
2D Human Pose Estimation
•
Inout: 2D RGB Image, Output: 2D Keypoints
◦
개의 keypoints 들을 정의하면, output 은 matrix 임 ( coorcinate)
•
인간은 다양한 pose 를 가지기 때문에 challenging 한 문제임.
Template Matching - An Early Approach
•
많은 templates 들을 준비하여, 해당 template 와 이미지의 특정 부분이 matching 되는지를 확인하여 pose 를 알아내는 방법론
•
Scale changes 나 rotation 을 고려해야 하고, 많은 template 들을 준비해야 하며, 좋은 matching 확인 방법을 만들어야 하기 때문에 어려운 방법임.
Idea: Detecting Each Pary by a Local Patch

•
Human 의 각 특징점들을 나누어서 찾을 수 있음.
•
하지만, 단순한 방법으로는 잘못된 matching 이 발생할 수 있고 이를 해결하기 위해서 human 이 일반적으로 가지는 spatial arrangement 에 기반하여 이런 mismatching 을 해결할 수 있음.
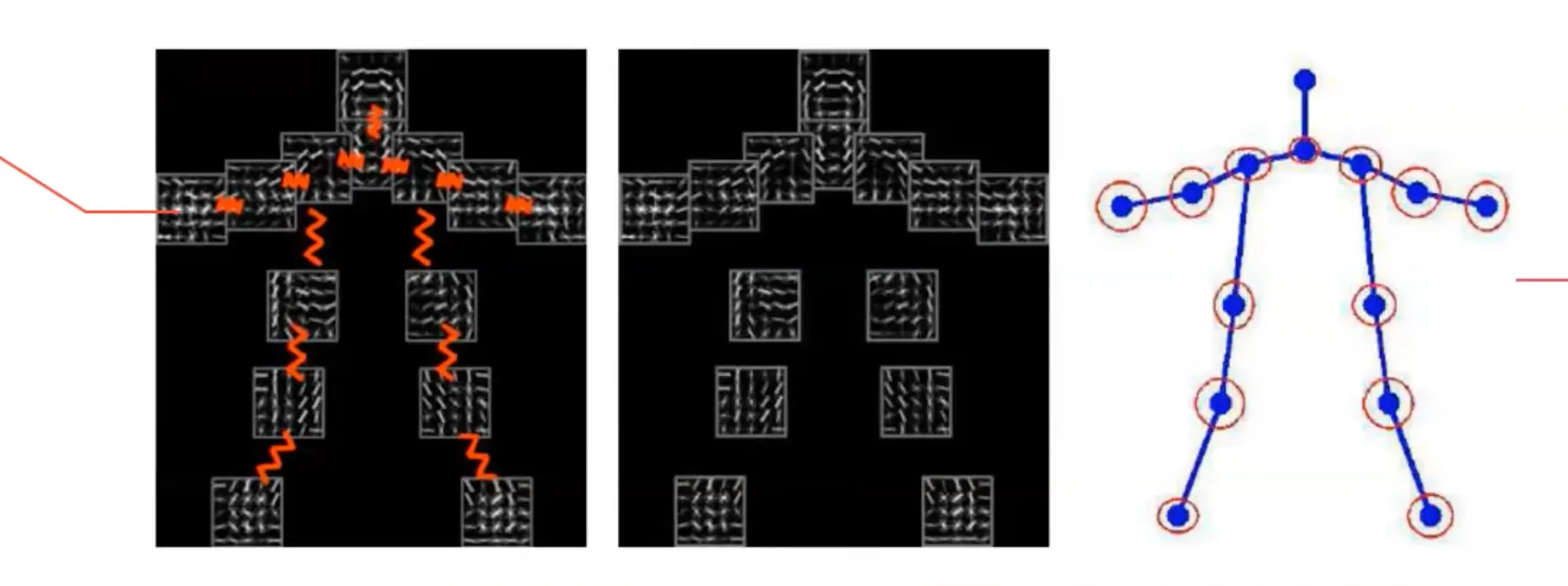
Pictorial Structure Models

•
Local Part 에 대한 pattern matching 을 하면서 human 의 configuration 을 (flexibility 를 어느정도 가지면서) 따르는 구조를 강제하고 싶어 만들어진 모델
•
좋은 예시로 Deformable Part Model (DPM) 이 있음.

◦
Local pattern 과 pattern 간의 pairwise relation 을 정의하고 이 pattern relation 을 잘 만족하면서도 local detail 에 잘 match 되는 구조를 찾는 방법론
•
다음과 같은 수식으로 최적화된 local patch 의 matching 의 위치를 찾음.
◦
일반적으로 structure, edge 에 집중하기 위해서 이미지에서 color term 을 다 날리고 시작함.
◦
위치에 있는 local image 의 HoG Feature:
◦
Human local part 에 대한 Unary Template:
◦
앞 항은 local matching, 뒷 항은 Human Configuration (tree structure) 에 대한 항목임.
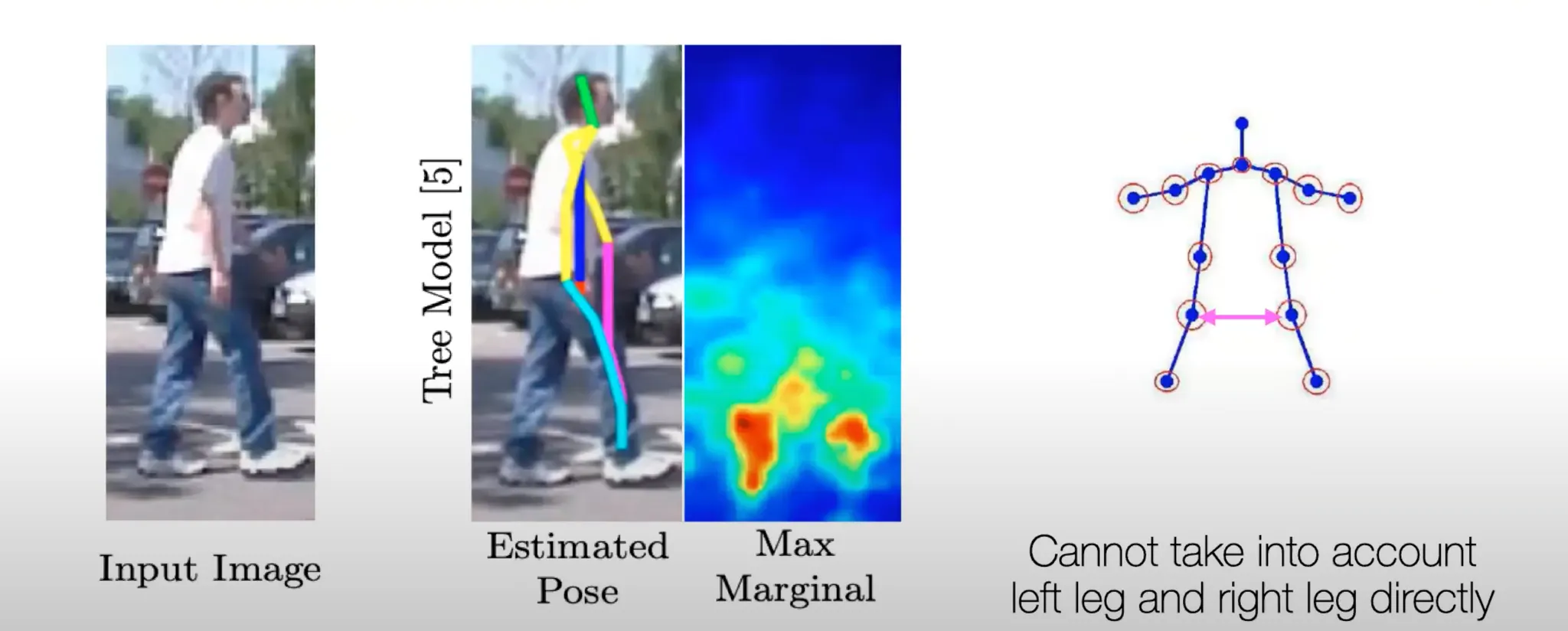
Limitation of “Classic” (Hand-designed) Approaches
•
Double Counting Issue
◦
일반적인 Tree Structure Model 로는 좌측 다리와 우측 다리를 구분할 수 있는 능력이 없음.
◦
딥러닝의 필요성이 대두되고 변화가 시작됨.
DeepPose

•
Input: Image, Output: Coordinate of Each Joint
•
딥러닝 기반 방법론이기에 Feature 와 Structure, Spatial Relation 에 대해서 엔지니어가 고민할 필요가 없음.
•
이러한 방법론이 가능했던 이유는 Large Scale Datasets 가 등장하고 사용 가능해졌기 때문임.
◦
MPII (2014): 25K Images from 40K people
◦
COCO (2017): 79K Trainging Images, 13K Validation Images (Multi-Person)
◦
COCO-WholeBody (2020): 250K Humans, Body + Hand + Face (133 keypoints)
•
전체 이미지를 통해 처음 keypoint 의 coorinate 를, 그 주변을 다시 한 번 통과시켜 keypoint 의 보정된 위치를 찾는 식으로 정확한 keypoint 를 찾아감.
•
기존에는 output 이 regression 을 통해 얻어낸 2D coordinate 였는데, coordinate 는 origin 이 필요함. Stage 가 거듭되면서 Input 의 범위가 달라지면서 coordinate 의 origin 이 달라지는 문제가 생김. → 학습이 어렵고 CNN 기반이 아니라서 별로였음.
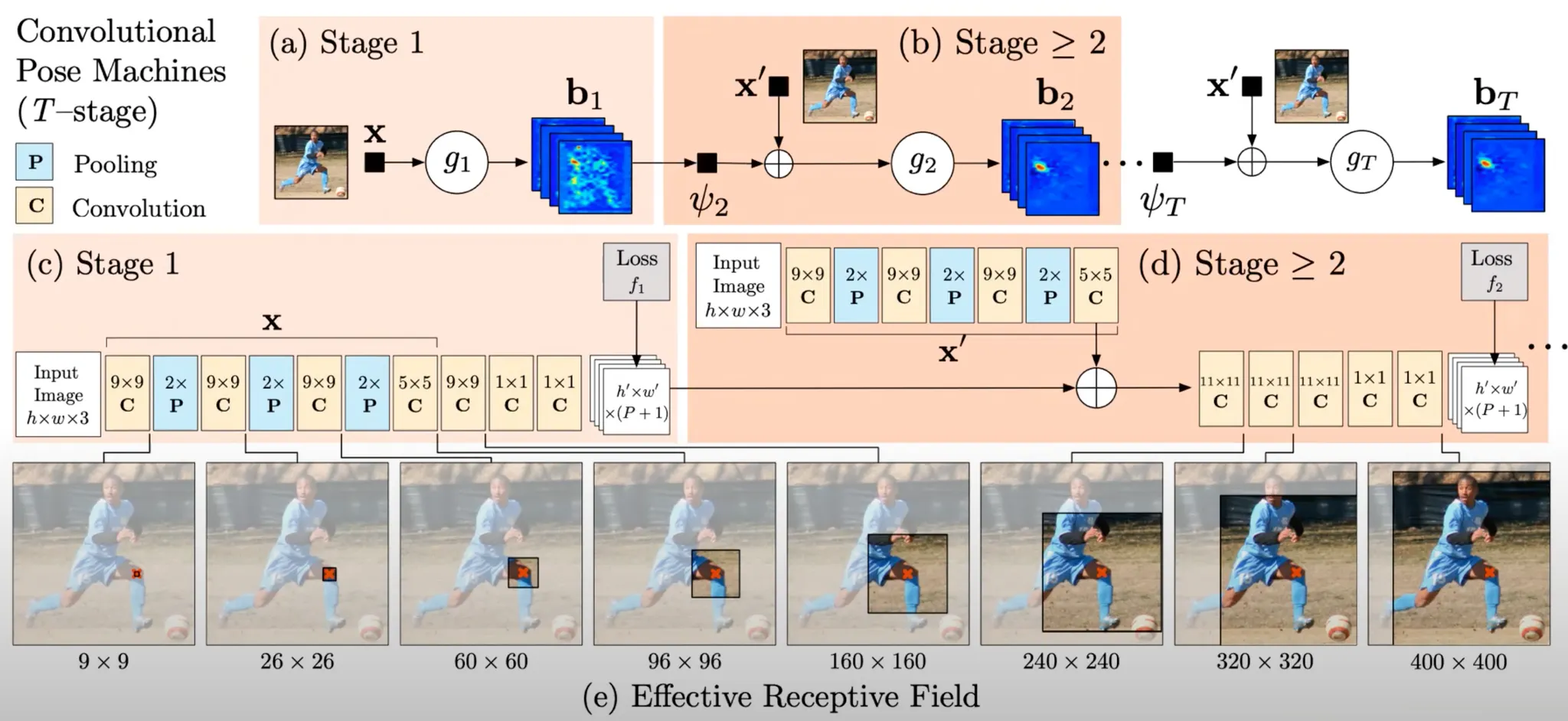
Convolutional Pose Machines

•
2D Coordinate 값을 직접적으로 regression 하는 것이 아닌, 픽셀값에 strength 를 주는 방식
•
즉, output 은 heatmap 들의 집합이 됨. 찾으려는 keypoint 의 개수만큼 heatmap 을 산출하면 됨.
◦
Keypoint 의 수보다 하나 많은 Heatmap 을 산출하는 이유는 모든 keypoint 를 제외한 영역만을 highlighting 하는 heatmap (background) 를 산출하기 때문임.
◦
Heatmap 의 크기는 Input 과 다를 수 있음.
Convolutional Pose Machines: Structure
•
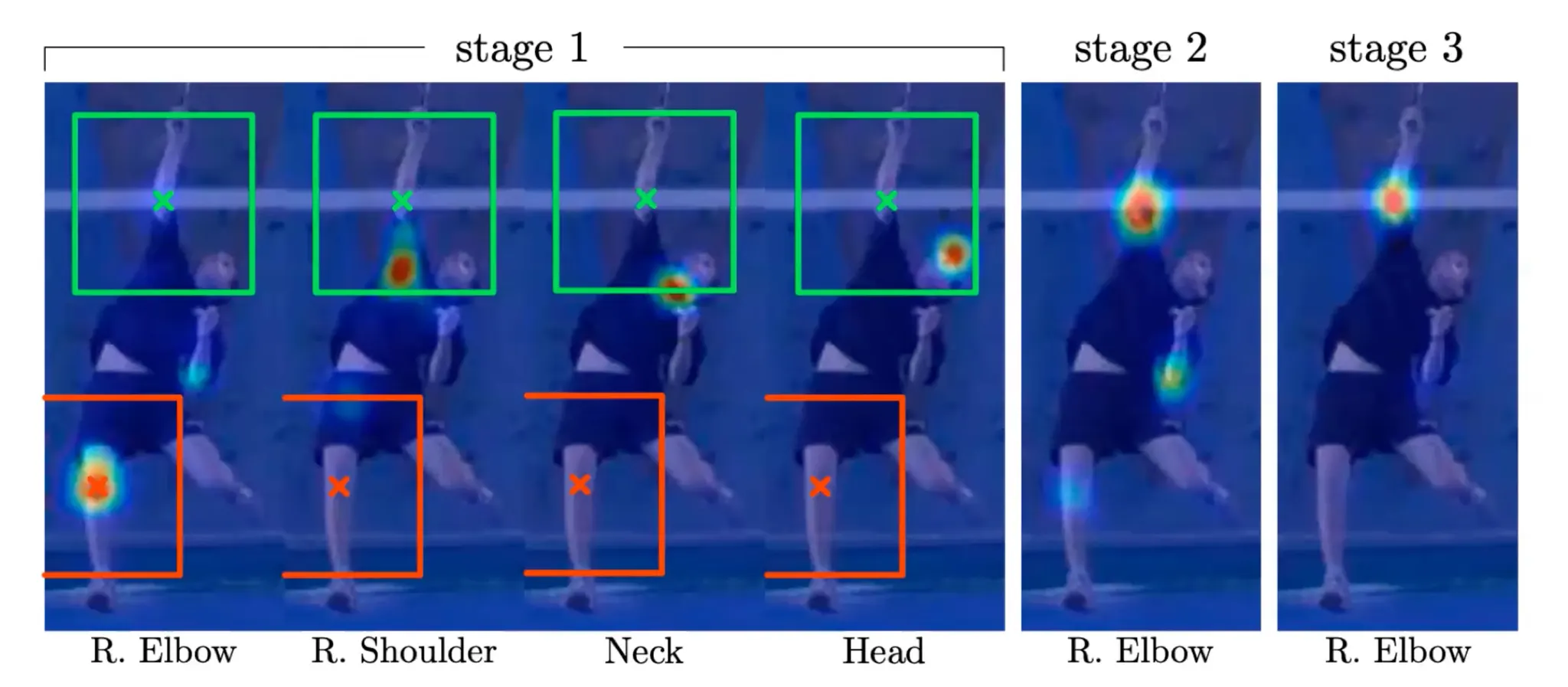
여러 stage 로 이루어져 있고, 각 stage 는 heatmap 을 산출함.
•
이전 stage 에서 산출한 heatmap 이 spatial infromation 을 담고 있기 때문에 다음 stage 에서 process 된 representation 에 concatenate 되어 stage 가 가면 갈수록 더 정확한 heatmap 을 산출하게 됨.
•
Ground Truth heatmap 은 정해진 keypoint 위치 근처에 gaussian kernel 을 이용해서 근처의 값을 높여주는 작업을 진행하여 생성할 수 있음.
•
전체적인 학습 프로세스는 다음과 같음.
1.
Stage 1 에서 FC + Conv 로 이루어진 layer 를 통과하여 heatmap 을 산출하고 ground truth heatmap 과의 비교를 통해 loss 을 산출함.
2.
Stage 2 에서 마찬가지로 FC + Conv 로 이루어진 layer 를 통과한 representation 과 이전 단계에서 온 heatmap 을 concatentate 하고 다시 좀 더 큰 receptive field 를 가진 (entire body part 를 봐야 왼팔, 오른팔을 구분할 수 있음…) Conv 에 태워 heatmap 을 산출하고 ground truth 와의 비교를 통해 loss 를 산출함.
3.
2 를 반복함.
4.
등을 이용해 최종 loss 를 정의하고 gradient descent 를 걸어 intermediate 한 부분에서도 gradient 가 흐르게 하여 gradient vanishing 문제를 해결함.
•
Heatmap + Intermediate Supervision + Large Receptive Field 의 사용이 이 방법론의 핵심임.
•
점점 recpetive field 을 늘리는 세팅이 DPM 에서 tree structure 를 통해 spatial configuration 을 고려하려고 했던 것을 달성할 수 있게 하는 역할을 함.
Stacked Hourglass
•
각 scale 마다 뽑아낸 정보를 propagation 시키는 approach 인데, 결과가 잘 나왔음.
Evaluation
•
만든 방법론이 얼마나 잘 되는지를 확인하기 위해서 metric 이 필요함. → 2D Human Pose Estimation 분야에서는 PCKh Metric (Percentage of Correct Keypoints) 을 주로 사용
•
일반적인 Pixel Error 를 사용하면, 이미지의 크기가 작으면 일반적으로 작은 경향이 생기므로, normalize 하는 과정이 필요함. → 머리 크기를 reference 로 하여 normalize 하려는 시도를 진행함.
•
Normalize 이후에는 pixel error 가 특정 threshold (보통 headsize 기준으로 정함) 보다 작은 joints 들을 correct 로 힘. → Correct 한 joint 의 비율이 PCKh Metric 임.
Multi-Person Pose Estimation
•
지금까지는 Single-Person Pose Estimation 인데, 이를 Multi-Person 에 적용하기 위해서는 naive 하게는 bounding box 를 모두 지정하면 되지만, 매우 time consuming 하고 occlusion 등에 정확하지 않음.
•
먼저 모든 점들을 찾은 다음에 사람 형태를 찾아 연결하는 방법에 대한 아이디어를 낼 수 있었음.
•
OpenPose 는 네트워크가 part 들에 대한 픽셀값 뿐만 아니라 conection 또한 산출하는 형태를 제안함.

◦
각 픽셀 별로 방향성을 추가로 산출하여 연결된 body part 의 위치를 나타내도록 함. 이를 Part Affinity Field (PAF) 라고 부름.
•
기존 네트워크가 비슷하지만, PAF 를 추가로 산출하고 이 정보 또한 다음 단계로 갈 때 추가로 concatentate 되어 다음 heatmap 과 PAF 를 산출하는데 모두 사용되는 형태임.
Human Keypoint Datasets
•
보통은 Human Keypoint detection 과 같은 분야에서 Face → Body 순서로 문제를 해결함.
•
손의 경우는 아무도 안함…
◦
데이터셋만 있으면 네트워크랑 방법론 다 있는데 하기만 하면 될듯해서 교수님이 직접 annotate 하심.
How to Make a Good 2D Hand Pose Detector

•
같은 이미지인데 annotation 이 완전히 다름.
•
처음에는 instruction 을 많이 주었지만 (Joint 가 맞고 아님을 자세히, 정확히 주었음.) 잘 안되었음.
•
돔 안에서 multiview 를 suprevision 으로 주는 방법을 사용해봄.
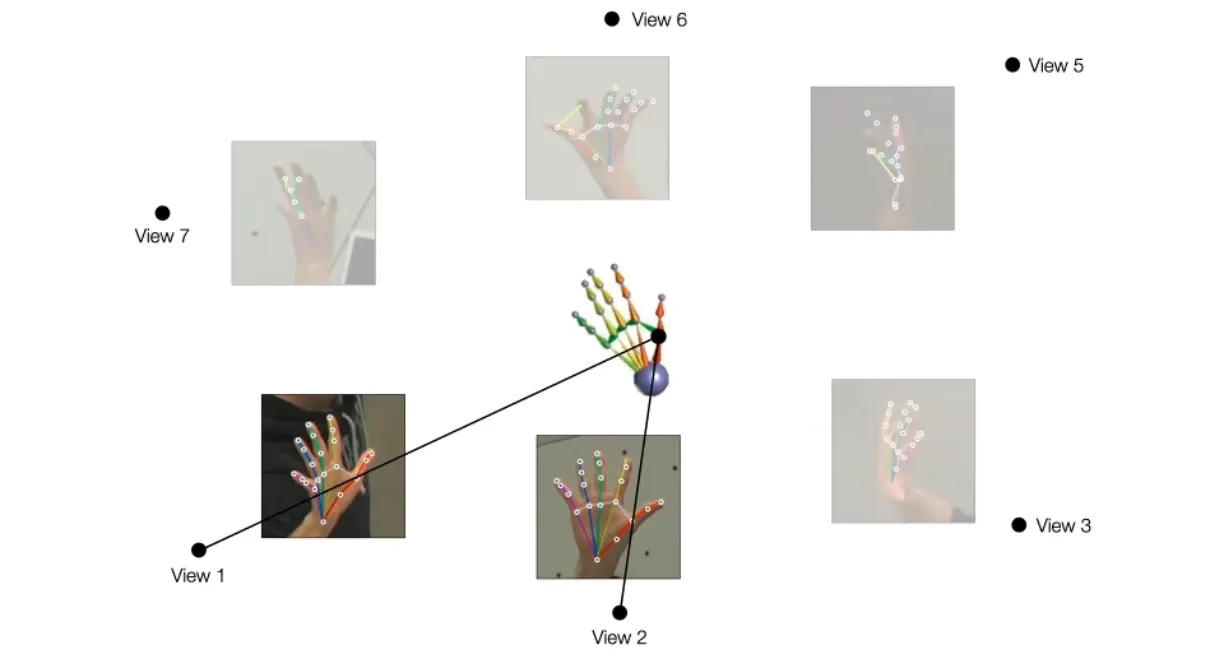
◦
Mutiview 이미지에서 Corresponding Point 를 찾고 이를 기반으로 Triangulation 을 사용해 3D reconstruction 을 진행함.
◦
몇몇의 annotation 이 잘 된 것들은 해당 joint 와 3D reconstruction 된 joint 가 matching 이 잘 되지만 그렇지 않은 것들은 그렇지 않음.
◦
이 방법을 통해서 잘못된 annotation 을 찾을 수 있고 버릴 수 있음.
◦
잘못된 annotation 은 반대로 완성한 3D reconstruction 에서 projection 을 통해 생성하게 됨.
•
이 방법으로 기존의 annotator 에서 실패하는 경우에서도 annotate 하여 데이터셋을 생성할 수 있었음.
DensePose
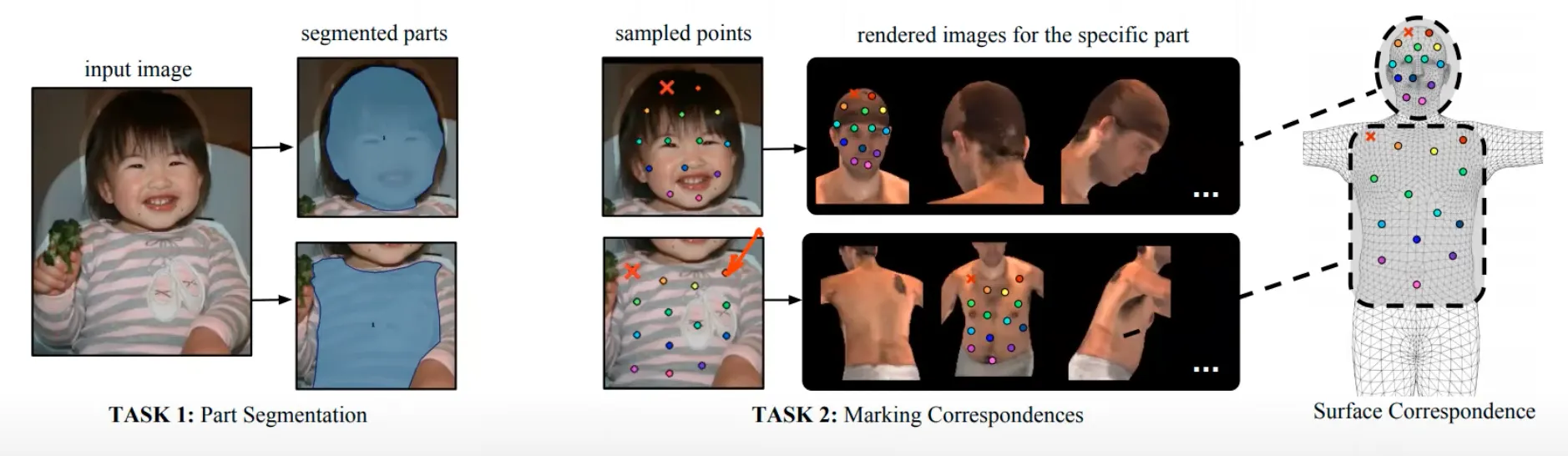
•
일반적인 keypoint 는 sparse 한데, dense 한 keypoints 들에 대한 detection 을 생각해볼 수 있음.
•
Dense Keypoint 를 정의하는 방법 ?
◦
어떻게 해당 점을 설명할 수 있을까 ? → Keypoint 가 찍힌 Sample Image 를 준비하고 해당 Keypoint 들과 동일한 점을 다른 이미지에서 찾으라고 명시해주는 방법을 사용함.
◦
Keypoint define 을 visual 로 진행함.
•
다양한 이미지에 대해서 해당 point 들을 찾는 방법으로 DensePose dataset 을 만들어 Mask-RCNN 으로 학습하여 일반적인 이미지에서 해당 keypoints 들을 찾을 수 있도록 함.