



Recap: Eigenvalues and Eigenvectors
•
Square Matrix 의 eigenvector 는 다음을 만족하는 nonzero vector 로 정의함.
•
이 때 가 해당 eigenvector 에 대응되는 eigenvalue
•
가 eignvector 이면 rescaled vector 도 eigenvector 가 되기 때문에 eigenvector 의 크기를 1 로 정의함. ()
Recap: Singular Value Decomposition (SVD)
•
matrix 에 대해서 SVD 는 다음과 같이 factorization 됨.
◦
는 orthonormal matrix (column 이 eigenvector)
◦
는 orthonormal matrix (row 가 eigenvector)
◦
는 diagonal matrix ()
Relation between SVD and Eigenvalue Decomposition
•
라고 할 때, 는 다음과 같음.
◦
는 vector 로, 개까지의 eigenvalue 의 제곱이 각 대각성분에 있는 matrix 임. (나머지는 0 으로 채워짐)
◦
마찬가지로, 이고, 여기서의 는 임.
◦
즉, 와 는 각각 , 의 eigenvector 로 구성된 matrix 임.
◦
, 의 eigenvalue 는 singularvalue 의 제곱임. ( 가 eigenvalue decomposition 의 diagnoal matrix 가 되기 때문!)
Variance
•
•
•
•
제곱의 평균 - 평균의 제곱
Covariances
•
•
◦
Covariance Matrix 과 다름!
◦
, →
•
Covariance Matrix 는 Symmetric 하고 Positive Semidefinite
Principal Component Analysis (PCA)

•
높은 차원의 데이터를 유의미한 것만 남기고 차원을 줄일 수 있는 방법론
•
가장 정보를 많이 잃지 않으면서 차원을 낮추는 방법 → Variation 이 가장 큰 방향으로의 Projection
•
방향으로의 projection 을 가정했을 때 projection 후의 variance? ()
•
해당 variance 를 크게 하는 는 eigenvector of largest eigenvalue of
◦
최대값을 만드는 의 후보군은 의 eigenvector
◦
eigenvector 에 대해 는 eigenvalue 를 가지고, 최댓값은 최대 eigenvalue
◦
variance 를 가장 크게 만드는 는 가장 큰 eigenvalue 를 가지는 eigenvector
◦
형태이므로 로 SVD 를 적용한 뒤에 의 largest singular vector 를 찾는 것과 같음…!
•
PCA 를 통해서 variance 를 기준으로 변경된 차원들의 축은 각 eigenvector 이며, N 개의 차원을 줄이고 싶다면 가장 작은 eigenvalue 를 가지는 N 개의 eigenvector 를 제거하면 됨! (축 제거)
Additional: EigenFaces
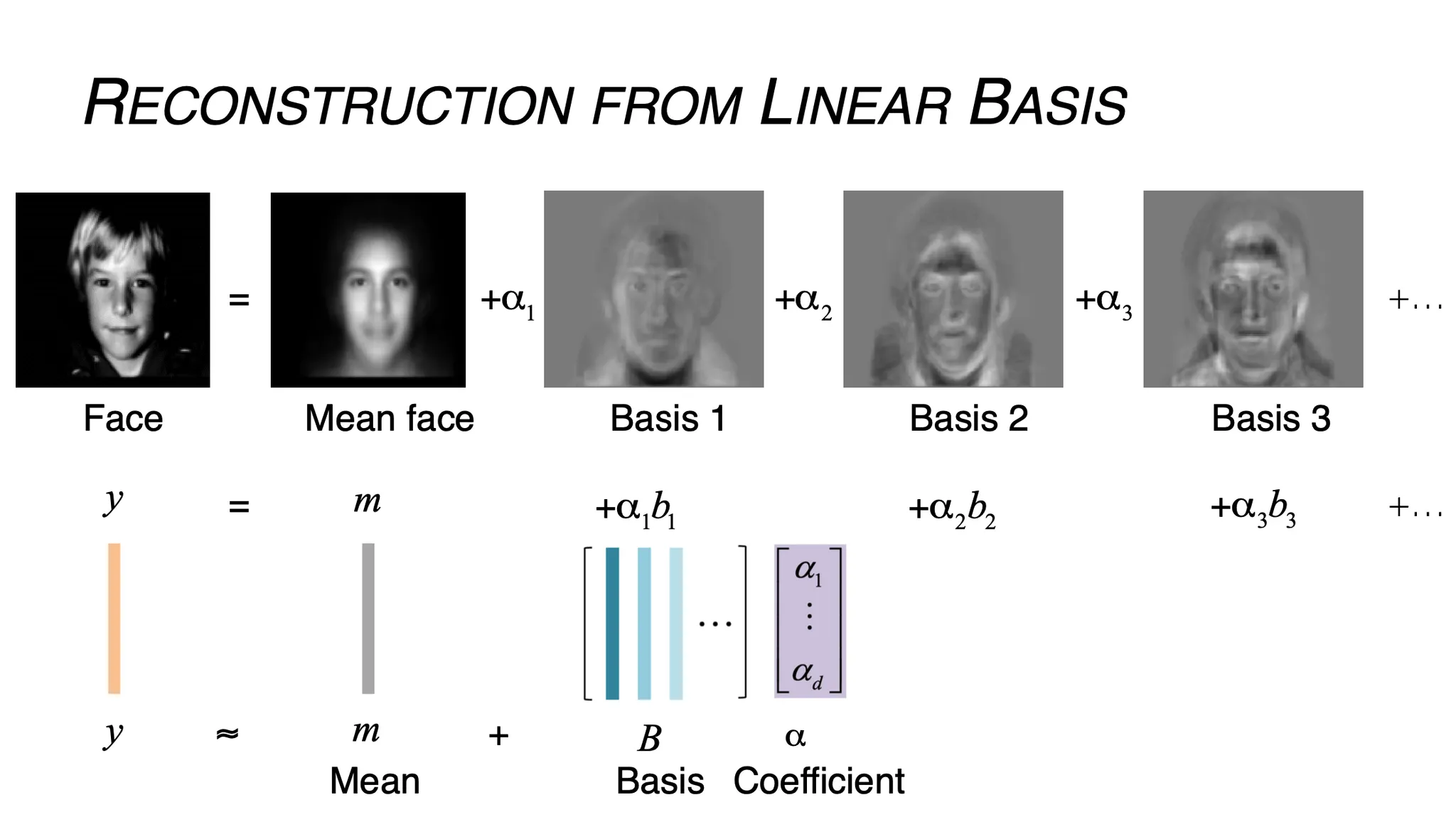
•
의 얼굴 이미지는 각 픽셀마다 차원을 가지기 때문에 차원이 굉장히 높음.
•
이 차원을 낮추면 mean 과 적은 수의 basis 로 얼굴을 재구성할 수 있음!
•
3D Face, Body 또한 마찬가지로 Low Dimension 으로 표현할 수 있음! (Mean Shape + Shape + Motion, Mean Shape + Shape Variation + Body Pose)
K-means Clustering
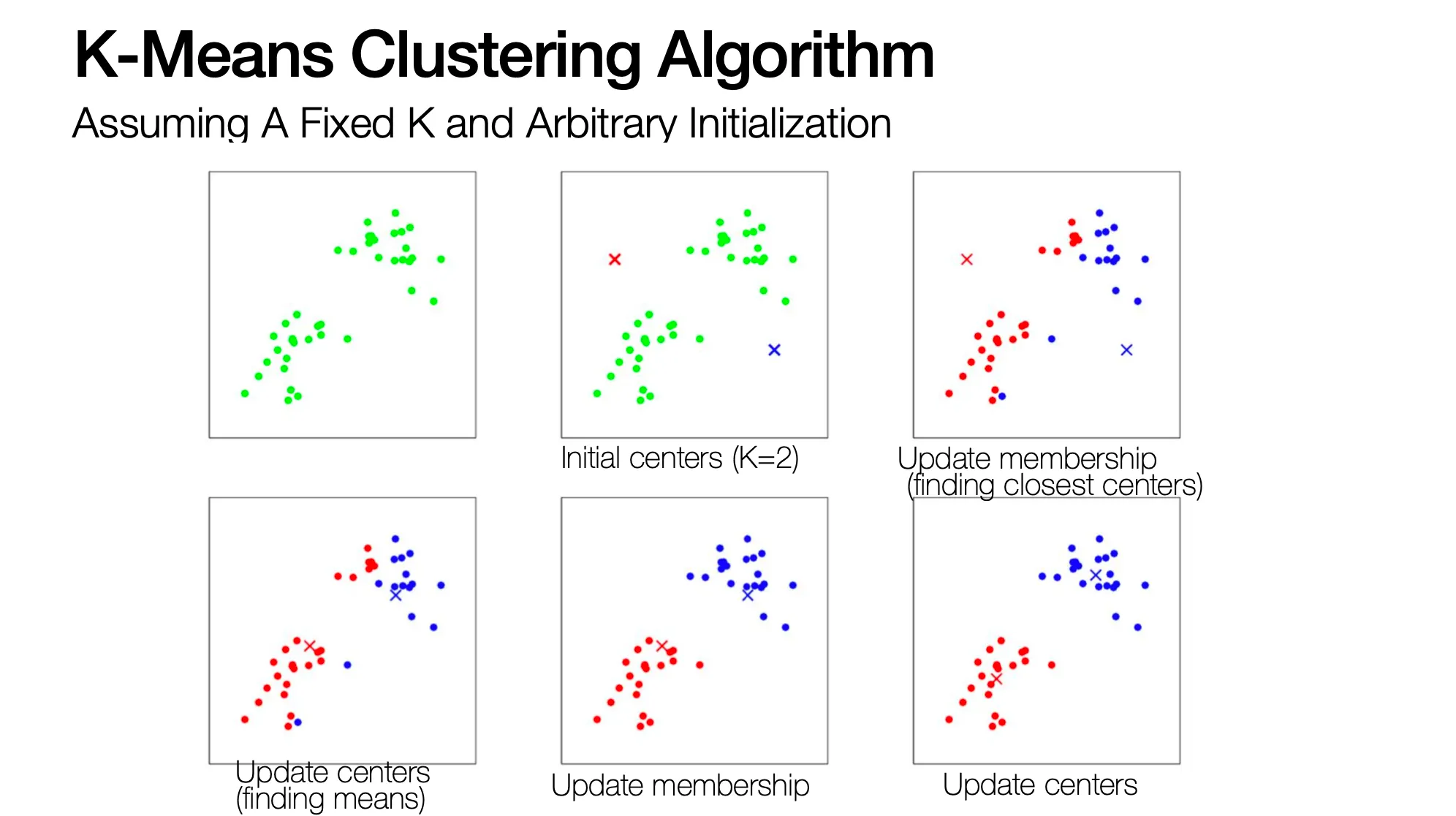
•
Clustering 의 목표는 각 그룹의 center 를 찾는 것
•
특정 데이터마다 속한 그룹 (membership) 이 정해지면, 가장 좋은 cluster center 는 각 그룹에 속한 데이터와 그 그룹의 center 와의 거리가 최소인 clustering 임.
◦
위 식은 Sum of Squared Distance 로 거리를 설정한 것
•
Membership 까지 변수로 고려한 최종적인 clustering 의 목적 함수는 다음과 같음!
◦
는 cluster 에 데이터 가 속하는지의 여부를 나타냄. 속하면 1, 아니면 0.
•
K-Means Clustering 은 초기에 cluster center ()를 임의로 둔 후,
1.
각 데이터들 각각에 대해서 가장 가까운 center 로 membership 을 설정함.
2.
동일한 membership 들을 가지는 데이터의 중심으로 해당 membership 의 center 를 옮김
◦
위의 1~2 를 convergence 까지 반복함! (반복해도 데이터의 membership 이 바뀌지 않을 때까지-)
•
픽셀들의 color 데이터로 clustering 을 할 수도 있음..! (동일한 색상이 동일한 cluster)
•
“K 를 어떻게 설정해야 하는가” 가 K-Means Clustering 의 가장 큰 한계점
•
“Initial centroid 를 어떻게 설정해야 하는가” 도 다른 문제점임 → 최대한 다양한 시작점을 둠!
•
Distance measure 또한 SSD 가 아니라 다르게 할 수 있음!
Mean-Shift
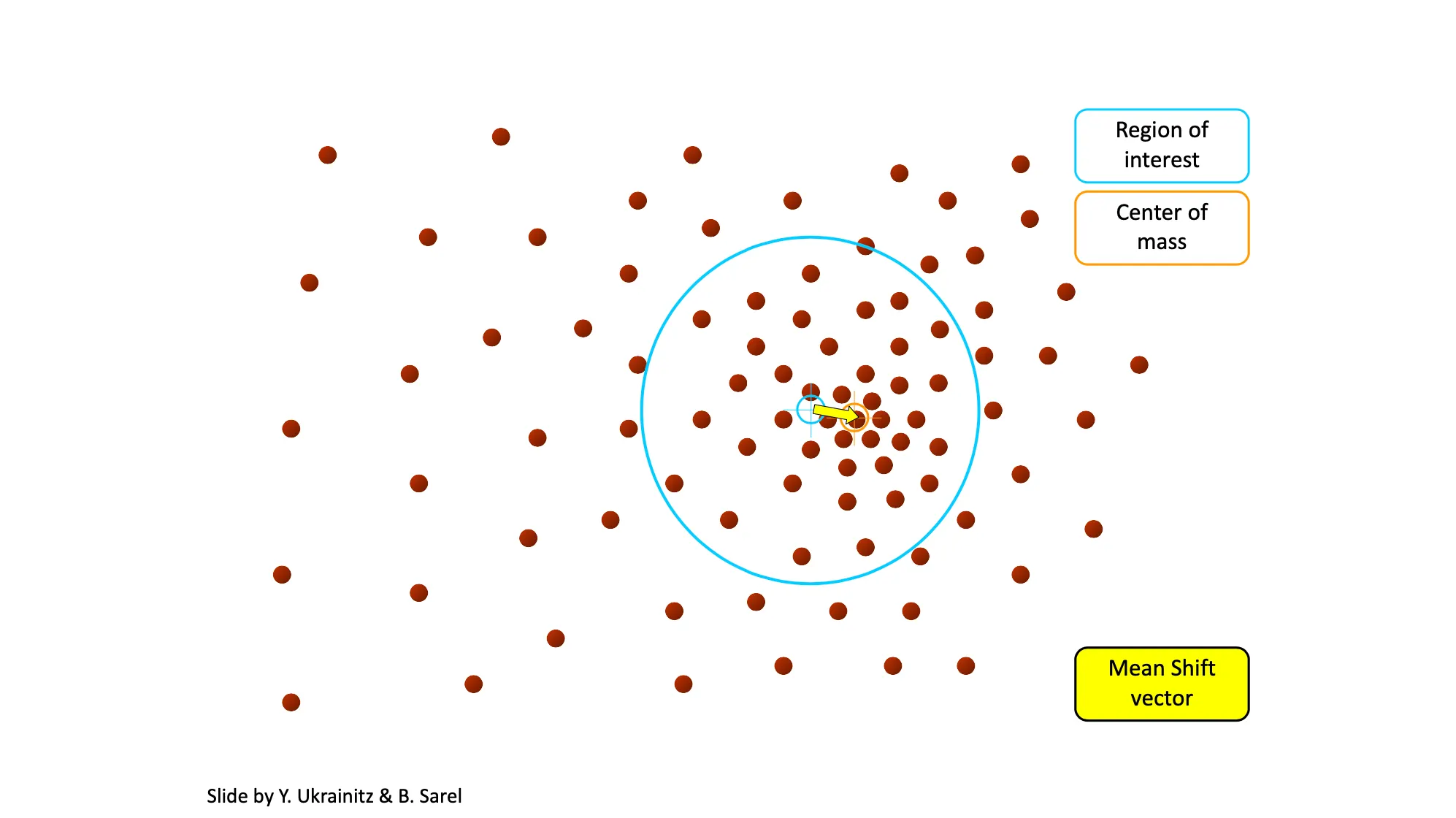
•
K-Means Clustering 은 초기 시작점에 대한 정보 없이 랜덤하게 설정해야 하는 문제점이 있음.
•
Mean-Shift 는 다음과 같은 알고리즘으로 진행됨.
1.
임의의 시작 위치와 window size 를 설정
2.
해당 Window Size 에 속한 데이터들의 중심으로 window 의 중심을 옮김
3.
2번을 반복함!
•
Cluster 는 동일한 데이터 지점으로 모일 수 있는 시작점들의 영역 (Attraction Basin) 내에 속한 데이터들을 묶으면 됨.
•
K 값을 정할 필요가 없지만, window size 를 정할 필요가 있음.