



Local Features for Correspondence Search
1.
Detection: Identify the interest points
•
Interest Operator Repeatability: 두 장의 이미지 각각에서 interest points 를 찾더라도 두 장의 이미지에서 동일한 지점을 찾고 싶음!
2.
Description: Extract vector feature descriptor surrounding each interest point.
•
Descriptor Distinctiveness: geometric, photometric difference 가 있더라도 invariance 한 descriptor 를 찾아 서로 다른 지점들은 확실히 다르게, 같은 지점들은 같게 matching 하고 싶음!
3.
Matching: Determine correspondence between descriptors in two views
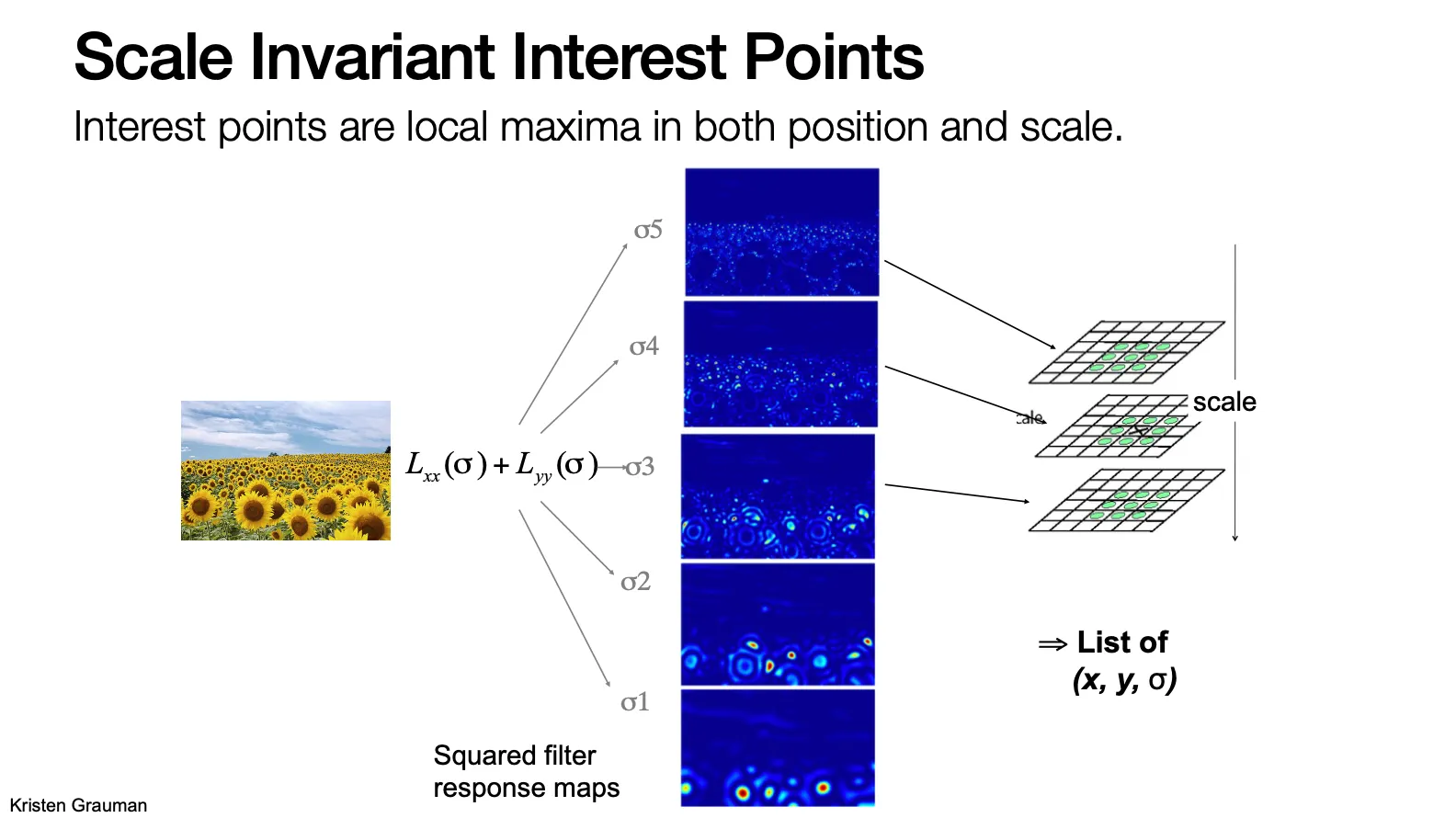
Detection: Scale Invariant Interest Points
•
이미지 상에서 interest points 의 scale 이 다를 수 있는데, 이러한 이미지들에 대해서도 잘 동작해야함
•
어떤 function f 가 local maxima 를 가지는 scale 과 position 을 interst point 로 설정하면 어떨까?
◦
한 번에 scale 과 position 을 찾을 수 있음! (Automatic scale selection)
◦
Laplacian of Gaussian ()을 적용하면, centor of blob 과 matching scale 에서 local maxima 를 가지기 때문에 이 함수를 통해 position 과 scale 을 찾을 수 있음!
•
Laplacian 은 Difference of Gaussian 으로 근사할 수 있음 → efficient to implement
◦
Gaussian 을 적용해가면서 (적용할수록 가 큰 gaussian 을 적용한 효과와 같음) 적용한 이미지들의 차이를 켜켜이 쌓아 DoG 들을 만들어냄 (Gaussian pyramid)
◦
4 번정도 적용한 것에 1/4 로 resizing 하여 반복하는 과정을 진행함
◦
만들어낸 DoG 의 pyramid 에서 scale (next, previos level 의 neighborhood pixel 비교), position (current level 의 neighborhood pixel 비교) 두 측면에서 모두 local maxima 를 보이는 점을 찾아서 interst points 로 지정함
Description: Feature Descriptor Extraction
•
추출할 feature descriptor 는 geometric/photometric 하게 invariance 해야함 (그래야 matching 할 수 있기 때문…)
•
이를 위해서 Scale Invariant Feature Transform (SIFT) 를 사용함 (하나의 이미지의 로컬 영역의 feature 를 다른 이미지의 로컬 영역의 feature 에 scale, orientation 측면에서 align 되도록 transform)
•
먼저, Scale Normalization 으로 영역의 크기를 normalize 함
◦
앞선 interest points 에서 구한 scale 을 이용해서 두 scale 이 같아지도록 resizing 함
•
다음으로, Orientation Assignment 로 rotation 함
◦
각 영역에서 Histogram of Oriented Gradient 를 만들어 dominant direction 을 구해내고 두 로컬 영역의 dominant direction 이 같아지도록 rotation 함
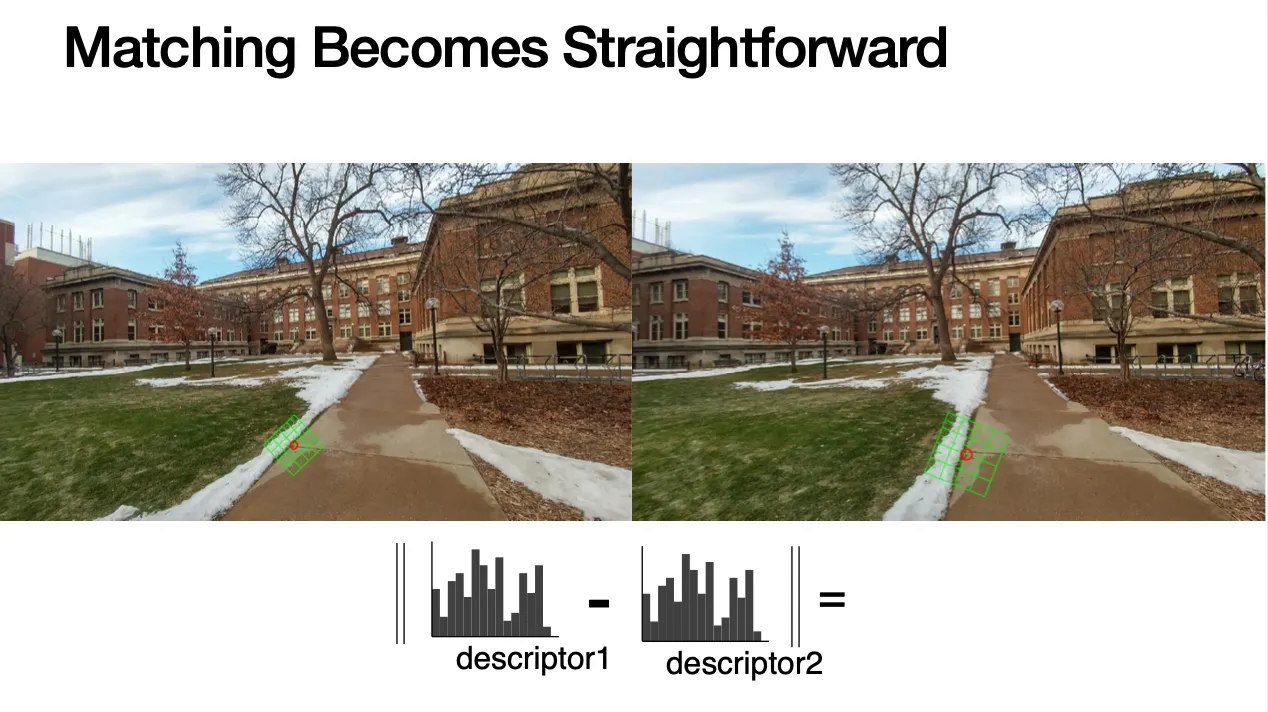
Matching
•
구해낸 local descriptor 사이의 거리를 이용해 matching 여부를 판단함
•
이러한 matching 은 object recognition, transformation 을 찾고 image warping, image stitching 등에 활용될 수 있음
Bag of Words

•
다량의 이미지 patch 로부터 D-dimensional feature (SIFT, HoG 등) 을 뽑아냄
•
뽑아낸 feature 에서 K-means clustering 을 하여 dictionary centroids 를 뽑아냄
•
이미지별로 각 dictionary centroids 에 들의 term frequency 에 대한 histogram 을 뽑아냄
•
뽑아낸 BoW representation 를 기반으로 SVM classifier 의 decision boundary 를 찾음
•
Tiny Image Representation < HoG Feature, Nearest Neighborhood < SVM