본 포스트에서는 확률론적인 방법으로 3D Scene 과 Egocentric View 에 기반하여 Human Mesh 를 복원하는 연구를 진행한 논문에 대해서 소개드리려고 합니다.
Project Page 및 논문을 직접 읽어보시고 싶으신 분들은 위 링크를 참고하시면 좋습니다.

Objective
AR 및 VR 애플리케이션의 빠른 발전에 힘입어 Head MountedDevices (HMD) 를 통해 보이는 상호작용 대상의 행동을 이해하는 것이 점차 중요해지고 있습니다. 특히, HMD 를 통해서 본인과 가까이서 상호작용하는 인간을 보게 되면 신체의 일부분만 보이게 되고, 전체적인 행동을 볼 수 없습니다. 이러한 상황에서 상대방의 자세를 예측하는 것은 어려운 일입니다.

EgoHMR
이러한 시나리오에서는 FrankMocap 과 같이 단일 이미지에서 Human Mesh 를 뽑아내는 연구들과는 달리, 인간의 신체가 가려져 있음에도 그럴듯한 Human Mesh 를 복원해야 합니다. 때문에 논문에서는 인간이 점유하고 있는 공간 주변의 3D Scene 이 자세에 대한 정보를 포함하고 있음에 착안하여 이를 활용해 Human Pose 에 대한 확률 분포를 학습하는 것으로 자연스럽고, 그럴듯한 다양한 자세를 만들어내는 시도를 합니다.
Method
논문에서는 신체의 일부분만 보이는 상대방에 대한 이미지를 Egocentric Image 로 칭합니다. 본래 1인칭 시점의 이미지라는 의미이지만, 이후에서 설명할 때는 논문의 이러한 양식을 따라서 설명을 진행하려고 합니다.
논문에서 다루고자 하는 문제의 formulation 은 다음과 같습니다.
1.
Input
•
Egocentric Image 와 그에 해당하는 intrinsic parameters
•
3D Scene Point Cloud
2.
Output
•
Plausible 한 Human Mesh SMPL parameters
위 formulation 의 과정을 구현하기 위해서 논문에서는 다음과 같은 pipeline 을 구성합니다.
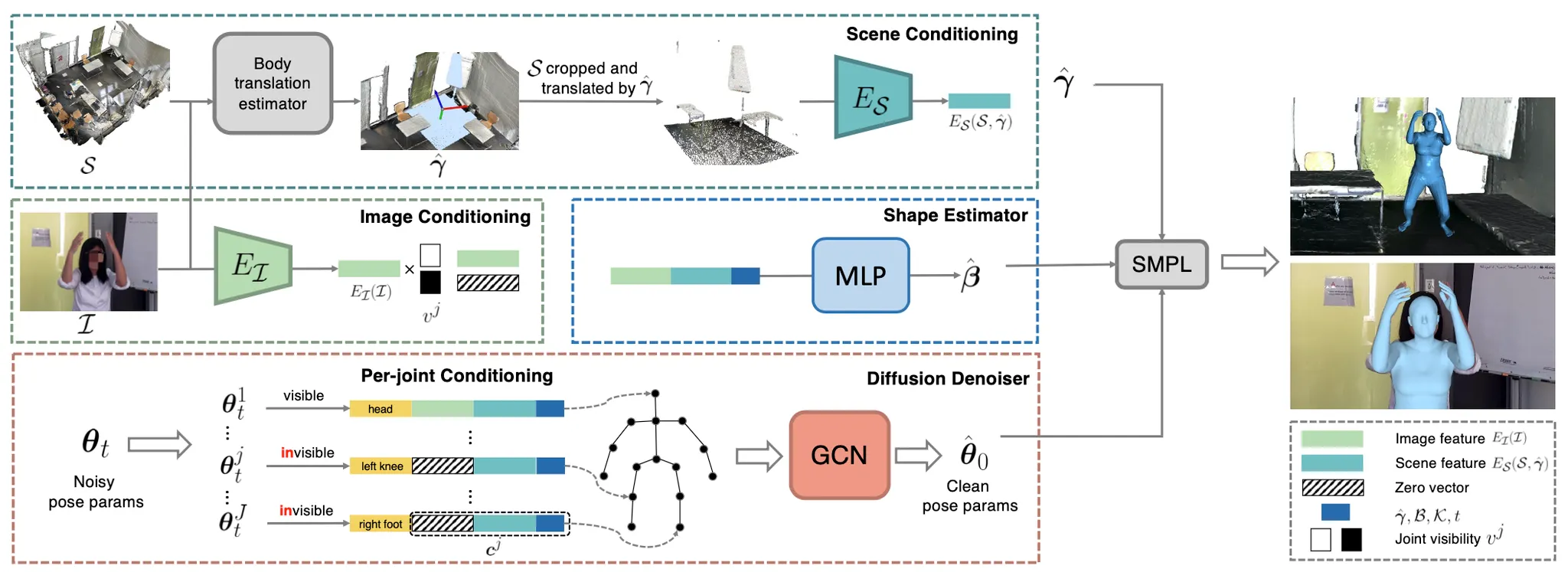
EgoHMR: Overall Pipeline
EgoHMR 의 과정을 간략히 요약하자면, 첫 번째 행 청록색 점선으로 감싸져 있는 부분과 두 번째 행 좌측 초록색 점선으로 감싸져 있는 부분은 Diffusion Model 의 Conditioning 을 담당하는 부분이고 부가적으로 해당 과정에서 Human Mesh 의 translation 을 산출합니다. 이러한 conditioning 을 바탕으로 세 번째 행 붉은색 점선으로 감싸져 있는 부분에서 SMPL pose parameter 를 예측하는 Diffusion 모델을 학습하게 됩니다. 두 번째 행 우측 푸른색 점선으로 감싸져 있는 부분은 Diffusion Model 과 별개로 SMPL shape parameter 를 estimate 하는 부분입니다. 이렇게 산출해낸 SMPL 의 translation, shape, pose 를 조합해 최종적으로 plausible 한 위치, 크기, 자세의 Human Mesh 를 복원할 수 있게 됩니다. 다음은 각각에 대한 구체적인 설명입니다.
Scene-Conditioned Pose Diffusion Model
3D Scene Conditioning
가장 먼저 소개드릴 것은 3D Scene 에 대한 정보를 SMPL pose parameter 를 예측하는 Diffusion Model 의 condition 으로 사용할 수 있도록 vectorize 하는 과정입니다.

3D Scene Conditioning
가장 먼저 3D Scene Point Cloud 와 Egocentric Image 를 입력으로 하여 Human Mesh 의 3차원적 위치 벡터 를 찾는 과정을 진행합니다. 이 때 사용하는 네트워크를 Body Translation Estimator 라고 칭하는데, 이는 Appendix 에 따르면 ProHMR 의 기본 baseline 에서 약간의 변형을 가한 것이며, 논문 저자들의 이전 논문이었던 EgoBody 데이터셋으로 학습한 네트워크입니다.
이렇게 성공적으로 Human Mesh Translation 을 예측했다면, 이를 기반으로 3D Scene Point Cloud 를 cropping 하는 과정을 진행합니다. 이는 해당 translation 과 가까운 points 들을 선택한 것으로, 이후 이 점들은 ProHMR 에서 사용한 Scene Encoder 를 통해 Human-Centric Scene Feature 로 vectorize 되게 됩니다. 다만 이 Scene Encoder 의 학습이나 기원에 대해서 설명해주는 부분이 없는데, pretrained Point Cloud encoder 들 중 하나를 사용하거나 scene reconstruction task 를 통해 학습했을 것으로 보입니다.
Per-Joint Conditioning
다음으로 소개드릴 것은 2D 이미지에 대한 정보를 SMPL Pose Parameter 를 예측하는 Diffusion Model 의 condition 으로 사용할 수 있도록 vectorize 하는 과정입니다
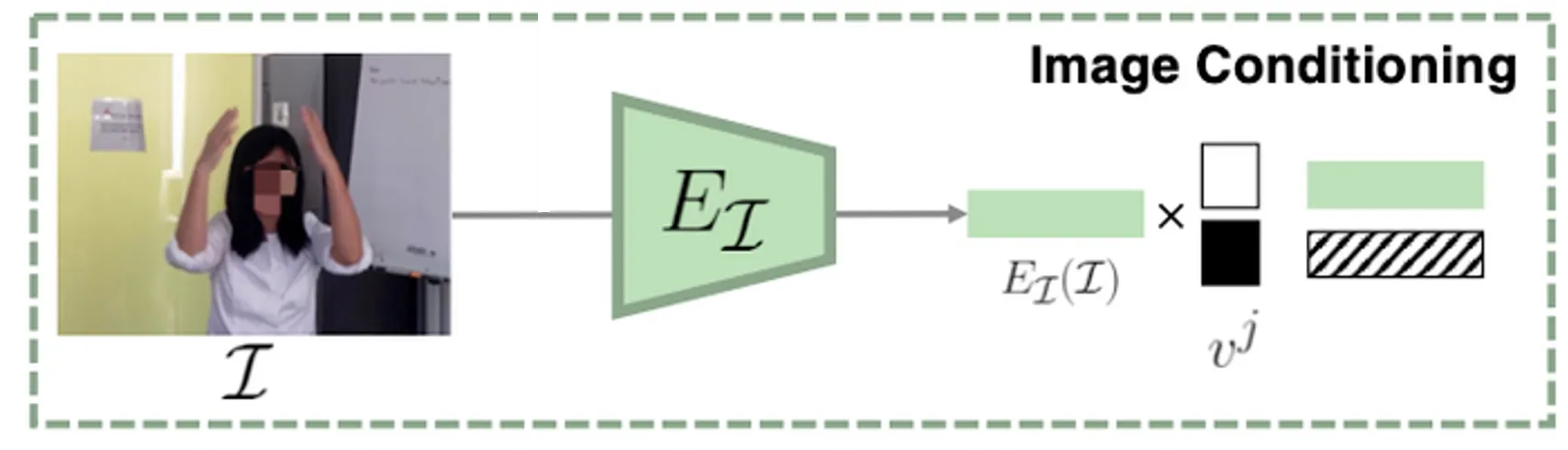
Per-Joint Conditioning
위 그림은 Egocentric Image 를 입력으로 받아 feature 를 산출하는 과정입니다. ResNet50 의 backbone 을 사용한 이 네트워크는 ProHMR 에서 pretrained 된 네트워크를 가져온 것이며, 크기의 벡터를 산출합니다.
이후에 설명드릴 Diffusion Model 이 각 SMPL Human Joint 에 대한 입력을 가지는데, 이 단계에서 joint 에 따라서 다르게 image conditioning 을 진행합니다. Egocentric Image 에서 관측되는 joint 의 경우에는 해당 이미지의 feature 를 사용하고, 그렇지 않은 경우에는 0 을 사용하여 각 joint 마다 에 대한 condition 을 지정합니다. 이를 2D joint visibility mask 로 결정해두고 multiply 하는 형태로 표현한 것입니다.
Additional Conditioning
부가적으로 논문에서는 Bounding Box 에 대한 정보도 이후에 설명드릴 Diffusion Model 의 condition 으로 사용할 수 있도록 하는데, 자세한 설명이 나와 있지 않아 논문에서 참고한 CLIFF 논문을 본 결과, 에서 human region 에 대한 정보를 주는 것으로 해석할 수 있었습니다.
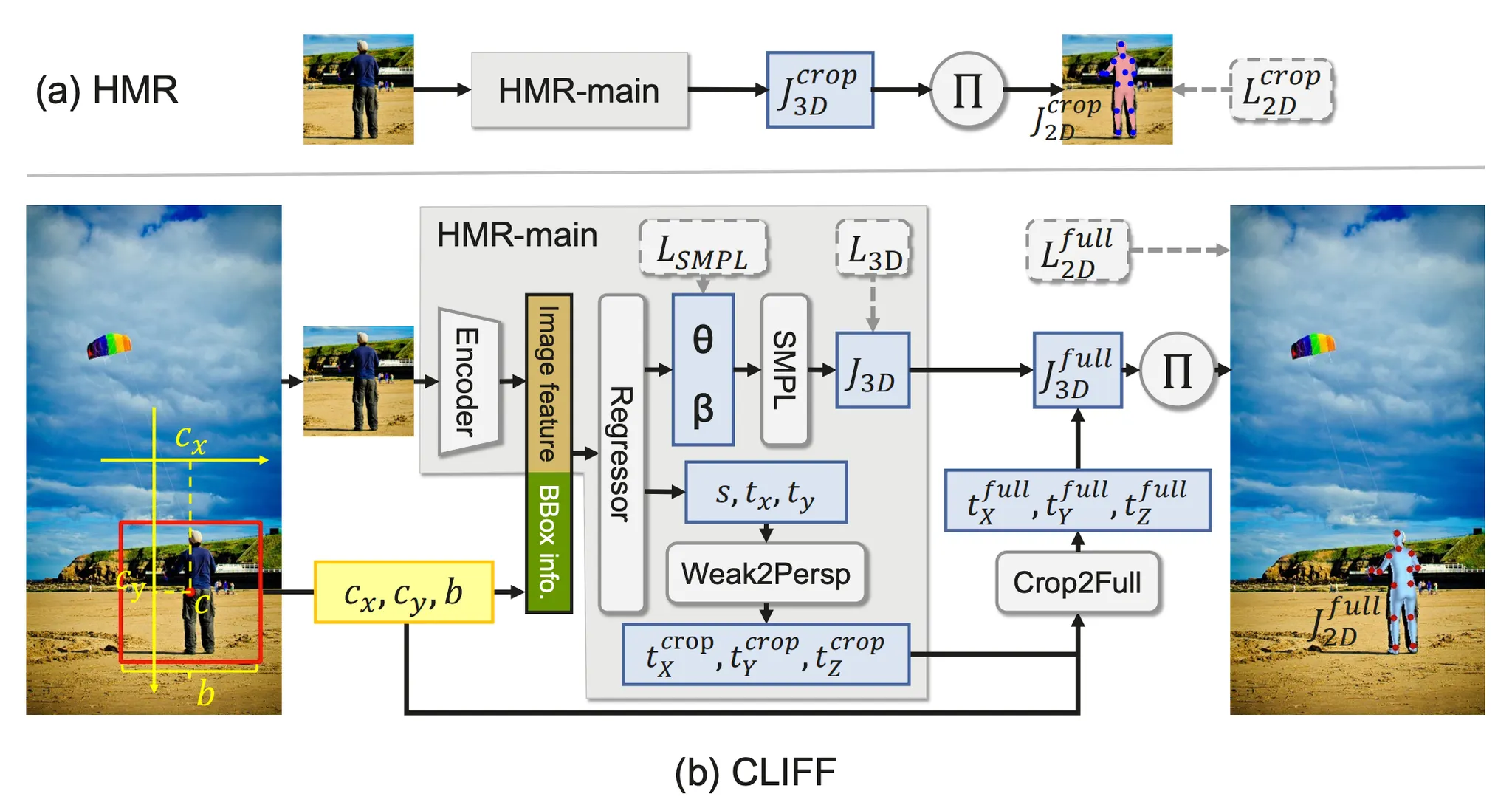
CLIFF
CLIFF 논문에서는 전체 이미지에서 human 의 위치 정보가 3D Human Pose 와 Shape Estimation 에 영향을 줄 수 있음을 시사하면서 Global Location Aware Information 의 부재가 SMPL 의 pose parameter 를 예측하는데 어려움을 줄 수 있다고 이야기 합니다.
때문에 논문에서는 위와 같은 형태의 bounding box 에 대한 정보도 각각의 joint 가 가질 condition 으로 포함시켜서 Diffusion Model 을 학습하게 됩니다. 최종적으로는 joint 에 대해서 다음과 같은 conditioning 이 이루어진다고 볼 수 있습니다.
Diffusion Denoiser Architecture
논문에서 가장 핵심적이라고 볼 수 이는 부분은 SMPL 의 pose parameter 를 확률론적으로 예측할 수 있는 부분입니다. 이를 위해서 Graph Convolution Network 에 기반한 Diffusion Model 을 사용했고, 각각의 Node (여기서는 joint) 에 대한 condition 으로 앞에 설명한 요소들이 들어가게 되며, 학습 단계에서 입력 및 출력으로는 SMPL pose parameter 입니다.
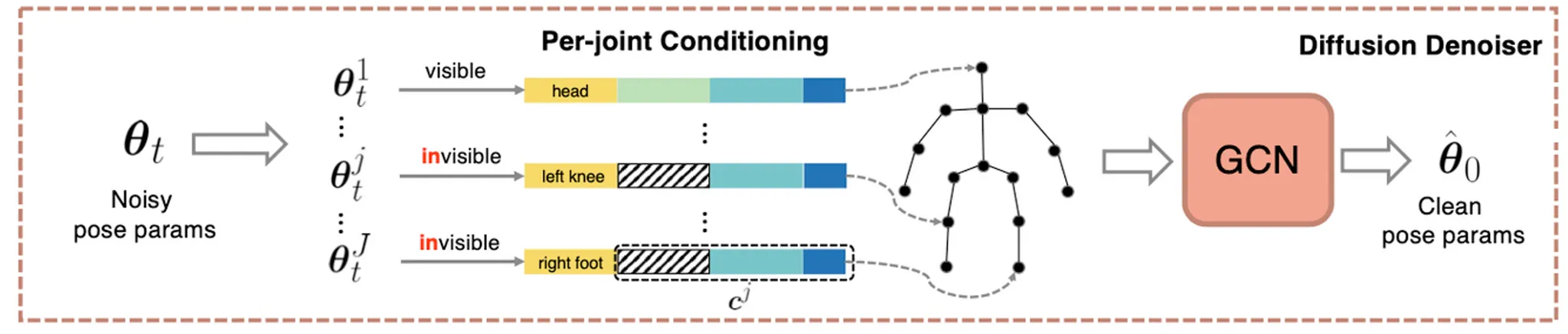
Diffusion Denoiser
위 그림과 같이 각각의 SMPL pose parameter 에 대해서 noise 를 추가한 뒤에, Per-Joint Conditioning 을 할당하여 Graph 를 완성한 뒤, GCN 을 통과시켜 denoised 된 pose parameter 를 예측하도록 하는 구조입니다. 기본적인 Diffusion Model 과 동일하게 sampling 된 timestep 에 대해서 이와 같이 학습을 진행한다고 볼 수 있습니다.
Shape Estimator
앞서는 SMPL 의 pose parameter 를 예측하는 과정에 대해서 설명이었다면, 논문에서는 SMPL 의 shape parameter 를 예측하는 과정도 있어야 합니다.
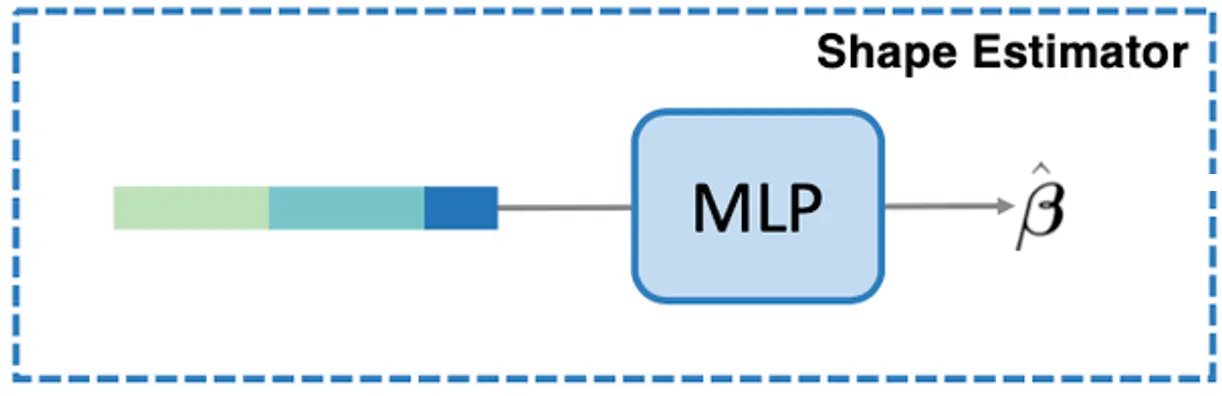
Shape Estimator
이는 간단하게 앞선 conditioning (Visibiliy Mask 에 대한 고려 없이 모든 condition 을 사용) 을 입력으로 하여 MLP 기반 regressor 네트워크를 통해서 학습을 진행합니다. SMPL pose parameter 는 Diffusion Model 을 통해 probabilistic 하게 (seed 에 따라 다른) 값을 산출된다면, SMPL shape parameter 는 MLP 를 통해 deterministic 하게 값이 산출됩니다.
Scene-Guided Sampling
앞서 학습한 Diffusion Model 의 inference 는 일반적인 DDPM 의 sampler 와 동일합니다. 특정 timestep 에 대해 각 GCN denoiser 는 를 예측하게 되고 이를 이용해 한 단계 noise 가 제거된 pose parameter 인 을 sampling 해낼 수 있게 됩니다.
이를 부터 까지 반복하여 최종적으로 noise 로부터 pose parameter 를 생성해낼 수 있게 되는 것입니다.
Classifier-Free Guidance
여타 다른 Diffusion Model 과 동일하게 논문에서도 Classifier-Free Guidance 를 training 및 inference 에서 활용합니다. 5% 의 확률로 모든 joint 에서의 image feature 를 지움으로써 모델이 이미지에만 의존하지 않게끔 학습을 진행합니다.
다만, 약간 특이한 점은 위 수식에서 처럼 모든 joint 에서의 image feature 를 제외하여 산출한 에서 visible 하지 않은 joint 의 값만 사용하고, 기존 conditioning 이 포함되어 산출한 에서는 visible 한 joint 의 값만 사용하는 형태로 이를 정의합니다. 아마 이미지에 포함되지 않은 joint 의 경우 joint 에 conditioning 을 주지 않았음에도 어느정도 이미지의 영향을 받았는지 아예 제외한 estimation 이 조금 더 좋았다고 판단하지 않았나 싶습니다.
Collision Score Guided Sampling
앞선 설계를 바탕으로 Human Mesh 를 복원할 수 있지만, 가장 치명적이었던 것은 기존 scene 과 복원한 Human Mesh 의 충돌이었습니다. 논문에서는 이러한 충돌을 최소화하기 위해서 COAP 에서 제안한 Neural Articulated Occupancy 를 예측하는 pretrained 된 네트워크 를 사용합니다.
COAP 는 를 query point 의 위치, 를 SMPL 의 parameters 로 하여, query point 가 얼마나 Human Mesh 내부에 occupied 되어있는지를 예측할 수 있습니다. 이를 이용해 다음과 같은 Collision Score 를 정의할 수 있습니다.
이는 3D Scene Point Cloud 를 구성하는 각 point 들에 대해서 Human Mesh 내부에 있다고 판단되는 점들에 대해서 그 정도를 sigmoid 를 씌워 summation 한 형태로 볼 수 있고, 이를 최소화하는 방향으로 pose parameter 를 optimize 하려고 했다고 볼 수 있습니다. 때문에 이의 gradient 를 직접적으로 Diffusion Sampling 과정에 더해 다음과 같이 변형합니다. 정성적으로는 매 sampling 마다 미리 학습된, plausible 한 distribution 이 높은 쪽 뿐만이 아니라, 충돌을 최소화하는 방향으로도 sampling 방향성을 조정한다고 볼 수 있습니다.
Training Objectives
앞서 설명드린 구성을 종합하여 논문에서는 총 5가지의 loss 를 구성합니다.
위 세 가지 loss 는 각각 3D Joint Loss, 2D Keypoint Re-Projection Loss, 그리고 Shape Loss 로 EgoBody 가 제공하는 ground truth 와의 차이를 기반으로 정의됩니다. 는 SMPL Joint Regressor 이고, 는 camera intrinsic 를 가지는 camera pose 에 대한 3D to 2D projection 입니다.
여기에다가 generated 6D pose rotation 이 orthonormal 하게 만들기 위한 orthonormal loss, 앞선 collision 및 기본적인 diffusion 학습 loss 가 포함되어 최종적으로 다음과 같이 loss 가 구성됩니다.
Experiments
Results
논문에서는 ground truth 와의 Mean Per-Joint Position Error (MPJPE), Vertex-to-Vertex Error (V2V) 를 사용하여 방법론을 평가합니다. 이 때 MPJPE 는 다양한 종류로 나누어서 평가를 진행하는데 G-MPJPE 는 global coordinate 에서의 joint error 를, 그냥 MPJPE 는 pelvis aligned SMPL 에서의 joint error 를, PA-MPJPE 는 Generalized procrustes analysis 논문에서 제안한 Procrutstes Alignment 에서의 joint error 를 나타냅니다.
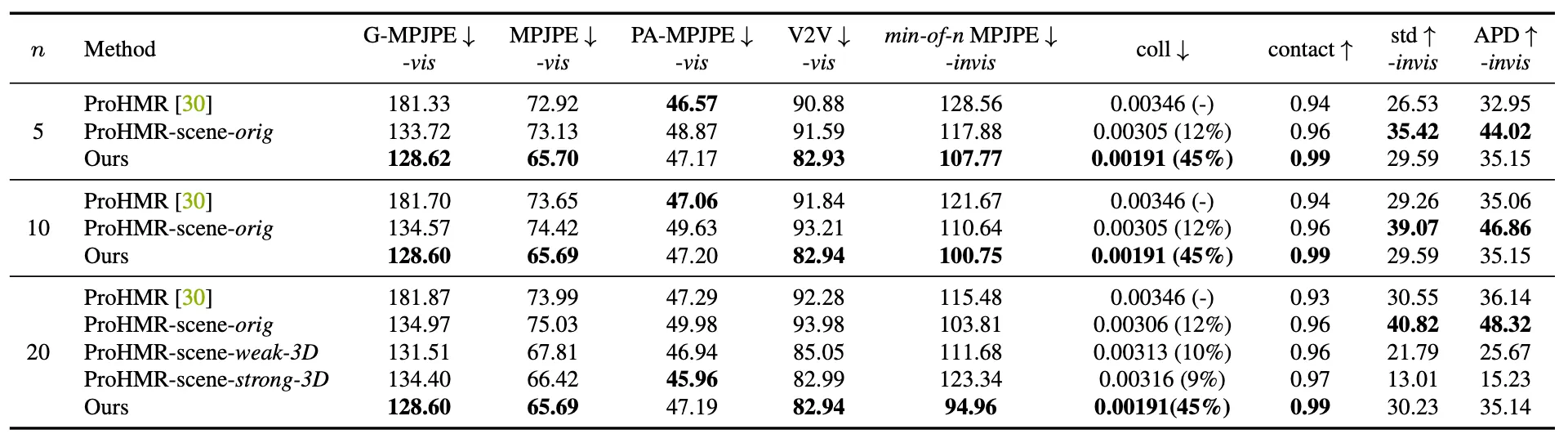
Quantitative Results
위 그림은 논문에서 그들의 baseline 과의 비교를 나타낸 것입니다. 논문의 방법론이 G-MPJPE, MPJPE, 그리고 V2V 의 visible joint 에서 가장 좋은 수치를 보였고 이로부터 보여진 joint 와 body shape 을 정확하게 예측할 수 있는 능력이 뛰어남을 알 수 있었습니다. 또한 invisible joint 에서 가장 좋은 min-of-n MPJPE 값을 보였고 이로부터 논문의 방법론이 가려진 신체 부분으로부터 원래를 복원하는 능력 또한 뛰어남을 알 수 있습니다.
또한 논문에서는 다른 방법론들보다 contact ratio 가 높았는데, 실제로 ProHMR 에 비하면 collision 이 45% 가 줄었고, ProHMR-scene 에 비하면 collision 이 37% 정도가 줄었습니다. 이는 신체와 3D 환경과의 더 나은 관계성을 구현했다고 볼 수 있었습니다.

Qualtitative Results

Multiple Samples
이러한 특징은 위의 qualitative results 에서도 잘 볼 수 있는데, 이전의 baseline 들이 붉은색 점선 영역에서 3D 환경을 침투하여 충돌을 발생시키는 것과 달리 논문의 방법론에서는 그러한 현상들이 발생하지 않음을 살펴볼 수 있습니다.
Ablation Study
논문에서는 그들이 설계한 세부적인 방법론이 유의미함을 보이기 위해서 Ablation Study 를 진행합니다.

Ablation Study (Quantitative)
위 표에 따르면, 논문에서 제시한 collision score based sampling 과정에 포함되는 과 collision loss 가 모두 coliision 발생을 유의미하게 줄였음을 확인할 수 있었습니다. 또한 Classifier-Free-Guidance 의 사용으로 invisible point 에 대한 예측은 unconditional 하게 진행한 것이 diversity 에 큰 도움이 되었다는 것을 확인할 수 있었습니다.

Ablation Study (Qualitative)
논문에서는 에 대한 효과를 qualitative 하게도 제공합니다. 붉은색 점선으로 표시된 영역처럼 3D 환경과 충돌이 났던 것도 해당 score 를 기반으로 sampling 하니 해결된 모습을 살펴볼 수 있었습니다.
Conclusion
이것으로 논문 “Probabilistic Human Mesh Recovery in 3D Scenes from Egocentric Views” 의 내용을 간단하게 요약해보았습니다.
이 논문은 3D Scene Graph 기반의 논문들을 찾으려는 시도를 통해서 찾게된 논문이었는데, 생각보다 범용적으로 쓰일만한 기술들이 있어서 재미있었던 것 같습니다. 특히나 Scene 에 대한 정보를 conditioning 하는 방법과 collision 에 대한 대응은 매우 흥미롭게 느낄만한 부분이었습니다.
개인적으로는 굉장히 impressive 한 논문이라고 생각하나, 논문이 세상에 나온지 별로 안되서 (2023년 4월) 아직 인용수가 없는 것으로 보여서 아쉬웠던 것 같습니다. 특히 제 관심분야랑 어느정도 align 되어 있어서 더 흥미롭게 읽을 수 있었던 것 같은데, 최근 읽은 논문 중에서는 가장 얻어갈 것이 많은 논문이 아니었나 싶습니다.
총평으로는, 이 논문은 3D Scene Conditioning, Human Mesh Recovery 에 관심이 있으신 분들은 읽으시는 것을 강하게 추천드려 보고 그냥 3D Vision 에 관심이 있다 하시는 분들도 가볍게 한 번 보시는 것을 추천드리고 싶습니다.