
Newton’s Method
•
주어진 함수 을 만족하는 해를 찾는 방법론
•
가장 naive 한 approach 는 를 정의하고 해당 크기만큼 변형해가면서 함수값을 측정하는 것
◦
양에서 음, 음에서 양으로 변하는 지점에서 해가 존재함.
◦
단점
▪
가 너무 작은 경우에는 알고리즘이 오래걸림.
▪
가 너무 크면 해가 2개 있을 때 하나만 찾고 지나쳐버릴 수도 있음.
•
Newton’s Method
1.
적절한 initial guess 에서 시작점을 잡음.
2.
를 해당 initial guess point 를 기준으로 tangent line 으로 근사하여 해석함
3.
근사한 tangent line 의 해를 다음 guess 으로 설정함.
4.
수렴할 때까지 1 ~ 3 을 반복함.
•
Optimization 문제를 풀 때 해를 구하는 것을 중요한 과정이 됨.
◦
Minimize → Find root for
General Problem of Image Registration
•
Template Image 와 Input Image 가 주어짐.
•
Image Registration 문제의 종류들은 다음과 같은 것들이 있었음.
1.
Image Alignment: 한 이미지 에서 다른 이미지 로 warping 하여 가장 좋은 match 를 찾는 경우
2.
Tracking: 는 시각에 점 근처의 (tracking 하고자 하는) 작은 영역 이고, 는 시각의 이미지인 경우
3.
Optical Flow: 와 각각이 , 시각의 이미지 영역이고 움직임을 시각정보만으로 예측하는 경우
•
카메라가 이동하면서 물체를 찍은 경우에는, 바뀐 카메라의 image plane 상으로 warping 을 한 다음에 matching 을 하는 것이 올바른 순서임.
Simple Approach (for Translation)
•
Sum of Squared Distances 를 최소화하는 , 를 구함.
•
단점
◦
효율적인 알고리즘이 아님. ( 상의 모든 location 에 대해서 SSD 를 모두 구해야 하기 때문임)
◦
Sub-pixel Accuracy 를 측정할 수 없음. (픽셀 단위 이하의 정확도를 구할 수 없음)
Lucas-Kanade Tracking
•
Object Tracking
◦
이전 frame 에 대해서 이미지 내에서 template 의 위치가 주어졌을 때, 다음 frame 에서의 template 의 위치를 구하는 문제
•
Frame 간 간격이 좁다고 가정하면 , 가 작다고 가정할 수 있고, Taylor Expansion 을 적용해볼 수 있음.
•
원래 Sum of Squared Distance 식에 위의 변형을 대입하면 다음과 같음.
•
SSD 를 최소화하기 위해 미분하면 다음과 같음.
•
위 식을 , 만 LHS 에 남기면 다음과 같이 변형할 수 있음.
•
최종적인 Matrix Form 으로 다음과 같이 표현할 수 있음.
One Problem with Lucas-Kanade
•
Initial frame 에 대해서 Tracking 하고자 하는 object 가 template 이 되어서 연속적인 frame 에서 찾아가는 방법인데, 물체를 바라보는 viewpoint 가 바뀌면 잘 동작하지 않음.
•
Warping 까지 고려한 일반화된 Lucas-Kanade Tracking 이 필요함.
◦
라는 parameter 를 가지는 warping 을 이용해서 point 를 변환시키고 해당 warped image plane 상에서의 위치 차이를 계산함.
◦
좋은 warping parameter 인 를 계속 찾아나가야 함. ( 로 정의되는 warping 은 translation 은 물론 homography 를 포함하기 때문에 , 를 포함하는 일반적인 개념임)
Lucas-Kanade Algorithm (Generalized ver.)
•
와 의 SSD 를 최소화하하도록 align 하는 warping parameter 를 찾아야 함.
◦
를 최소화하는 를 찾아야 함
•
Examples
◦
Warping = Translation
◦
Warping = Affine
•
가 에 대한 선형적인 함수로 표현이 되지 않기 때문에 Non-Linear Optimization 을 풀어야 함.
•
Tracking 같은 경우에는 많은 경우에 Affine Transform 으로 가정해도 충분함. → 6DoF
◦
처음 시작 위치에서는 Template 의 위치가 주어지기 때문에 으로 설정함.
◦
다음 시각 때부터는 정확한 가 아닌 에 대해서 구함.
Parametric Model
•
First Order Taylor Expansion 을 적용하여 를 변경할 수 있음.
•
에 비해서 항목이 충분히 작다는 가정 하에서 다시 한 번 First Order Taylor Expansion 을 사용할 수 있음.
•
최종적인 목표는 다음과 같이 변형됨.
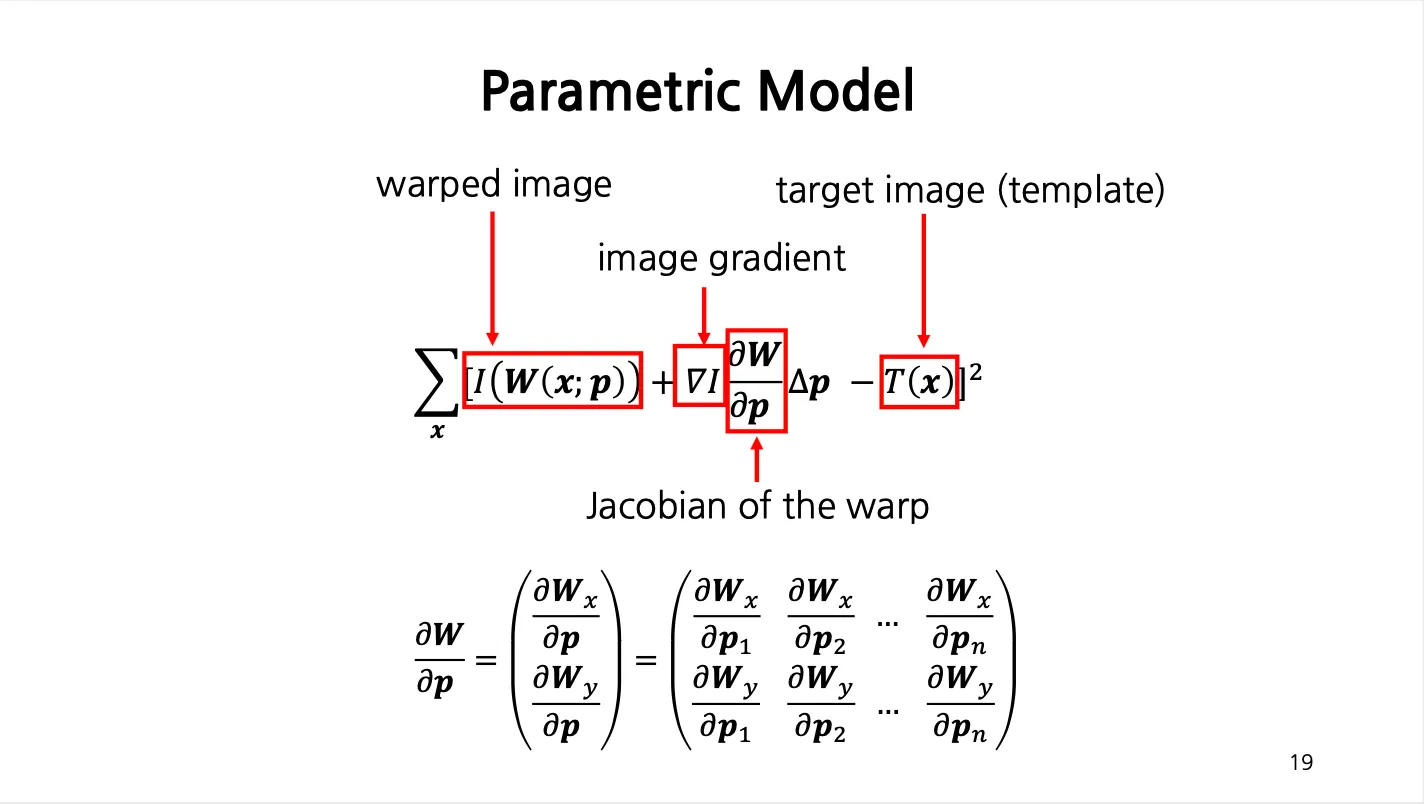
Jacobian Matrix
•
에 대한 미분은 derivative
•
에 대한 미분은 gradient
•
에 대한 미분은 jacobian
Jacobian of the Warp
•
Example - Affine Transform
Parametric Model
•
에 대한 편미분을 통해 minimum 을 찾음.
•
만 LHS 에 남기고 식을 정리하면 위와 같이 나타남.
•
각각의 step 마다 를 위와 같은 식으로 구해냄.
Lucas-Kanade Algorithm
1.
Warp with to
2.
Compute error image
3.
Warp gradient of to compute
4.
Evaluate Jacobian
5.
Compute Hessian
6.
Compute ,
7.
Update parameters
Tracking Facial Mesh Models
•
Active Appearance Model 로, Face Tracking 에 많이 씀.
1.
얼굴에 많은 landmark point 및 mesh 를 가정함
2.
Deformation 을 허용하되, 많이는 허용하지 않는 채로 움직임을 tracking 함.
Errors in Lukas-Kanade
•
가정이 위반될 때 오류가 발생함.
1.
Brightness Consistency 가 지켜지지 않을 경우 (corresponding point 가 다음 frame 에서 다르게 보이는 경우)
2.
Taylor Expansion 이 적용되지 않는 경우 - The motion is not small
3.
Occlusion 이 있는 경우