본 포스트에서는 Machine Learning 에서 제가 꽤나 궁금했던 분야에 대해서 알아보려고 합니다. Machine Learning 이라고 하면, 많은 사람들이 신기하고, 색다른 결과에 집중하기 마련인데 실제로 머신러닝을 연구할 때 많이들 드는 생각이 "이렇게 해보면 학습이 잘 되겠지...?" 보다는 "이렇게 해보니 잘 되었네...?" 라고 합니다. 한마디로, "때려 맞추기" 의 느낌이 강하시다고 보면 됩니다. 저는 이런 "때려 맞추기" 식 연구를 하는 것을 상당히 마음에 안들어했지만, 최근에 Explainable Artificial Interlligence 라고 하여 말 그대로 결과를 설명 가능한 인공지능에 대한 연구가 꾸준히 진행된다는 것을 알게 되었습니다. 그래서 관련 내용을 찾아보았고, 그 내용을 정리해보려고 합니다.
Blackbox Problem
Machine Learning, AI based 시스템은 일명 "블랙박스" 라고도 불립니다. 무엇이 input 으로 주어지고, 무엇을 output 으로 주어지는지는 알지만 그 안에서 무엇이 어떻게 진행되는지, 그리고 왜 그런 결과가 나오는지 알지 못하기 때문입니다.
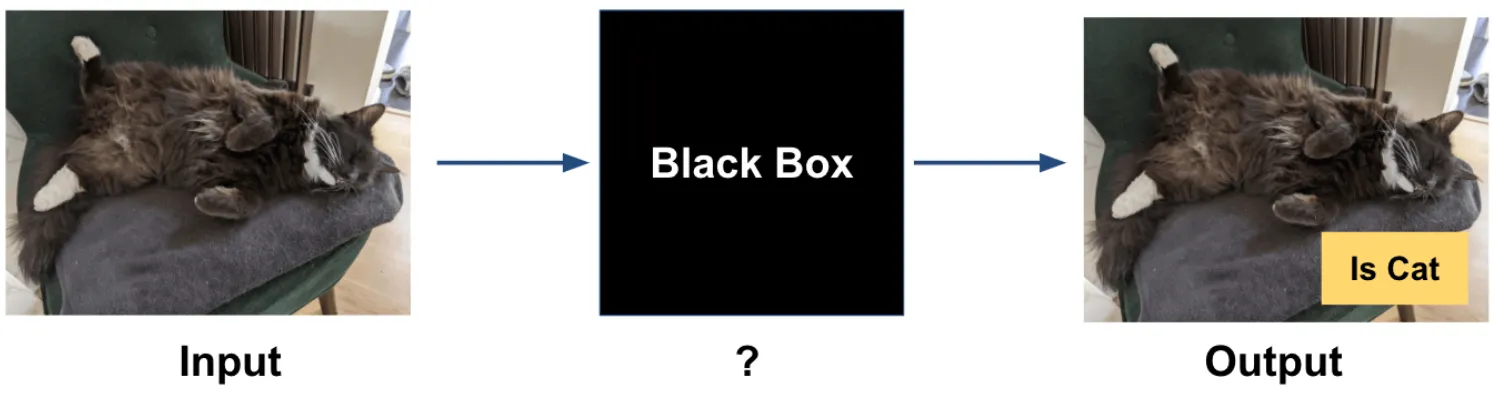
위의 그림과 같이, 개/고양이 분류기에 고양이 사진을 넣어서 결과로 이 사진이 고양이 사진이라는 것을 얻을 수는 있지만, 안에서 어떤 과정이 일어났기에 고양이라고 결론 지을 수 있는지에 대해서 알 수 없다는 말입니다.
저는 딥러닝을 학습한 사람으로써, 처음에 이 말이 이해가 잘 되지 않았습니다. 블랙박스 내부에서는 objective function 을 최소/최대화 하는 방향으로 weight 를 변화시켜가면서 최적의 weight 를 찾아내는 일들이 일어나는 것을 알고 있었기 때문입니다. 하지만, 이내 "어떤 과정이 일어났기에" 가 진정으로 의미하는 바가 무엇인지 알게 되었습니다.
물론, 제가 처음 한 생각도 틀린 말은 아닙니다. 실제로 블랙박스 내부에선 그런 일들이 일어나기 때문입니다. 하지만, 블랙박스 문제가 초점을 맞추는 것은 학습이 완료된 이후에 고양이 사진을 넣었을 경우 일어나는 일입니다. 저희가 forward propagation 이라고 말하는 그 과정입니다. 저희는 블랙박스에서 forward propagation 이 일어난다는 것을 알지만, 그 연산이 일어나는게 무슨 의미인지는 모릅니다. 그저 다음과 같이 설명할 뿐입니다.
1.
사진의 특징(feature) 을 뽑아냅니다.
2.
고양이랑 비슷한 특징을 가지는지, 강아지랑 비슷한 특징을 가지는지 확인합니다.
3.
더 비슷한 특징을 가지는 쪽으로 판단을 내립니다.
위의 설명은 상당히 모호한 설명입니다. 사진의 특징이 뭔지 정확히 설명할 수도 없으며, 더더욱 고양이랑 비슷한 특징이 무엇인지도 설명할 수 없습니다. 애초에 "고양이 같다" 라는 말이 정확히 의미하는 바를 설명할 수 없는 말이기도 합니다. 눈이 있고, 코가 있고, 입이 있고 등등으로 어찌어찌 비슷하게 정의할 수는 있지만 결국에 반례는 존재합니다. 단순히 위의 조건만으로 생각하면 눈, 코, 입이 따로 노는 괴물도 고양이로 분류할 수 있는 것입니다.
반대로 생각해보면, 설명할 수 없기에 이러한 것들을 딱 떨어지는 방법론으로 구별하는 것이 아니라, 빅데이터에 기반한 딥러닝 기술로 연구하는 것이기도 합니다. 때문에, 딥러닝과 설명불가능성은 사실상 필수불가결한 관계에 있는 경우가 많습니다. 애초에 어떤 무언가로 정의나 설명이 잘 되었으면 굳이 딥러닝을 써서 해결하려고 하지도 않았을 것이라는 말입니다.
XAI (Explainable Artificial Intelligence)
앞서 설명한 대로, blackbox problem 은 Machine Learning, AI based 시스템이 목표로 하는 바가 주로 "명확한 답이 존재하지 않는 문제에 대한 해답을 얻기 위해서" 이기 때문에 나타납니다. 예시를 들어 설명을 하자면,
•
강아지랑 고양이 분류하기 (O)
•
사람처럼 생긴 이미지 생성하기 (O)
•
텍스트가 묘사하는 것에 대한 이미지 생성하기 (O)
•
특정 사용자가 좋아할만한 영화 메인에 띄워주기 (O)
•
자동차 별 최대 시속 구하기 (X)
강아지랑 고양이 분류하기, 사람처럼 생긴 이미지 생성하기, 텍스트가 묘사하는 것에 대한 이미지 생성하기, 특정 사용자가 좋아할만한 영화 메인에 띄워주기는 명확한 답이 존재하지 않는 문제들입니다. 반면, 자동차 별 최대 시속 구하기는 명확한 답이 존재하는 문제입니다. 때문에 자동차 별 최대 시속 구하기는 실제로 자동차 사진을 보고 최대 시속을 예측하는 등의 엉뚱한 작업을 하면서까지 딥러닝을 사용할 필요가 없습니다. 그저, 자동차 제작사 사이트에 가거나 그 곳에 전화를 해서 알아내면 되는 문제라는 것입니다.
Explainability
그러면, 명확한 답이 존재하지 않는데 XAI 는 도대체 무엇을 설명하려고 하는 걸까요?
이에 대해서 알기 위해서는 Exaplainability(설명가능성) 에 대해서 짚고 넘어가야 합니다.
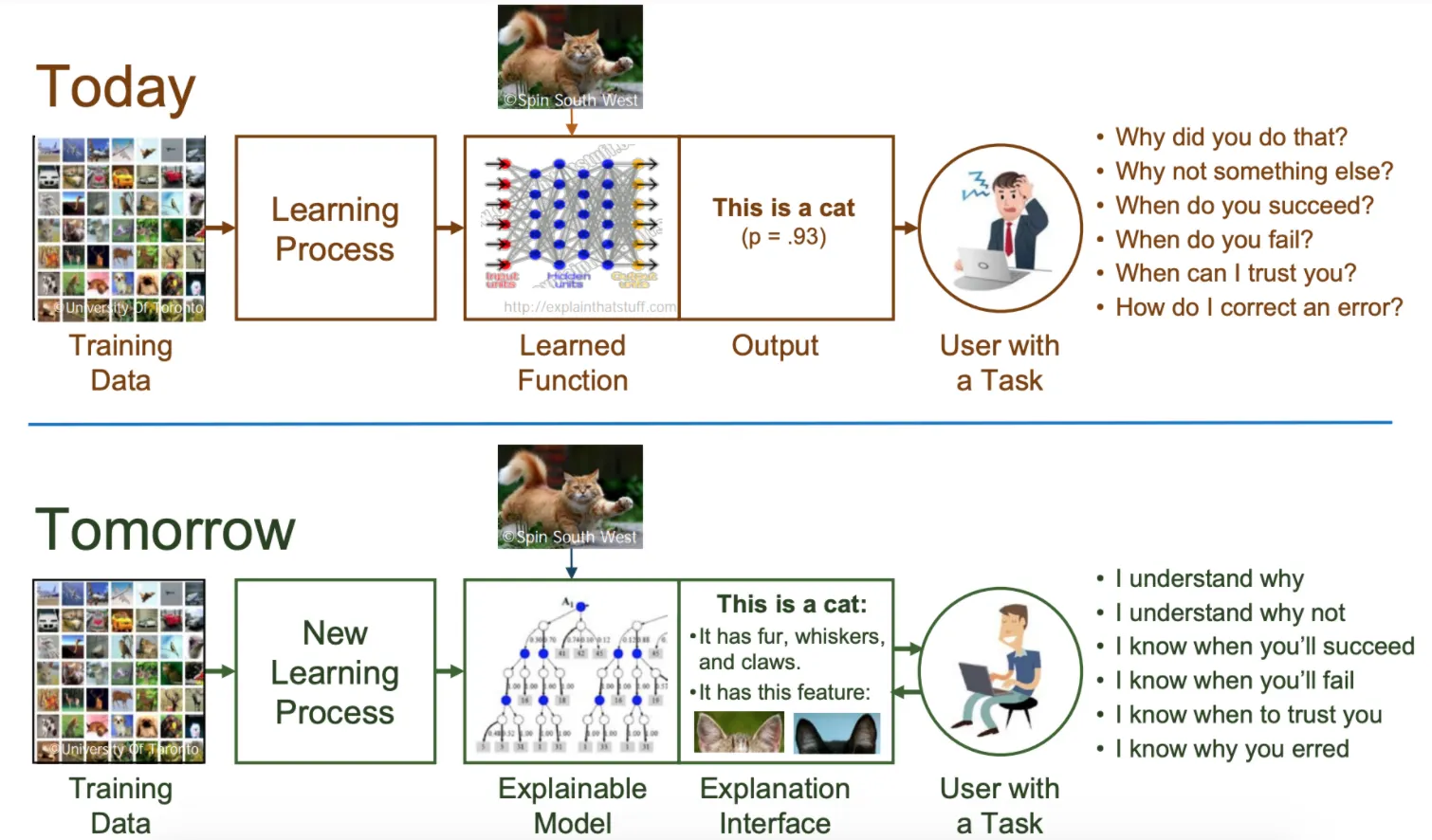
설명 가능성은 "모델이 어떤 역할을 하는지 이해할 수 있는 특성" 입니다. 이는 모델이 다양한 상황에서 어떤 결과를 내는지를 알수 있는가의 여부로 볼 수 있습니다. 개/고양이 분류기를 예시로 들자면, 어떤 경우에 개/고양이의 분류를 성공하는지 어떤 경우에 개/고양이의 분류를 실패하는지를 알 수 있다면, 그 개/고양이 분류기를 설명가능하다라고 보는 것입니다. 즉, 설명가능한 모델을 사용하면 다음과 같은 작업을 할 수 있다는 것입니다.

내 개/고양이 분류기가 눈, 코, 입이 있는 것을 고양이로 분류하는 것을 알고, 내가 지금 눈, 코, 입을 가진 괴물 사진을 넣었으니 내 분류기의 결과는 믿을 수 없는 결과이구나.
물론, 몇몇 사람들은 위 예시에서 눈이 뭔데 ? 코가 뭔데 ? 입이 뭔데 ? 라는 이야기를 하면서 "눈, 코, 입이 있는 것을 고양이로 분류하는 것을 알고" 가 상황별 모델의 결과를 완벽하게 설명할 수 없다고 주장할 수 있습니다. 맞는 말씀이지만, 그러한 관점으로 따지기 시작하면 앞서 설명했듯이 완벽한 설명은 어디에도 있을 수 없습니다. 앞서 말씀드린 것처럼 애초에 정답이 없는 문제이기 때문입니다. 그렇기에, 설명가능성에서 집중하는 것은 "완벽한 설명" 이라기 보다는 "기존보다 나은 설명" 입니다. 아무것도 설명할 수 없었던 기존에서 적어도 눈, 코, 입이 있는 것을 고양이로 분류한다는 설명을 내걸 수 있게 되는 것 같이 말입니다.
이러한 "설명가능성" 의 정의 아래에서 XAI 는 다음과 같은 것을 목표로 하는 인공지능이라고 볼 수 있습니다.
1.
설명 가능한 모델을 설계합니다.
2.
Machine Learning, AI based 시스템에 대해 인간이 믿을 수 있도록 합니다.
3.
법적/윤리적 기준 설립의 척도를 마련합니다.
Necessity
지금까지 XAI 가 무엇인지를 설명가능성을 토대로 알아보았습니다. 그렇다면, XAI 를 연구하는 사람들은 XAI 가 왜 필요하다고 주장하는 것일까요?
XAI 의 필요성을 주장하는 사람들은, 이에 대해서 크게 4가지의 이유를 대서 설명합니다.
1.
Model Optimization 에 하는데 큰 도움이 됩니다.
일반적으로 이해하지 못하는 것에 대해서는 성능 개선을 비롯한 최적화를 진행하지 못합니다. 어떠한 상황에서 모델이 자주 실패하는지에 대한 정보가 없기 때문입니다. 물론, 지금까지와 같이 "때려 맞추기" 식의 개선이 가능하겠지만, 설명가능성이 보장된다면 이전과는 다르게 확실한 개선 방향성을 잡을 수 있습니다. 특히, objective function 을 설계할 때 이러한 점을 고려하여 설계 할 수 있게 되면서 성능 개선을 기대할 수 있다는 점에서 XAI 는 모델 최적화에 혁신적인 변화를 가져올 수 있습니다.
2.
Model Output 에 기반한 판단에 큰 도움이 됩니다.
일반적으로 저희는 model output 에 기반한 판단을 많이 합니다. 하지만, 많이 하는데에 비해서 모델이 산출한 결과에 대한 대책을 세울 때 근거가 없이 세우는 경우가 많습니다. 예를 들어 모델이 소비자가 신제품을 구매하지 않을 확률이 95% 여서 가격을 기존보다 낮추었는데 실제로 가격 때문에 신제품을 구매하지 않다고 판단한 것이 아니라 디자인이 큰 비중을 차지했을 경우가 있을 수 있습니다.
XAI 가 적용되었을 경우, 정확한 실패원인을 알 수 있기 때문에 이러한 판단에 근거를 제시해줄 수 있고 결과적으로 옳은 판단을 하는데 큰 도움을 줄 수 있습니다.
3.
데이터에 의존적인 시스템 속에서 데이터 오류를 핸들링하는데 큰 도움이 됩니다.
일반적으로, 딥러닝은 준비한 데이터에 대한 전적인 믿음을 기반으로 데이터 간의 관계를 추출해 내고 결과를 도출해냅니다. 하지만, 이러한 시스템은 상당히 위험할 수 있습니다. 편향된 데이터를 수집했을 경우, 악의적으로 학습 데이터를 조작당했을 경우에 나도 모르게 모델이 이상한 방향으로 학습이 진행될 수 있습니다.

위의 예시는 의도적으로 이미지 라벨을 바꿔서 학습해버린 경우인데, 실패의 원인이 라벨의 오류라는 점을 알지 못하면, 쉽사리 캐치하지 못하고 고생할 수 있습니다.
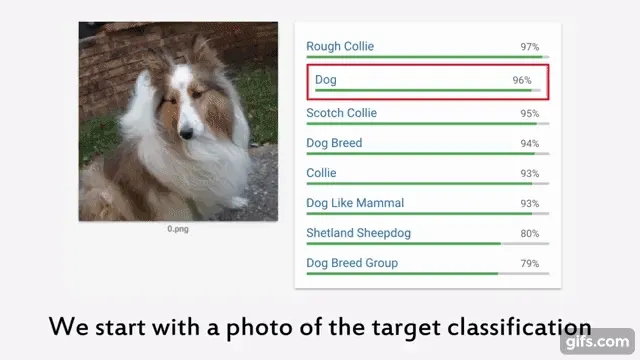
위의 예시는 강아지 사진에서부터 픽셀을 미세하게 조정하여 스키타는 사람들 그림으로 바꿔버리는 경우입니다. 실제로 악의적으로 개 라고 판단하기를 바라면서 오류를 발생시키는 경우인 것입니다. 이러한 경우는 특히 픽셀 자체에 의미를 알지 않는 한 왜 모델이 실패했는지에 대해서 모를 것입니다. 이러한 상황들에서 반대로 XAI 는 실패의 원인을 알고 핸들링하는데 큰 도움을 줄 수 있습니다.
4.
Machine Learning, AI based 시스템이 법적, 규제적, 윤리적 고려가 필요하기 때문입니다.
입력이 결과로 이어지는 과정을 이해할 수 있어야 법적, 규제적, 윤리적 문제들에 대한 정확한 판단이 가능합니다. 하나의 예시로 자율주행 자동차를 들 수 있습니다. 자율주행 자동차가 낸 사고에 대해서 과실을 명백히 하기 위해서는 정확히 어떤 상황에서 모델이 오류가 발생하여 사고를 냈는지에 대해서 판단하는 것이 필요합니다. 또한 모델이 어느정도의 정확성을 보유해야 실제로 시판이 가능한지에 대한 기준을 세우기 위해서라도 설명가능성은 필요한 요소입니다. 3번의 데이터 오류랑 합쳐진다면, 악의적으로 사고를 낼 수도 있기 때문에 이 부분은 더더욱 민감한 주제입니다.
How much we need to explain ?
지금까지 XAI 가 필요한 이유에 대해서 알아보았습니다. 하지만 필요한 이유를 알아보기 전에 저희는 XAI 가 어차피 완벽한 설명을 할 수 없다는 점을 알았습니다. 그렇다면, XAI 는 모델이 어느정도를 설명할 수 있어야 된다고 생각하는 걸까요?
이를 알기 위해서는 모델의 복잡성(Complexity) 과 모델의 중요성(Criticality) 에 대해서 알아야 합니다.
1.
Complexity
모델의 복잡성은 일반적으로 dimensionality 로 표현합니다.
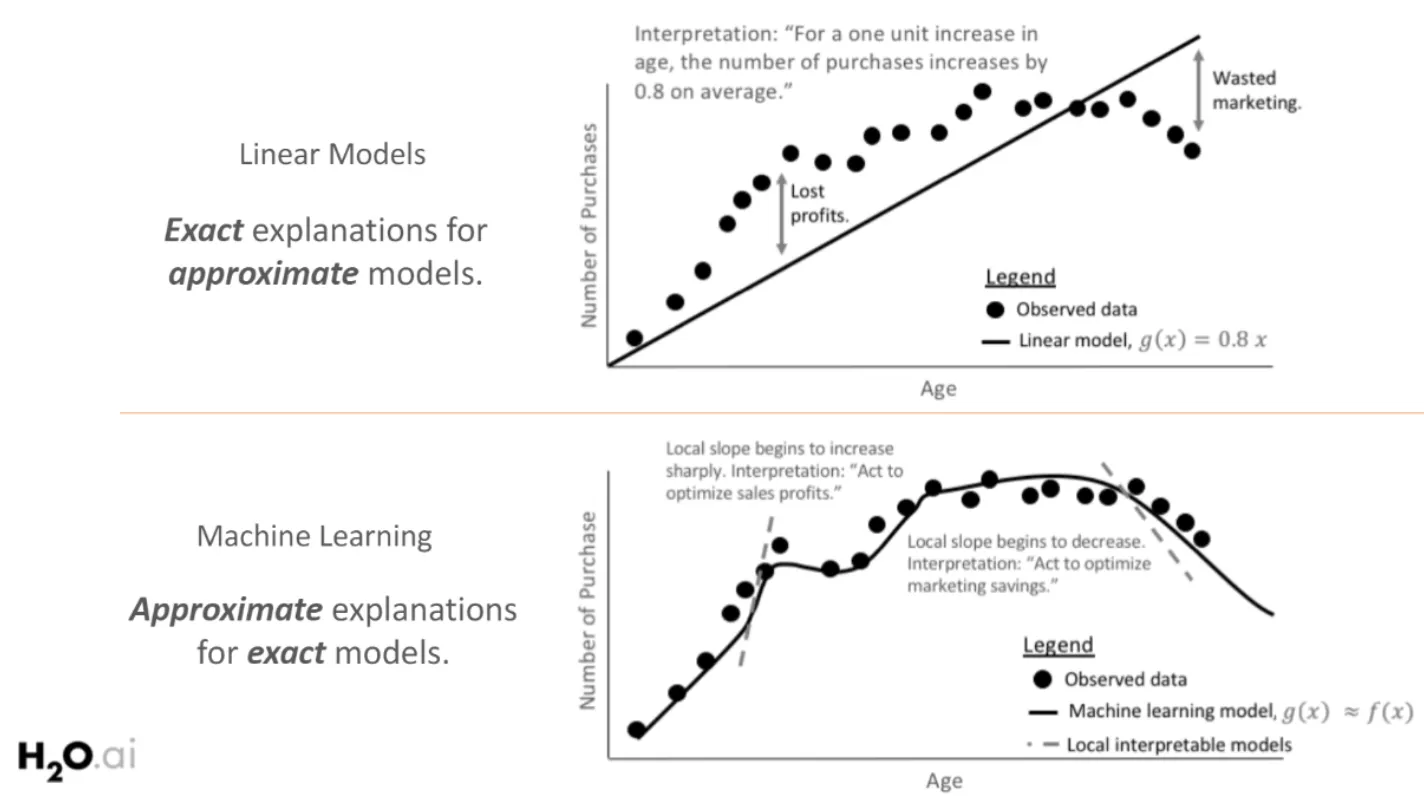
Dimensionality 는 모델의 hypothesis 가 얼마나 복잡한지에 대한 정보입니다. 위의 그림을 예시로 들면 위의 그래프는 일차 함수의 형태이고, 아래의 그래프는 고차 함수입니다. 이 경우, 고차 함수가 더 hypothesis 의 dimension 이 높다는 의미에서 dimensionality 가 높습니다.
일반적으로 dimensionality 가 높은 것을 complexity 가 높다고 표현하고, 위의 그림에서는 아래의 모델이 complexity 가 높다고 표현합니다.
2.
Criticality
모델의 중요성은 말 그대로 모델이 다루는 문제가 얼마나 중요한가에 대한 척도입니다. 이 또한, 저희의 주관으로 중요성을 따지지 않고 생각보다 명확한 기준이 존재합니다. 자세한 기준은 아래의 표를 참고하시면 좋습니다. 알아두셔야 할 것은 민감한 문제일수록, 대중적인 문제일수록, 인간의 삶에 밀접한 관계가 있는 문제일수록 중요도가 높아진다는 점입니다.

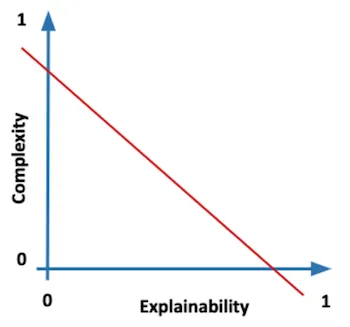
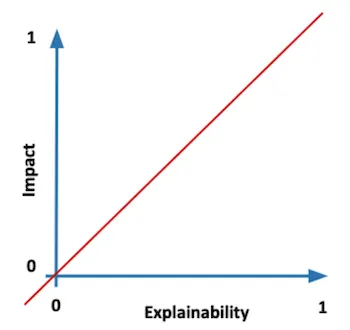
앞에서 이렇게 모델의 복잡성과 중요성에 대해서 언급한 이유는 일반적으로 모델의 복잡성은 모델의 설명 가능성에 반비례하고, 모델의 중요성은 모델의 필요 설명 가능성과 비례하기 때문입니다.
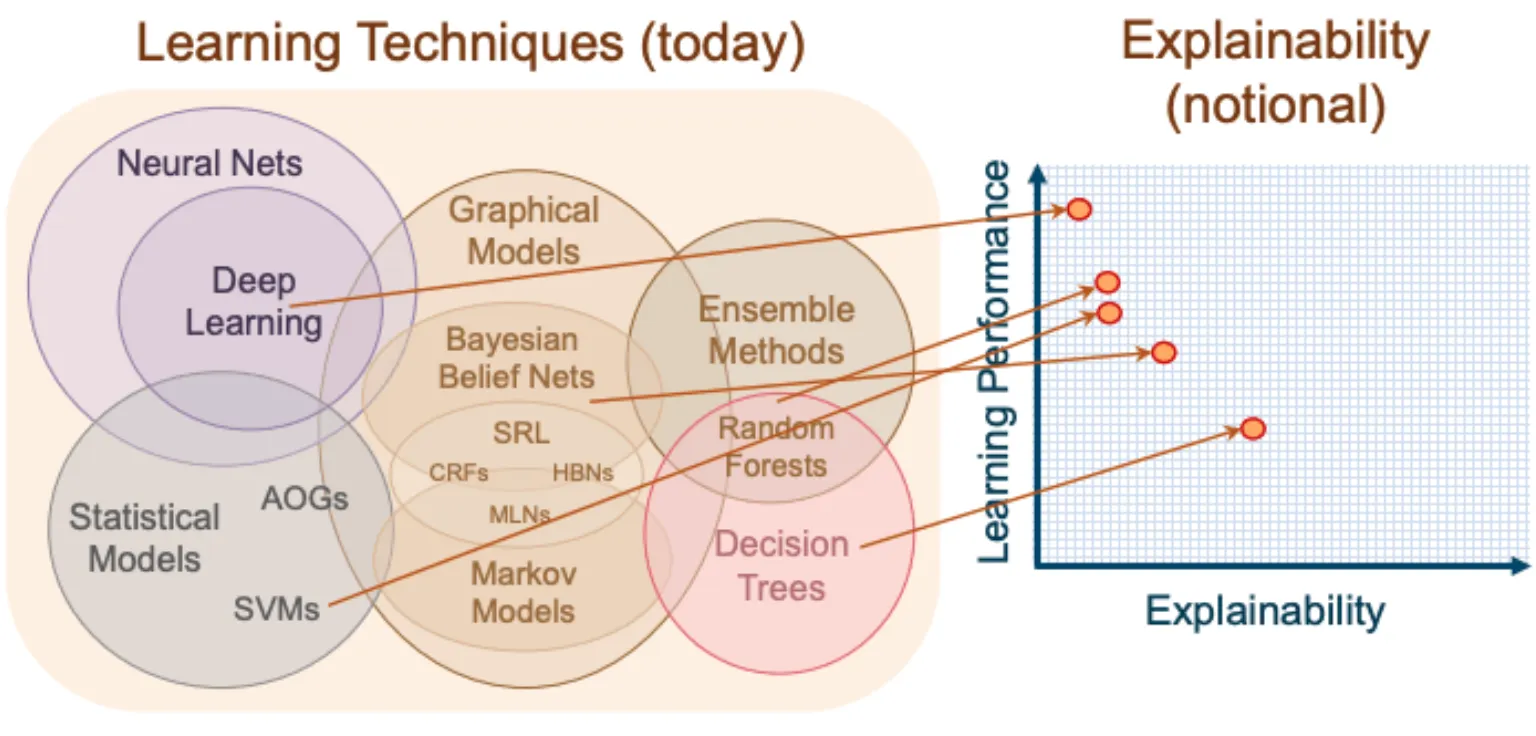
모델의 복잡성에 따라서 설명가능성이 달라지는 것은 Learning Technique 에 따른 설명가능성으로 예시를 들어 설명할 수 있습니다. Deep Learning 과 같은 학습 기법은 설명가능성이 매우 낮은데 비해서, decision tree 와 같은 기법은 특정 기준에 따른 판단의 분류이기 때문에 설명가능성이 높습니다.
그리고, 모델의 중요성에 따라서 모델의 필요 설명가능성이 비례하는 것은 앞서 설명했던 것처럼 민감한 문제일수록, 대중적인 문제일수록, 인간의 삶에 밀접한 관계가 있는 문제일수록 모델에 대해 필요한 믿음의 크기가 중요하기 때문에 높은 설명가능성이 필요한 것입니다.
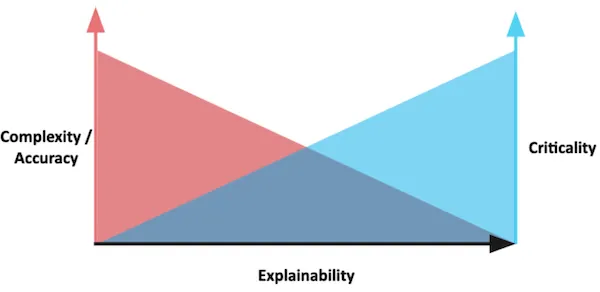
그런데, 눈치가 빠르신 분들은 이 두가지 요소가 서로 상충된다는 점을 아실 수 있으실 것입니다. 위 그림과 같은 양상으로 그래프가 합쳐진다는 것입니다. Complexity 를 욕심낸다면, Explainability 를 어느정도 포기해야하고, Criticality 가 높은 문제에 대해서 다루려면 Explainability 를 챙겨야하기 때문입니다. 즉, 높은/민감한 중요도의 문제를 해결하는 모델에 대해서는 높은 설명가능성을 부여해야 하고, 그만큼 Complexity 를 낮게 가져가도 됩니다. 이 경우는 자율주행 시스템 같은 예시가 있습니다. 반대로, 낮은 중요도의 문제를 해결하는 모델에 대해서는 굳이 높은 설명가능성을 부여할 필요가 없고, 그만큼 Complexity 를 높게 가져가 정확도를 높여도 됩니다. 이 경우는 개/고양이 분류기 같은 예시가 있습니다.
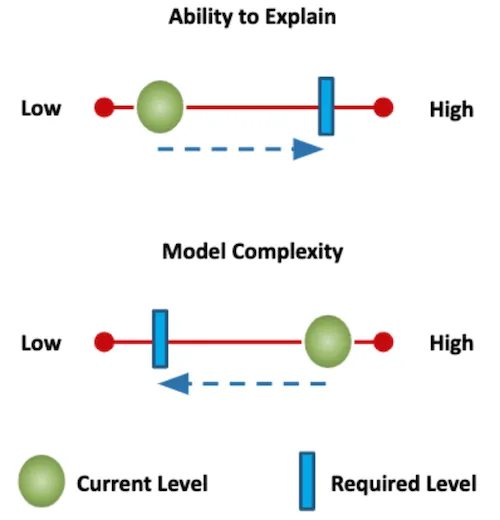
그리고, 이렇게 각 모델의 필요 설명 가능성과 현재 설명가능성을 정의할 수 있게된다면, 모델을 어떤 식으로 바꾸어야 하는지에 대한 계획을 세울 수도 있습니다. 위 그림처럼 Explainability 가 Necessary Explainability 가 작은 경우에는 모델 커스터마이징으로 어느정도의 Explainability 를 확보해야 하고, Explainability 가 Necessary Explainability 보다 큰 경우에는 정확도를 위해 모델 Complexity 를 증가시켜야 합니다.
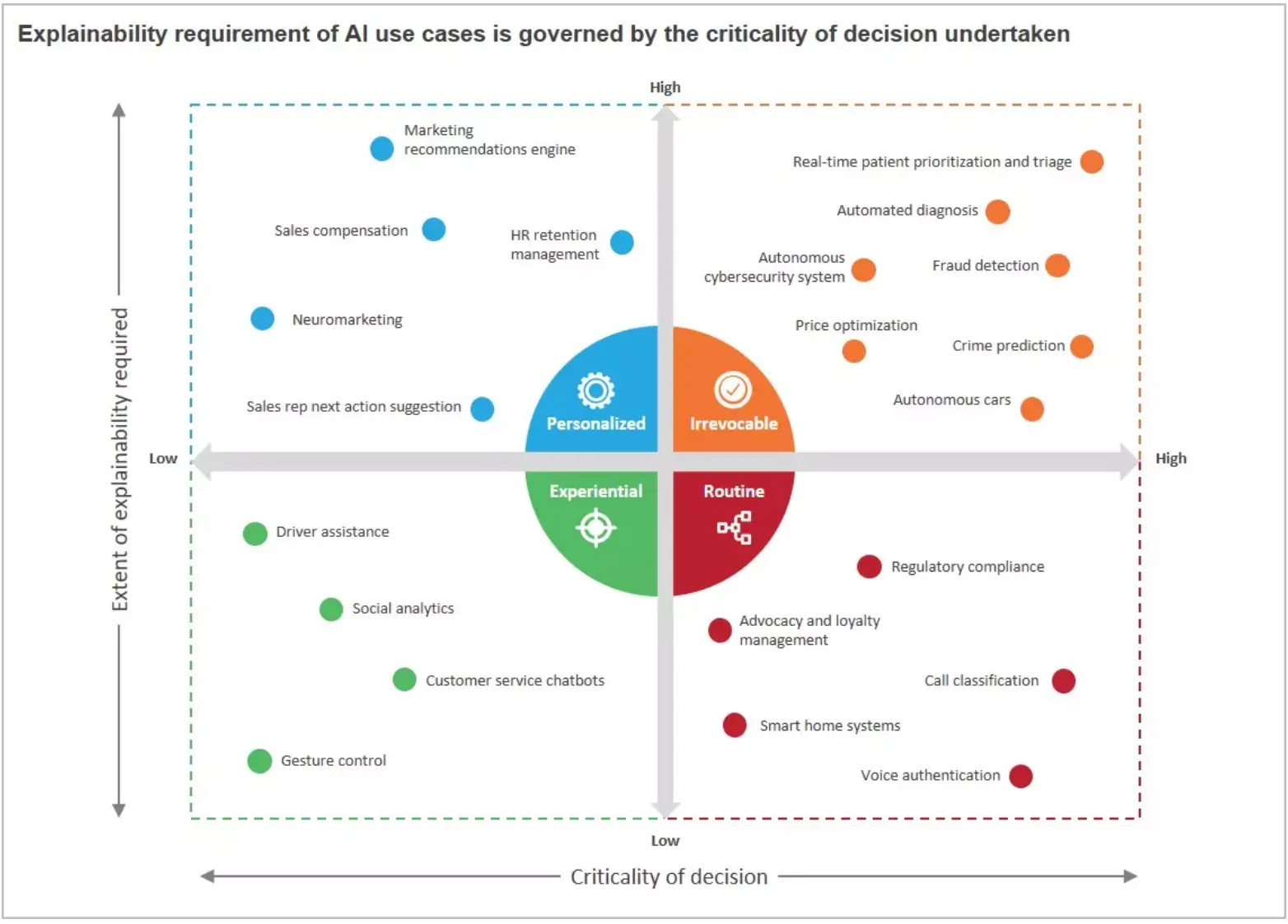
위 그림은 Criticality 와 Necessary Explainability 에 따라 AI usecase 들을 분류한 것입니다. 간단하게 살펴보면 자율 주행차의 경우 우측 상단에, 챗봇 같은 경우 좌측 하단에 있는 것을 볼 수 있습니다.
Current Situation
지금까지, XAI 가 무엇인지, 왜 필요한지, 그리고 얼마나 필요한지에 대해서 알아보았습니다. 현재 이러한 XAI 에 대한 논쟁이 많은데, 일부 AI Scientist (페이스북의 수석 과학자 Yann Lekun 등) 들은 통계적 신뢰가 절대적 신뢰가 될 수 있다고 주장하며 엄격한 테스트를 통해서 Explainability 를 대체할 수 있다고 말하고 있습니다. 또 반대로 다른 AI Scientist (Microsoft Research 의 Rich Caruana 등) 들은 통계적 신뢰가 절대적 신뢰가 될 수 없다고 말하며 설령 그게 되더라 하더라도 신뢰 이상의 악의적인 공격에 대해서도 안전을 보장받아야 한다고 주장하고 있습니다.
이러한 논쟁과 별개로 실제로 GAN 과 같은 연구 분야에서는 XAI 에 입각하여 Layer 를 On/Off 해가며 어떤 neural layer 가 어떤 이미지를 생성하는데에 기여하는지를 디버깅하는 작업을 실제로 적용하고 있다고 합니다.
XAI Examples
끝으로, XAI 가 필요했던 과거의 상황들에 대한 예시를 간단히 소개하고 마치려고 합니다.
1.
Amazon 의 CV screening
아마존에서는 AI based system 으로 취업 지원서에 대한 합/불 판단을 진행해왔었습니다. 그런데, 남성 지원자가 많아서 상대적으로 합격자도 남성 지원자가 많았고, 합격자들의 공통점들 중에 남성으로써 가지는 공통점들이 많았습니다. 아마존은 결과적으로 남성이라는 항목이 평가에 긍정적인 영향을 준다는 것을 자각하고 이러한 시스템을 폐지했었습니다. 실제로 이 시스템이 존재하는 동안 여성 취업 지원자의 합격자 수가 점점 감소했었기 때문입니다.
그런데 흥미로운 점은 지원서에서 성별을 지우고 구축한 시스템에서도 결과가 크게 다르지 않았습니다. 살펴보니, 남성이라는 항목 자체가 평가에 긍정적인 영향을 준 것이 아니라, 남성들이 주로 보이는 특성 중 하나인 자신감 있고 권위적인 어투의 지원서의 특성이 평가에 긍정적인 영향을 주었던 것이었습니다.
모델이 "지원서의 어투가 자신감 있고 권위적인지에 대한 여부" 를 하나의 주요 평가요소로 특성 삼아서 굴러가고 있었다는 것을 설명할 수 있었다면 일어나지 않았을 사건입니다.
2.
미국의 대출 부과 시스템
미국의 대출 금리 부과는 AI based system 으로 산정되었습니다. 그런데, 일반적으로 라틴계 미국인, 아프리카계 미국인이 6~9 basis points 정도 높게 금리를 부과받았습니다. 실제로 이는 라틴계, 아프리카계 미국인 대출자들의 역사적 데이터의 편중에 의한 결과로 밝혀졌고, 피부색으로 금리를 결정하는 어처구니 없는 상황이 발생했던 것입니다.
모델이 "미국인의 피부색" 이 하나의 주요 평가요소로 특성 삼아서 굴러가고 있었다는 것을 설명할 수 있었다면 일어나지 않았을 사건입니다.
3.
영국이 COVID-19 상황에서 세운 A-LEVEL TEST 에 대한 대안책
영국의 A-LEVEL TEST 는 한국의 수능과도 같은 시험입니다. 그런데, COVID-19 바이러스가 퍼지면서 국제적 단위의 대면 시험을 치르는 것에 무리가 있다고 판단한 영국은 자체 개발한 AI based system 으로 성적을 예측하기로 했습니다. 실제로 교사들의 평가점수와 지난 시험성적을 비롯한 학생 정보에 평가기관의 보정을 거쳐서 시스템을 구현했습니다. 그런데, 공립학교 학생들이 사립학교 학생들보다 실제보다 훨씬 저평가를 받는 상황이 나타났습니다. 결과적으로, 이러한 평가는 학생들의 출신 학교에 대한 보정이 들어갔었고, 많은 학생들이 반발했었습니다. 모델이 "출신 학교" 를 하나의 주요 평가요소로 특성 삼아서 굴러가고 있었다는 것을 설명할 수 있었다면 일어나지 않았을 사건입니다.
Conclusion
이렇게 Explainable Artificial Intelligence 에 대해서 알아보는 시간을 가졌습니다. 지금까지는 기술적인 부분만을 많이 학습 해왔었는데, 오랜만에 이전부터 궁금했던 주제를 조사하여 알아볼 수 있어서 좋았던 것 같습니다. 특히, 악의적인 데이터 조작과 같은 예시가 나중에 실제로 AI 가 실생활의 많은 부분을 대체하게 되었을 때 무서운 부분이라고 느꼈던 것 같고, 이에 대한 대안이나 기준을 세우기 위해 XAI 가 어느정도 필요하다는 사실에 대해서 공감한 것 같습니다. 더불어 실제로 GAN 과 같은 분야에서도 XAI 에 기반한 연구를 어느정도 진행하고 있다는 점에서 연구자나 개발자로써도 어느정도 고려하면 재미있는 연구분야나 개발분야가 나올 수 있지 않을까에 대한 생각도 들었던 것 같습니다. 전반적으로 AI 가 바꾸게 될 미래에 대해서 어느정도 생각을 하면서 살아야겠다는 경각심을 일꺠워 준 시간이었던 것 같습니다.