



Occupancy Networks
•
3D Location. Condition → Occupancy Probability 인 네트워크를 정의할 수 있음.
◦
: 3D Location, : Condition
◦
Condition 을 넣는 이유는 하나의 네트워크로 다양한 category 등을 나타내고 싶어서임.
◦
Surface Implicity 를 non-linear classifier 의 decision boundary 로 사용할 수 있음.
•
해당 function 을 occupancy field 로 부름.
Network Architecture
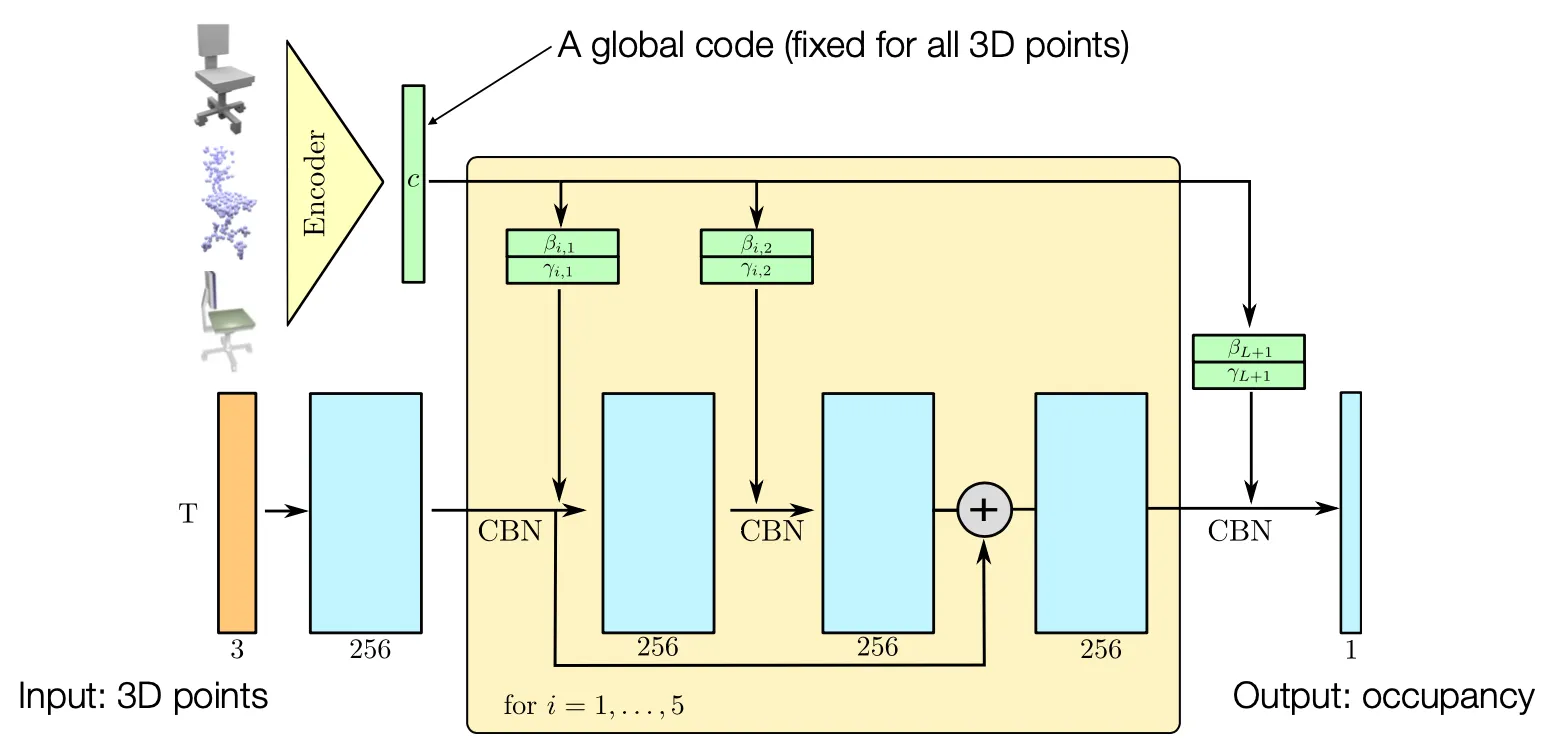
•
3D points 가 입력으로 들어가서 occupancy 가 출력으로 나옴.
◦
는 batch size
•
Global code 가 encoder 로 들어가서 conditioning 을 해주어 하나의 category 만 사용해서 네트워크가 구조를 외우는 현상을 해결하고 여러 category 를 지원하도록 설계함.
◦
Encoder 의 경우 Image → ResNet, Point Cloud → PointNet 등을 사용할 수 있음.
Training Objective
•
: Randomly Sampled 3D Points
•
: Encoder
•
앞 항은 Ground Truth 와의 비교 항목이고, 뒷 항은 encoder 의 latent space 를 prior (보통 normal distribution) 으로 유도하기 위한 항목임. → Sampling purpose 측면에서 좋은 트릭임!
Multiresolution IsoSurface Extraction (MISE)
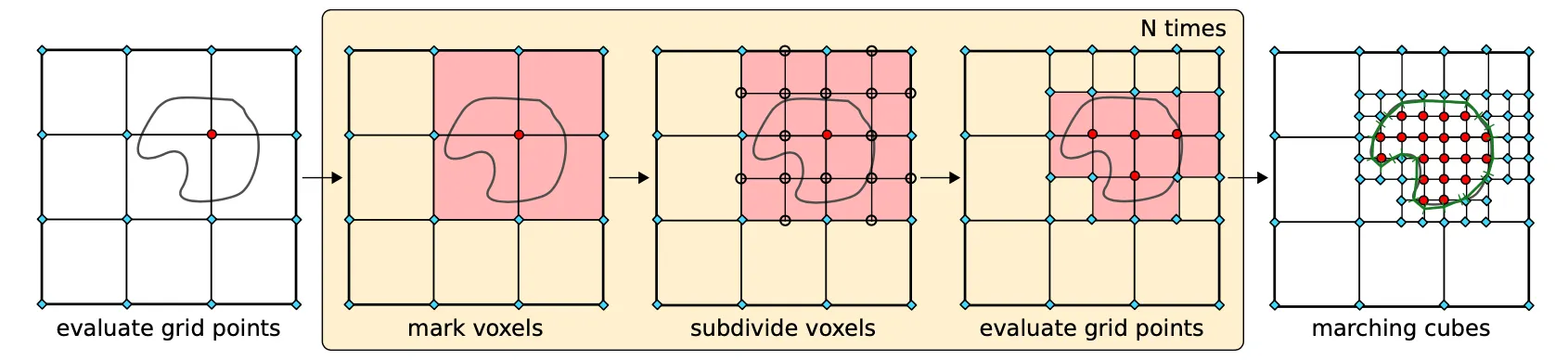
•
Naive 한 marching cube 방법론은 시간이 오래 걸림.
•
크게 먼저 grid 를 자르고, 모든 점이 occupied 되어있지 않다면 그 안에는 없는 것으로 판단하고 세부적으로 조사를 안 해보아도 됨.
•
세부적으로 나누어진 영역에 대해서만 marching cube 를 적용할 수 있음.
DeepSDF Network
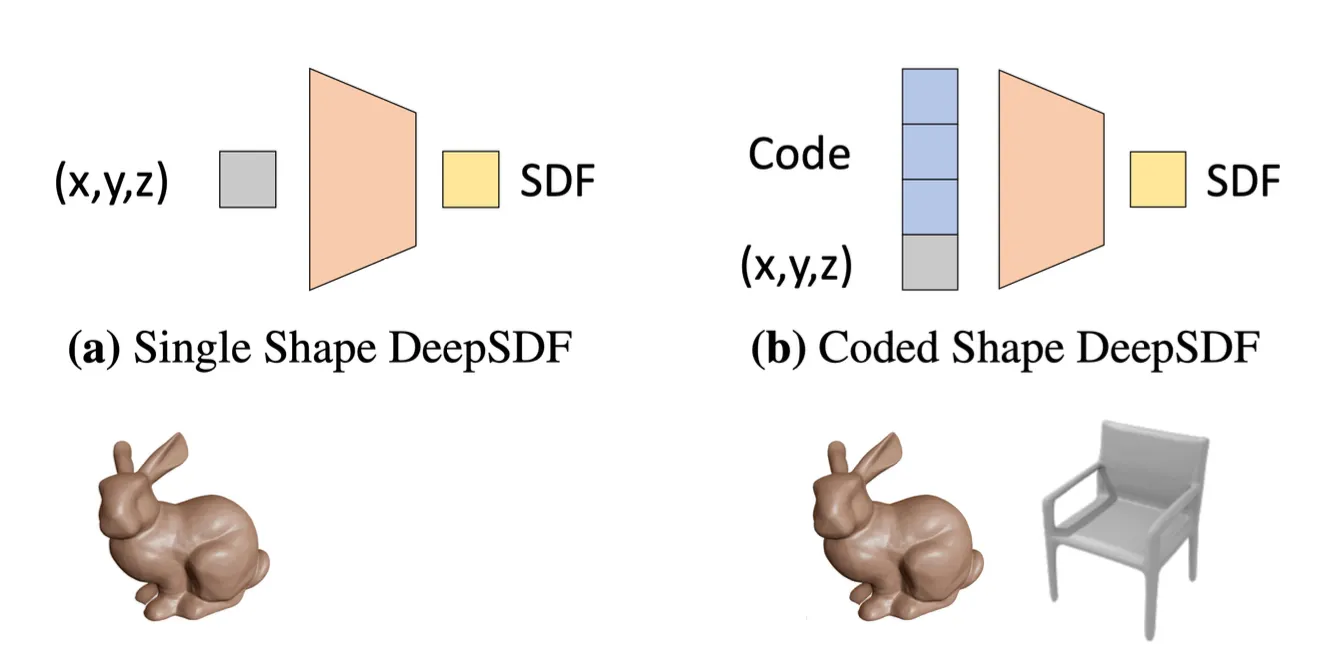
•
기존의 접근과 다른 점은 output 이 occupancy 가 아니라 signed distance function 이라는 점임.
•
기존과 또 다른 점은 conditioning code 가 입력과 concatenate 되어 들어가게 됨.
•
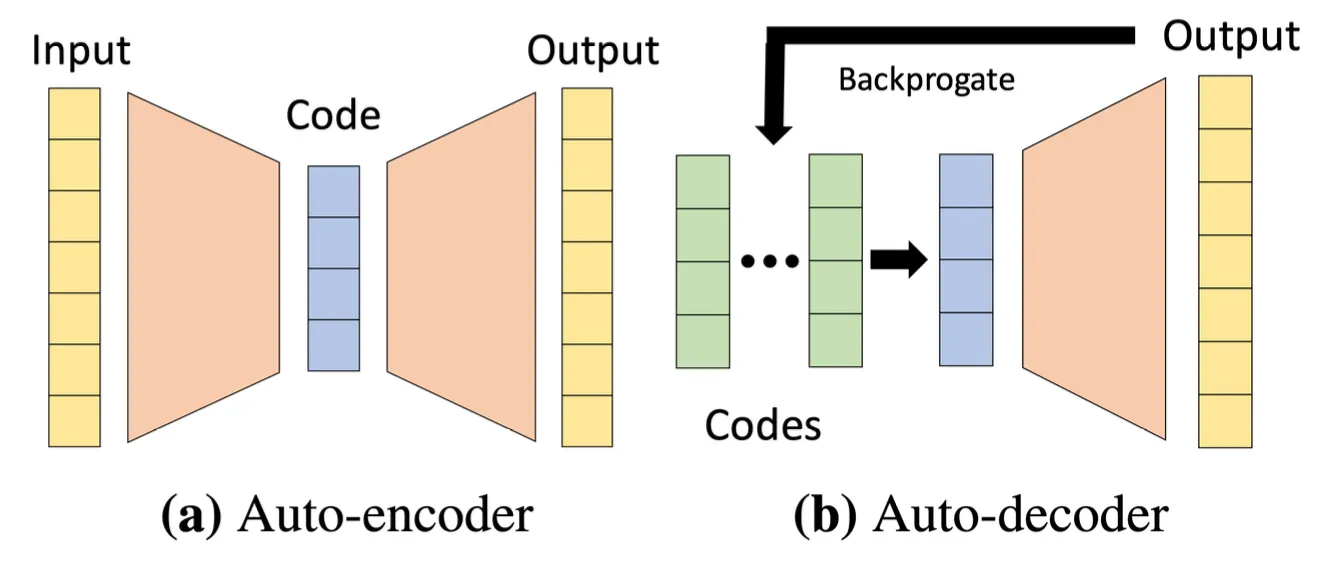
Code 를 direct 로 optimize 하는 방법론을 사용함. (Auto-decoder)
◦
단점은 testing time 에도 code 를 optimize 해야 함.
◦
Ground truth 로 code 를 optimize 한 뒤에 해당 code 기반으로 signed distance function 을 뽑아냄. → code 를 기반으로 signed distance function 을 뽑는 능력은 이미 seen data 로 학습이 되었고, code 를 ground truth 기반으로 생성하는 것임!
•
치명적인 한계점은 단순한 물체에 대해서는 잘 동작하지만 complex scene 에 대해서는 잘 동작하지 못하다는 점임.
Convolutional Occupancy Networks
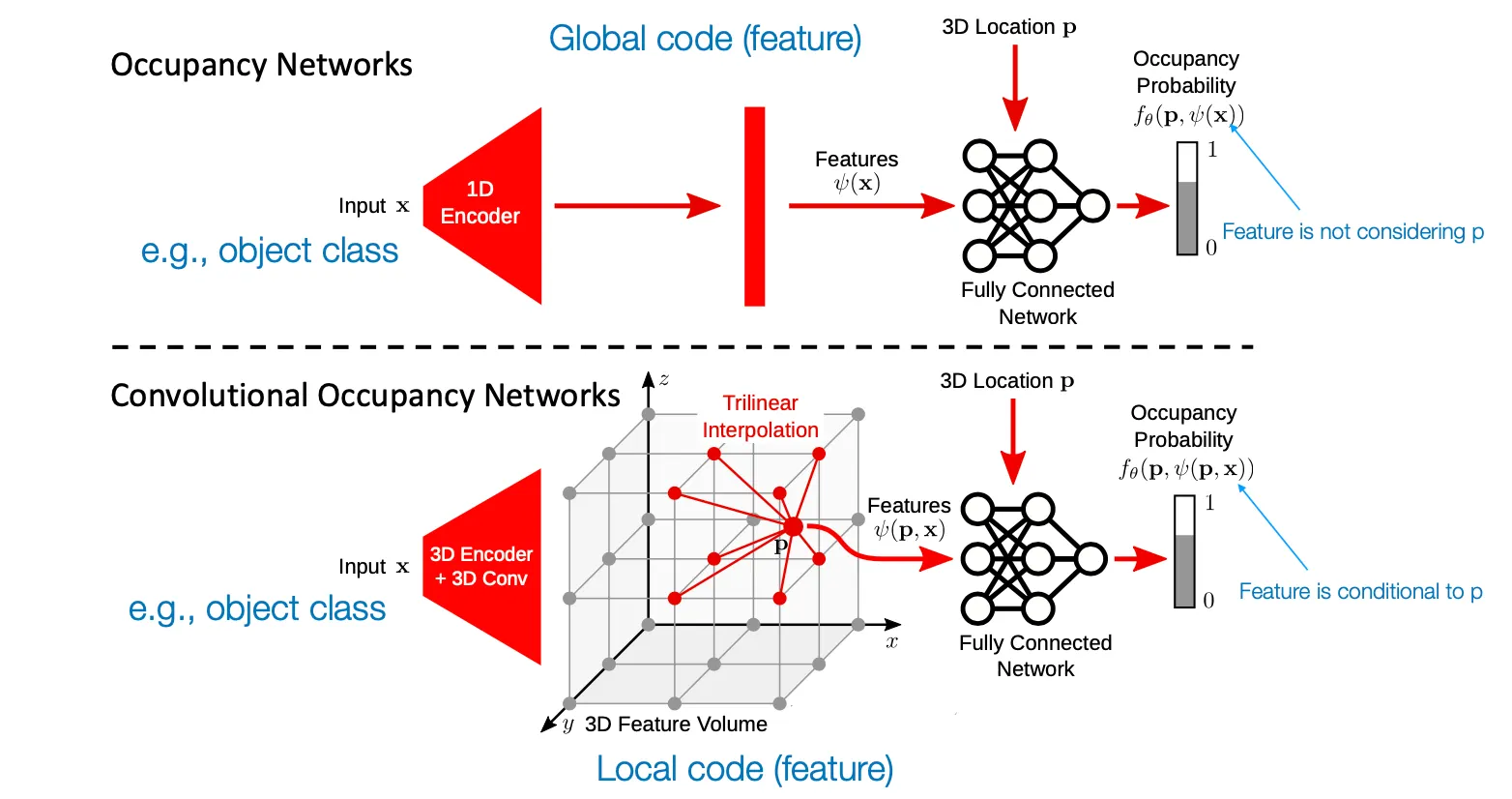
•
Complex scene 에 대해서 동작하지 않던 DeepSDF 의 문제점을 해결하기 위해 local 한 feature 가 point 에 dependent 하도록 설계함.
PIFu
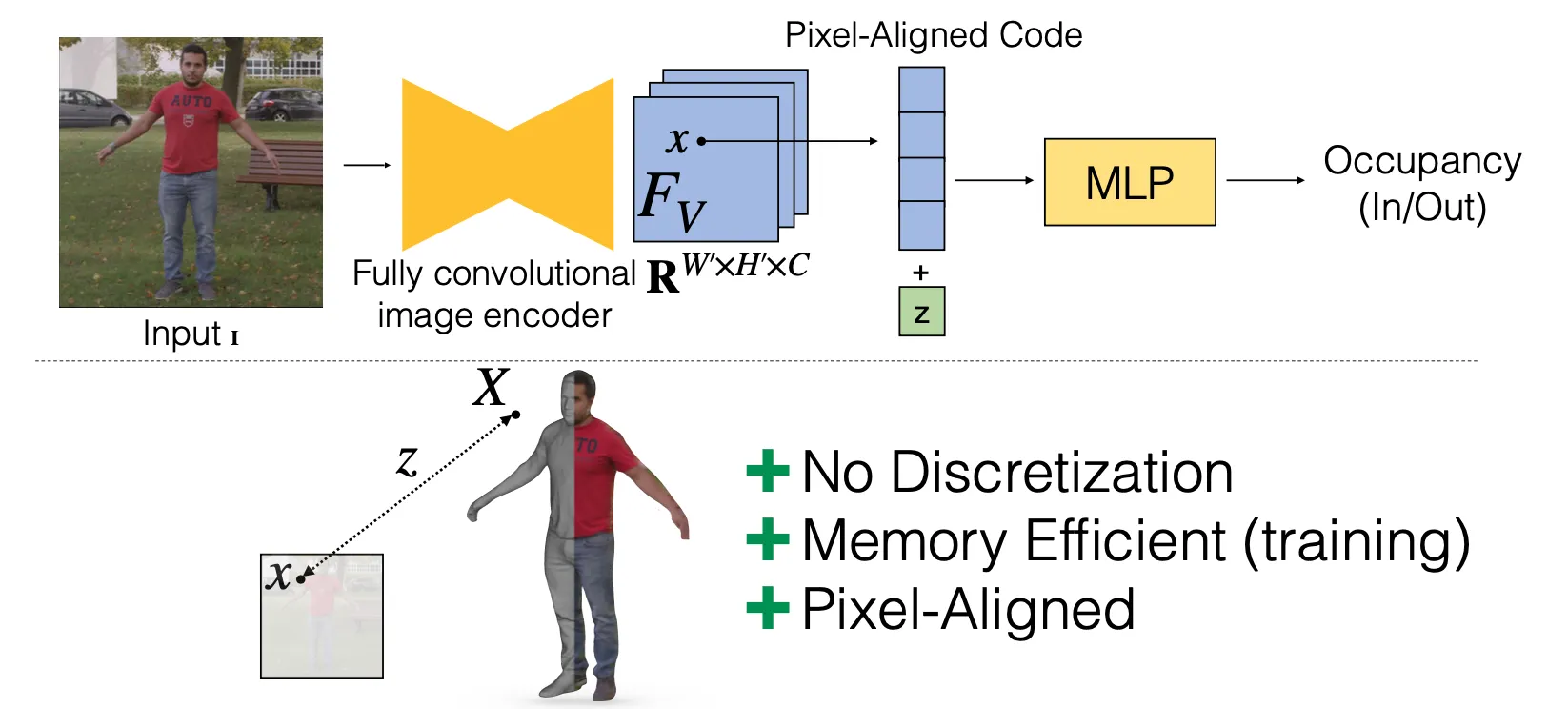
•
Global code 대신에 fully convolutional image encoder 를 통과한 feature 기반의 code 를 사용한 것이 기존의 work 들과의 차이점임.
•
원하는 position 일대의 latent vector 를 얻고 depth 를 concatenate 하여 MLP 를 통과시킨 후 occupancy 를 얻어낼 수 있음.
PIFuHD: Multi-Level Representation
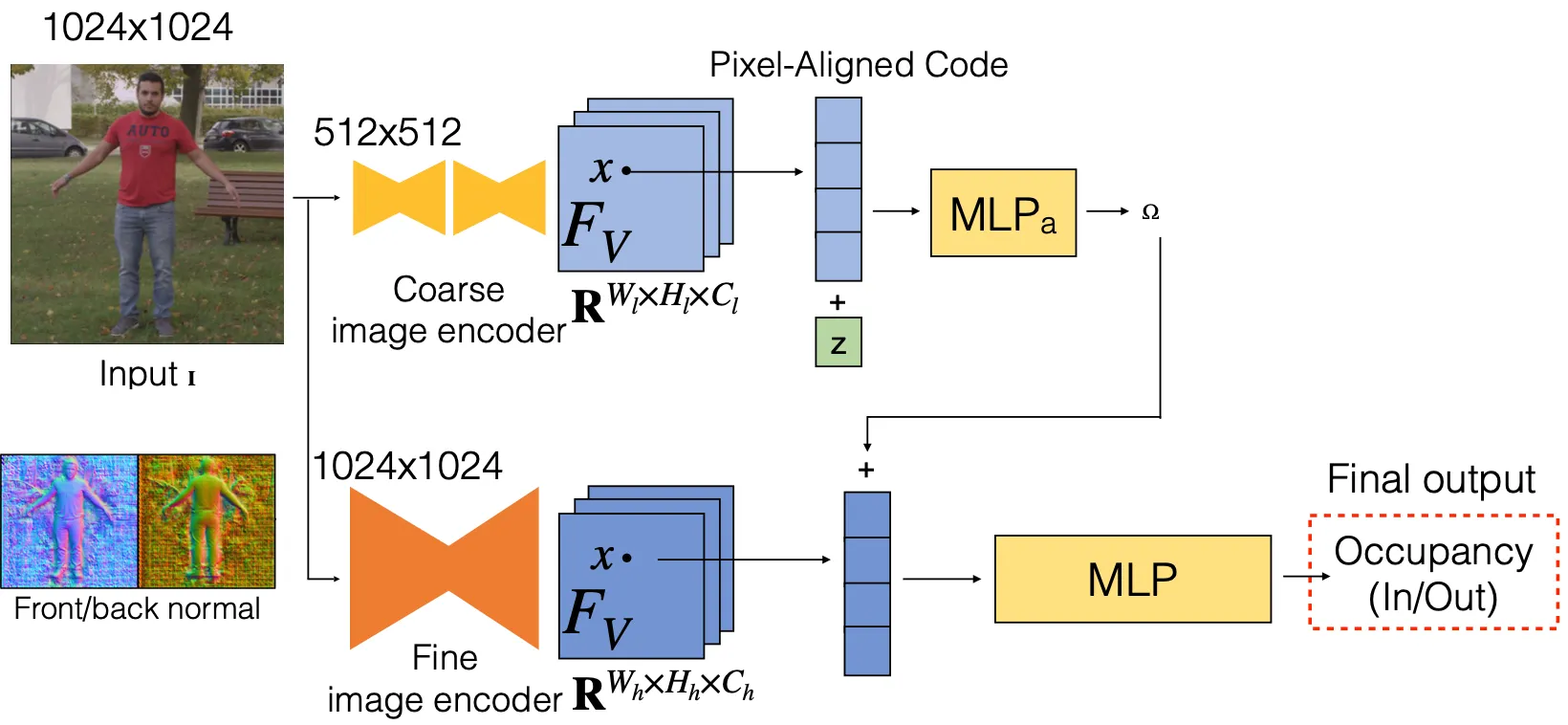
•
얼굴에 대한 detail 을 챙길 수 없었던 기존의 문제점을 해결하기 위해, heirarchical 하게 global 및 local part 를 나누어서 동일한 파이프라인을 설계한 뒤 concatenate 하는 방법론을 사용해봄.
•
사실 이미 PIFuHD 는 silhouette 만으로도 잘 됨. 이는 human 에 대한 prior 를 이미 네트워크가 가지고 있었던 것임. → 다만 서 있는 human 만 잘 되었음.