Binary Linear Classification
•
Input: ,
•
Target: ,
◦
사실 말고 다른 것을 써도 되긴 하는데 (ex. ) 보통 이렇게 많이 설계함
•
로 model 을 설계하고, 와 를 learnable weight 로 설정함
•
prediction
◦
WLOG, 으로 설정할 수 있음
•
결국 Binary Linear Classification 문제는 다음과 같이 정의됨
How to define Loss Functions for Classification
•
First Attemp: 0-1 Loss
◦
맞으면 loss 가 0, 틀리면 loss 가 1
◦
Averaged Loss
◦
Limitation
동일한 판단을 하는 모든 결정경계가 동일한 loss 를 가지기 때문에 거의 모든 영역에서 gradients 가 0 이고 를 optimize 할 수 없음!
•
Second Attemp: Squared Error Loss (from Linear Regression)
◦
그냥 naive 하게 true 값과의 차이를 통해 penalize
◦
인 경우에 true 로 예측
◦
Limitation
Decision boundary 가 데이터 의 크기에 영향을 받고, 극단적으로 크기가 큰 데이터가 존재함에 따라 decision boundary 가 정상적으로 잡히지 않을 수 있음!
•
Third Attemp: (Binary) Cross Entropy
◦
Sigmoid Function
▪
산출값을 0~1 사이로 bounding 시킬 수 있음
◦
산출값에 sigmoid 를 씌워 0~1 사이로 bounding 하고, 0.5 를 기준으로 thresholding 할 수 있음! (sigmoid 에서 0.5 thresholding 은 에서 0 thresholding 과 같음)
◦
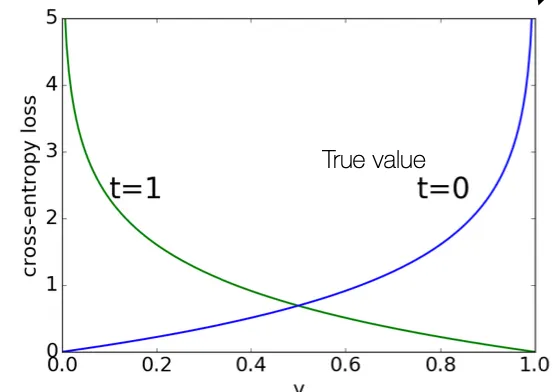
인데, 일 떄는 가 0 에 가까울 때 크게 penalize 하고 일 때는 가 1 에 가까울 때 크게 penalize 함
◦
Sigmoid 이후 squared error 를 쓰는 것보다는 optimization 속도가 빠르다는 장점이 있음 ( 값이 0 ~ 1 사이에서 절댓값이 크기 때문에…)
Recall: Cross Entropy in Kullback-Leibler (KL) Divergence
•
두 distribution 와 의 차이를 측정할 수 있는 지표
◦
항목이 cross entropy 였음
◦
구해낸 함수 가 얼마나 와 다른가를 측정하는 지표
Multi-class Classification
•
Logistic Regression 을 다중 categories 로 generalize 해야 함
•
산출 값이 여러 개가 될 것인데, 이들을 one-hot vector 형태로 바꾸기 위해서 maximum 을 1 로 나머지를 0 으로 바꾸는 방법이 있을 수 있음.
◦
하지만, 이 방법은 differentiable 하지 않아 optimize 할 수 없음
•
Softmax Function
◦
Softmax 를 거친 벡터의 각 항목을 더하면 1 이 됨
◦
Max function 의 soften 버전이라고 보아도 됨
◦
의 경우에 softmax 는 sigmoid 형태가 됨
•
Cross Entropy Loss
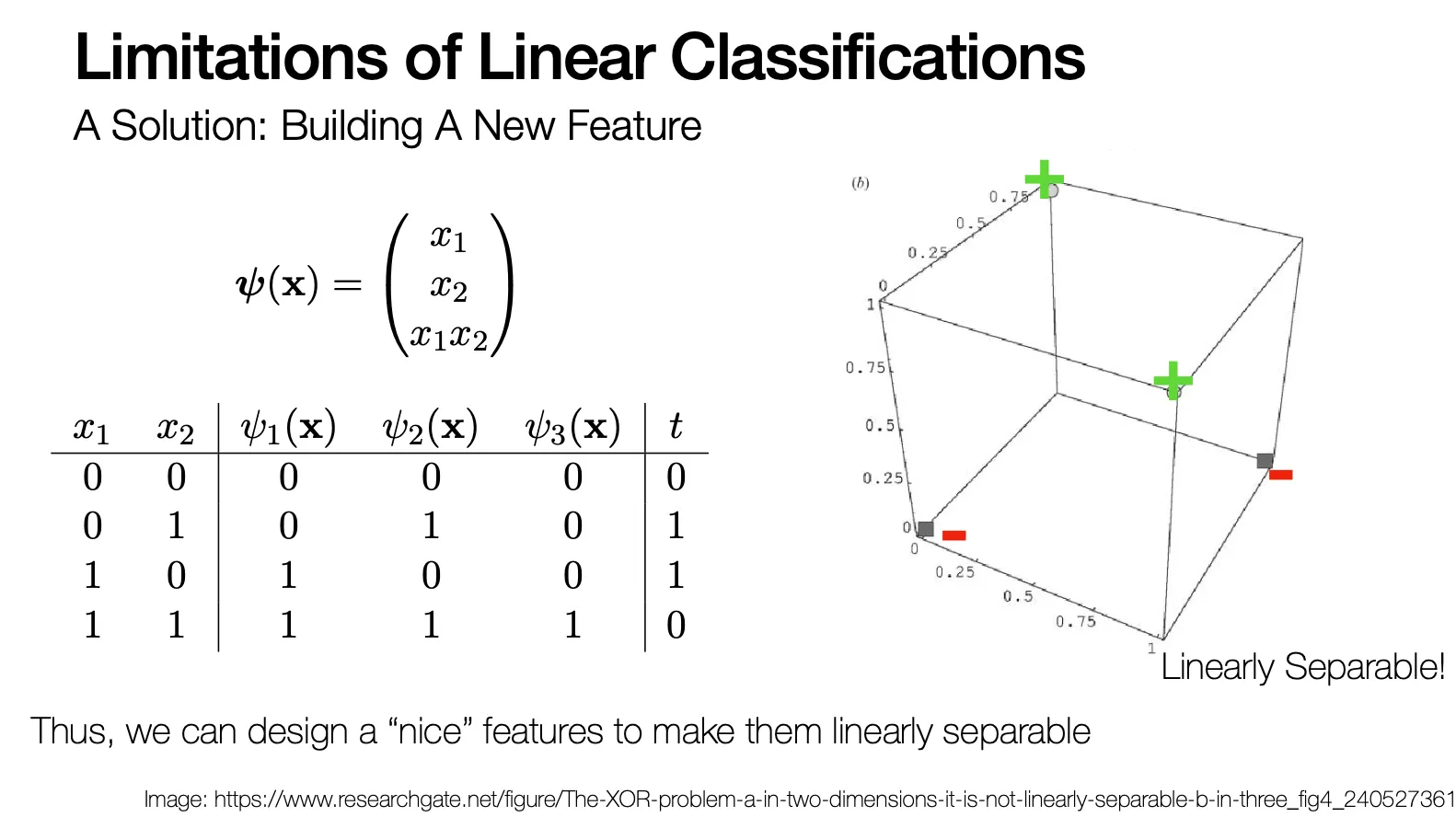
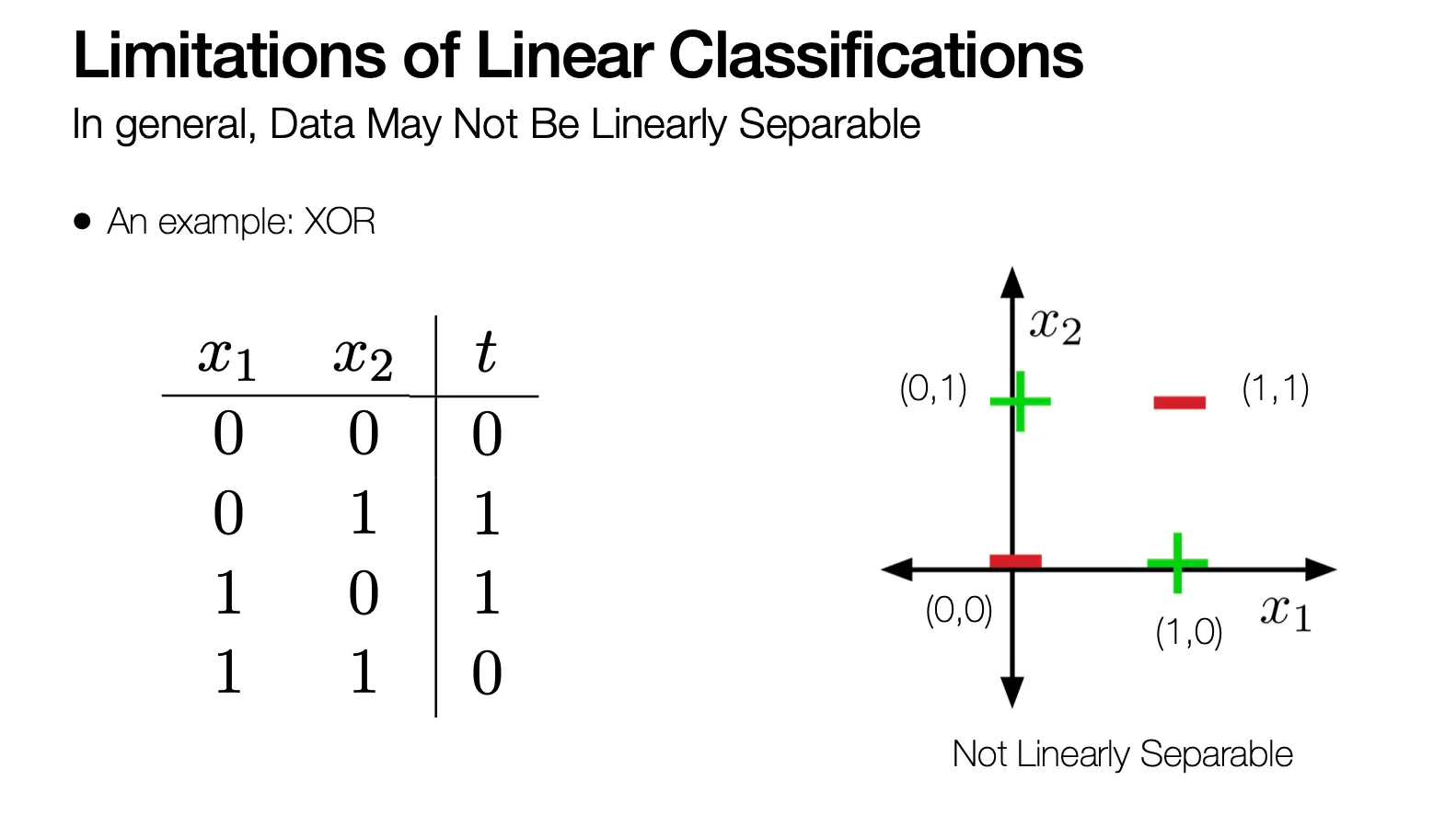
Limitations of Linear Classifications
•
실제 상황에서는 데이터가 linear 하게 separable 하지 않을 수도 있음 (ex. XOR)
•
이러한 상황에서 새로운 feature 를 만드는 형태로 해결할 수 있음 (차원을 추가하여 linearly separable 하도록 만들어버림)