Contribution
1.
Hybrid Explicit-Implicit 3D representation 을 사용하여 표현력의 손실 없이 fully implicit / excplicit 을 사용하는 접근보다 speed 와 memory 적 improvement 를 가져옴.
2.
3D-grounded rendering 을 여전히 사용하긴 하지만, Dual Discrimination Strategy 를 도입하여 view-inconsistent 한 경향성을 줄였음.
3.
Generator 에 Pose-based Conditioning 을 추가하여 pose 와 관련있는 속성들을 분리하여 inference 단에서 multi-view consistent 한 결과를 얻어내도록 함.
Methods
Tri-Plane Hybrid 3D Representation
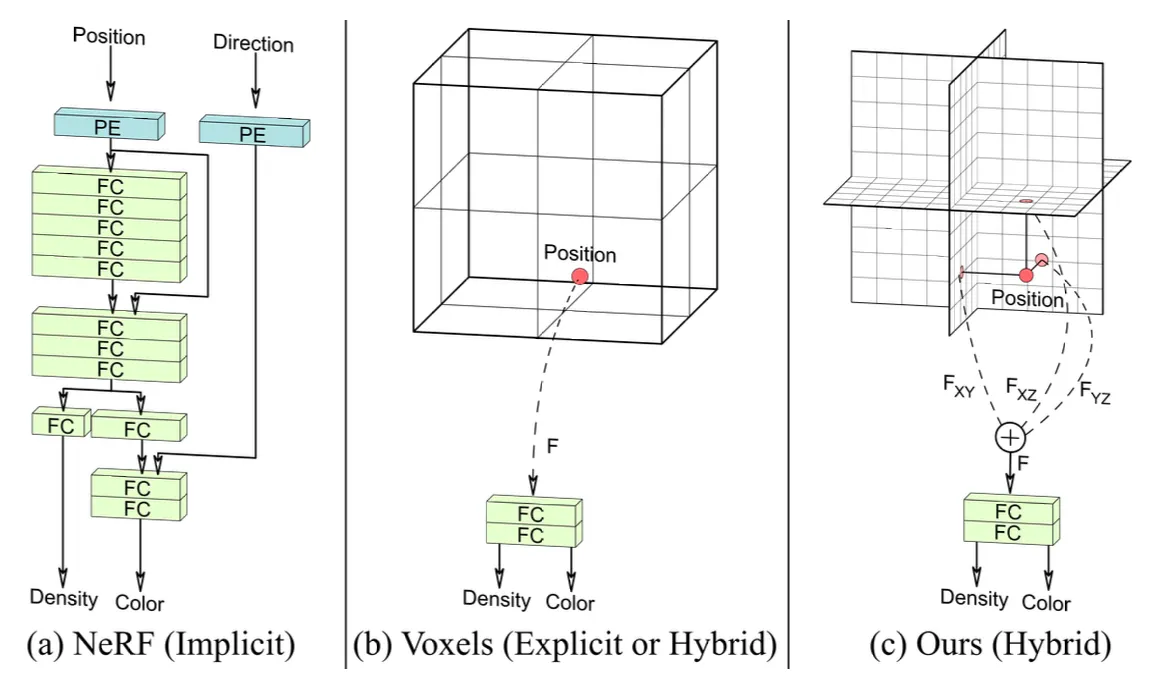
3 개의 orthogonal plane 를 정의하여 3차원 점에서 각 plane 에 projection 한 points 들의 값을 bilinear intepolation 으로 구하고 각 로 지칭함.
이들 feature vectors 를 summation 한 vector 를 입력으로 하여 Tri-Plane Decoder 를 통과시킨 후에 해당 점의 Color 와 Density 를 얻어냄.
이러한 설계의 장점은 FC 단을 가볍게 만들어 memory 나 inference speed 에 있어서 장점을 가져가면서도 explicit 한 representation 을 크게 가져가서 표현력을 줄어들지 않는다는 점임.
Dual Discrimination
Super Resolution 을 사용했을 때 나타날 수 있는 low resolution 과 high resolution image 의 inconsistency 문제를 targeting 할 수 있는 방법론.
Neural Rendering 되어 나타난 Feature Map 으로부터 low resolution image 를 형성하고 이 정보와 super resolution 된 image 가 결합되어 discriminator 에 들어가게 되어 두 이미지가 모두 real world domain 에 속하도록 되는 효과임.
Pose-Correlated Attributes
FFHQ 와 같은 데이터셋을 기반으로 학습을 하게 되면 pose 와 facial expression 이 correlated 되는 현상을 해결하기 위한 방법론.
Camera Pose 를 generator 와 discriminator 에 추가적으로 넣어주는 방법으로 feature map 의 표현력이 camera pose 로 가지 않을 수 있도록 함.
3D GAN Framework
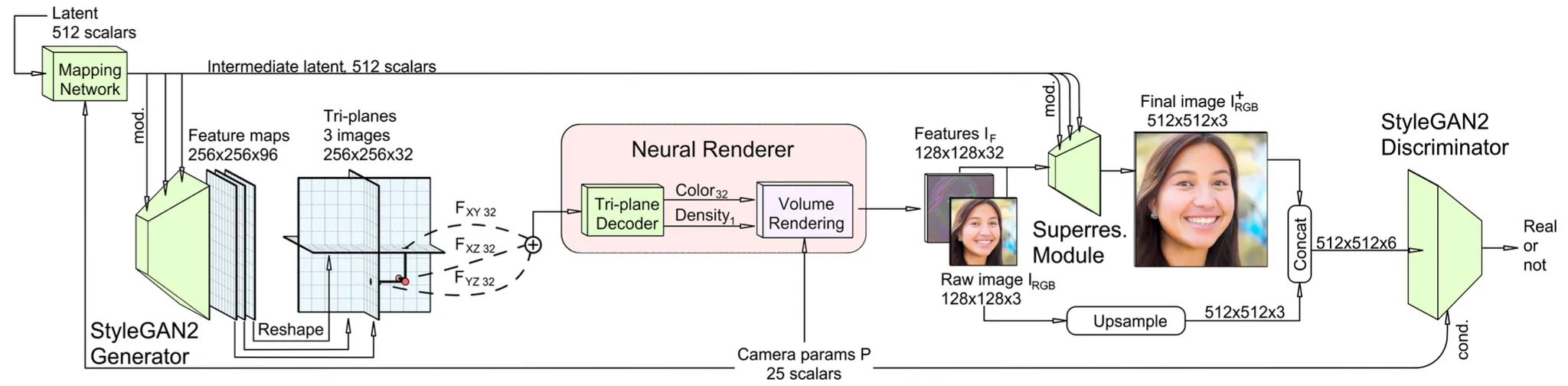
StyleGAN2 generator backbone 을 수정하여 의 feature map 을 산출하도록 변경
의 feature map 을 3 개의 orthogonal 한 plane 으로 reshape 함.
각 coordinate 별 feature 를 뽑아내어 summation 을 해 Tri-Plane Hybrid 3D Representation 을 구성함.
MLP 로 구성된 Tri-Plane Decoder 를 통과시켜 32 dimension 인 color 와 density 를 뽑아냄.
Volume Rendering 을 통해 의 feature image 를 구성함.
Super Resolution Module 로 feature image 로 부터 high resolution rgb image 구성함.
의 첫 3 개의 feature map 을 low resolution rgb image 인 로 취급하고 이를 bilinear upsampling 한 것과 와 concatenate 하여 의 6 channel image 를 형성함.
해당 6 channel image 를 StyleGAN2 discriminator 를 통과시킴.