
Objective
복잡하고 Subtle 한 Human Object Interaction 를 Post-Hoc Optimization (Physical Prior) 없이, Mesh 기반의 데이터로 생성해낸 것이 Contribution.
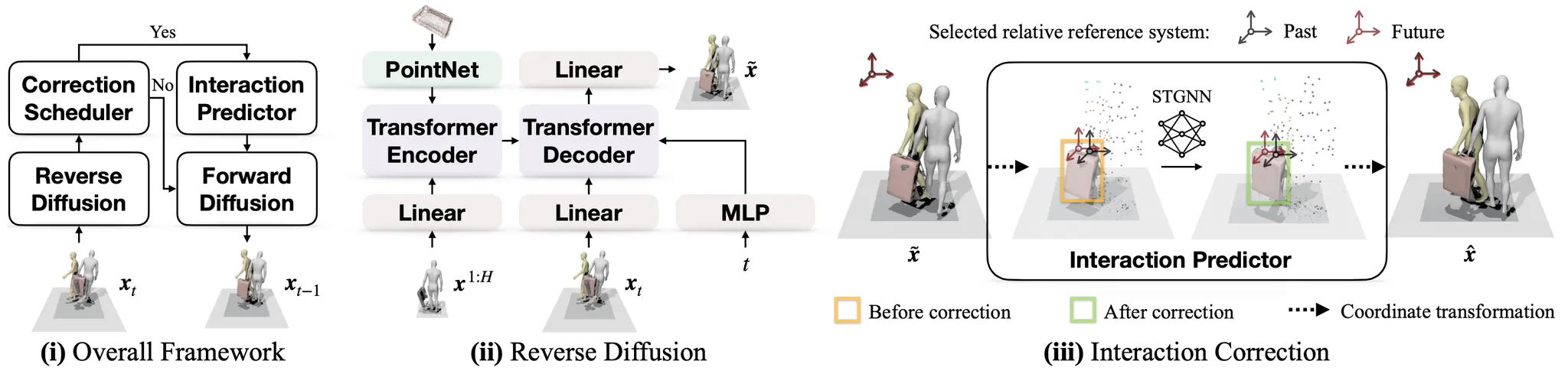
의 historical frames 를 입력으로 받아 를 생성하는 것이 목적으로, 각 는 Human Pose 와 Object Pose 로 구성되어 있다.
Method
1.
Reverse Diffusion
Transformer 구조의 encoder 로 입력 sequence 를 encoding 하고, PointNet 으로 object 의 shape embedding 을 찾아내어 time step 의 positional embedding 과 함께 decoder (diffusion 의 denoiser) 의 condition 으로 삽입하여 estimated human pose & object pose 를 뽑아낸다.
2.
Correction Scheduler
Reverse Diffusion 으로 Estimated 된 Human pose & Object pose 가 적절한지 판단한다. 이 때 사용되는 것이 Contact 와 Penetration 정보이다.
Penetration 은 Human 의 SDF 상에서 object 의 vertices 를 query 했을 때 등장하는 최솟값 과 0 중 작은 값에 - 를 붙여 Human Penetration 이 있으면 + 가 되도록 한다. 이 값이 threshold 보다 크면 Penetration 이 심한 것으로 판단한다.
Contact 는 Human 의 각 vertices 마다 Object 의 vertices 들 중 가장 가까운 점과의 거리를 구해, 이것의 최솟값이 threshold 보다 크면 contact 이 안 이루어진 것으로 판단한다.
Contact 과 Penetration 여부와 관계없이 다음 Interaction Predictor 의 사용여부를 결정할 수 있다.
3.
Interaction Predictor
Predefined Markers 를 human vertices 중 지정하고 이를 potential reference points 로 지정한다. 만약 앞서 Correction Scheduler 에서 Contact 가 없다고 판단했으면 Default Ground Reference System 을, 있다고 판단했으면 가장 가까운 contact 을 가지는 marker points 를 Reference System 으로 채택한다.
개의 markers 기준으로 나머지들의 sequence 동안의 sequence, 그리고 채택한 reference 기준으로의 sequence 를 합친 그래프 를 STGNN 에 넣어 future sequence 를 뽑아내고 이 중에서 reference 기준의 것을 로 가져와 ground system 으로 transform 하고, 이를 기존 estimation 과 blend 하여 보정한다.
이러한 Reference System 변환은 Contact Point 를 기준으로 한 motion 은 일반적으로 Simple Motion 임에 기인하여 STGNN 네트워크가 더 잘 학습될 수 있다는 점에 영감을 받아 진행한 것이다.
4.
Forward Diffusion
Langevin Dynamics 에 따라 estimated 된 motion 을 기준으로 sampling 하여 다음 을 얻어낸다.