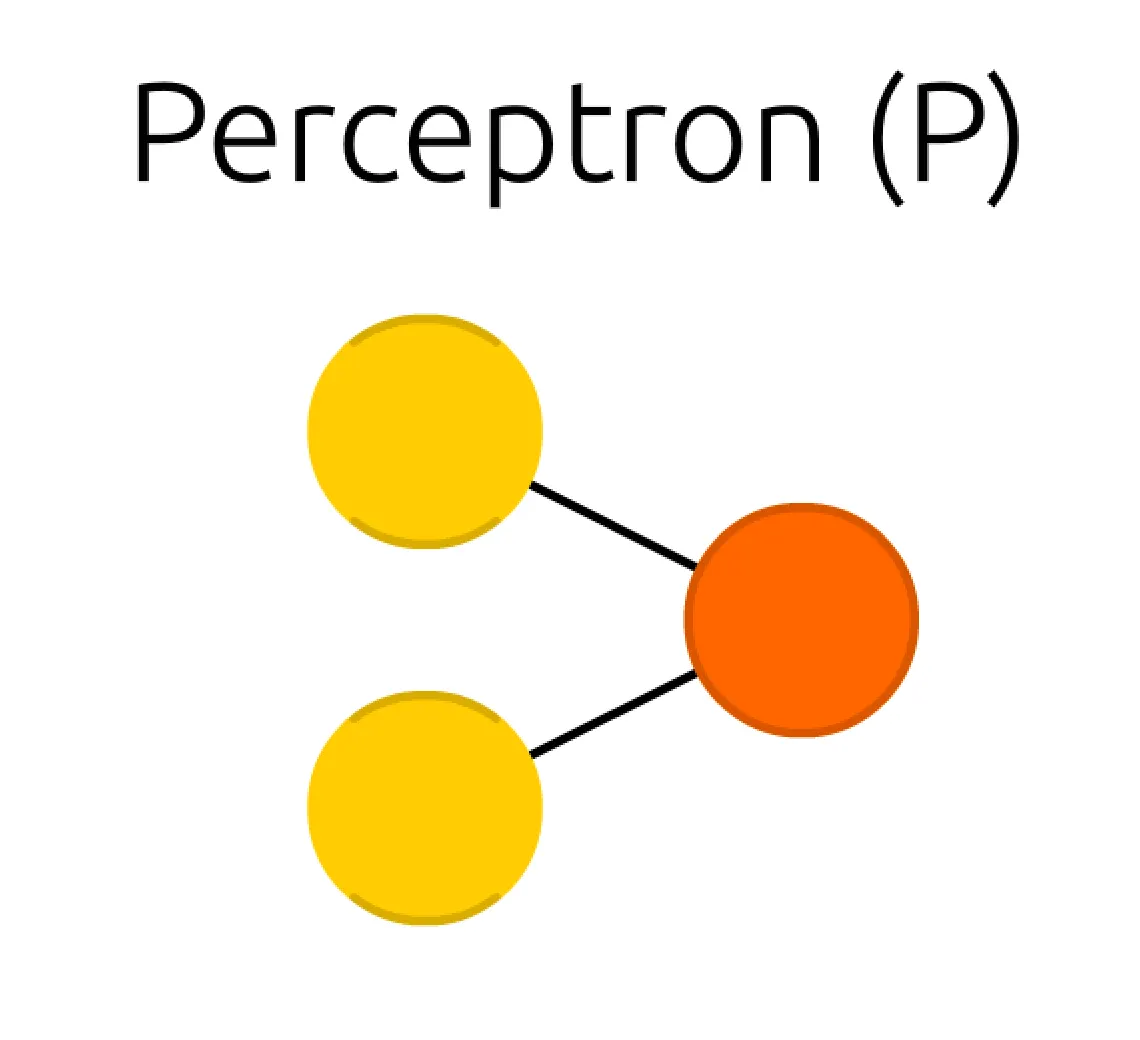
설명의 편의성을 위해 위의 그림을 다시 한 번 가져오겠습니다. 학습을 위한 parameter 는 perceptron 을 구성하는 원들 사이의 선입니다. 이 선 하나하나를 weight 라고 부르며, 곧 학습을 위한 parameter 입니다.
그럼 원은 무엇일까요?
좌측의 노란색 원은 두 개의 입력이고, 우측의 주황색 원은 한 개의 출력입니다. 이들은 본 세션을 포함하고 있는 ANN 글에 소개되어 있는 그림에서도 각각 Input Cell, Output Cell 이라고 표현되어 있는 친구입니다. 원들을 cell 말고 node 라고 부를 수도 있는데 무엇이든간에 원을 지칭하는 표현은 자주는 쓰지 않습니다.
그럼 원과 선의 관계는 무엇일까요?
단순합니다. Sum of Product, elementwise product 를 한 뒤에 더해준 것입니다. 위 선 두 개를 각각 위에서부터 , 라고 하고, 노란색 원 두 개를 각각 , 라고 한다면 주황색 원은 계산하기 위해 다음과 같이 계산할 수 있는 것입니다.
여기서 는 bias 로 parameter 만으로 풀리지 않는 linear regression 문제에서 넣어주는 항목이고, 이 경우에는 activation function 을 shifting 해줄 수 있는 효과가 있습니다. 이는 모델에 전체적으로 유동성을 부여할 수 있으며, 다양한 해가 가능하도록 만들어줄 수 있습니다. 이 부분은 밑에서 짧게 다시 소개해드겠습니다.
위의 식을 행렬곱으로 표현하면,
위와 같이 나타낼 수 있고, 일반적으로 다음과 같이 표현합니다.
그리고 한 가지 덧붙여서, 여기에 activation function 인 sigmoid 까지 붙이게 된다면, 최종적인 결과가 나옵니다.
그리고, 이 결과로 나온 값들을, 보통의 경우에는 하나의 입력을 모델에 넣어 나온 가설이라고 하여 hypothesis, 혹은 라고 많이 지칭합니다. 그리고 눈치채셨겠지만, 이 가 이전에 설명한 BCE loss 에 들어갈 값입니다. 수식으로 표현하면 아래와 같습니다.
위 수식은 머신러닝을 배우면서도 꽤나 많이 등장할 것이니 알아두시면 도움이 많이 됩니다.
지금까지, 학습의 목적성과 학습을 위한 parameter 를 비롯하여 perceptron 을 구성하고 있는 요소에 대해서 알아보았습니다. 그런데, 사실 중요한 부분을 생략했습니다.
"왜 cost function 을 BCE loss 로 설정하고 gradient descent 로 학습을 위한 parameter 를 update 를 하면 원하는 결과에 도달할 수 있는가" 에 대한 내용을 말씀드리지 않았습니다.
다시 BCE loss 를 가져왔습니다. 에 관한 내용은 앞서 설명드린대로, activation function 까지 거친 최종 결과입니다. Sigmoid 를 사용했기 때문에, 값은 0 과 1 사이의 값이며, 입력 의 값이 0 이상이냐 0 이하냐에 따라서 값이 0.5 에서 나뉘어집니다.
위 BCE loss 를 설계할 때부터 사실 이런 생각을 가지고 있던 것입니다.

" 값이 0.5 보다 크면, 모델은 True(참, 1) 을 산출하도록 설정하고, 값이 0.5 보다 작으면 모델이 False(거짓, 0) 을 산출하도록 설정해야겠다"
이 말은 즉슨, 의 값이 0 초과면 True(참, 1) 를, 의 값이 0 미만이면 False(거짓, 0) 을 산출하도록 설정했다는 것입니다. 그러면, 이제 확인해야 할 것은 실제로 설계한 cost function 이 위와 같은 설계를 따르도록 설정되었는가! 입니다. Loss 를 최소화하는 것이 무슨 의미를 가지는가에 대해서 살펴보면 이는 상당히 간단합니다.
BCE loss 를 최소화한다는 것은 각각의 에 대해서 다음 항목을 최대화하는 것과 같습니다. 물론, 가 독립적이고 dataset 이 편향되지 않았다는 가정 하에서 가능한 이야기입니다.
위 식은 가 1 일 때와 0 일 때로 나누어서 살펴볼 수 있습니다.
먼저 가 1 일 때 뒤쪽 항은 0이 되어 사라집니다. 그리고 앞쪽의 만 남게 됩니다. 그리고 가 1 이라고 했으니 이는 곧 랑 같게 됩니다. 이를 최대화하는 것은 를 최대화 하는 것과 같습니다.
그런데, 앞에서 " 값이 0.5 보다 크면, 모델은 True(참, 1) 을 산출하도록 설정하고" 라고 말한 적이 있습니다. 이 목적을 달성하기 위해서 모델은, 가 1 일 때 를 최대화하도록 모델을 update 하는 것입니다. 가 1 인 다양한 입력들에 대해서 가 충분히 커져 0.5 를 넘는 경우들이 많아지다보면 모델의 정확성이 높아지는 것입니다.
다음으로 가 0 일 때 앞쪽 항은 0이 되어 사라집니다. 그리고 뒤쪽의 만 남게 됩니다. 그리고 가 0 이라고 했으니 이는 곧 랑 같게 됩니다. 이를 최대화하는 것은 를 최소화 하는 것과 같습니다.
그런데, 앞에서 " 값이 0.5 보다 작으면, 모델은 False(거짓, 0) 을 산출하도록 설정하고" 라고 말한 적이 있습니다. 이 목적을 달성하기 위해서 모델은, 가 0 일 때 를 최소화하도록 모델을 update 하는 것입니다. 가 0 인 다양한 입력들에 대해서 가 충분히 작아져 0.5 를 작은 경우들이 많아지다보면 모델의 정확성이 높아지는 것입니다.
사실 이렇게 설명을 했지만, 한 줄로 요약해서 정리하면 다음과 같습니다.
나와야 하는 결과가 1 인 경우에는 결과를 크게 만들고 싶고 나와야 하는 결과가 0 인 경우에는 결과를 작게 만들고 싶었기 때문에 이를 이분법적으로 분리할 수 있는 cost function 을 설계한 것이고 그게 BCE loss 인 것입니다.
이제 정리가 좀 되셨나요?
마지막으로, 학습 이후에 정해질 , , 에 대해서 한 번 살펴보려고 합니다. 앞서 의 값이 0 초과면 True(참, 1) 를, 의 값이 0 미만이면 False(거짓, 0) 을 산출하도록 설정했다고 했었습니다. 이 말은 값이 0 초과인지 0 미만인지에 따라서 산출 값을 달리한다는 뜻입니다.
그렇다면 구분선이 될 수 있는 은 어떤 모습일까요?
위 식을 변경하면,
형태가 되는 것을 알 수 있습니다. 그리고, AND Gate 를 만족하는 , , 를 0.5, 0.5, -0.75 정도로 설정해보면, 식은 임을 알 수 있습니다. 이를 그래프로 그려본다면, 아래와 같게 나오게 됩니다.
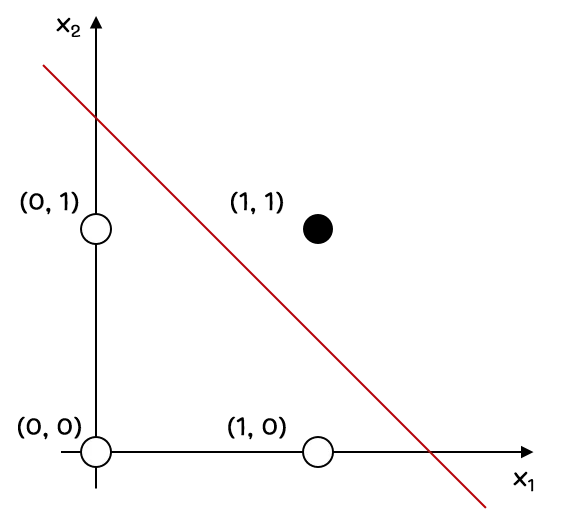
선의 위쪽, 즉 0보다 큰 경우는 산출 값이 True(참, 1) 인 영역이고, 0보다 작은 경우는 산출 값이 False(거짓, 0) 인 영역으로 보시면 됩니다. 어느정도 예상하셨겠지만, (1, 1) 입력의 경우와 그렇지 않은 경우를 선으로 정확히 이등분하고 있습니다. 애초에 목표 자체가 이를 이등분할 수 있는 선의 식을 구하는 것입니다. (정확히 말하자면, 선의 식을 구성하는 parameter 들을 학습하는 것입니다.)
이렇게 이번 세션에서는 인공신경망을 이루는 가장 작은 단위, perceptron 의 구조와 예시에 대해서 알아보는 시간을 가졌습니다. 이번 세션을 통해서 perceptron 이 인공신경망을 이루는 가장 작은 단위이며, 실제로 이 또한 학습을 위한 요소로 활용될 수 있다는 점을 알아가셨으면 합니다 !!